Hadoop体系架构详解
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/118655138(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 NameNode职责
1.1 NameNode三大职责
- (1) 管理HDFS:数据节点(DataNode)需要向NameNode报告数据块状态
- (2) 接受客户端的请求:数据上传,数据下载(客户端有上传数据的需求,就会把请求发给NameNode,然后NameNode指定DataNode存放数据,俗话理解就是甲方有个需要,让后找个对应的技术负责方,负责方安排小弟各个完成任务)
- (3) 维护HDFS:体现在维护edits文件(客户端操作日志)、维护fsimage文件(元信息文件)
关于edits文件和fsimage文件之前博客中也有部分梳理,但是没有详细地介绍,以下就分别进行详细介绍
1.2 edits文件
首先确定一下文件的位置,确保可以找到它:$HADOOP_HOME/tmp/dfs/name/current
在进行环境搭建的时候,无论是伪分布模式还是全分布模式,在配置core-site.xml文件前都需要在Hadoop中新建一个tmp文件夹,该文件目录就是对应着HDFS操作系统目录,所有操作内容都将存储在这个文件夹中

上机实操如下,进入tmp文件目录中,可以看到其下的dfs文件夹,更进一步就可以知道里面包含的信息,由于这里启动的是bigdata111虚拟机,设置的是伪分布模式,所有的节点都在一台机器上,故dfs文件中包含了全部的三个节点的信息
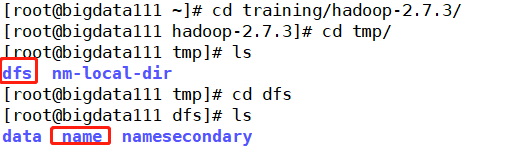
自然我们要找的edits文件就在name文件夹下,然后更进一步获取信息,可以发现pwd输出的结果正式上面列出的edits文件所在的位置,不过也发现fsimage文件也是在此路径下
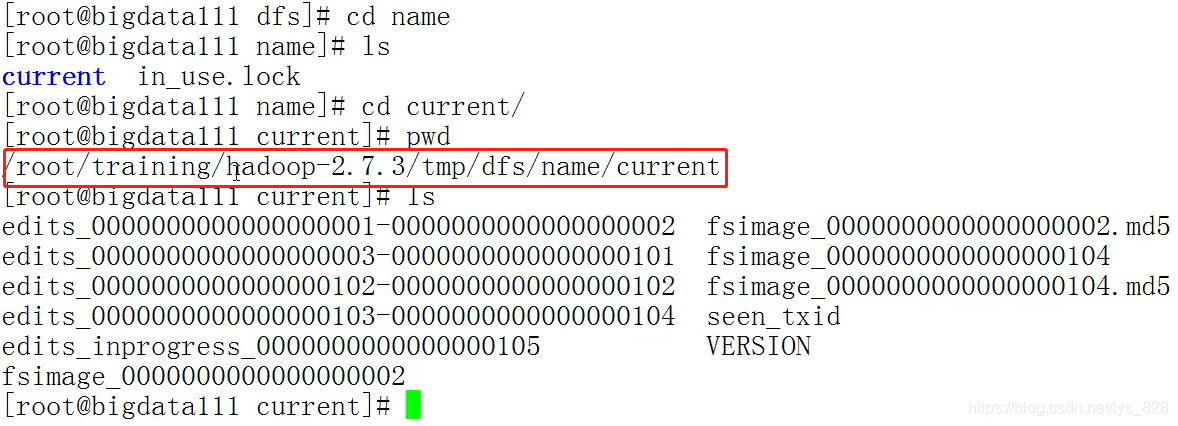
为了查看edits文件的功能,这里可以在HDFS中新建一个文件夹,然后查看一下对应的edits文件,如下
hdfs dfs -mkdir /toolspwdls edits_*

注意:edits_inprogress_0000000000000000105是当前正在操作的日志,都是二进制,可以使用日志查看器进行内容的查看,具体的操作如下,其中oev指令,-i为参数,后面指定具体的二进制文件,然后-o参数后指定具体的文件位置,最终生成一个xml的可编辑(查看)文件
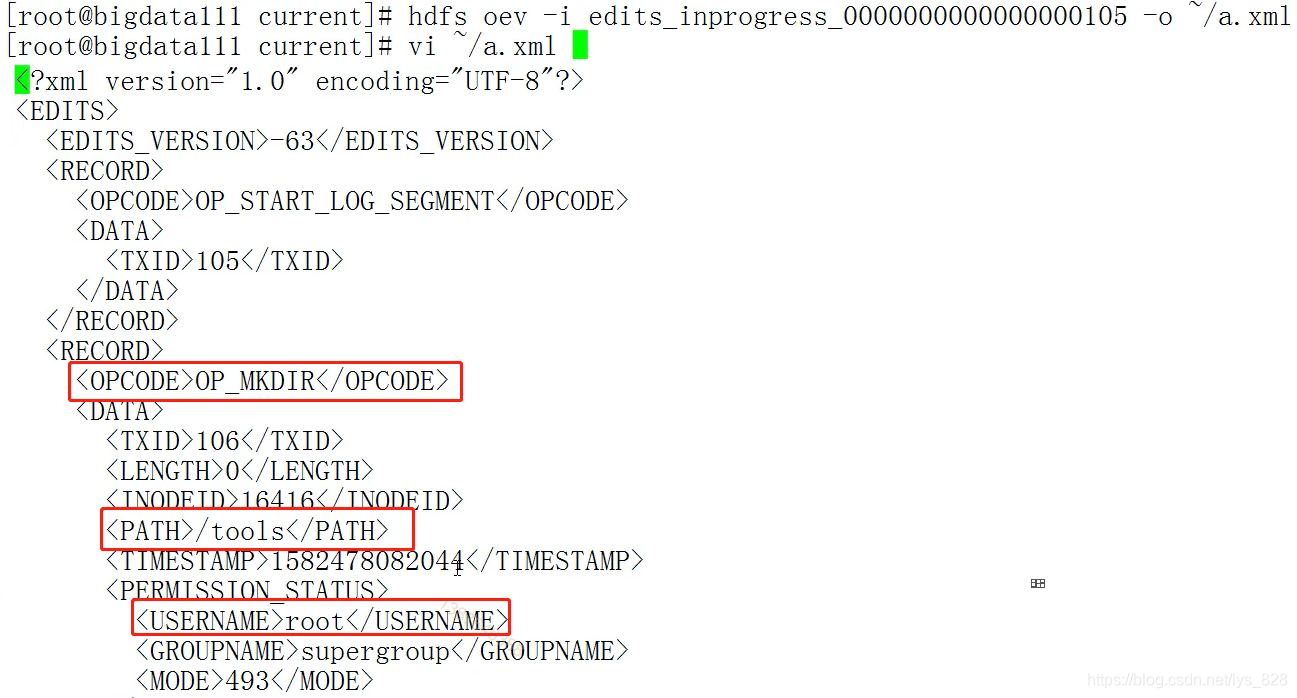
hdfs oev -i edits_inprogress_0000000000000000105 -o ~/a.xml
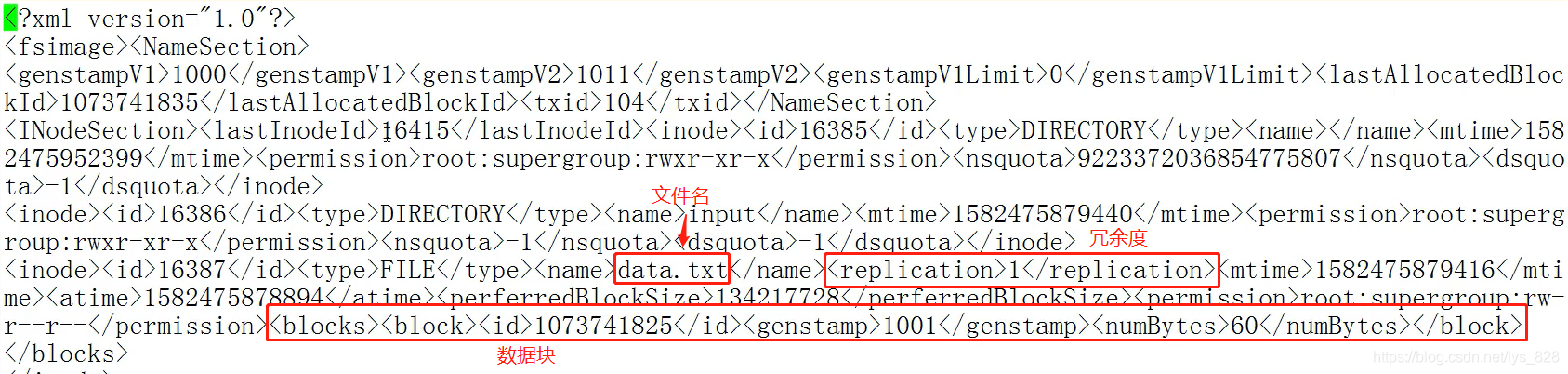
打开a.xml文件后,可以发现使用的是root用户,执行的命令是mkdir,然后生成的文件夹名称为tools,还有相应的时间戳,因此如果系统中有文件/文件夹损坏,就可以使用这种方式进行恢复
1.3 fsimage文件
首先确定一下文件的位置,确保可以找到它:$HADOOP_HOME/tmp/dfs/name/current
fsimage文件功能:记录的是数据块的位置信息、冗余信息
为了明确fsimage文件功能,比如将hadoop介质直接上传到刚刚创建的tools文件夹中,hadoop介质的内存大小204m,操作如下

然后在current中查看fsimage文件,同样HDFS中也提供的有元信息查看器,最终生成的也是xml文件,代码指令:hdfs oiv -i fsimage_0000000000000000104 -o ~/b.xml -p XML
对比前面客户端日志转化的指令可以发现,之前的oev,中间的e就是代表着edits文件,这里的oiv,中间的i就是指的fsimage文件,最后多了一个-p XML要求最终的文件为xml格式。查看生成的文件内容,核实一下是否包含了所说的一些功能(核实无误)
至此关于NameNode有关的信息就全部梳理完毕
2 DataNode职责
(1)数据节点(DataNode),自然是用来存放数据。存放的要求,即是按照数据块来保存数据:1.x:64M 2.x:128M
(2)数据块的位置:$HADOOP_HOME/tmp/dfs/data/current/BP-90413187-192.168.157.111-1582475681214/current/finalized/subdir0/subdir0
之前的NameNode信息存放在dfs文件目录下的name文件夹下,自然DataNode信息就存放在data文件夹下,且数据块的信息都是以blk信息开头,查找全部的数据块信息操作如下,这样就可以发现数据块的具体位置(当然直接在data下的current文件夹下找也可以)
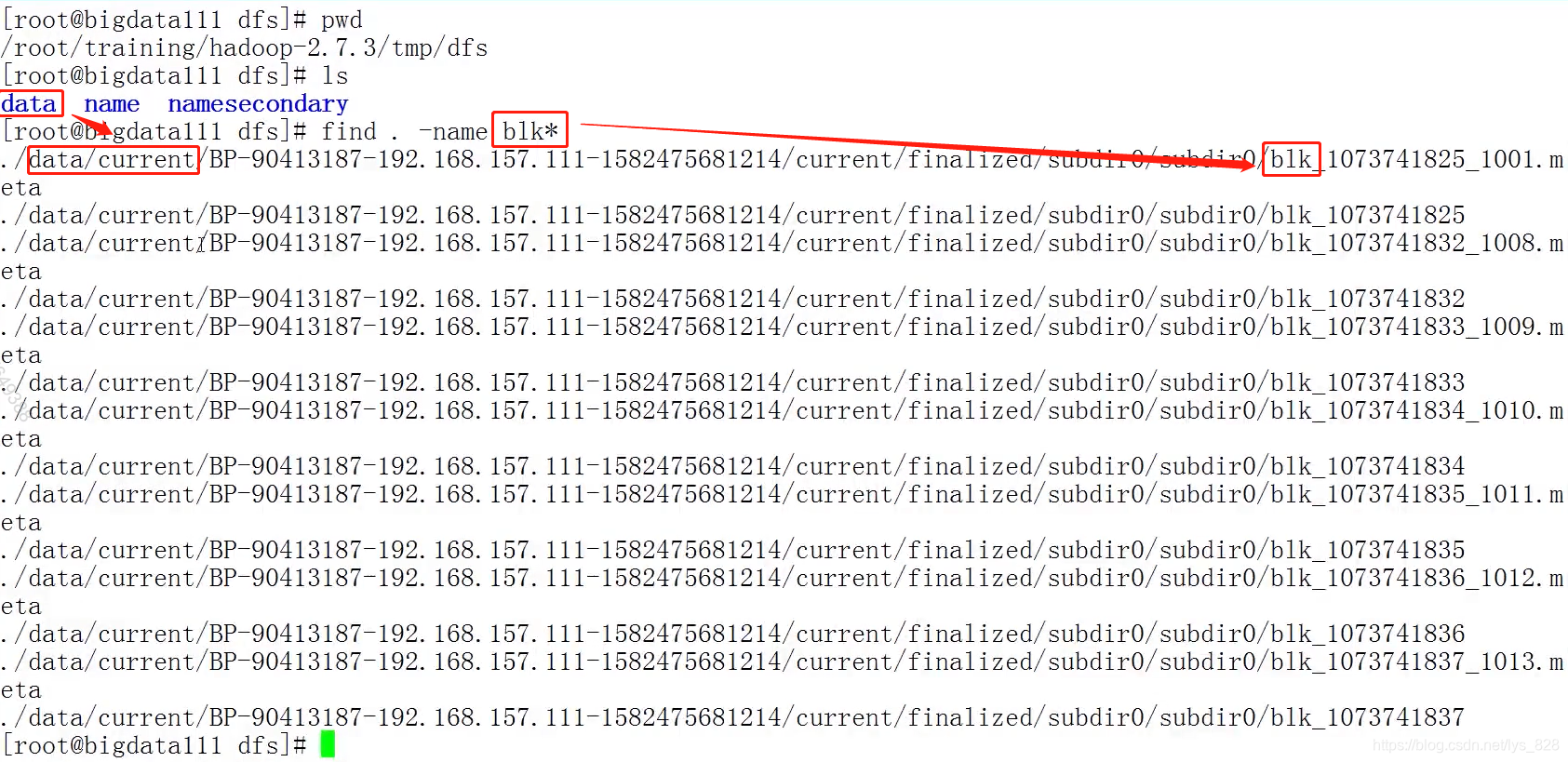
(3) 数据块信息,满128m被分块
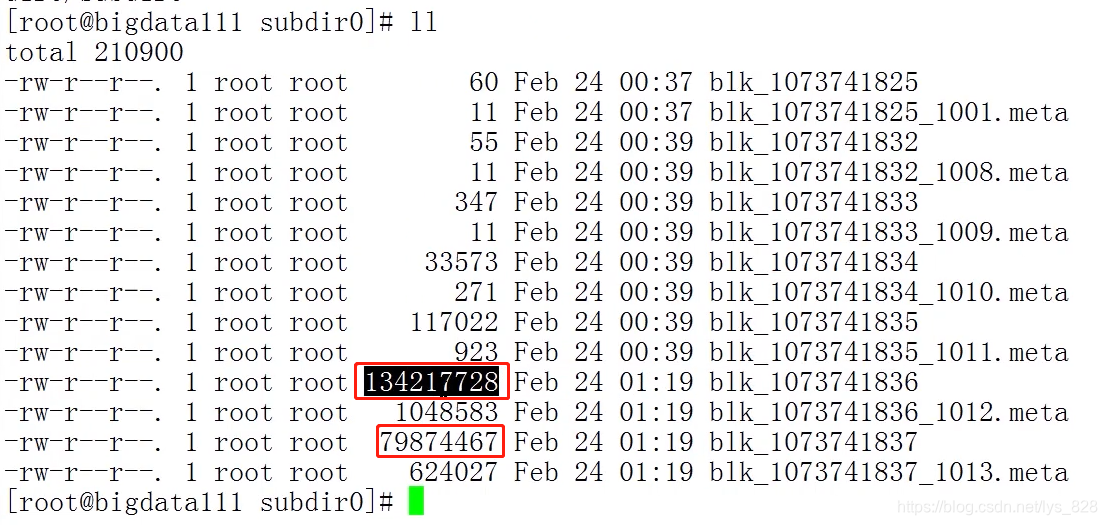
细心点可以发现,blk信息都是成对的出现,有一份是.meta后缀的文件属于对应数据块的元信息文件。上面在进行fsimage文件功能查看之前上传了一个hadoop介质,该文件的大小为204m。自然上传完毕后就会被切割为两个数据块,可以计算一下两个数据快的大小,下面框选的就是数据块的字节大小,然后除以1024就是以m为单位的大小(134217728+798744467=214092195),算出的字节数和上面fsimage文件处查看hadoop介质的内存大小是一致。
(4)设置数据块冗余度的一般原则:冗余度跟数据节点个数一致,最大不超过3。
至此关于DataNode的所有知识就梳理完毕
3 SecondNameNode职责
SecondaryNameNode:第二名称节点,跟NameNode运行在一起
- (1)不是NameNode热备(还是要强调,如果NameNode故障,SecondaryNameNode不能顶替其进行工作)
- (2)职责:定期进行日志信息的合并:把edits文件----> fsimage文件
- (3)重点:掌握日志合并的过程(可以用于解释为什么要和NameNode运行在一起)
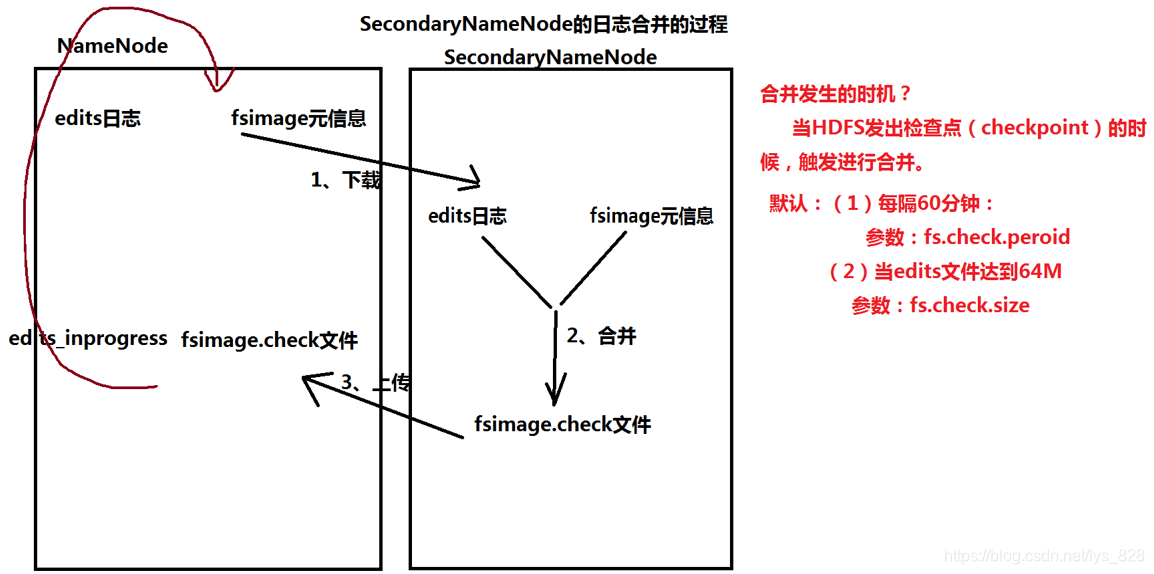
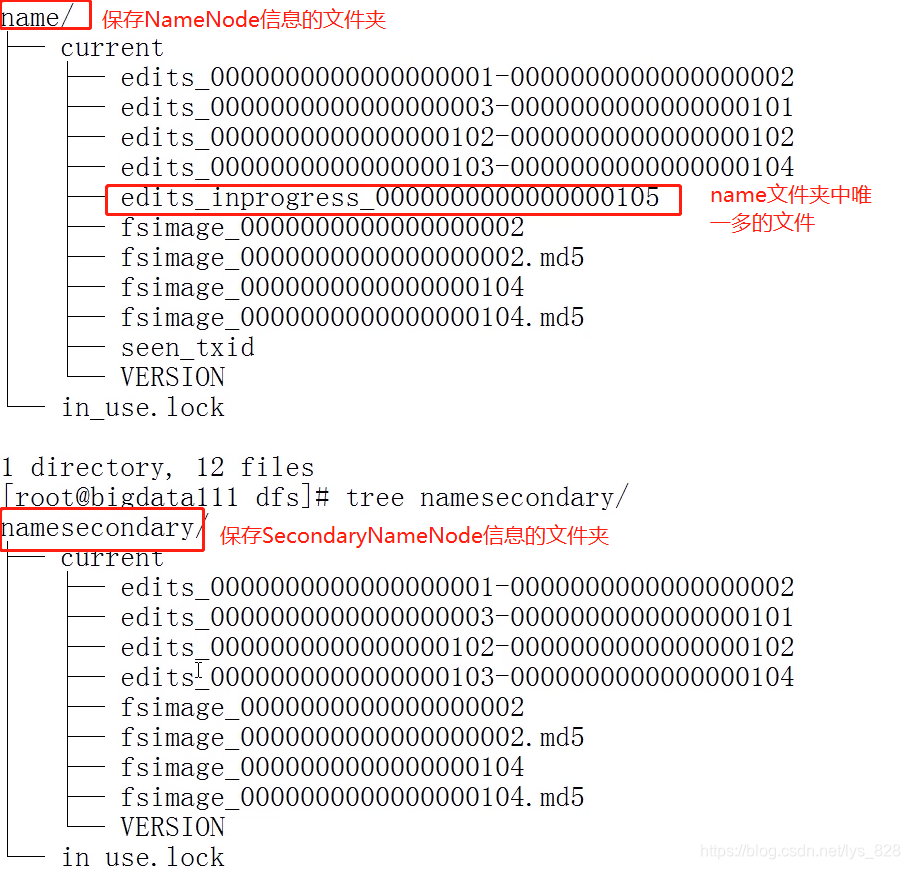
上机演示name文件夹和namesecondary文件夹之间的差异,唯一多出来的这个文件显示inprogress,说明正在处理中,为什么会有这个文件?因为文件的下载、合并、上传都是需要花费时间的,假定是一分钟,那么客户端在这一分钟之内就可能产生新的日志文件,因此就会生成这个inprocess文件(作用:当合并发生以后,记录最新的客户端日志)
然后就可以回答为什么NameNode要和SecondaryNameNode运行在一起,就是因为这个下载、合并、上传的过程,发生在本地时候,这时系统处理数据不需要通过网络连接,避免了网络请求而是直接在本地(同一台机子)上完成,这样会大大提高数据的处理效率
补充一点:检查点(就是触发合并的时间)
(1)HDFS:触发日志的合并
(2)Oracle:会以最高优先级唤醒数据库的写进程,写脏数据
(3)Spark和Flink:容错机制
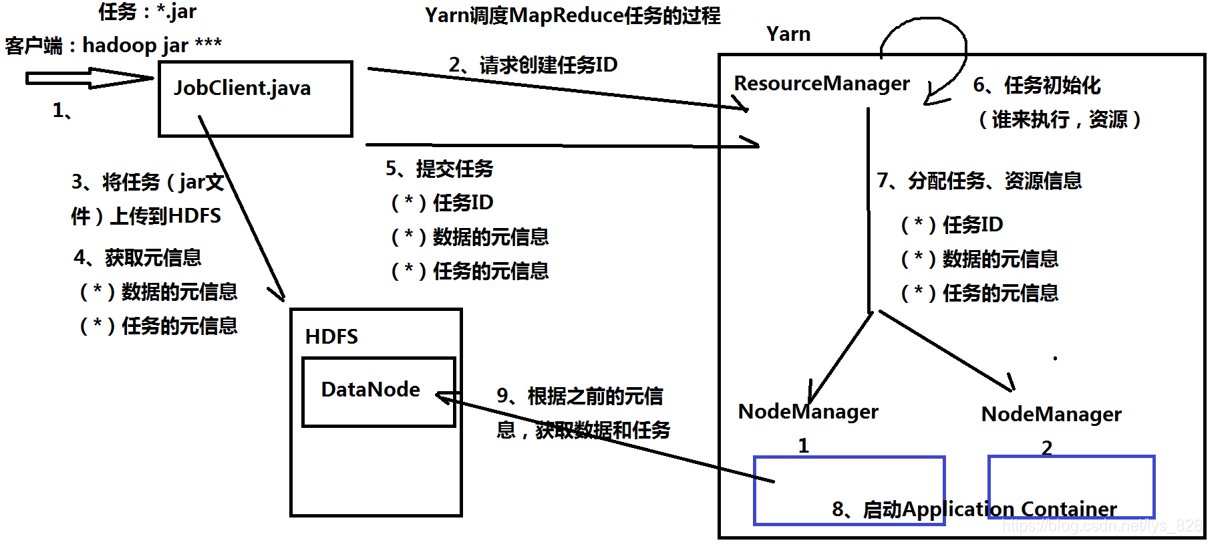
4 Yarn体系架构和任务调度过程
之前已经演示过wordcount程序:hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/data.txt /output/wc1
输出结果是对文件中的单词进行统计并且排序,接下来就解析期间yarn中的各个节点是如何运行,yarn体系架构依然是主从节点组成。
(1)ResourceManager:主节点(职责如下)
- ① 接收客户端的请求:执行MapReduce任务的请求
- ② 资源的分配:CPU、内存、网络
- ③ 任务的分配:分给NodeManager去执行
(2)NodeManager:从节点(职责如下)
- ① 从ResourceManager获取任务和资源
- ② 执行任务
(3)Yarn调度MapReduce任务的过程:注意这里的NodeManger是要和DataNode连接在一块,这样就减少了网络请求,直接加快了效率(也就解释了为啥这两个节点要在一块了)
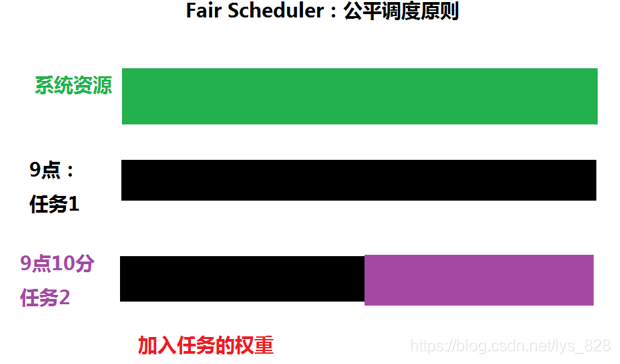
(4)Yarn的资源分配方式:3种
- ① FIFO Scheduler 先来先得,问题:没有考虑任务的优先级
- ② Capacity Scheduler:容器管理的调度规则,允许多个组织共享集群的资源
- ③ Fair Scheduler:公平调度原则,假设:任务具有相同的优先级,平均分配系统的资源。(之后利用yarn调度spark,必须要是公平调度模式)
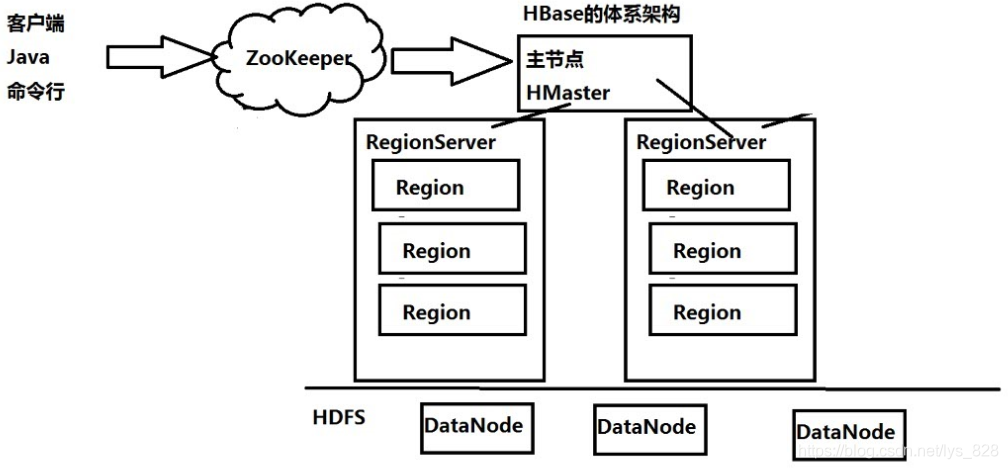
5 Hbase体系架构
Hbase也是主从架构,主节点为HMaster,从节点为RegionServer,还有一个ZooKeeper(当做“数据库”即可)
由于是一个大表存放数据,所以随着数据的加入,列族可能会不断地增大,这时候为了保存数据尽量会使用多个region进行存储,而且客户端的请求不能直接连接到HMaster,需要中间有个ZooKeeper进行架桥(也就是客户端并不认识HMaster,当其要上传时候,它就找一下ZooKeeper,然后ZooKeeper告诉它,把请求发给指定的HMaster就行。俗话点就是,你想找一个官场人员办事,但是你并没有官场朋友,就打听到村里有个人能够使用他的关系,有能力帮你找到负责人的官场办事人员,然后你就可以把你的诉求上报给官场的人员了)。
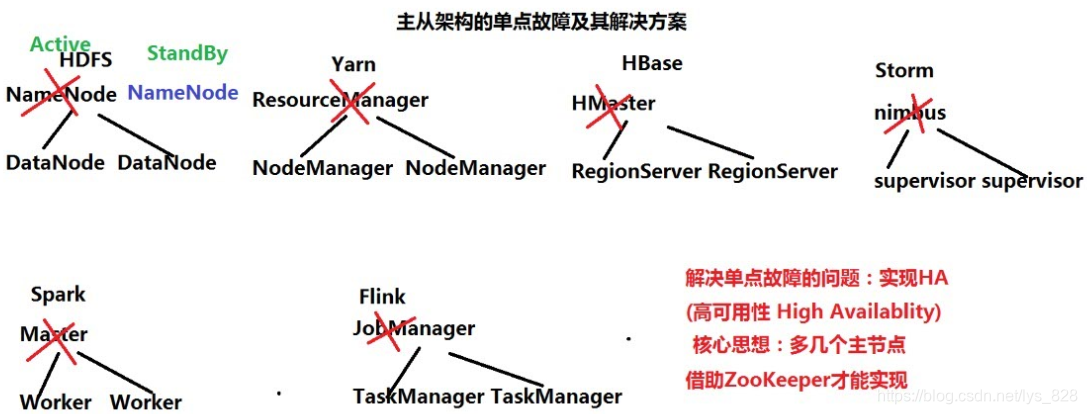
6 主从架构单点故障问题及解决方案
除了Hadoop,整个大数据的体系架构基本上也是一个主从架构,如下。核心思想就是多搞点主节点,一个主节点激活,其余的都处于待命的状态。