1. Redis介绍
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如
字符串(strings),散列(hashes),列表(lists),集合(sets),有序集合(sorted sets) 与范围查询, bitmaps,hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了复制(replication),LUA脚本(Lua scripting),LRU驱动事件(LRU eviction),事务(transactions)和不同级别的 磁盘持久化(persistence), 并通过==Redis哨兵(Sentinel)和自动分区(Cluster)==提供高可用性(high availability)
1.1 特点
- 内存数据库,速度快,也支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等多种数据结构的存储。
- Redis支持数据的备份(master-slave)与集群(分片存储),以及拥有哨兵监控机制。
- 支持事务
1.2 优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持
Strings、Lists、Hashes、Sets、Sorted Sets等数据类型操作。 - 原子操作 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。(事务)
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等特性。
1.3 Redis、Memcached、Ehcache的区别
| Ehcache | Memcached | Redis | |
|---|---|---|---|
| 最新版本 | 见官网 | 见官网 | 见官网 |
| 许可证 | free | free | free |
| 实现语言 | Java | C | C |
| 服务器系统 | 有jvm的系统 | FreeBSD,Linux,OS X,Unix,Windows | FreeBSD,Linux,OS X,Unix,Windows |
| 数据类型 | 支持 | 不支持 | 支持多重string,hash,list,set,sorted set 等 |
| 客户端语言 | Java | Net,C,C++,ColdFusion,Erlang,Java,Lisp,Lua,Ocaml,Perl,PHP,Python,Ruby | C,C#,C++,D,Erlang,Go,Haxe,Java,Node.js,Lisp,Lua,MatLab,Objective-C,Pascal,Perl,PHP,R,Ruby,Scala,Swift,Visual Basic等30多种 |
这三个中间件都可以应用于缓存,但目前市面上使用Redis的场景会更多,更广泛,其原因是:Redis性能高、原子操作、支持多种数据类型,主从复制与哨兵监控,持久化操作等。
2. Redis的高并发
官方的
bench-mark数据:测试完成了50个并发执行100000个请求。设置和获取的值是一个256字节字符串。结果:读的速度是110000次/s,写的速度是81000次/s。redis尽量少写多读,符合缓存的适用要求。单机redis支撑万级,如果10万+可以采用主从复制的模式。
2.1 原理
-
Redis是纯内存数据库,一般都是简单的存取操作,线程占用的时间很多,时间的花费主要集中在IO上,所以读取速度快。
-
Redis使用的是非阻塞IO,IO多路复用,使用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,减少了线程切换时上下文的切换和竞争。
-
Redis采用了单线程的模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
-
Redis存储结构多样化,不同的数据结构对数据存储进行了优化,如压缩表,对短数据进行压缩存储,再如,跳表,使用有序的数据结构加快读取的速度。
-
Redis采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能力比较大。
2.2 Redis的单线程
原因
1)不需要各种锁的性能消耗
Redis的数据结构并不全是简单的Key-Value,还有list,hash等复杂的结构,这些结构有可能会进行很细粒度的操作,比如在很长的列表后面添加一个元素,在hash当中添加或者删除一个对象。这些操作可能就需要加非常多的锁,导致的结果是同步开销大大增加。总之,在单线程的情况下,就不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
2)单线程多进程集群方案

单线程的威力实际上非常强大,每核心效率也非常高,多线程自然是可以比单线程有更高的性能上限,但是在今天的计算环境中,即使是单机多线程的上限也往往不能满足需要了,需要进一步摸索的是多服务器集群化的方案,这些方案中多线程的技术照样是用不上的。
3)CPU消耗
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU。但是如果CPU成为Redis瓶颈,或者不想让服务器其他CPU核闲置,那怎么办?可以考虑多起几个Redis进程,Redis是key-value数据库,不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个Redis进程上就可以了。
优劣
单进程单线程优势
- 代码更清晰,处理逻辑更简单
- 不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
- 不存在多进程或者多线程导致的切换而消耗CPU
单进程单线程弊端
- 无法发挥多核CPU性能,不过可以通过在单机开多个Redis实例来完善
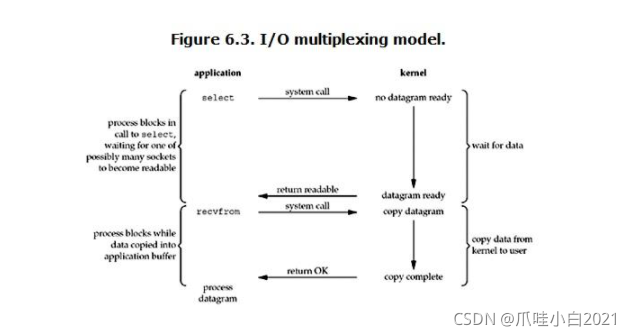
IO多路复用技术
redis 采用网络IO多路复用技术来保证在多连接的时候, 系统的高吞吐量。
多路-指的是多个socket连接,复用-指的是复用一个线程。多路复用主要有三种技术:select,poll,epoll。epoll是最新的也是目前最好的多路复用技术。
这里 多路 指的是多个网络连接,复用指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
3. Redis软件安装
第一步:下载安装包
下载地址:https://redis.io/download,一般下载稳定版(Stable),截止目前为止最新版是6.0
1.Redis2.6
Redis2.6在2012年正是发布,经历了17个版本,到2.6.17版本,相对于Redis2.4,主要特性如下:
1)服务端支持Lua脚本。
2)去掉虚拟内存相关功能。
3)放开对客户端连接数的硬编码限制。
4)键的过期时间支持毫秒。
5)从节点支持只读功能。
6)两个新的位图命令:bitcount和bitop。
7)增强了redis-benchmark的功能:支持定制化的压测,CSV输出等功能。
8)基于浮点数自增命令:incrbyfloat和hincrbyfloat。
9)redis-cli可以使用–eval参数实现Lua脚本执行。
10)shutdown命令增强。
11)重构了大量的核心代码,所有集群相关的代码都去掉了,cluster功能将会是3.0版本最大的亮点。
12)info可以按照section输出,并且添加了一些统计项
13)sort命令优化
2.Redis2.8
Redis2.8在2013年11月22日正式发布,经历了24个版本,到2.8.24版本,相比于Redis2.6,主要特性如下:
1)添加部分主从复制的功能,在一定程度上降低了由于网络问题,造成频繁全量复制生成RDB对系统造成的压力。
2)尝试性的支持IPv6.
3)可以通过config set命令设置maxclients。
4)可以用bind命令绑定多个IP地址。
5)Redis设置了明显的进程名,方便使用ps命令查看系统进程。
6)config rewrite命令可以将config set持久化到Redis配置文件中。
7)发布订阅添加了pubsub。
8)Redis Sentinel第二版,相比于Redis2.6的Redis Sentinel,此版本已经变成生产可用。
3.Redis3.0(里程碑)
Redis3.0在2015年4月1日正式发布,相比于Redis2.8主要特性如下:
Redis最大的改动就是添加Redis的分布式实现Redis Cluster。
1)Redis Cluster:Redis的官方分布式实现。
2)全新的embedded string对象编码结果,优化小对象内存访问,在特定的工作负载下载速度大幅提升。
3)Iru算法大幅提升。
4)migrate连接缓存,大幅提升键迁移的速度。
5)migrate命令两个新的参数copy和replace。
6)新的client pause命令,在指定时间内停止处理客户端请求。
7)bitcount命令性能提升。
8)cinfig set设置maxmemory时候可以设置不同的单位(之前只能是字节)。
9)Redis日志小做调整:日志中会反应当前实例的角色(master或者slave)。
10)incr命令性能提升。
4.Redis3.2
Redis3.2在2016年5月6日正式发布,相比于Redis3.0主要特征如下:
1)添加GEO相关功能。
2)SDS在速度和节省空间上都做了优化。
3)支持用upstart或者systemd管理Redis进程。
4)新的List编码类型:quicklist。
5)从节点读取过期数据保证一致性。
6)添加了hstrlen命令。
7)增强了debug命令,支持了更多的参数。
8)Lua脚本功能增强。
9)添加了Lua Debugger。
10)config set 支持更多的配置参数。
11)优化了Redis崩溃后的相关报告。
12)新的RDB格式,但是仍然兼容旧的RDB。
13)加速RDB的加载速度。
14)spop命令支持个数参数。
15)cluster nodes命令得到加速。
16)Jemalloc更新到4.0.3版本。
5.Redis4.0
可能出乎很多的意料,Redis3.2之后的版本是4.0,而不是3.4、3.6、3.8。
一般这种重大版本号的升级也意味着软件或者工具本身发生了重大改革。下面是Redis4.0的新特性:
1)提供了模块系统,方便第三方开发者拓展Redis的功能。
2)PSYNC2.0:优化了之前版本中,主从节点切换必然引起全量复制的问题。
3)提供了新的缓存剔除算法:LFU(Last Frequently Used),并对已有算法进行了优化。
4)提供了非阻塞del和flushall/flushdb功能,有效解决删除了bigkey可能造成的Redis阻塞。
5)提供了memory命令,实现对内存更为全面的监控统计。
6)提供了交互数据库功能,实现Redis内部数据库的数据置换。
7)提供了RDB-AOF混合持久化格式,充分利用了AOF和RDB各自优势。
8)Redis Cluster 兼容NAT和Docker。
6.Redis5.0
1)新的Stream数据类型。[1]5.0
2)新的Redis模块API:Timers and Cluster API。
3)RDB现在存储LFU和LRU信息。
4)集群管理器从Ruby(redis-trib.rb)移植到C代码。可以在redis-cli中。查看redis-cli —cluster help了解更多信息。
5)新sorted set命令:ZPOPMIN / MAX和阻塞变量。
6)主动碎片整理V2。
7)增强HyperLogLog实现。
8)更好的内存统计报告。
9)许多带有子命令的命令现在都有一个HELP子命令。
10)客户经常连接和断开连接时性能更好。
11)错误修复和改进。
12)Jemalloc升级到5.1版
6.Redis6.0
1)多线程IO。Redis 6引入多线程IO。但多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。之所以这么设计是不想因为多线程而变得复杂,需要去控制 key、lua、事务,LPUSH/LPOP 等等的并发问题。
2)重新设计了客户端缓存功能。实现了Client-side-caching(客户端缓存)功能。放弃了caching slot,而只使用key names。
Redis server-assisted client side caching
3)RESP3协议。RESP(Redis Serialization Protocol)是 Redis 服务端与客户端之间通信的协议。Redis 5 使用的是 RESP2,而 Redis 6 开始在兼容 RESP2 的基础上,开始支持 RESP3。
推出RESP3的目的:一是因为希望能为客户端提供更多的语义化响应,以开发使用旧协议难以实现的功能;另一个原因是实现 Client-side-caching(客户端缓存)功能。
4)支持SSL。连接支持SSL,更加安全。
5)ACL权限控制
-
支持对客户端的权限控制,实现对不同的key授予不同的操作权限。
-
有一个新的ACL日志命令,允许查看所有违反ACL的客户机、访问不应该访问的命令、访问不应该访问的密钥,或者验证尝试失败。这对于调试ACL问题非常有用。
6)提升了RDB日志加载速度。根据文件的实际组成(较大或较小的值),可以预期20/30%的改进。当有很多客户机连接时,信息也更快了,这是一个老问题,现在终于解决了。
7)发布官方的Redis集群代理模块 Redis Cluster proxy。在 Redis 集群中,客户端会非常分散,现在为此引入了一个集群代理,可以为客户端抽象 Redis 群集,使其像正在与单个实例进行对话一样。同时在简单且客户端仅使用简单命令和功能时执行多路复用。
8)提供了众多的新模块(modules)API
第二步:上传至服务器
或者 wget 远程下载。
wget -P /usr/local/src/ https://download.redis.io/releases/redis-6.0.9.tar.gz
第三步:解压
tar -zxvf redis-6.0.9.tar.gz
第四步:安装依赖
yum -y install gcc-c++ autoconf automake
升级GCC
这里需要说明一下:在编译 Redis 6 之前需要升级 gcc 的版本,默认情况 yum 安装的 gcc 版本是 4.8.5,如下图:
由于版本过低,在编译时会报如下错误(部分截取)。
server.c: 在函数‘call’中:
server.c:3247:11: 错误:‘struct redisServer’没有名为‘fixed_time_expire’的成员
server.fixed_time_expire++;
^
In file included from server.h:63:0,
from server.c:30:
server.c:3251:26: 错误:‘struct redisServer’没有名为‘monitors’的成员
if (listLength(server.monitors) &&
^
adlist.h:57:25: 附注:in definition of macro ‘listLength’
#define listLength(l) ((l)->len)
^
server.c:3252:16: 错误:‘struct redisServer’没有名为‘loading’的成员
!server.loading &&
......
server.c:5169:176: 错误:‘struct redisServer’没有名为‘maxmemory’的成员
serverLog(LL_WARNING,"WARNING: You specified a maxmemory value that is less than 1MB (current value is %llu bytes). Are you sure this is what you really want?", server.maxmemory);
^
server.c:5172:31: 错误:‘struct redisServer’没有名为‘server_cpulist’的成员
redisSetCpuAffinity(server.server_cpulist);
^
server.c: 在函数‘hasActiveChildProcess’中:
server.c:1476:1: 警告:在有返回值的函数中,控制流程到达函数尾 [-Wreturn-type]
}
^
server.c: 在函数‘allPersistenceDisabled’中:
server.c:1482:1: 警告:在有返回值的函数中,控制流程到达函数尾 [-Wreturn-type]
}
^
server.c: 在函数‘writeCommandsDeniedByDiskError’中:
server.c:3790:1: 警告:在有返回值的函数中,控制流程到达函数尾 [-Wreturn-type]
}
^
server.c: 在函数‘iAmMaster’中:
server.c:4964:1: 警告:在有返回值的函数中,控制流程到达函数尾 [-Wreturn-type]
}
^
make[1]: *** [server.o] 错误 1
make[1]: 离开目录“/root/redis-6.0.5/src”
make: *** [all] 错误 2
所以我们需要执行以下操作升级 GCC
# 安装 scl 源
yum install -y centos-release-scl scl-utils-build
# 安装 9 版本的 gcc、gcc-c++、gdb 工具链(toolchian)
yum install -y devtoolset-9-toolchain
# 临时覆盖系统原有的 gcc 引用
scl enable devtoolset-9 bash
# 查看 gcc 当前版本
gcc -v
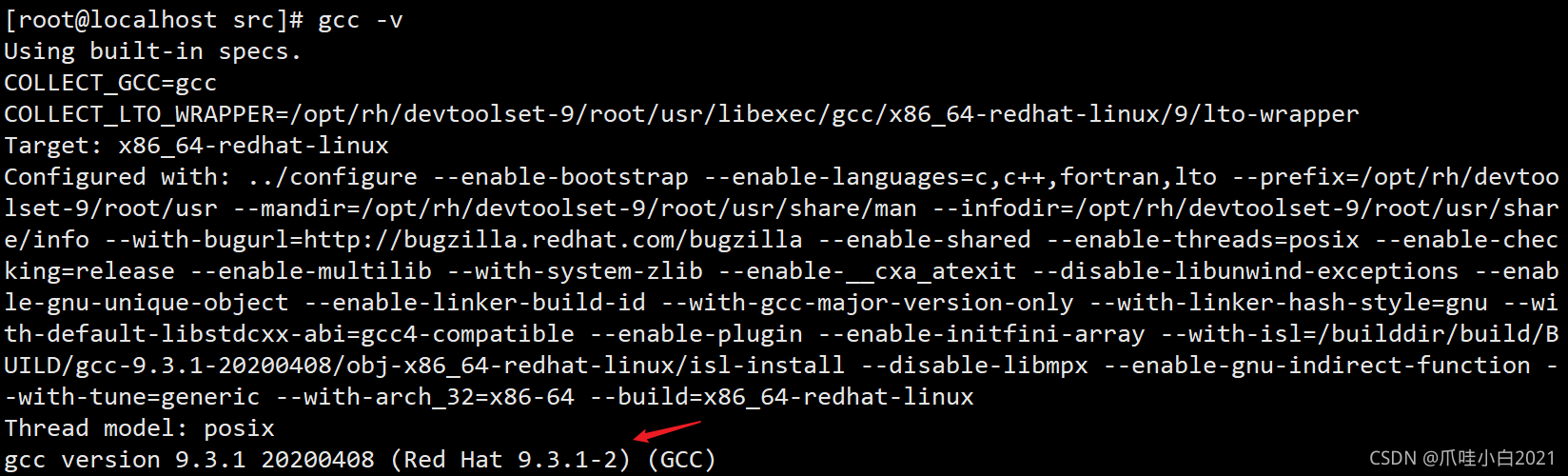
第五步:预编译
切换到解压目录
cd redis-6.0.9
make

第六步:安装
创建安装目录
mkdir -p /usr/local/redis
不使用:make install(make install默认安装到/usr/local/bin目录下)
使用:如果需要指定安装路径,需要添加PREFIX参数
make PREFIX=/usr/local/redis/ install
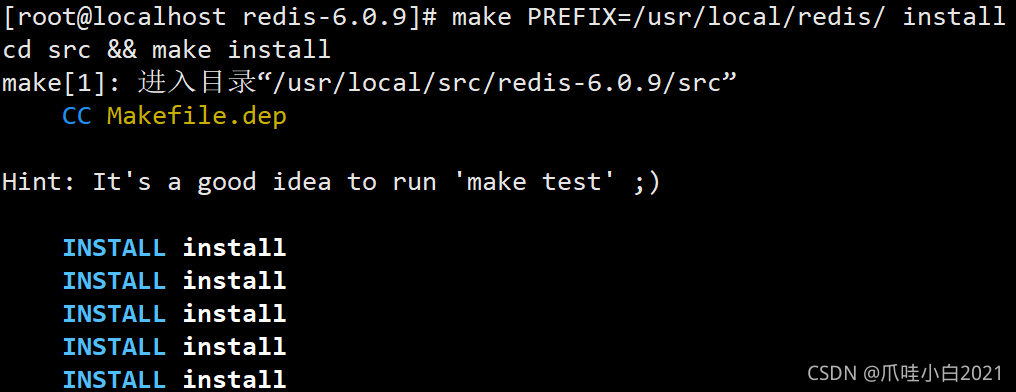
安装成功如图

安装成功后的几个文件解释
- redis-benchmark 性能测试工具
- redis-check-aof AOF文件修复工具
- redis-check-rdb RDB文件修复工具
- redis-cli 客户端命令行
- redis-sentinal 集群管理工具
- redis-server 服务进程指令
第七步:启动
安装的默认目标路径:/usr/local/redis/bin
启动
./redis-server
启动方式
第一种:执行./redis-server命令
执行Ctrl + C就会停止服务
第二种:守护进程启动
redis.conf是Redis的配置文件,安装完后,可以复制redis.conf文件到安装路径下
cp /usr/local/src/redis-6.0.9/redis.conf /usr/local/redis/bin/
修改安装路径下的redis.conf,将daemonize修改为yes

启动时,指定配置文件路径即可
./redis-server ./redis.conf
第三种:配置开机启动(centos7以上)
在系统服务目录里创建redis.service文件
vim /etc/systemd/system/redis.service
写入以下内容:
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/bin/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target
配置描述:
Description:描述服务
After:描述服务类别
[Service]服务运行参数的设置
Type=forking是后台运行的形式
ExecStart为服务的具体运行命令
ExecReload为重启命令
ExecStop为停止命令
PrivateTmp=True表示给服务分配独立的临时空间
注意:[Service]的启动、重启、停止命令全部要求使用绝对路径
重载系统服务:systemctl daemon-reload
测试并加入开机自启
关闭redis-server:systemctl stop redis.service
开启redis-server:systemctl start redis.service
查看redis-server状态:systemctl status redis.service
开启成功,将服务加入开机自启
systemctl enable redis.service
4. Redis的配置
Redis的配置文件
Redis 支持很多的参数,但都有默认值。 daemonize默认情况下, redis 不是在后台运行的,如果需要在后台运行,把该项的值更改为 yes。
pidfile当 Redis 在后台运行的时候, Redis 默认会把 pid 文件放在/var/run/redis.pid,你可以配 置到其他地址。当运行多个 redis 服务时,需要指定不同的 pid 文件和端口
bind指定 Redis 只接收来自于该 IP 地址的请求,如果不进行设置,那么将处理所有请求,在 生产环境中最好设置该项
port监听端口,默认为 6379
timeout设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令, 那么关闭该连接
loglevellog 等级分为 4 级, debug, verbose, notice, 和 warning。生产环境下一般开启 notice
logfile配置 log 文件地址,默认使用标准输出,即打印在命令行终端的窗口上
databases设置数据库的个数,可以使用 SELECT 命令来切换数据库。默认使用的数据库是 0
save设置 Redis 进行数据库镜像的频率。
if(在 60 秒之内有 10000 个 keys 发生变化时){ 进行镜像备份 }else if(在 300 秒之内有 10 个 keys 发生了变化){ 进行镜像备份 }else if(在 900 秒之内有 1 个 keys 发生了变化){ 进行镜像备份 }
rdbcompression在进行镜像备份时,是否进行压缩
dbfilename镜像备份文件的文件名
dir数据库镜像备份的文件放置的路径。这里的路径跟文件名要分开配置是因为 Redis 在进行备份时,先会将当前数据库的状态写入到一个临时文件中,等备份完成时,再把该该 临时文件替换为上面所指定的文件,而这里的临时文件和上面所配置的备份文件都会放 在这个指定的路径当中
slaveof设置该数据库为其他数据库的从数据库
masterauth当主数据库连接需要密码验证时,在这里指定
requirepass设置客户端连接后进行任何其他指定前需要使用的密码。警告:因为 redis 速度相当快, 所以在一台比较好的服务器下,一个外部的用户可以在一秒钟进行 150K 次的密码尝试, 这意味着你需要指定非常非常强大的密码来防止暴力破解。
maxclients限制同时连接的客户数量。当连接数超过这个值时, redis 将不再接收其他连接请求, 客户端尝试连接时将收到 error 信息。
maxmemory设置 redis 能够使用的最大内存。
appendonly默认情况下, redis 会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时 的,而且备份也不能很频繁,如果发生诸如拉闸限电、拔插头等状况,那么将造成比较大范围的数据丢失。所以 redis 提供了另外一种更加高效的数据库备份及灾难恢复方式。开启 append only 模式之后, redis 会把所接收到的每一次写操作请求都追加到appendonly.aof 文件中,当 redis 重新启动时,会从该文件恢复出之前的状态。但是这样会造成 appendonly.aof 文件过大,所以 redis 还支持了 BGREWRITEAOF 指令,对appendonly.aof 进行重新整理。所以我认为推荐生产环境下的做法为关闭镜像,开启appendonly.aof,同时可以选择在访问较少的时间每天对 appendonly.aof 进行重写一次。
appendfsync设置对 appendonly.aof 文件进行同步的频率。 always 表示每次有写操作都进行同步, everysec 表示对写操作进行累积,每秒同步一次。这个需要根据实际业务场景进行配置
vm-enabled是否开启虚拟内存支持。因为 redis 是一个内存数据库,而且当内存满的时候,无法接 收新的写请求,所以在 redis 2.0 中,提供了虚拟内存的支持。但是需要注意的是, redis中,所有的 key 都会放在内存中,在内存不够时,只会把 value 值放入交换区。这样保证了虽然使用虚拟内存,但性能基本不受影响,同时,你需要注意的是你要把vm-max-memory 设置到足够来放下你的所有的 key
vm-swap-file设置虚拟内存的交换文件路径
vm-max-memory这里设置开启虚拟内存之后, redis 将使用的最大物理内存的大小。默认为 0, redis 将 把他所有的能放到交换文件的都放到交换文件中,以尽量少的使用物理内存。在生产环 境下,需要根据实际情况设置该值,最好不要使用默认的 0
vm-page-size设置虚拟内存的页大小,如果你的 value 值比较大,比如说你要在 value 中放置博客、 新闻之类的所有文章内容,就设大一点,如果要放置的都是很小的内容,那就设小一点。
vm-pages设置交换文件的总的 page 数量, 需要注意的是, page table 信息会放在物理内存中,每 8 个 page 就会占据 RAM 中的 1 个 byte。总的虚拟内存大小 = vm-page-size * vm-pages
vm-max-threads设置 VM IO 同时使用的线程数量。因为在进行内存交换时,对数据有编码和解码的过 程,所以尽管 IO 设备在硬件上本上不能支持很多的并发读写,但是还是如果你所保存 的 vlaue 值比较大,将该值设大一些,还是能够提升性能的
glueoutputbuf把小的输出缓存放在一起,以便能够在一个 TCP packet 中为客户端发送多个响应,具体 原理和真实效果我不是很清楚。所以根据注释,你不是很确定的时候就设置成 yes
hash-max-zipmap-entries在 redis 2.0 中引入了 hash 数据结构。当 hash 中包含超过指定元素个数并且最大的元素 没有超过临界时, hash 将以一种特殊的编码方式(大大减少内存使用)来存储,这里 可以设置这两个临界值
activerehashing开启之后, redis 将在每 100 毫秒时使用 1 毫秒的 CPU 时间来对 redis 的 hash 表进行重新 hash,可以降低内存的使用。当你的使用场景中,有非常严格的实时性需要,不能 够接受 Redis 时不时的对请求有 2 毫秒的延迟的话,把这项配置为 no。如果没有这么严 格的实时性要求,可以设置为 yes,以便能够尽可能快的释放内存
通过windows客户端访问
安装Redis客户端
建立连接->失败
修改配置文件redis.conf
注释掉bind 127.0.0.1可以使所有的ip访问redis,若是想指定多个ip访问,但并不是全部的ip访问,可以bind设置

关闭保护模式,修改为no

添加访问认证
修改后kill -9 XXXX杀死redis进程,重启redis
再次建立连接 -> 成功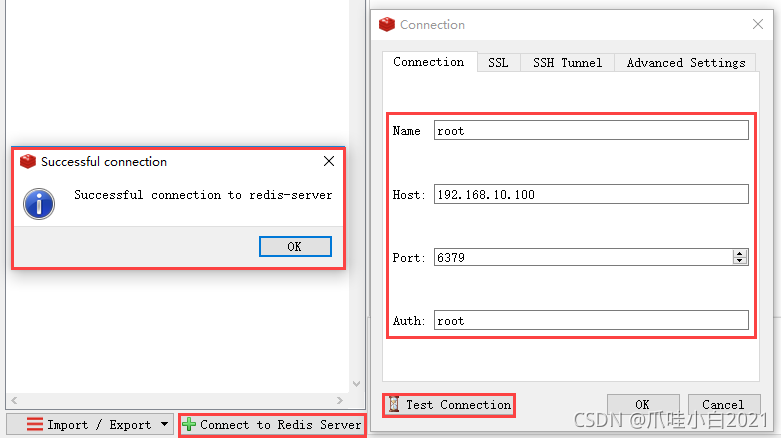
我们可以修改默认数据库的数量 默认16
修改database 32则默认为32个数据库
修改后kill -9 XXXX杀死redis进程,重启redis即可看到效果

5. Redis的Java客户端
Redis客户端介绍
Redis支持多种语言的客户端,这也是Redis受欢迎的原因之一。https://redis.io/clients
Java客户端
Redis的Java客户端也有很多:https://redis.io/clients#java,其中比较受欢迎的是Jedis和Lettuce。
- Jedis在实现上是直接连接的redis server,如果在多线程环境下是非线程安全的,这个时候只有使用连接池,为每个Jedis实例增加物理连接
- Lettuce的连接是基于Netty的,连接实例(StatefulRedisConnection)可以在多个线程间并发访问,应为StatefulRedisConnection是线程安全的,所以一个连接实例(StatefulRedisConnection)就可以满足+ 多线程环境下的并发访问,当然这个也是可伸缩的设计,一个连接实例不够的情况也可以按需增加连接实例。
- 在SpringBoot Data Redis 1.X之前默认使用的是Jedis,但目前最新版的修改成了Lettuce。
- 之前公司使用Jedis居多,Lettuce近两年在逐步上升,总的来讲Jedis的性能会优于Lettuce(因为它是直接操作Redis)。
Jedis客户端
简单的demo演示:
第一步:导入Jedis依赖包
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.3.0</version>
</dependency>
第二步:编写测试代码
public class ConnectionToRedis {
/**
* 连接Redis
*/
public static void main() {
// 创建jedis对象,连接redis服务,其中Jedis(host, port)
Jedis jedis = new Jedis("127.0.0.1", 16379);
// 设置认证密码,如果没有可以设置为空
jedis.auth("root");
// 指定数据库 默认是0
jedis.select(1);
// 使用ping命令,测试连接是否成功
String result = jedis.ping();
System.out.println(result);// 返回PONG
// 添加一条数据
jedis.set("username", "zhaowaxiaobai");
// 获取一条数据
String username = jedis.get("username");
System.out.println(username);
// 释放资源
if (jedis != null)
jedis.close();
}
}
第三步:引入连接池
我们知道Jedis是直接操作Redis,当在并发量非常大的时候,那么Jedis操作Redis的连接数很有可能就会异常,因此为了提高操作效率,引入连接池。
Jedis池化技术(JedisPool)在创建时初始化一些连接资源存储到连接池中,使用Jedis连接资源时不需要创建,而是从连接池中获取一个资源进行redis的操作,使用完毕后,不需要销毁该jedis连接资源,而是将该资源归还给连接池,供其他请求使用。
public class JedisPoolConnectRedis {
private static JedisPool jedisPool;
static {
// 创建连接池配置对象
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
// 设置最大连接数
jedisPoolConfig.setMaxTotal(5);
// 设置等待时间ms(当资源池连接用尽后,调用者最大等待时间)
jedisPoolConfig.setMaxWaitMillis(100);
// 其中JedisPool(jedisPoolConfig, host, port, connectionTimeout, password, db)
jedisPool = new JedisPool(jedisPoolConfig, "127.0.0.1", 6379, 100, "root", 0);
}
/*获取jedis*/
public static Jedis getJedis() {
return jedisPool.getResource();
}
/**
* 连接Redis
*/
public static void main() {
Jedis jedis = getJedis();
// 使用ping命令,测试连接是否成功
String result = jedis.ping();
System.out.println(result);// 返回PONG
// 添加一条数据
jedis.set("username", "zhaowaxiaobai");
// 获取一条数据
String username = jedis.get("username");
System.out.println(username);
// 释放资源
if (jedis != null)
jedis.close();
}
}
Jedis连接池优化
参数名:maxTotal
含义资源池最大连接数 【默认值:8】
使用建议需要考虑以下几点
-
业务希望的Redis并发量
-
客户端执行命令时间
-
Redis资源:例如应用个数(客户端)* maxTotal 不能超过Redis服务端的最大连接数(config get maxclients)
-
资源开销:例如虽然希望控制空闲连接,但是不希望因为连接池的频繁释放创建连接造成不必要的开销。
举例:命令平均执行时间0.1ms = 0.001s,业务需要100000 QPS,maxTotal理论值 = 0.001 * 100000 = 100个。实际值要偏大一些。
参数名:maxIdle
含义: 资源池允许最大的空闲连接数 【默认值:8】
使用建议: 建议跟maxTotal设置的值一样,这样可以减少创建新连接的开销
参数名:minIdle
含义: 资源池确保最少空闲连接数 【默认值:0】
使用建议: 建议第一次开启的时候预热(初始化一个值),减少第一次启动后的新连接开销
参数名:jmxEnabled
含义: 是否开启jmx监控,可用于监控资源使用状态 【默认值:true】
使用建议:开启
参数名:blockWhenExhausted
含义: 当资源池用尽后,调用者是否要等待。只有当为true时,配置的maxWaitMillis参数才会生效 【默认值:true】
使用建议: 建议先使用默认值,但这个也要看情况,如果并发量大,可以直接设置false,即每次请求资源时,如果连接资源不够,马上new个新的
参数名:maxWaitMillis
含义: 当资源池连接用尽后,调用者最大等待时间(单位为毫秒) 【默认-1,表示永不超时】
使用建议: 不建议使用默认值,再高并发环境下,获取资源不能hand在一个没有超时时间的地方,具体设置根据实际场景 如设置1000即为等待1秒。
参数名:testOnBorrow、testOnReturn
含义: 这两个参数是说,客户端向连接池借用或归还时,是否会在内部进行有效性检测(ping),无效的资源将被移除 【默认值:false】
使用建议:建议false,在高并发场景下,因为这样无形给每次增加了两次ping操作,对QPS有影响,如果不是高并发环境,可以考虑开启,或者自己来检测。
6. SpringBoot集成Redis
搭建环境:采用IDEA + JDK8 + SpringBoot2.3.5集成Redis
第一步:使用IDEA构建项目,同时引入对应依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.5.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.imooc</groupId>
<artifactId>springboot-redis-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>springboot-redis-demo</name>
<description>Demo Redis project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
第二步:配置Redis
在application.properties中添加Redis相关配置
spring:
# redis 配置
redis:
host: 192.168.10.101
port: 6379
password: 123456
database: 5
# jedis 连接池配置
# jedis:
# pool:
# max-active: 8
# max-idle: 8
# min-idle: 0
# max-wait: 1000
# lettuce 连接池配置
lettuce:
pool:
max-active: 8
max-idle: 8
min-idle: 0
max-wait: 1000
第三步:添加Redis序列化方法
在启动类中添加如下代码:
/**
* redisTemplate 序列化使用的jdkSerializeable, 存储二进制字节码, 所以自定义序列化类
* @param redisConnectionFactory
* @return
*/
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
// 使用Jackson2JsonRedisSerialize 替换默认序列化
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
// 设置key和value的序列化规则
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
第四步:测试Redis
在测试的package中,写下测试方法如下:
@SpringBootTest
public class ConnectionRedisTest {
@Resource
private RedisTemplate redisTemplate;
@Test
void testConnection() {
String result = redisTemplate.getConnectionFactory().getConnection().ping();
// 验证
assertEquals("PONG", result);
}
@Test
void testOptString() {
// 写入数据
redisTemplate.opsForValue().set("username", "Hello Redis!");
// 读取数据
String result = (String)redisTemplate.opsForValue().get("username");
// 验证
assertEquals("Hello Redis!", result);
}
}
如果全部是pass的话,那么就没有问题。
7. 需求分析与数据库设计
需求分析
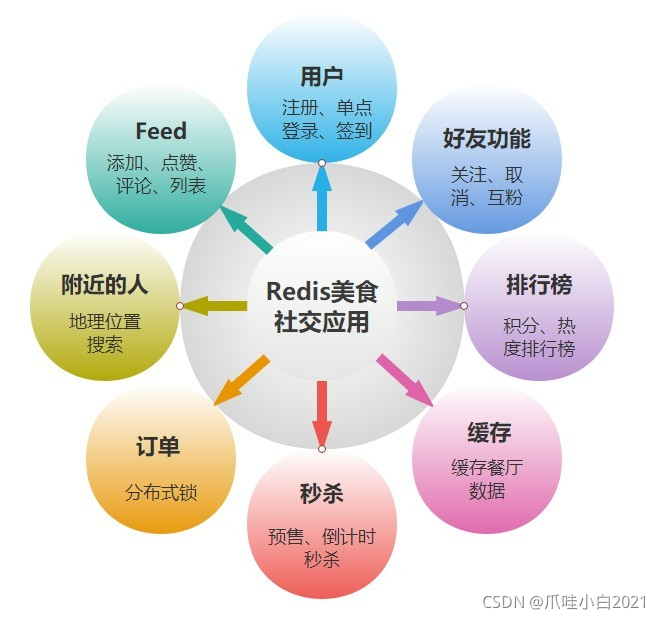
本课程以美食社交APP后台API接口设计为例。涉及APP中用户、好友、订单为基础的相关业务,分为用户、好友、排行榜、优惠券/秒杀、订单、附近的人、Feed 等微服务。完成用户登录、交友、发朋友圈以及购买优惠券、下单整个业务流程,并实现积分排行榜以及附近的人等相关功能。
数据库设计
项目架构与微服务搭建
项目架构
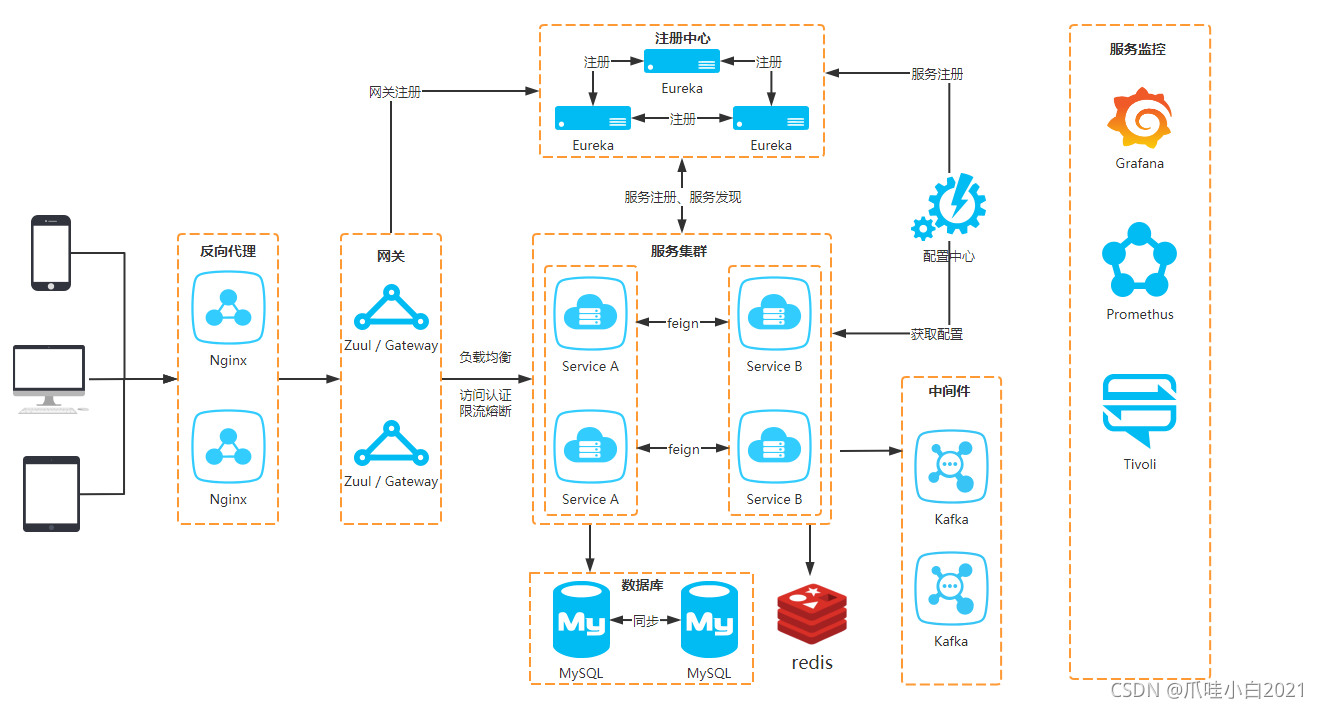
-
基于微服务进行项目开发,微服务是目前比较热门的架构方式,具有以下特点:
-
职责单一:理论上一个微服务只解决一件事(小)
-
隔离性强:服务单独部署,服务之间互相隔离,互不影响,因此一个服务宕机并不影响其他服务运行。(松)
-
开发简单:一个微服务解决一件事情,那么对开发团队的要求相对就减少(不论从人数还是开发语言都可以随心所欲),能够快速提高开发效率。(便)
微服务搭建
基于Spring Cloud Hoxton.SR1搭建。
第一步:创建Maven的父级工程,添加对应依赖
<!-- 可以集中定义依赖资源的版本信息 -->
<properties>
<spring-boot-version>2.3.5.RELEASE</spring-boot-version>
<spring-cloud-version>Hoxton.SR8</spring-cloud-version>
<lombok-version>1.18.16</lombok-version>
<commons-lang-version>3.11</commons-lang-version>
<mybatis-starter-version>2.1.3</mybatis-starter-version>
<swagger-starter-version>2.1.5-RELEASE</swagger-starter-version>
<hutool-version>5.4.7</hutool-version>
<guava-version>20.0</guava-version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<!-- 集中定义依赖,不引入 -->
<dependencyManagement>
<dependencies>
<!-- spring boot 依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot-version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- spring cloud 依赖 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud-version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- lombok 依赖 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok-version}</version>
</dependency>
<!-- common-lang3 依赖 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>${commons-lang-version}</version>
</dependency>
<!-- mybatis 依赖 -->
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis-starter-version}</version>
</dependency>
<!-- swagger 依赖 -->
<dependency>
<groupId>com.battcn</groupId>
<artifactId>swagger-spring-boot-starter</artifactId>
<version>${swagger-starter-version}</version>
</dependency>
<!-- mysql 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- hutool 依赖 -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>${hutool-version}</version>
</dependency>
<!-- guava 依赖 -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${guava-version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<!-- 集中定义项目所需插件 -->
<build>
<pluginManagement>
<plugins>
<!-- spring boot maven 项目打包插件 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</pluginManagement>
</build>
第二步:创建基于Eureka的注册中心微服务
第三步:配置注册中心(单机版)
server:
port: 8080
spring:
application:
name: ms-registry
# 配置 Eureka Server 注册中心
eureka:
client:
register-with-eureka: false
fetch-registry: false
service-url:
defaultZone: http://localhost:8080/eureka/
第四步:启动注册中心并验证
第五步:添加网关微服务,并注册到注册中心,启动并测试
第六步:添加用户食客微服务,并注册到注册中心,启动并测试
同理创建其他微服务
8. 问题引入?
1. 加入设置参数maxmemory为100M,当数据超过100M时,Redis会怎样处理?
当内存满了100M的时候,如果还接收到 set 命令, redis 将先尝试剔除设置过 expire 信息的 key,而不管该 key 的过期时间还没有到达。根据淘汰算法进行删除。如果带有 expire 信息的 key 都删光了,那么将返回错误。这样, redis 将不再接收写请求,只接收 get 请求。maxmemory 的设置比较适合于把 redis 当作于类似memcached的缓存来使用。
2.无法从连接池中获取连接(超时)
- 慢查询阻塞:池子连接都被hang住。
- 资源参数不合理:例如QPS高,池子小。
- 连接泄露(没有close()):也就是没有归还连接,可以用client list、netstat观察连接的一个增长情况,最重要的是try…catch…finally