身为测试工程师,总有一道绕不过去的坎就是定位bug,这其实是非常花费时间的。
也许有很多人不以为然,觉得无非就是发现bug后提交bug管理系统,描述操作步骤,预期结果和实际结果哪里不一致,然后继续测试。并不是说这样做的不对,只是说这样做的不够好,看似节约了测试时间,实则对于项目的进度没有起到应有的推动作用。
1、web前端
Web前端就是通常说的网页。互联网公司的前端一般包含如下内容:JavaScript、ActionScript、CSS、HTML(…ML)、HTML5、Flash、交互式设计、视觉设计。
web前端测试可能发现的问题——版面设计、交互设计、文字、性能、功能。
bug定位通用思路:现象–>原因–>验证手段–>结论–>现象
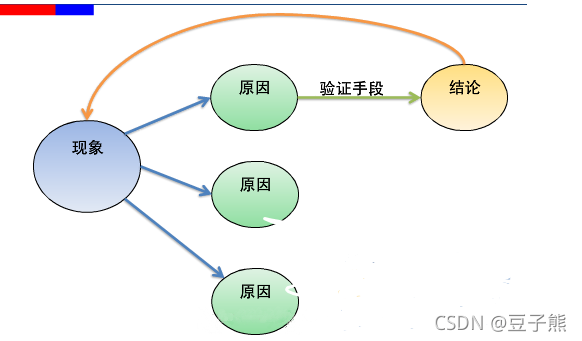
测试bug定位原因归类:
测试环境相关
- 是否安装了flash及flash的版本——可能导致部分页面显示出问题,目前常用的版本诶flash10
- 是否开启了浏览器插件——插件可能导致浏览器行为的变化,除非测试要求,否则一律禁用插件
- 是否开启了安全软件——可能会截包、弹窗拦截、防钓鱼等
浏览器相关
- 不同浏览器的支持标准——不同内核的浏览器对js及各种标准的支持不同,因此页面解析出来的效果可能不同。Firefox:gecko;Chrome:webkit;IE:trident;Safari:webkit。
- 浏览器的设置——禁用js;禁用弹窗;禁用cookie等
- 浏览器cache策略——js,css,图片等都有可能被cache住。ctrl+F5强制刷新请求
- cookie——跨域,过期
网络相关
- 是否发出了正确的请求——请求url、参数变量。content数据
- 是否得到了正确的应答——http的返回值:200-正确;302-对象已移动;304-对象未修改;404-没有找到页面。返回的数据体
- 是否性能问题——异步请求的数量过多;网速过慢
字符编码相关
- 页面乱码——百度后端存储基本是使用的GBK编码,前端提交可能是UTF-8编码,后端对于非GBK编码一般采用实体存储。可能出现编码没有转换。转换的时候没有判断半个汉字(转掉了半个汉字导致雪崩)。
- url错误——url路径中汉字编码使用的是utf-8编码,参数中使用系统默认编码,flash脚本中使用的都是uft-8编码。
安全相关
Xss漏洞——输入一些特定字符页面出现错乱或有恶意代码被执行,RD未对特殊字符转义完整
性能相关
- 图片数量——页面中同一个域的图片的数量控制在16个以下,IE会控制同一个域下图片并行的下载数量
- 页面抖动——异步请求的数量过多
- 加载失败——限速情况下,超时
bug定位常用工具
- Firefox——firebug、web developer、live http headers、http fox
- IE插件——httpwatch
- 第三方工具——fiddler、charles
- 慢速网模拟工具——firefox throttle、fiddler、charles
2、web后端
后端包含运行在服务器上的程序,脚本和服务。比如:各种各样的逻辑处理系统,数据存储系统等。
后端可能发现的问题——逻辑的,数据的,策略的,接口的,性能的等
测试bug定位原因归类:
数据流相关
- 上下游模块是否连接正常——模块的ip和端口的配置,白名单黑名单配置,session授权
- 模块的数据发送接收是否正常——日志是否有滚动,是否显示发送了数据或接收到数据,数据是否完整,跨机房,负载均衡算法(从哪些机器获取到的数据)
- 非socket的数据传输——共享内存(是否分配,key的配置等),cache(是否创建,脏数据等),数据库(配置,连接,表,触发器,存储过程),文件(大小,访问权限)
- 模块之间的接口——协议的一致性(mcpack1,mcpack2等),字段的一致性(一个按signed解析,一个按unsigned解析),字段复用
处理逻辑相关
- 程序的各种配置——功能是否开启/关闭,词表是否加载,各种阈值的配置,超时配置
- 程序日志——日志级别,交互的流程,处理的流程
- 各种边界——数据边界(int,long),文件边界(空文件,分文件的边界),时间边界
- 各种资源并使用——Cache是否遗留脏数据,并发和死锁
系统和环境相关
- 系统资源——Cpu,io,句柄,内存,网络状态,数据库状态,数据库连接数
- 环境资源——程序版本,内核版本,网络(外网)访问权限,系统动态库不一致
程序和代码相关(常用验证手段)
- 确认问题出现的位置——日志中的代码行,gdb中的代码行,抛出异常显示的代码行
- 获取当时的运行时信息——Gdb core文件,gdb attach到进程,查看堆栈,查看寄存器,设置breakpoint,watchpoint,查看内部数据
- 获取程序和系统信息——Strace查看系统调用,系统状态获取(ps,top,/proc/pid/*,vmstat,netstat)
- 更深入的手段——反汇编,查看寄存器,gdb高级应用
后端测试bug定位
日志查看命令
- 查看压力——tail -f as.log | grep ‘^NOTICE’ | awk ‘{print $3}’ | uniq -c
- 排除日志中的特定内容——grep -v ‘pattern’ as.log
- 只输出感兴趣的内容——grep -o ‘proctime:toal:\d+’ as.log;grep -o ‘proctime:toal:\d+’ as.log | grep -o '\d+ ';grep -o ‘proctime:toal:\d+’ as.log | grep -o '\d+ ’ | sort -n | uniq -c
- 将wf日志归类——grep -o ‘\w+.(cpp|h):\d+’ as.log.wf | sort | uniq -c
gdb常用命令 - bt——查看堆栈信息
- print——打印某变量值
- break——设置断点
- x/i——翻译当前指令为汇编
- info thread——查看所有线程,星号*标记的是当前线程
- thread num——切换到线程号为num的线程
- set scheduler -locking on——锁定在线程:输入continue命令以后,当前线程继续执行,其它线程不执行
- set scheduler-locking off——这是默认设置,输入continue命令以后,所有线程都继续执行
3、性能测试
旨在获取系统在特定一种或多种环境下,在不同的外部输入压力(包含极限)的条件下的系统各项指标的测试
常用命令
- 进程相关——ps,top,/proc/pid/*
- 系统相关——vmstat,top,iostat,sar,df,lsof
- 网络相关——netstat
bug定位原因归类
压力工具相关
- 工具的功能和性能——能否达到预期压力,启动压力的机器性能,压力工具是否有异常连接关闭,压力工具如何处理异常,长连接短连接,并发的个数
- 工具运行环境——压力机器的带宽,是否跨机房
被测系统相关
- 机器性能——系统所在机器性能,机器网络带宽,机器的内存,sd卡,硬盘
- 系统本身——系统的下游模块的性能,系统的配置,系统的数据量,系统的特点状态(充cache,dump,merge),系统的部署,程序的bug
环境相关 - 操作系统相关—— 是否和线上一致,内核版本,刷脏页时间,有没有调用directIO
- 查看系统状态——Ps,top,/proc/pid/*, vmstat,netstat
- 正确的思路+丰富的业务知识+丰富的技术背景知识+较好的调试和开发能力= 强大的bug定位能力Bug定位的过程是能力提升的过程。
最后也给软件测试的朋友们分享一份测试资料:

这些资源都共享在群里面,需要的可以加群 946094265自取。群里除了有很多测试资源,还有不少大牛,大家可以一起交流技术,不再野蛮生长。
正所谓万事开头难,只要迈出了第一步,你就已经成功了一半,古人说的好“不积跬步,无以至千里。”等到完成之后再回顾这一段路程的时候,你肯定会感慨良多。