数字、字符串和对象的排序
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/118974089(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 Java的排序
在认识Hadoop中的排序操作之前,可以了解一下Java的排序操作,具体是通过Comparable接口实现。可以直接查看一下API文档,看看这个类的使用说明
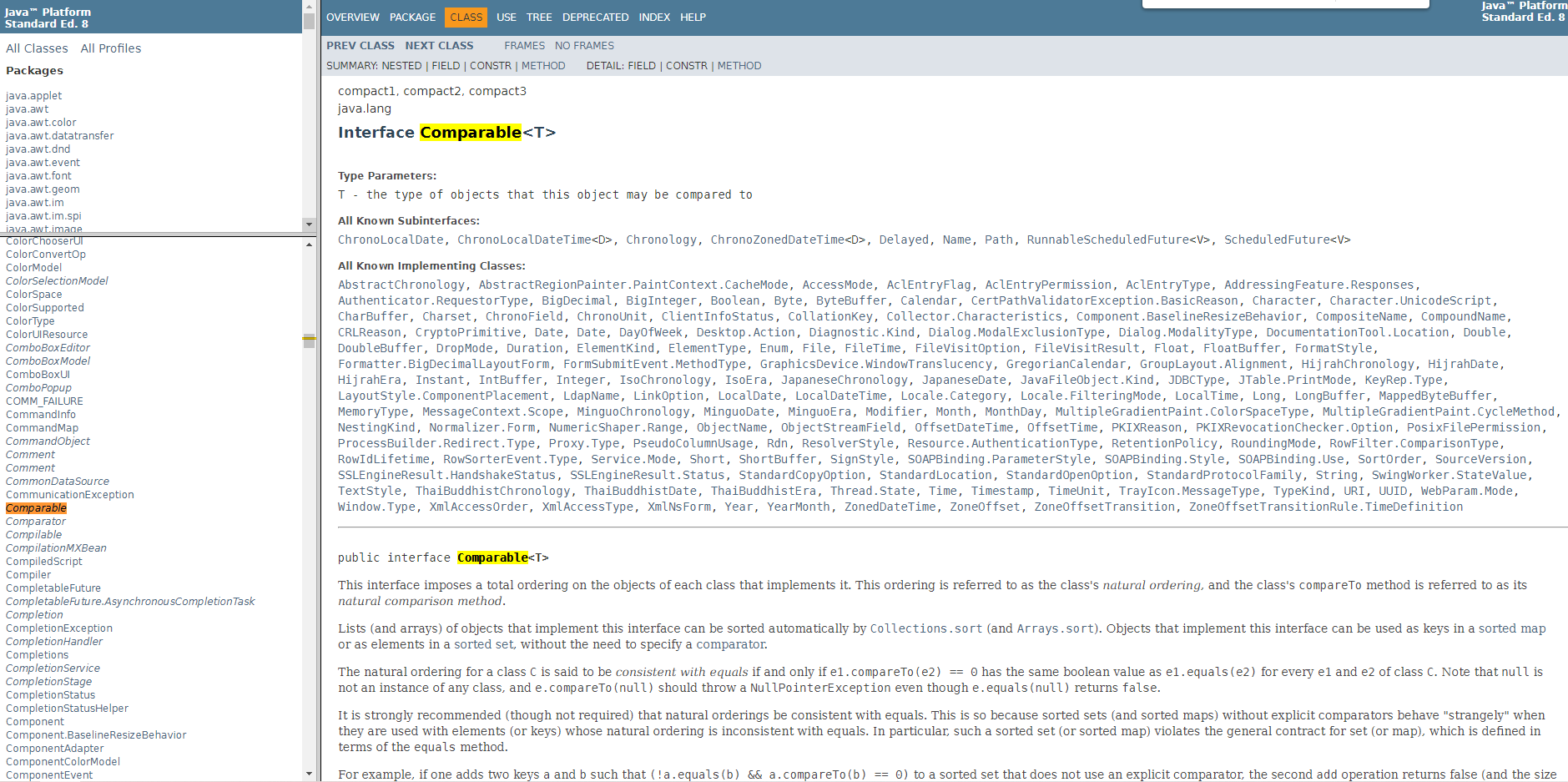
直接写一个小程序,看一下Java中的排序,首先创建一个sort.java的package,然后创建一个Student的Java Class的程序,其中只有学生ID,姓名和年龄,为了方便查看输出,重写一下里面的tostring方法,最后要实现排序的话,要执行Comparable接口,代码如下
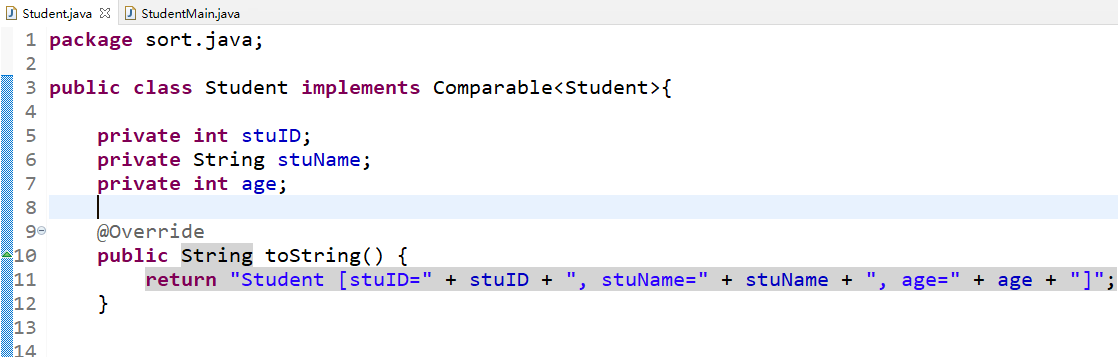
对于get和set方法自动生成,完善接口里面的方法,也就是compareTo方法,指定一下排序的规则,代码如下
@Override
public int compareTo(Student o) {
// 定义排序规则
if(this.age >= o.getAge()) {
return 1;
}else {
return -1;
}
}
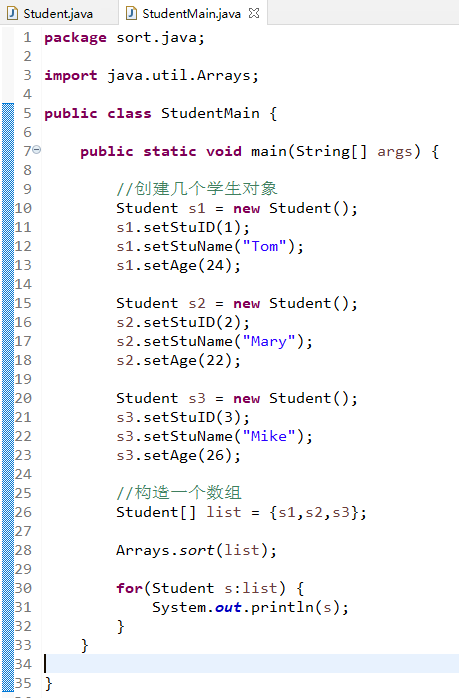
保存文件后,创建一个新的运行主程序,初始化三个学生对象,构造数组,使用sort的方法按照年龄进行排序,代码如下
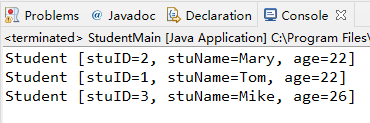
输出结果为:(按照之前重写的tostring方法进行输出,输出的结果也满足按照升序进行排列)

以上是按照单个列的排序,有没有可能按照两个列进行排序呢?答案是肯定可以的,只需要修改一下排序的规则
@Override
public int compareTo(Student o) {
// 定义排序规则
if(this.age > o.getAge()) {
return 1;
}else if(this.age < o.getAge()) {
return -1;
}
if (this.stuID >= o.getStuID()) {
return -1;
}else {
return 1;
}
}
保存后为了显示出排序的作用,把第二个同学的年龄修改为22,再次运行主程序,查看运行结果,可以发现最终是按照年龄进行升序排序的,如果年龄相同的话,就是按照ID进行降序排列
2 MapReduce排序
对于数字的排序默认采用升序,字符串就是按照首字母的字典顺序排序,对象的话就是按照员工的薪水(这里就是举个栗子)
MapReduce中的排序是以k2作为依据,比如WordCount计数中k2就是单词,代表着字符串,就是按照默认的字典顺序,先排大写字母再排小写字母;在进行员工工资求解时候k2为员工编号,最后就是按照数字的升序进行排列
2.1 数字排序
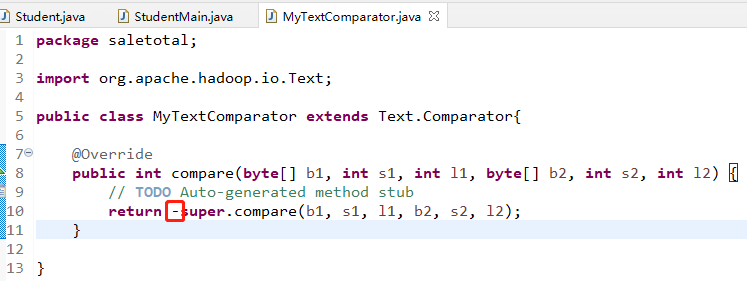
既然是默认的排序规则,自然是可以进行重新设置,进行自定义排序规则,下面针对数字进行自定义排序需要设置一个排序的类(直接继承文本的排序父类,然后重写里面的compare方法,这里就是在return后面添加了一个负号,表示与原来的排序方式相反)
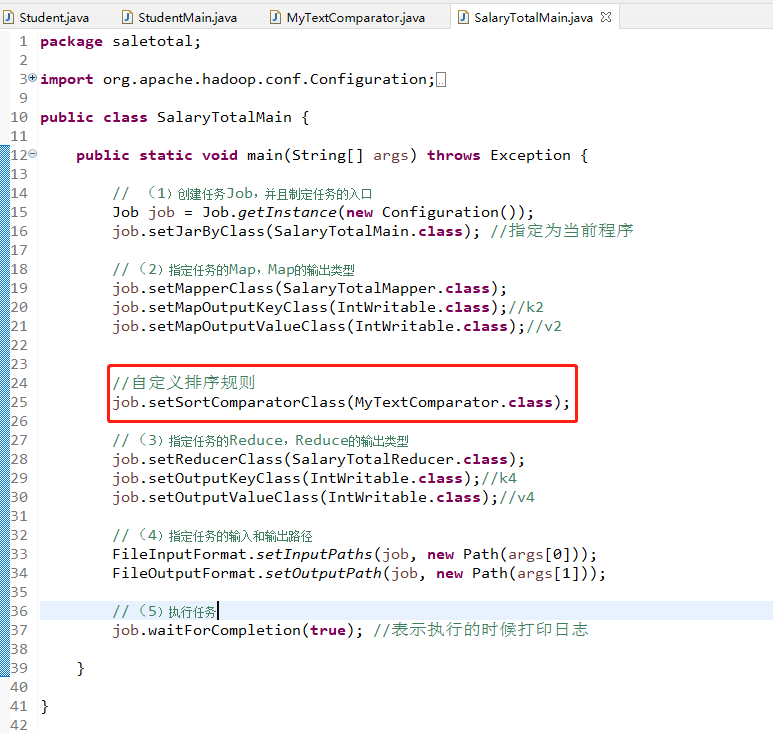
接着就是修改一下主程序里面的内容,将修改后的排序类加载进去,由于MapReduce是对k2进行排序,所以可以放置在k2的内容后面,具体的内容及位置如下
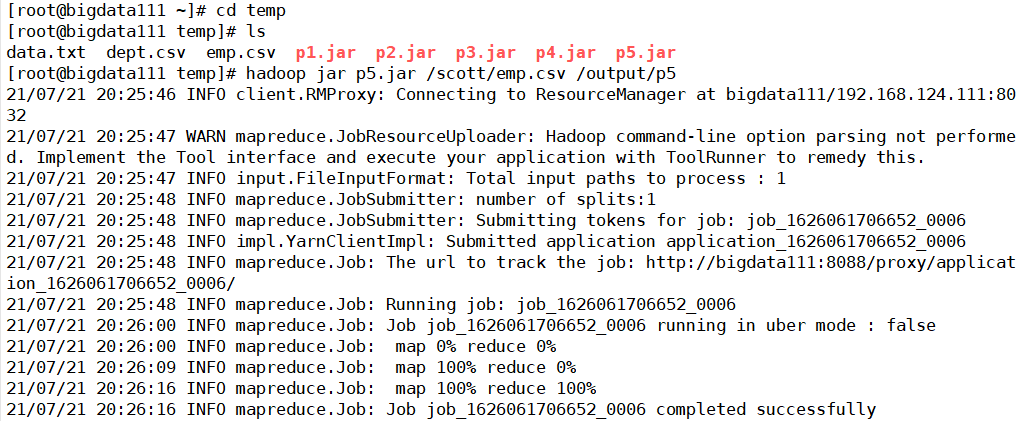
然后将整个代码文件重新打包生成p5.jar,上传至hadoop运行
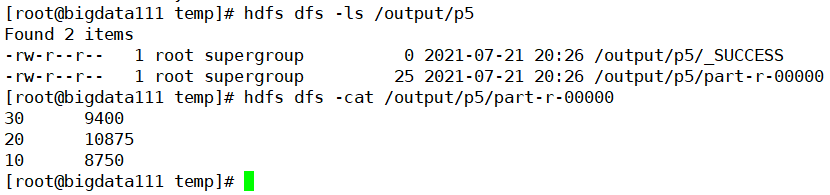
最后就是核实一下生成文件中的数据信息是否为我们期待的样子(很完美,反序过来了)
运行到这里,可以会有点疑问,创建比较器时候的类是继承的Text下面的父类,对应的就是字符串的数据类型,并不是真正的数字类型,这里是因为最终是数值型字符串,最终排序的时候还是以数值的方式进行,可以再重新写一下比较类,使用IntWritable下面的比较类进行
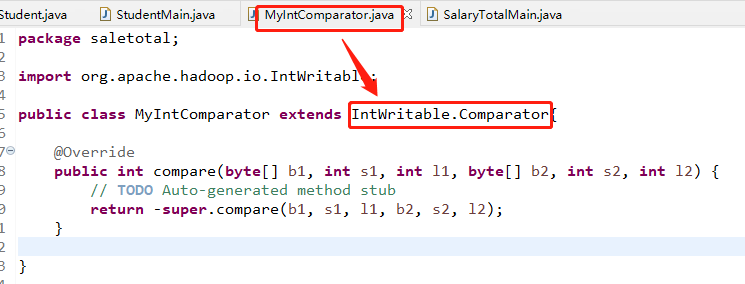
然后再修改一下主程序里面的那个排序代码,如下
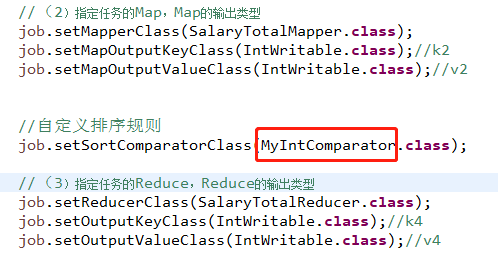
最后打包成jar文件在hadoop上运行,看看结果输出(这次生成的p6.jar文件)
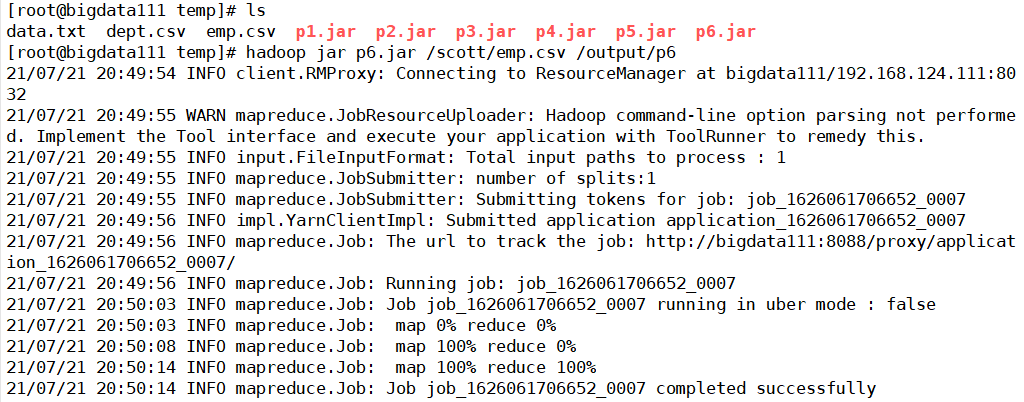
核实一下输出的文件数据信息是否一致(输出结果中是保持一致,没有问题)

2.2 字符串排序
这个就是修改一下WordCount计数程序,其中的k2是字符串数据类型,重新创建一个比较类,重新创建一个文本数据的比较类,名称为MyTextComparator(是在wc的package下面)
package wc;
import org.apache.hadoop.io.Text;
public class MyTextComparator extends Text.Comparator{
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
// TODO Auto-generated method stub
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
然后就是运行的主程序中添加指定的自定义规则(注意这次是WordCount的程序,和之前的代码完全一样,但是在不同文件中)
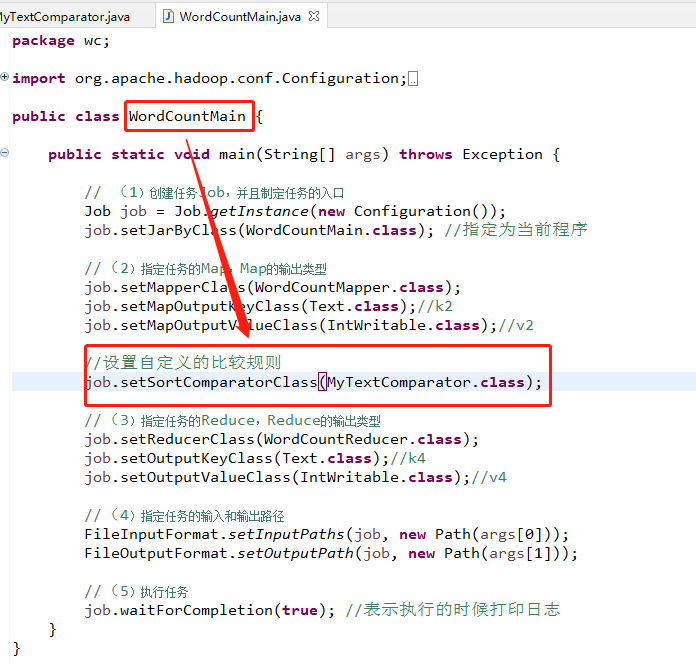
最后导出为p7.jar文件,上传至hadoop上运行
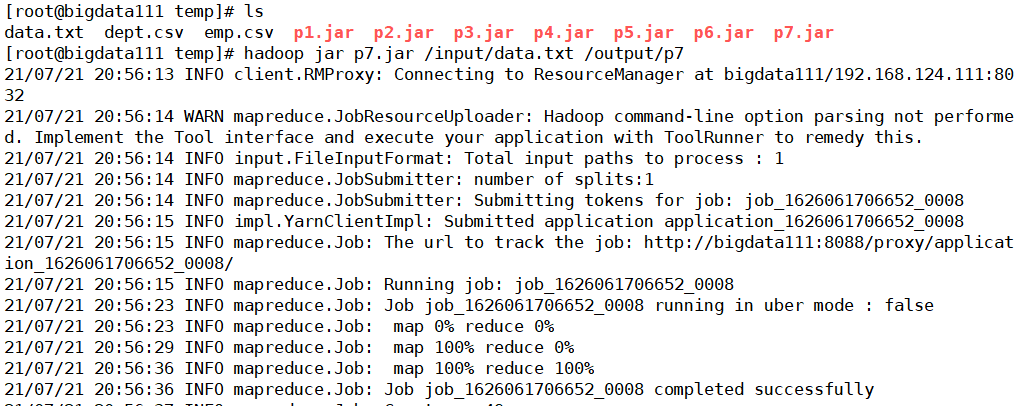
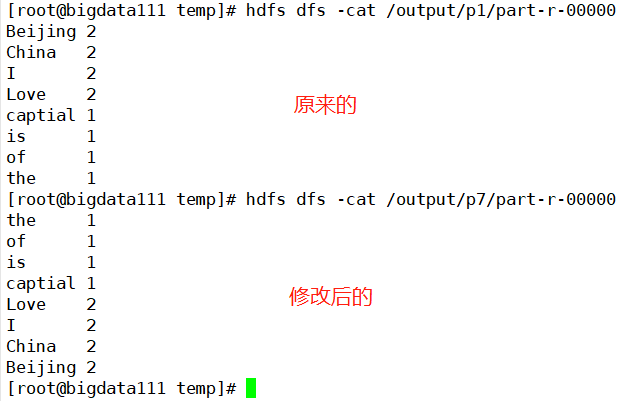
核实一下目标文件夹下的数据信息是够和原来相反(核实无误,啦啦啦~)
2.3 员工对象排序
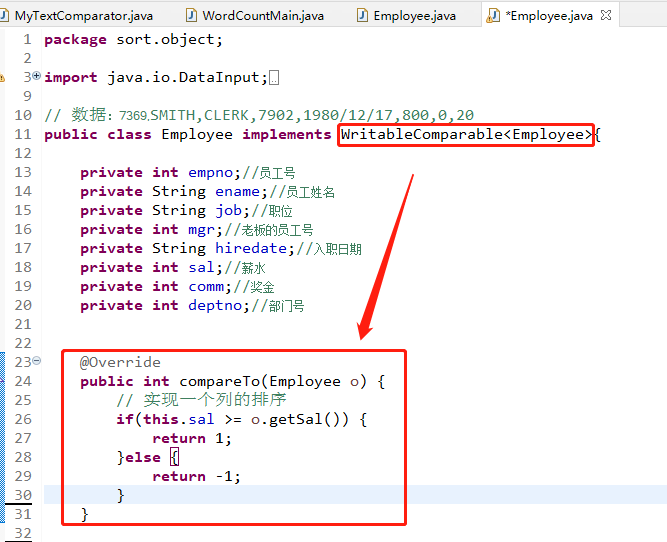
先新建一个package命名为sort.object,再把之前序列化的Employee的类复制粘贴过来,修改一下执行的接口,这里要使用WritableComparable类(光看这个名字就知道,不仅可以实现序列化还可以实现比较的功能),然后重写里面的方法,就是compare方法,具体修改的内容如下
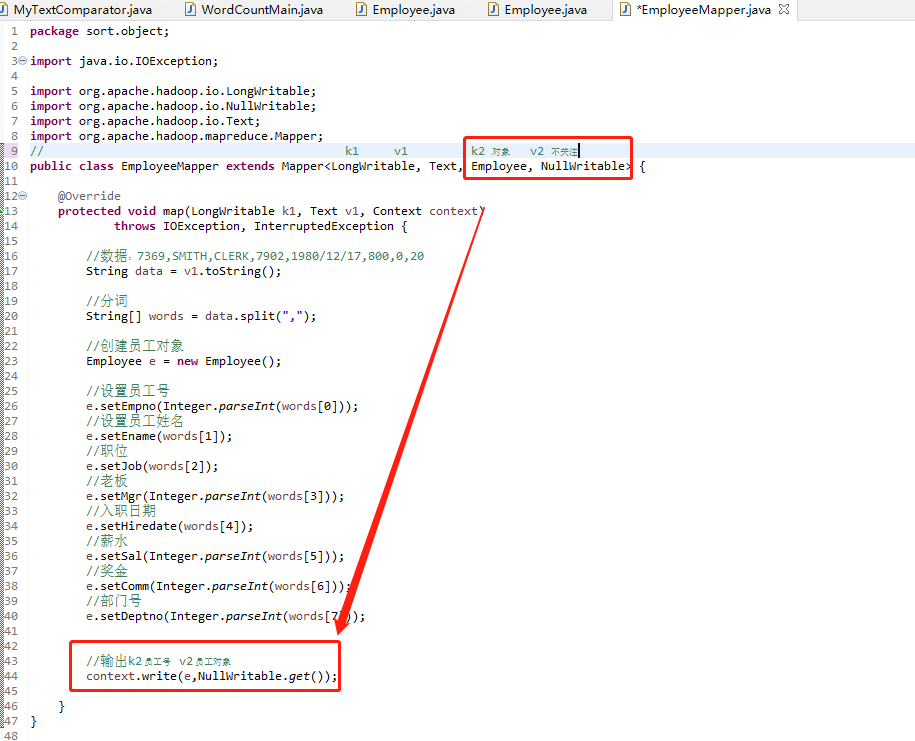
框架中的Map程序也是从之前的地方进行赋值粘贴,同样需要小小的修改,由于是按照对象进行排序,而MapReduce是按照k2进行排序的,所以这里的k2需要修改为员工对象,v2不关注就可以直接设置为空,最后的输出这里也要进行修改
框架中的Reduce可以不用指定,不进行合并运算,直接进行输出,就剩下最后的主程序的设计,还是把之前的程序拿来修改一下(只用修改两处)
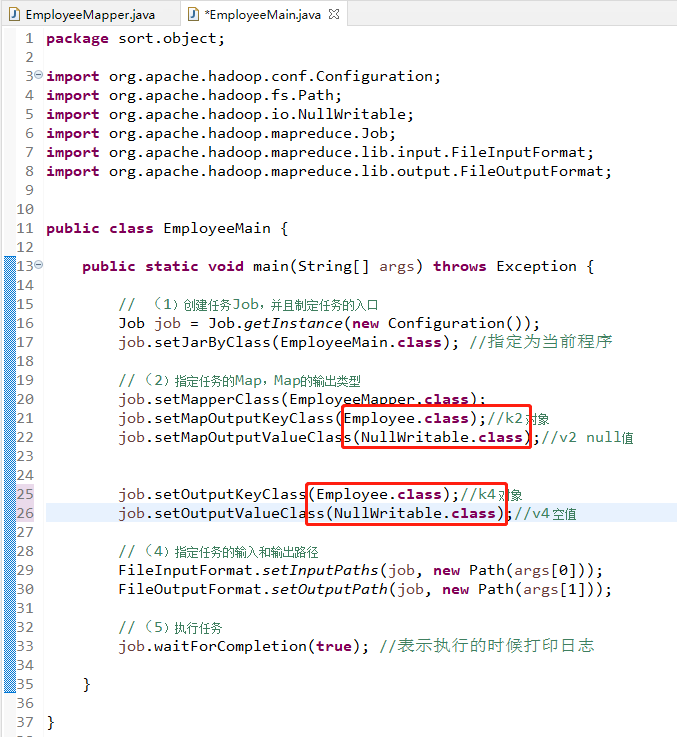
把程序文件都打包为p8.jar文件,上传hadoop上运行
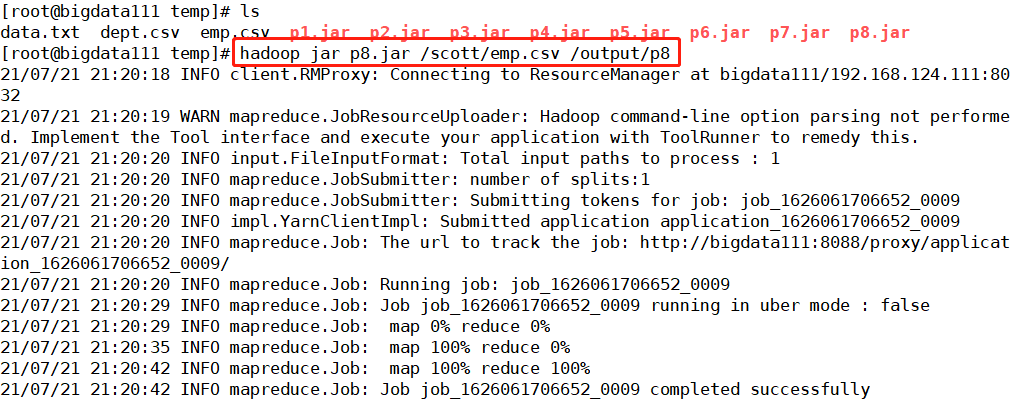
核实一下最终生成的文件中的内容(完美了,顺利完成了,啦啦啦~)

接下来就是进一步的发散,上面的操作是按照一个列进行排序,那么两个列甚至多个列的排序也是有实际需求的,只需要修改一下之前指定的排序方法
@Override
public int compareTo(Employee o) {
if(this.deptno > o.getDeptno()) {
return 1;
}else if (this.deptno < o.getDeptno()) {
return -1;
}
if (this.sal >= o.getSal()) {
return 1;
}else{
return -1;
}
}
其余的保持不变后进行代码的保存,最终生成p9.jar文件,上传至hadoop进行测试
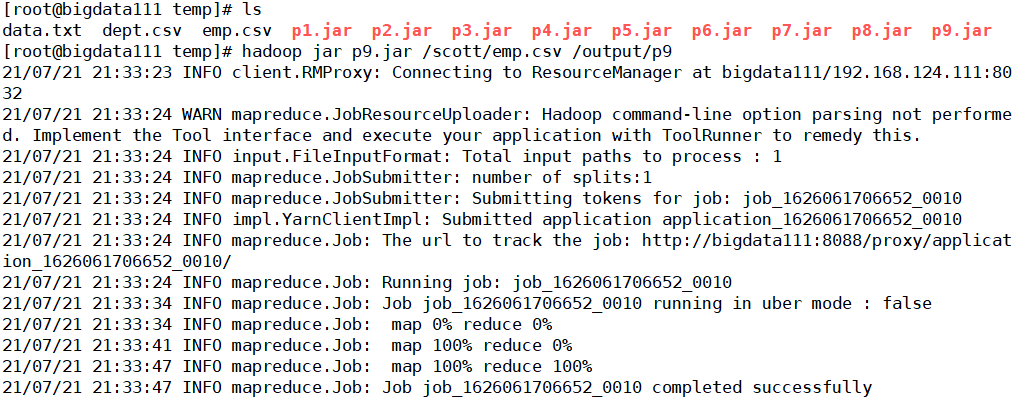
核实一下文件中的信息,并与刚刚的p8处理的结果进行对比

如果要执行降序的排列,直接将排序方法里面return中的1和-1对换一下位置即可,至此关于MapReduce中的数字、字符串和对象的排序就梳理完毕了,完结撒花✿✿ヽ(°▽°)ノ✿