六、线程池
我们先了解一个整个线程池的执行流程,类似于生产者消费者模式

分析大致流程:主线程生产task(任务),如果阻塞队列不满就放入阻塞队列,否则当前线程进入waitSet等待,但是这种等待对于主线程是不利的,因为这样的话它会一直无限期的等,我们可以通过设置超时等待,或添加拒绝策略,来解决这个问题!其次就是线程池中会有多个线程,线程调用任务前判断,任务队列中的任务是否为空,如果为空则等待,否则线程获取任务执行,任务是线程安全的保证了一个任务只能由一个线程去执行!
以后可以尝试,手写一个线程池
ThreadPoolExecutor
我们JDK自带的线程池

1、线程池的状态
ThreadPoolExecutor使用int的高三位表示线程池的状态,低29位表示线程数量

注意:从数字上比较TERMINATED > TIDYING > STOP > SHUTDOWN > RUNNING ,高三位中的第一位表示符号,0表示正,1表示负
为什么线程池的状态和数量要用一个整数的不同位表示?
因为这些信息存储在一个原子变量ctl中,目的是将线程池状态与线程个数合二为一,这样就可以用一次cas原孔操作进行赋值,如果开2个原子变量分别存储就是需要两次cas操作 ;
// c为旧值,ct1of返回结果为新值 , 目的是为了合并我们的状态和数量
ctl.compareAndSet(c, ctlof(targetstate,workerCountOf( c))));
// rs为高3位代表线程池状态,wc为低29位代表线程个数,ctl是合并它们
private static int ctlof(int rs, int wc) {
return rs | wc; } //由于是不同位,进行或运算就是合并
2、构造方法 *
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
线程池的七大参数
- corePoolSize核心线程数目(最多保留的线程数)
- maximumPoolSize最大线程数目
- keepAliveTime生存时间-针对救急线程(没活做的话,能存活的时间)
- unit时间单位-针对救急线程
- workQueue阻塞队列
- thread Factory 线程工厂-可以为线程创建时起个好名字(线程池中创建线程的名字规则)
- handler拒绝策略
工作方式 : JDK中的线程池ThreadPoolExecutor中的线程被分为:核心线程和救急线程
初始化一个线程池

两个核心线程分别处理2个任务,任务1、任务2,阻塞队列再存放两个任务:任务3、任务4,由于救急线程的存在,救急线程会直接执行第5个任务, 任务5插队处理,得到如下:

但是需要注意的是我们的救急线程是有生存时间的,时间已过就会结束(不忙了就结束!) ;
JDK自带线程池的特点 ;
- 线程池中刚开始没有线程,当一个任务提交给线程池后,线程池会创建一个新线程来执行任务。
- 当线程数达到corePoolSize并没有线程空闲,这时再加入任务,新加的任务会被加入workQueue队列排队,直到有空闲的线程。
- 如果队列选择了有界队列(有界队列表示的是我们的线程池中的线程有数量限制,无界表示无数量限制),那么任务超过了队列大小时,会创建maximumPoolSize - corePoolSize数目的线程来救急。
- 我们的拒绝策略是在我们没有救急线程可用的情况下才会执行的 ;
JDK自带线程池的四种拒绝策略

- AbortPolicy 让调用者抛出RejectedExecutionException异常,这是默认策略
- CallerRunsPolicy 让调用者运行任务
- DiscardPolicy放弃本次任务
- DiscardOldestPolicy放弃阻塞队列中最早的任务,本任务取而代之I
3、Executors工具类
提供快速创建线程池的方法
1) newFixedThreadPool
创建固定大小的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
//接收整型的线程数
return new ThreadPoolExecutor(nThreads(核心线程数), nThreads(最大线程数),
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
//由于救急线程数 = 最大线程数 - 核心线程数 ,我们可以得出救急线程数为0 ,创建固定大小的线程池中不含救急线程
特点:
- 没有救急线程被创建,因此无需超时时间
- 阻塞队列LinkedBlockingQueue是无界的,可以存放任意数量的任务
评价
- 适用于任务量已知,相对耗时的任务
2)newCachedThreadPool
带缓冲线程池
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0(最小核心线程数), Integer.MAX_VALUE(最大线程数),
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
特点:
核心线程数是0,最大线程数是Integer.MAX_VALUE,救急线程的空闲生存时间是60s,意味着
- 全部都是救急线程(60s 后可以回收)
- 救急线程可以无限创建
- 队列采用了SynchronousQueue实现特点是,它没有容量,没有线程来取是放不进去的(一手交钱、一手交货)
评价:
- 适合于线程数比较大,任务时间较短
3)newSingleThreadExecutor
单线程线程池
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
特点:
希望多个任务排队执行。线程数固定为1(线程池中只有一个线程),任务数多于1时,会放入无界队列排队。任务执行完毕,这唯一的线程也不会被释放。
线程池中只含有一个线程相比于我们一个线程有什么好处?
如果我们只有单一的一个线程的话,如果线程意外停止,后续任务无法执行,而如果是含有一个线程线程池,出现这种情况,我们的线程池会再创建一个线程继续执行任务,会保证线程池中始终有一个存活的线程!
4、执行任务
线程池执行任务 : execute | submit | invokeAll | invoke Any
1、void execute(Runnable command); //线程池调用任务,无序返回值
2、<T> Future<T> submit(Callable<T> task); //线程池调用任务,需要返回值
3、<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) // 线程池执行多个任务
4 <T> T invokeAny(Collection<? extends Callable<T>> tasks //执行多个任务,但是其中有一个任务执行完成后,值返回给
throws InterruptedException, ExecutionException; //future,线程池不再执行
测试:线程池执行单个任务
//线程池执行单个任务
public class LongAdderTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(2); //创建一个线程池
//future相当于之前的guardedObject会接收线程池中的线程执行完任务的返回值!
Future<String> future = fixedThreadPool.submit(new Callable<String>() {
@Override
public String call() throws Exception {
Thread.sleep(1000);
return "OK";
}
});
System.out.println(future.get()); // OK
}
}
5、关闭线程池
1、shutdown
- 线程池进入SHUTDOWN状态
- 线程池中和阻塞队列中的任务会继续执行
2、shutdownNow
- 线程池进入STOP状态
- 会中断线程池中正在执行的线程,而且会抛弃阻塞队列中的线程
6、创建多少线程池合适
- 不能过大,上下文切换浪费时间,占用更多的内存 ;
- 不能过小,造成CPU资源浪费,容易导致饥饿 ;
6.1 CPU 密集型运算
通常采用cpu核数+1能够实现最优的CPU利用率,+1是保证当线程由于页缺朱故障(操作系统)或其它原因导致暂停时,额外的这个线程就能顶上去,保证CPU时钟周期不被浪费
6.2 I/O密集型运算
CPU不总是处于繁忙状态,例如,当你执行业务计算时,这时候会使用CPU资源,但当你执行ⅣO操作时、远程RPC调用时,包括进行数据库操作时,这时候CPU就闲下来了,你可以利用多线程提高它的利用率。
经验公式如下
线程数 = 核数 * 期望cpu利用率 * 总时间(cpu计算时间+等待时间) / CPU计算时间
例如 : 4核CPU计算时间是50%,其它等待时间是.50%,期望cpu被100%利用,套用公式
4 * 100% * 100% / 50% = 8
ScheduleThreadPoolExecutor
任务调度线程池 ,可以延时执行任务、定时执行任务
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(2); //创建任务调度线程池
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
// 任务调度线程池构造方法
return new ScheduledThreadPoolExecutor(corePoolSize);
}
延时、定时执行任务
schedule
public ScheduledFuture<?> schedule(Runnable command,
long delay, TimeUnit unit); // delay 延时执行时间
//这个样线程池中的多个线程都延时执行是互不干扰的
scheduleAtFixedRate
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,
long initialDelay, //初始延迟时间
long period, //任务间隔时间,重复执行(类似定时)
TimeUnit unit);
//但是这种情况如果任务出现异常或阻塞的情况下, ;
比如在任务1中执行Thread.sleep(2000)阻塞2s,而我们设置任务的间隔时间为1s,这样的话我们的任务会在2s后再次执行,也类似串行执行(在一个任务完成后,再次执行这个任务)
scheduleWithFixedDelay
public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,
long initialDelay, //初始延时
long delay, //延时重复执行
TimeUnit unit);
//这个就是我们这个任务执行完成后,在经过一个delay时间再次执行
注:jdk1.3之前采用的是Timer,可以实现同样的延时执行,但是timer最大的缺陷在于只能在一个线程中延时执行 ;
正确处理异常
1、传统的遇到异常,主动的去try catch 处理一下 ;
2、使用Futrue保存线程执行任务返回的结果 ,如果中途出现异常,future保存的 不是结果,而是异常信息
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(1);
Future<Boolean> future = fixedThreadPool.submit(new Callable<Boolean>() {
@Override
public Boolean call() throws Exception {
System.out.println("任务1执行....");
// int i = 2 / 0 ; 如果存在结果返回异常信息,不存在结果就返回true
return true;
}
});
System.out.println(future.get()); // 返回ture | 异常信息
}
线程池应用—定时任务
通过线程池实现定时任务
/*
* 如何让每周四定时执行任务
* */
@SuppressWarnings("All")
public class Test {
public static void main(String[] args) {
LocalDateTime now = LocalDateTime.now(); //获取当前时间JDK1.8开始的
LocalDateTime time = now.withHour(18).withMinute(0).withSecond(0).withNano(0).with(DayOfWeek.THURSDAY);//获取本周四的时间 ,
// 这里需要注意如果当前时间 < 周四,直接用 , 如果当前时间 > 周四,求下一周四的时间
if(now.compareTo(time) > 0){
time = time.plusWeeks(1) ;
}
//initaildelay 当前时间到周四的时间差值(毫秒数)
long initaildelay = Duration.between(now,time).toMillis() ;
//period 一周的时间间隔
long period = 1000 * 60 *60 * 24 *7 ;
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1); // 创建任务调度线程池
pool.scheduleAtFixedRate(()->{
//定时任务内容
}, initaildelay, period ,TimeUnit.MILLISECONDS );
}
}
Tomcat线程池
Tomcat的哪里用到线程池了呢?

- LimitLatch用来限流,可以控制最大连接个数,类似J.U.C中的 Semaphore后面再讲
- Acceptor 只负责【接收新的socket连接】
- Poller 只负责监听socket channel是否有【可读的IO事件】
- 一旦可读,封装一个任务对象(socketProcessor),提交给Executor线程池处理
- Executor线程池中的工作线程最终负责【处理请求】
Tomcat线程池扩展了ThreadPoolExecutor,行为稍有不同
- 如果总线程数达到maximumPoolSize
- 这时不会立刻抛RejectedExecutionException异常(拒绝策略)
- 而是再次尝试将任务放入队列,如果还失败,才抛出RejectedExecutionException异常
Tomcat配置
Connector配置 (连接器配置)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tI7dscoj-1634809307568)(JUC并发编程.assets/image-20211017164140647.png)]](https://img-blog.csdnimg.cn/7a72b63161a149269f77a37b90a2dc1d.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA54iq5rS8aW5n,size_20,color_FFFFFF,t_70,g_se,x_16)
Executor配置 (线程池配置,会覆盖上面连接器中的线程池配置)

相对于普通的线程池子,tomcat线程池做的优化是
优化一:核心线程被用光了,那么就创建救急线程,如果 核心线程+救急线程的总线程数达到最大线程数,那么就是将任务放到队列中
优化二:tomcat线程池中的线程是守护线程,而且队列是无界队列
Fork/join线程池
概念
- Fork/Join是JDK 1.7加入的新的线程池实现,它体现的是一种分治思想,适用于能够进行任务拆分的cpu密集型运算
- 所谓的任务拆分,是将一个大任务拆分为算法上相同的小任务,直至不能拆分可以直接求解。跟递归相关的一些计算,如归并排序、斐波那契数列、都可以用分治思想进行求解
- Fork/Join在分治的基础上加入了多线程,可以把每个任务的分解和合并交给不同的线程来完成进—步提升了运算效率
- Fork/Join默认会创建与cpu核心数大小相同的线程池
七、 J.U.C并发工具包
AQS原理 *
1、什么是AQS
- AQS,全程AbstractQueuedSynchronizer,位于java.util.concurrent.locks包下。
- 是JDK1.5提供的一套用于实现阻塞锁和一系列依赖FIFO等待队列的同步器(First Input First Output先进先出)的框架实现。是除了java自带的synchronized 关键字之外的锁机制。 可以将AQS作为一个队列来理解
- 我们常用的ReentrantLock、Semaphore、CountDownLatch、CyclicBarrier等并发类均是基于AQS来实现的。具体用法是通过继承AQS,并实现其模板方法,来达到同步状态的管理。
AQS的功能在使用中可以分为两种:独占锁和共享锁
- 独占锁:每次只能有一个线程持有锁。eg: ReentrantLock就是独占锁
- 共享锁:允许多个线程同时获得锁,并发访问共享资源。eg: ReentrantReadWriteLock中的读锁、CountDownL.atch
理解:
同步器是实现锁(也可以是任意同步组件)的关键,在锁的实现中聚合同步器,利用同步器实现锁的语义。可以这样理解二者的关系:锁是面向使用者,它定义了使用者与锁交互的接口,隐藏了实现细节;同步器是面向锁的实现者,它简化了锁的实现方式,屏蔽了同步状态的管理,线程的排队,等待和唤醒等底层操作。锁和同步器很好的隔离了使用者和实现者所需关注的领域
例如:我们的ReentrantLock是我们使用者关注的、里面的同步器(sync继承AQS)是实现者所需关注的领域
2、自定义一个锁
package com.aqs;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.AbstractQueuedSynchronizer;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
public class AqsTest {
public static void main(String[] args) {
MyLock lock = new MyLock();
Thread t1 = new Thread(() -> {
lock.lock();
try{
System.out.println("加锁成功!");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}finally {
System.out.println("解锁成功!");
lock.unlock();
}
}, "t1");
Thread t2 = new Thread(() -> {
lock.lock();
try{
System.out.println("加锁成功!");
}finally {
System.out.println("解锁成功!");
lock.unlock();
}
}, "t2");
t1.start();
t2.start();
}
}
//自定义锁(不可重入锁)
class MyLock implements Lock{
//同步器(独占锁)
class MySync extends AbstractQueuedSynchronizer{
@Override
protected boolean tryAcquire(int arg) {
//尝试获取锁
if (compareAndSetState(0,1)){
//原子修改state属性,获取锁将其状态由0——>1
setExclusiveOwnerThread(Thread.currentThread()); //获取锁后,当前线程获得锁
return true ;
}
return false ;
}
@Override
protected boolean tryRelease(int arg) {
//尝试获取锁
setExclusiveOwnerThread(null); // 当前锁的拥有者设为null
setState(0); //将锁的状态修改为0,释放锁,只有获取锁才能释放,所以不会有其他线程干扰
// (此处考虑到state是volatile修饰的,产生一个写屏障,保证之前的代码不会被指令重排序)
return true ;
}
@Override
protected boolean isHeldExclusively() {
//是否持有独占锁
return getState() == 1 ; //state状态 == 1 表示持有锁
}
public Condition newCondition(){
return new ConditionObject() ;
}
}
private MySync sync = new MySync() ;
@Override
public void lock() {
//加锁
sync.acquire(1);
}
@Override
public void lockInterruptibly() throws InterruptedException {
//加锁,是可打断的!
sync.acquireInterruptibly(1);
}
@Override
public boolean tryLock() {
//尝试加锁(一次)
return sync.tryAcquire(1);
}
@Override
public boolean tryLock(long time, TimeUnit unit) throws InterruptedException {
//尝试加锁(带超时时间)
return sync.tryAcquireNanos(1,unit.toNanos(time));
}
@Override
public void unlock() {
//释放锁
// sync.tryRelease(1); //tryRelease不会唤醒阻塞中的线程
sync.release(1) ; //Release会唤醒阻塞中的线程
}
@Override
public Condition newCondition() {
//创建条件变量
return sync.newCondition();
}
}
就是自定义的锁本质还是内部类中继承的AQS中的方法,其自身只是提供一个对外的接口
ReentrantLock原理 *

由于ReentrantLock支持非公平锁和公平锁
1、非公平锁原理
先从构造器开始看,默认是非公平锁的实现方式
public ReentrantLock() {
sync = new NonfairSync();
}
NonfairSync非公平继承自AQS
没有竞争的时候

第一个竞争出现的时候,去竞争锁,执行以下代码

static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
final void lock() {
if (compareAndSetState(0, 1)) //Thread1尝试修改,但是由于cas修改失败
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1); //再次尝试获取锁
}
public final void acquire(int arg) {
if (!tryAcquire(arg) && //再次获取一次锁失败,执行与后边的代码
acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) // 将线程1作为Node节点添加到队列acquireQueued当中
selfInterrupt();
}

其中的Dummy表示哑元,只占位并不关联线程!
2、可重入原理
//源代码
//尝试获取锁
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
//如果获取了锁,线程还是当前线程那么表示锁重入发生
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
//尝试释放锁
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
//只有当state == 0的时候,才会释放锁,唤醒其他线程才有意义!
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
//总结:锁重入几次,就必须得释放几次,当前线程才能完全释放锁,才能唤醒其他线程!
3、可打断原理
不可打断模式
在此模式下,即使它被打断,仍会驻留在AQS队列中,等获得锁后方能继续运行(是继续运行!只是打断标记被设置为true)
可打断模式
4、公平锁原理
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
acquire(1);
}
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() && //先去检查AQS队列当中是否包含前驱节点,没有才去竞争
// 就是队列里边有线程,让队列里得先执行(先来后到)
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
- 非公平锁底层使用的是
NonfairSync,公平锁底层调用的是FairSync - 两者的流程基本一致,唯一的区别是
C A S执行前,多了一步hasQueuedPredecessors函数判断
区别:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aj5EPIDU-1634809307569)(JUC并发编程.assets/image-20211018220204868.png)]](https://img-blog.csdnimg.cn/2148019a7fa14d6fa373b581f4b6f748.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA54iq5rS8aW5n,size_20,color_FFFFFF,t_70,g_se,x_16)
5、条件变量的实现原理
每个条件变量对应着一个等待队列类似于一个WaitSet,对应实现类是ConditionalObject
1、await流程
开始Thread-0持有锁,调用ConditionObject(类似WaitSet)的await方法,进入ConditionObject的addConditionWaiter流程创建新的Node状态为-2 r(Node.CONDITION),关联 Thread-0,加入等待队列尾部

接下来进入AQS的fully Release流程,释放同步器上的锁

unpark (唤醒)AQS队列中的下一个节点,竞争锁,假设没有其他竞争线程,那么Thread-1竞争成功

流程结束 ;
思考:步骤中为什么使用fullyRelease,而非tryRelease ?
当一个线程获取对象锁多次,这时调用awiat,当前线程会释放对象锁,必须要释放完,不然线程在AQS队列,对象锁的owner还是这个线程,矛盾了
2、signal流程
假设Thread-1要唤醒Thread-0

进入ConditionObject的doSignal流程,取得等待队列中第一个Node(队首,而非随机唤醒),即 Thread-0 所在Node

执行transferForSignal流程,将该Node加入AQS队列尾部,将Thread-0的 waitStatus改为0,Thread-3的 waitStatus改为-1

Thread-0释放锁,结束
ReentrantReadWriteLock读写锁 *
让读操作和写操作分开处理 ;我们读操作是不会修改数据的,所以我们提供读操作可以并发,提高效率!
- 读写锁指一个资源能够被多个读线程访问,或者被一个写线程访问,但是不能同时存在读写线程
- ReentrantReadWriteLock中有两个静态内部类:ReadLock读锁和WriteLock写锁,这两个锁实现了Lock接口ReentrantReadWriteLock支持可重入,同步功能依赖自定义同步器(AbstractQueuedSynchronizer)实现,读写状态就是其同步器的同步状态
写锁的获取和释放
写锁WriteLock是支持重进入的排他锁。如果当前线程已经获取了写锁,则增加写状态。如果当前线程在获取读锁时,读锁已经被获取或者该线程不是已获取写锁的线程,则当前线程进入等待状态。读写锁确保写锁的操作对读锁可见。写锁释放每次减少写状态,当前写状态为0时表示写锁已背释放。
读锁的获取与释放
读锁ReadLock是支持重进入的共享锁(共享锁为shared节点,对于shared节点会进行一连串的唤醒,知道遇到一个读节点),它能够被多个线程同时获取,在没有其他写线程访问(写状态为0)时,读锁总是能够被成功地获取,而所做的也只是增加读状态(线程安全)。如果当前线程已经获取了读锁,则增加读状态。如果当前线程在获取读锁时,写锁已经被获取,则进入等待状态
锁降级
- 锁降级指的是写锁降级成为读锁。锁降级是指当前拥有的写锁的同时,再获取到读锁,随后释放写锁的过程
结论 :
- 读读是并发的,支持锁重入
- 读写是互斥的
- 写写是互斥的,但是支持锁重入
以下测试用以证明
package com.aqs;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/*
* 结论 : 读读是并发的
* 读写是互斥的
* 写写是互斥的
*/
//读写锁测试
public class ReentrantReadWriteLockTest {
public static void main(String[] args) {
DataContainer container = new DataContainer();
Thread t1 = new Thread(() -> {
container.read(); //读
},"t1");
Thread t2 = new Thread(() -> {
container.write(); //读
},"t2");
t1.start();
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.start();
}
}
class DataContainer{
private Object data ;
private ReentrantReadWriteLock rw = new ReentrantReadWriteLock() ;
private ReentrantReadWriteLock.ReadLock r = rw.readLock() ; //读锁
private ReentrantReadWriteLock.WriteLock w = rw.writeLock() ; //写锁
public Object read() {
System.out.println("正在加读锁、、");
r.lock(); //加读锁
try{
System.out.println("读取");
Thread.sleep(1000);
return data ;
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("正释放读锁、、");
r.unlock();
}
return null ;
}
public void write(){
System.out.println("正在加写锁、、");
w.lock();
try{
System.out.println("写入");
}finally {
System.out.println("正在释放写锁、、");
w.unlock();
}
}
}
读写锁再缓存上的应用
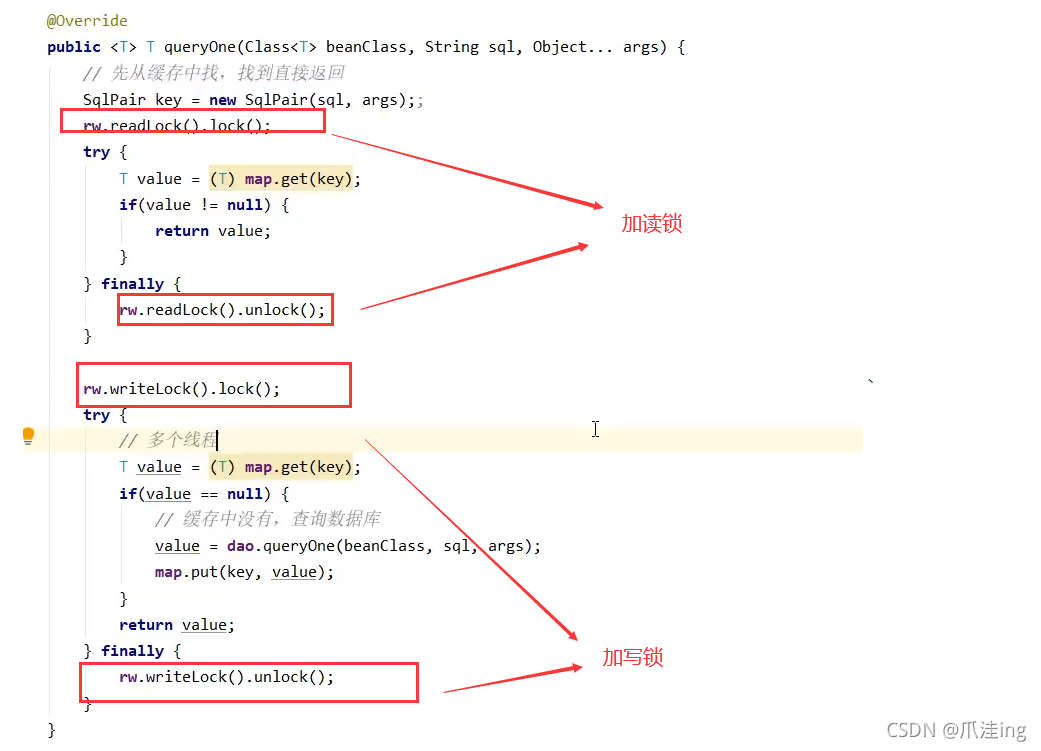
如下两个操作 :
- 查询操作: 先去缓存查、再去数据库查询
- 修改操作:先清空缓存、在更新数据库数据

缓存更新策略
更新时,是先清缓存还是先更新数据库 ?
1、如果先清缓存

发生问题:线程B先执行修改操作,同时线程A执行查询操作,当线程B将缓存清空后,还未更新数据库,这时线程A去查询数据,先去缓存,发现缓存没有,去数据库查询,查到了并将查到的target = 1放入缓存,接着再次查询target一直就是1了,而此时线程B修改target成功,target = 2 ,线程A查询到的还时旧的数据(查询的很长一段时间都是旧的数据)!
2、先更新数据库
虽然也有错误,但是想读先清缓存还好一点

这种情况下,线程B先行将数据库中的数据更新,还未来得及啊清空缓存,此时线程A来查询了,查询的还是之前缓存中的数据,但是很快的线程B会清空缓存,线程A再查就会发现缓存中旧数据没了,就得查数据库了,然后更新缓存!
为了彻底解决上述数据不一致的问题我们可以通过加锁解决 ;(虽然性能会低一些,但是解决了数据的一致性)
但是我们可以通过读写锁ReentrantReadWriteLock,我们可以使得性能不像其他锁一样,性能低那么多!

注意:
以上实现体现的是读写锁的应用,保证缓存和数据库的一致性,但有下面的问题没有考虑·
- 适合读多写少,如果写操作比较频繁,以上实现性能低
- 没有考虑缓存容量
- 没有考虑缓存过期·只适合单机
- 并发性还是低,目前只会用一把锁
- 更新方法太过简单粗暴,清空了所有key (考虑按类型分区或重新设计ke y)
读写锁原理 *
说是读写锁,但是锁内部用的是一个sync同步器,因此AQS等待队列和State也是同一个!
t1 w.lock,t2 r.lock
1、 t1成功上锁,流程与ReentrantLock加锁相比没有特殊之处,不同是写锁状态占了state的低16位,而读锁使用的是state的高16位

关于state的总结 :
- 当state == 0 ,即高低位都是0,没有线程占用锁 ;
- 当state == 1,即为高位为1或低位为1,线程占用读锁或写锁中的一个 ;
- 当state > 1 , 表示的时发生了多个线程占用读锁,或者一个线程占用多次读锁(锁重入) ;
2、 t2执行r.lock,这时进入读锁的sync.acquireShared(1)流程,首先会进入tryAcquireShared流程。如果有写锁占据,那么tryAcquireShared返回-1表示失败tryAcquireShared返回值表示
- -1 表示失败
- 0 表示成功,但后继节点不会继续唤醒
- 正数表示成功,而且数值是还有几个后继节点需要唤醒,读写锁返回1

StampedLock
我们读写锁的可以读读并发,相对重量级锁已经很快了,但是我们每次读都会通过cas操作增加读状态,导致我们并不能进行写操作!因此我们为了进一步优化读性能,所以从JDK8k开始引入StampedLock 它的特点是在使用读锁、写锁时都必须配合【戳】使用
StampedLock 支持 tryOptimisticRead() 方法(乐观读),读取完毕后需要做一次 戳校验 如果校验通过,表示这期间确实没有写操作,数据可以安全使用,如果校验没通过,需要重新获取读锁,保证数据安全。StampedLock采取乐观获取锁后,其他线程尝试获取写锁时不会被阻塞(可以解决读写锁,锁饥饿问题)
总结:引入一个戳,这个戳有一个检验的作用,如果检验出当前只有读操作,我们不加锁!
Semaphore 信号量
[ˈseməfɔː ( r )] , 设置能同时访问共享资源的线程上限
package com.aqs;
import java.util.concurrent.Semaphore;
public class SemaphoreTest {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(3); // permits : 表示许可多个线程,能同时访问共享资源,
// bool fair : 表示的是公平、非公平
//10个线程同时运行
for (int i = 0; i < 10 ; i++) {
new Thread(()->{
try {
semaphore.acquire(); //获得许可
} catch (InterruptedException e) {
e.printStackTrace();
try{
System.out.println("running..");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
} // sleeper(1)
System.out.println("end..");
}finally {
semaphore.release(); //释放许可
}
}).start();
}
}
} //结论 : 我们10个线程只有前3个启动,等3个执行结束后,接着再来3个启动
Semphore的应用
- 使用Semaphore限流,在访问高峰期时,让请求线程阻塞,高峰期过去再释放许可,当然它只适合限制单机线程数量,并且仅是限制线程数,而不是限制资源数(例如连接数,请对比Tomcat LimitLatch的实现)
- 用Semaphore 实现简单连接池,对比『享元模式』下的实现(用wait notify),性能和可读性显然更好,注意下面的实现中线程数和数据库连接数是相等的
场景1:我们可以使得许可数 == 数据库连接池的大小(poolSize) ,每次获取连接就会获取许可,许可用完就不能获取链接!
一个固定长度的资源池,当池为空时,请求资源会失败。使用 Semaphore可以实现当池为空时,请求会阻塞,非空时解除阻塞。也可以使用Semaphore将任何一种容器变成有界阻塞容器
public class SemaphoreDemo {
public static void main(String[] args) {
// 创建一个无界线程池
ExecutorService exec = Executors.newCachedThreadPool();
// 配置只能5个线程同时访问
final Semaphore semaphore = new Semaphore(3);
// 模拟10个客户端访问
for (int i = 0; i < 5; i++) {
int num = i;
Runnable task = (() ->{
try {
// 获取许可
semaphore.acquire();
System.out.println("获得许可: " + num);
//休眠随机秒(表示正在执行操作)
TimeUnit.SECONDS.sleep((int)(Math.random()*10+1));
// 访问完后,释放许可
semaphore.release();
// availablePermits()指还剩多少个许可
System.out.println("----------当前还有多少个许可:" + semaphore.availablePermits());
} catch (InterruptedException e) {
e.printStackTrace();
}
});
exec.execute(task);
}
// 退出线程池
exec.shutdown();
}
}
Semphore原理 *
Semaphore有点像一个停车场,permits 就好像停车位数量,当线程获得了permits 就像是获得了停车位,然后停车场显示空余车位减一 .
刚开始,permits (state)为3,这时5个线程来获取资源

假设其中 Thread-1,Thread-2,Thread-4 cas竞争成功,而Thread-0和Thread-3竞争失败,进入AQS队列park阻塞

这时Thread-4释放了permits,状态如下

接下来Thread-0竞争成功,,permits再次设置为0,设置自己为head 节点,断开原来的head节点,unpark 接下来的Thread-3节点,但由于permits是0,因此Thread-3在尝试不成功后再次进入park状态

CountdownLatch倒计时锁
我们创建一个倒计时锁,初始化一个值,表示等待值,每有一个线程访问,我们值就减去1,减到0后,等待结束
基本使用
public class CountdownLatchTest {
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(3);
//三个线程启动
new Thread(()->{
System.out.println(Thread.currentThread().getName() + "开始执行!");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
countDownLatch.countDown();
System.out.println(Thread.currentThread().getName()+ "结束执行!");
}).start();
new Thread(()->{
System.out.println(Thread.currentThread().getName() + "开始执行!");
try {
Thread.sleep(1500);
} catch (InterruptedException e) {
e.printStackTrace();
}
countDownLatch.countDown();
System.out.println(Thread.currentThread().getName()+ "结束执行!");
}).start();
new Thread(()->{
System.out.println(Thread.currentThread().getName() + "开始执行!");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
countDownLatch.countDown();
System.out.println(Thread.currentThread().getName()+ "结束执行!");
}).start();
countDownLatch.await(); // 一主线程陷入等待,直到count减为0了为止!
System.out.println("主线程可以运行!");
}
}
- 我们之前学过join,也可以完成,但是join属于底层API使用起来相对繁琐。而且对于使用线程池中的线程,就不能使用join等待线程结束了,程池中的线程一直运行,基本不会结束!所以就永远等不完 hh
应用:等待多线程准备完毕 *
模拟一个王者荣耀游戏加载界面
public class CountdownLatchTest02 {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(10);
ExecutorService pool = Executors.newFixedThreadPool(10);
Random random = new Random(); //随机数
String[] all = new String[10] ;
for (int j = 0; j < 10 ; j ++) {
int k = j ;
pool.submit(()->{
for (int i = 1; i <= 100 ; i++) {
try {
Thread.sleep(random.nextInt(200));
} catch (InterruptedException e) {
e.printStackTrace();
} //sleeper(1)
all[k] = i + "%" ;
System.out.print("\r" + Arrays.toString(all)); //不换行 + "\r" 可以做到替换上一个输出
}
latch.countDown(); //latch的技术减1
});
}
latch.await();
System.out.println("\n所有玩家准备完毕,游戏开始!");
pool.shutdown(); //关闭线程池
}
}
运行结果

直接模拟游戏加载!
CycliBarrier
循环栅栏,用来解决CountdownLatch无法解决的重复利用倒计时锁问题!
CyclicBarrier也叫同步屏障,CyclicBarrier可以协同多个线程,让多个线程在这个屏障前等待,直到所有线程都达到了这个屏障时,再一起继续执行后面的动作。构造时设置『计数个数』,每个线程执行到某个需要“同步”的时刻调用 await() 方法进行等待,等待数+1,当等待的线程数满足『计数个数』时,继续执行
区别:CycliBarrier根CountdownLatch大体相似,但是我们的后者一旦初始化倒计时就不可更改,而我们的的前者可以恢复如初!
- CountDownLatch:一个或者多个线程,等待其他多个线程完成某件事情之后才能执行;
- CyclicBarrier:多个线程互相等待,直到到达同一个同步点,再继续一起执行。而且可以重用
CountDownLatch是计数器,线程完成一个记录一个,只不过计数不是递增而是递减,而CyclicBarrier更像是一个阀门,需要所有线程都到达,阀门才能打开,然后继续执行。
@Slf4j(topic = "c.TestCyclicBarrier")
public class TestCyclicBarrier {
public static void main(String[] args) {
ExecutorService service = Executors.newFixedThreadPool(2);
// 注意:线程数和CyclicBarrier的计数相同才会到达预期的效果
CyclicBarrier barrier = new CyclicBarrier(2, ()-> {
log.debug("task1, task2 finish...");
});// 可以重复被使用,当计数变为0之后,会重新恢复为2
for (int i = 0; i < 3; i++) {
// task1 task2 task1
service.submit(() -> {
log.debug("task1 begin...");
sleep(1);
try {
barrier.await(); // 2-1=1
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
});
service.submit(() -> {
log.debug("task2 begin...");
sleep(2);
try {
barrier.await(); // 1-1=0
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
});
}
service.shutdown();
}
}

八、线程安全集合类

重点介绍java.util.concurrent.*下的线程安全集合类,可以发现它们有规律,里面包含三类关键词:Blocking、CopyOnWrite、Concurrent
Concurrent【重点】
内部很多操作使用cas 优化,一般可以提供较高吞吐量-弱一致性,性能虽然很高,但是仍然存在一些缺点 :
- 遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍历,这时内容是旧的
- 求大小弱一致性,size操作未必是100%准确·读取弱一致性
ConcurrentHashMap *
computeIfAbsent方法
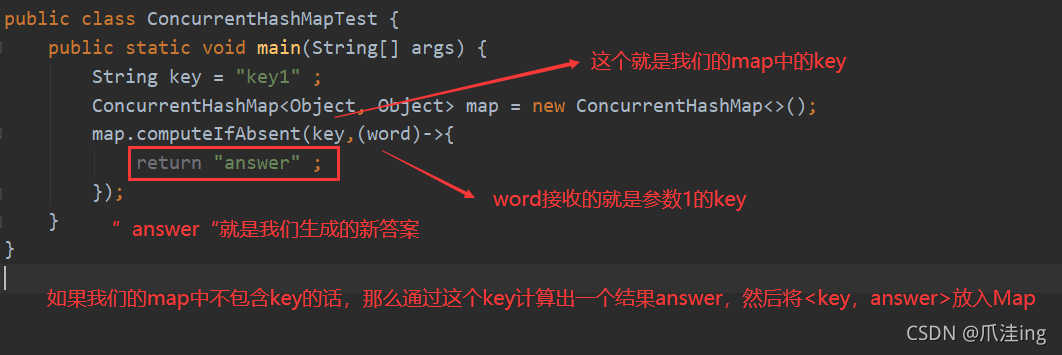
首先提以下 Java8关于ConcurrentHashMap引入新的方法computeIfAbsent,为了保证原子性!
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction)
实战测试:
public class ConcurrentHashMapTest {
public static void main(String[] args) {
String key = "key1" ;
ConcurrentHashMap<Object, Object> map = new ConcurrentHashMap<>();
map.computeIfAbsent(key,(word)->{
return "answer" ;
});
}
}
对该方法做一个分析 ;
这个方法代替的是
int newValue = 1 ;
Object key1 = map.get(key); //获取key
if (key1 == null){
//key为null,得出新的结果
newValue += 1 ;
}
map.put(key,newValue) ; //放入新的k,v
我们的map中的get,put虽然是线程安全的,但是组合起来并不一定!所以引入这个方法,因为一个方法肯定能保障了原子性!
HashMap并发扩容死链问题
只有JDK1.7才会存在这种情况,JDK8修改了扩容算法!
问:多线程下使用HashMap会有什么缺陷?
答:除了不是线程安全的类外,在JDK1.7的情况下存在并发死链问题 , 但是这种死链情况在JDK1.8已经不见了,虽然修复这个问题但是还是存在其他线程安全的问题!
下篇ConcurrentHashMap的原理以及源码分析 !