我们都知道,事务是个好东西,好东西就会发展,发展就会壮大。
随着事务的发展,事务的用法也分为几大类:扁平事务,带有保存点的事务,链事务,嵌套事务以及分布式事务等。
下面对这几类事务进行学习
1.扁平事务
1)什么是扁平事务?
扁平事务是最简单的事务,此类事务的所有操作都在同一层次上(同一数据库,同一回滚原则,要么都执行成功,要么都执行失败)。
扁平事务的执行只存在三种状况:成功提交,人工回滚,外界原因强制终止。
2)扁平事务实例
我们先查询表t
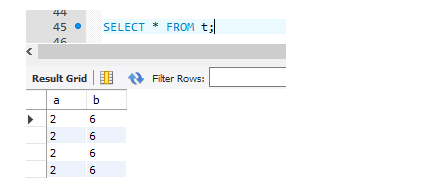
然后执行下面事务:
START TRANSACTION;
select * from t;
update t set b=7 where a=2;
rollback;
COMMIT;
会发现,表t中的数据没发生变化,因为回滚了,然如果将上面的rollback去掉,就会发现更新成功。
2.带有保存点的事务
1)什么是带有保存点的事务?
顾名思义,带有保存点的事务,就是可以在事务中设置保存点,并在一定条件下回滚到保存点而不是全部回滚。
2)实例学习
START TRANSACTION;
select * from t;
SAVEPOINT delete1;
update t set b=7 where a=2;
rollback to delete1;
COMMIT;
验证过程:
首先我们先查询表t的数据:
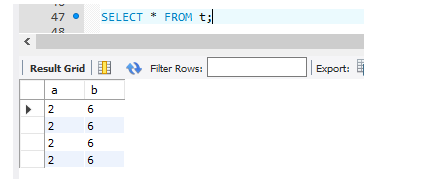
然后,执行:
START TRANSACTION;
select * from t;
SAVEPOINT delete1;
update t set b=7 where a=2;
后再查询表t的数据:
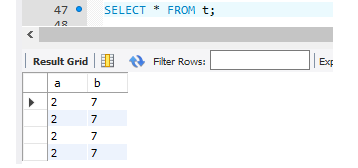
这时发现表t的数据在本次事务的当前时间发生了变化。
接着执行:
rollback to delete1;
后在查询:
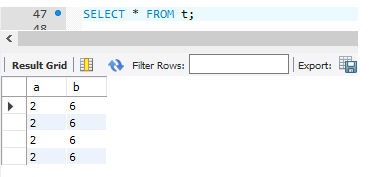
会发现它回滚了!!这就是保存点的威力。
3.链事务
1)什么是链事务?
链事务可以作为保存点模式的一个变种,带有保存点的事务虽然可以设置保存点,但是当系统发生崩溃时所有的保存点将会消失。
这意味着如果想要恢复保存点,就必须从开始重新执行,而不能从最近的一个保存点继续执行。
而链式事务的思想是:在提交一个事务时,释放不需要的数据对象,将必要的处理上下文隐式地传给下一个要开始的事务。
这就意味着,前一次事务的操作是持久的。但链式事务也是有缺点的:最多只能回滚到当前事务的起始点,无法回滚前一个节点事务提交前的状态。
2)实例学习
START TRANSACTION;
select * from t;
SAVEPOINT delete1;
update t set b=7 where a=2;
COMMIT;
START TRANSACTION;
select * from t;
rollback to delete1;
COMMIT;
我们执行上面链式事务看看结果:

可以很清楚的看到,当后一个事务想要回滚到前一个事务的保存点时,失败了。
接着看看表的数据是不是前一个事务提交后的数据:
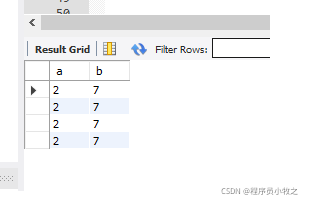
可以清楚的发现前一个事务提交的事务是持久的!!
4.嵌套事务
1)什么是嵌套事务?
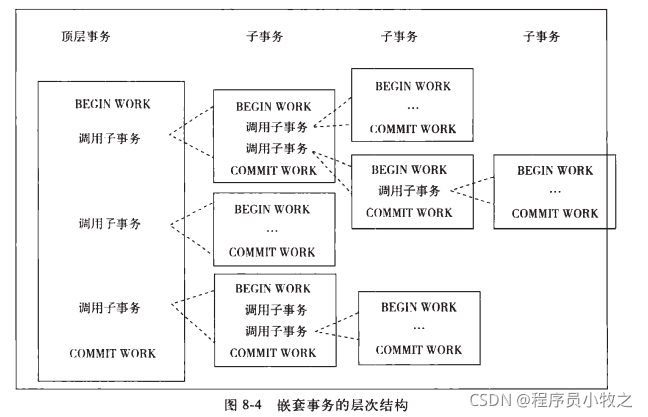
嵌套事务是一个层次结构的框架。有一个顶层事务控制着各层次的事务。顶层事务之下嵌套的事务被称为子事务,其控制每个个局部的变换。
如图:
关于嵌套事务,我们必须注意它的一些特性:
- 嵌套事务是由若干事务组成的一颗树,子树可以是嵌套事务,也可以是扁平事务。
- 处于叶节点的事务时扁平事务,但是每个子事务从根到叶节点的距离可以是不同的。
- 位于根节点的事务称为顶层事务,其他事务称为子事务。事务的前驱称为父事务,事务的下一层称为儿子事务。
- 子事务既可以提交也可以回滚,但是它的提交操作不会马上生效,除非由其父事务提交。因此可以知道:任何子事务都在顶层事务提交后才真正提交哦。
- 树中的任意一个事务的回滚会引起它的所有子事务一同回滚。故子事务只保留A,C,I特性,不具有D特性。
2)实例学习
mysql不显式的支持嵌套事务,但我们可以通过保存点来实现:
START TRANSACTION;
select * from t;
#开启子事务update1
SAVEPOINT update1;
update t set b=8 where a=2;
#开启子事务中的子事务sonupdate2
SAVEPOINT sonupdate2;
update t set b=9 where a=2;
#回滚子事务sonupdate2
rollback to sonupdate2;
select * from t;
#回滚update1
rollback to update1;
COMMIT;
通过保存点的嵌套可以实现嵌套事务的控制。
5.分布式事务
1)什么是分布式事务?
分布式事务通常指的是一个在分布式环境下运行的扁平事务,因此需要根据数据所在的位置访问网络中的不同节点进行数据库操作,这样就存在不同节点下事务如何同步的问题。
假设一个用户在AMT机前进行银行的转账操作,要从人民银行储蓄卡转账1000员到邮储银行卡中,
在这种情况下,可以将AMT机器视为节点A,人民银行的后台数据库视为节点B,邮储银行的后台数据库视为节点C,这个转账操作则可以被分为以下步骤:
节点A发出转账命令
节点B执行从人民银行储蓄卡中将余额值减去1000
节点C执行从邮储银行卡中加上1000
然后节点A通知用户操作完成或失败
在上面的过程中,很明显他们不在用一台机器上,所以这个过程必须通过网络通知来进行事务的同步,如何控制呢?
我们可以考虑下面的方案:
首先节点A发出转账命令后进入监听状态,然后节点B收到命令后执行完后告诉节点C并进入监听,然后节点C执行完后将成功或失败的标识发送给节点B,
节点B收到节点C的返回后,来进行事务的提交或回滚,然后节点B将执行的结果又返回给节点A,节点A根据节点B返回的结果告诉用户是失败或成功。
那么在实现上面方案的过程中的事务编程,就称之为分布式事务编程。
分布式事务非常具有挑战性,以后详细深入学习!!