参考:https://blog.csdn.net/hahayikeshu/article/details/103552631
1、airflow
安装
pip install apache-airflow
airflow initdb
airflow scheduler
web端口
----- start the web server, default port is 8080
airflow webserver -p 8080
启动任务
1、把执行py文件拷贝到airflow/dags/下
2、运行任务调度
airflow unpause dag_id 启动
airflow pause dag_id 暂停
unpause相当于在web页面操作点击on、off;红色为失败,黄色为重启中,绿色为执行中,深绿是成功执行完

案例,文件放在/usr/local/airflow/dags下,airflow会自动识别
主要:
1>> scheduler要确保先运行起来,不然后面识别不了taskid和调度不起来
2 >> dags文件产生新的文件保存,可能需要进行权限赋予,sudo chomd 777 dags
3 >> /usr/long.txt '必须使用绝对路径,不然会保存不了
from airflow.models import DAG
from airflow.operators.bash_operator import BashOperator
from datetime import datetime, timedelta
import pytz
#default_args = dict()
import pendulum
tz = pendulum.timezone("Asia/Shanghai")
#tz = pytz.timezone('Asia/Shanghai')
# naive = datetime.strptime("2018-06-13 17:40:00", "%Y-%m-%d %H:%M:%S")
# local_dt = tz.localize(naive, is_dst=None)
# utc_dt = local_dt.astimezone(pytz.utc).replace(tzinfo=None)
dt = datetime(2021, 8, 13, 14, 55, tzinfo=tz)
#utc_dt = dt.astimezone(pytz.utc).replace(tzinfo=None)
default_args = {
'owner': 'airflow',
'start_date': dt,
'depends_on_past': False,
'email': ['1***[email protected]'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=1)
}
#每5分钟执行一次
dag = DAG(dag_id='bash_test',default_args=default_args,schedule_interval='*/5 * * * *')
task_1 = BashOperator(
task_id='bash_1',
bash_command='echo "hello world" >> /usr/long.txt ',
dag=dag
)
#获取参数的值
cmd = """
{% for i in range(4) %}
echo 'hello'
echo '{
{ds}}'
echo '{
{params.my_param}}'
{% endfor %}
"""
task_2 = BashOperator(
task_id='bash_2',
bash_command=cmd,
params={'my_param':'task_2'},
dag=dag
)
task_1.set_downstream(task_2)
SparkSubmitOperator可能出问题,建议使用BashOperator方便
****使用 Jinja 作为模版,可以传参形式:
参考:https://www.thinbug.com/q/42016491
https://airflow.apache.org/docs/apache-airflow/stable/tutorial.html#templating-with-jinja


****依赖关系:
参考:https://cloud.tencent.com/developer/article/1831455
t1.set_downstream(t2)
# 这意味着 t2 会在 t1 成功执行之后才会执行
# 与下面这种写法相等
t2.set_upstream(t1)
# 位移运算符也可用于链式运算
# 用于链式关系 和上面达到一样的效果
t1 >> t2
# 位移运算符用于上游关系中
t2 << t1
# 使用位移运算符能够链接
# 多个依赖关系变得简洁
t1 >> t2 >> t3
# 任务列表也可以设置为依赖项。
# 下面的这些操作都具有相同的效果:
t1.set_downstream([t2, t3])
t1 >> [t2, t3]
[t2, t3] << t1
t2.set_upstream(t1)
t3.set_upstream(t1)
# 等价于 t1 >> [t2, t3]
****airflow cron时间表达式
schedule_interval 是任务时间设定:与Linux cron 时间是不同的
airflow cron 表达式: * * * * * * (分 时 月 年 周 秒)
0 0/1 * * * 每小时
0/50 * * * * 每50分钟
***Trigger DAG 点击是触发重新启动整个task

2、pyspark
窗口函数
参考:https://database.51cto.com/art/202101/639239.htm
https://blog.csdn.net/liuyingying0418/article/details/108025262
**窗口函数最后结果总行数不会变
# spark = SparkSession.builder.appName('Window functions').getOrCreate()
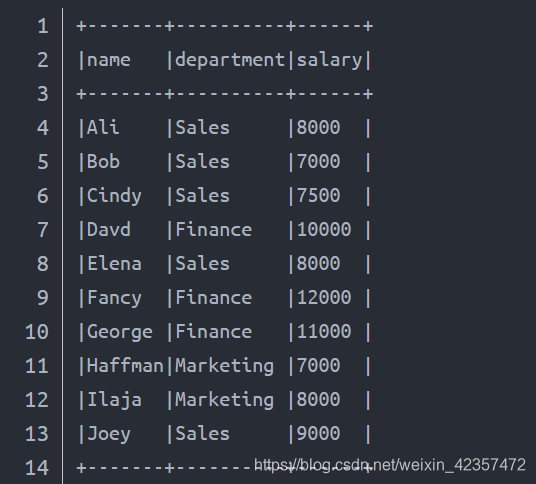
employee_salary = [
("Ali", "Sales", 8000),
("Bob", "Sales", 7000),
("Cindy", "Sales", 7500),
("Davd", "Finance", 10000),
("Elena", "Sales", 8000),
("Fancy", "Finance", 12000),
("George", "Finance", 11000),
("Haffman", "Marketing", 7000),
("Ilaja", "Marketing", 8000),
("Joey", "Sales", 9000)]
columns= ["name", "department", "salary"]
df = spark.createDataFrame(data = employee_salary, schema = columns)
df.show(truncate=False)
窗口函数格式:
from pyspark.sql.window import Window
import pyspark.sql.functions as F
windowSpec = Window.partitionBy("department").orderBy(F.desc("salary"))
df.withColumn("row_number", F.row_number().over(windowSpec)).show(truncate=False)

udf函数
udf:
# udf cid+vendor
def new_cid(col1, sidx1, res1):
if col1 == "p1":
ress = eval(res1)[int(sidx1)]
newcid = str(ress[0]) + str(ress[1])
return newcid
else:
ress = eval(res1)[int(sidx1)]
newcid = str(ress[0]) + str(ress[1])
return newcid
cid_udf = F.udf(new_cid, StringType())
df = df.withColumn("new_cid", cid_udf("pageid", "sidx", "results"))

pandas_udf
参考:https://blog.csdn.net/weixin_42902669/article/details/104677557
https://blog.csdn.net/weixin_40161254/article/details/91548469
注意:
1)pandas_udf 传入和返回都是pd series格式
2)pandas_udf 传入的是batch数据,不是一条一条的内容
from pyspark.sql.functions import pandas_udf, PandasUDFType
df = spark.createDataFrame([(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],("id", "v"))
def subtract_mean(pdf):
v = pdf.v
return pdf.assign(v=v - v.mean())
sub_spark = pandas_udf(f=subtract_mean, returnType="id long, v double", functionType=PandasUDFType.GROUPED_MAP)
df.groupby("id").apply(sub_spark).show()
from pyspark.sql.functions import pandas_udf,PandasUDFType
from pyspark.sql.types import IntegerType,StringType
slen=pandas_udf(lambda s:s.str.len(),IntegerType())
@pandas_udf(StringType())
def to_upper(s):
return s.str.upper()
@pandas_udf(IntegerType(),PandasUDFType.SCALAR)
def add_one(x):
return x+1
df = spark.createDataFrame([(1, "John Doe", 21)], ("id", "name", "age"))
df.select(slen("name").alias("slen(name)"), to_upper("name"), add_one("age")).show()
df.withColumn('slen(name)',slen("name")).show()

3、spark提交集群任务
spark-submit提交任务集群计算:
nohup spark-submit --conf spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC --conf spark.yarn.executor.memoryOverhead=6G --conf spark.debug.maxToStringFields=100 --master yarn --deploy-mode cluster --executor-memory 4G - -executor-cores 6 --driver-memory 8G User***Play.py
查看集群执行log:
yarn logs -applicationId applic******id值**0_77969