大数据中的几个概念
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/118599017(CSDN作者:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 大数据聚集层面
先举个例子:假如我是一个电商,我想要把过去一个月中卖得好的商品提出来打包放在电商网页的首页,这样用户打开首页之后就能直接看到热销的商品了(这里就是一个商品推荐的案例),具体面临的问题有两个
- (1) 大量数据如何存储(比如订单数量,信息)
- (2)大量数据如何进行计算(繁杂的数据中如何进行数值计算,统计)
还有一个就是天气预报的案例:比如将某一城市的天气预测,就需要将市中所有的站点数据全部都获取到,然后再进行计算,而且天气数据是实时动态刷新数据,数据量及其庞大,存储是一个问题,计算同样也是一个问题
所以大数据就聚焦在两个方面:
-
(1)海量数据的存储。解决方式:分布式文件系统 HDFS
-
(2)庞大的数据计算。解决方式:分布式计算模型MapReduce、Spark RDD、Flink分区
* 具体数据计算细分: *(A)离线计算、批处理 MapReduce、Spark Core、Flink DataSet *(B)实时计算、流处理 Storm、Spark Streaming、Flink DataStream
2 数据仓库
在没有大数据技术之前,人们依然是有数据存储的需要的,那时候常用的数据库都是关系型数据库(比如Mysql,Orcle等),现在随着数据存储的需要变得庞大,那么就有了数据仓库的概念,本质上也就是一个数据库。一般只做查询select
Hadoop、Spark、Flink、NoSQL都可以看成是数据仓库的一种实现方式。数据仓库的搭建过程解析如下,可以分为四部分:
- (1)数据源:数据的来源可以由传统的关系数据库管理系统(RDBMS);也可以来自于微信聊天记录,微博评论等文本日志数据;也可以是其他数据源
- (2) 数据仓库:用于存放经过处理的数据源,传统的处理方式就是ETL,E代表着提取(指采用一定的方式进行数据的读取),T代表着转换(提取出的数据不一定都是需要的,有些数据是敏感数据,有些为缺失数据),L代表着加载(将最终的需求数据放置到数据仓库中)。但是需要注意的一点就是,进入仓库的数据虽然经历过ETL的过程,但是仍然是原始的数据,没有进行任何的分析和详细地处理,因此不能直接提供给用户端
- (3)数据集市:对存放在数据仓库的数据进行分析与整理,按照业务需求搭建数据集市,从本质上来讲也是一个数据库,但是面向的是业务主题,而这个业务主题也就是有用户需求所决定的,所以数据集市里面的数据要面向业务主题,面向用户
- (4)用户端:用户根据需求向数据集市中获取数据
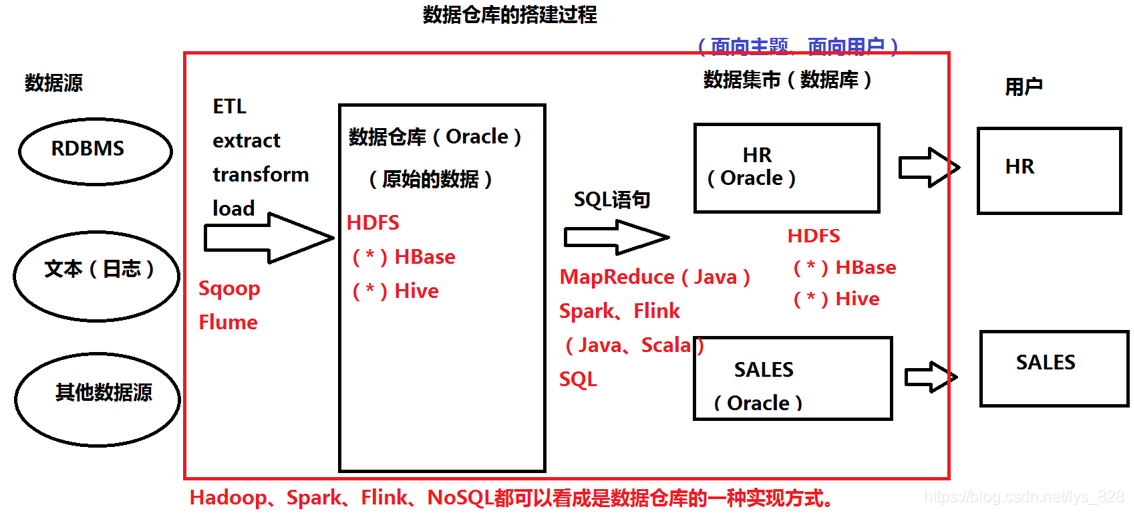
在上图中红框内部,上面黑色的部分是传统的数据仓库搭建的过程,而红字代表着现在大数据技术下的数据仓库搭建
- Sqoop和Flume都是进行数据采集,不同点在于Sqoop作用于RDBMS,而Flume应用于文本日志数据采集
- HDFS(分布式份文件系统),解决海量数据的存储,还可以存在Hbase和Hive进行存储,需要注意的是Hbase是基于HDFS之上的NoSQL数据库,Hive是支持SQL语句,基于HDFS之上的数据数据仓库,所以Hbase和Hive存放数据时依然是放在HDFS里面
- 分析和计算,可以使用MapReduce、Spark、Flink,之前介绍了这三种都是用Java或者Scala语言进行编写, 然而很多人都是无法同时接受多种语言,最终需要一个简单的SQL语言进行操作,而Hive就是基于SQL语言进行操作的,所以最后的数据集市依然可以使用Hbase和Hive
3 OLAP和OLTP
数据分析师的考核题:(ETL属于哪个环节中?答案是OLAP)
OLAP: online analytic processing 联机分析处理:select
数据仓库又是一种OLAP的应用(也就是说重点放在查询操作上)
OLTP: online transaction processing 联机事务处理:insert update delete commit rollback (重在传统数据库的事务操作上)