文章目录
引言
关联规则分析是数据挖掘中最活跃的研究方法之一,目的是在一个数据集中找到各项之间的关联关系,而这种关系并没有在数据中直接体现出来。以超市的销售数据为例,当存在很多商品时,可能的商品组合数量达到了令人望而却步的程度,这是提取关联规则的最大困难。因此各种关联规则分析算法从不同方面入手减少可能的搜索空间大小以及减少扫描数据的次数。Apriori算法是最经典的挖掘频繁项集的算法,第一次实现在大数据集上的可行的关联规则提取,其核心思想是通过连接产生候选项及其支持度,然后通过剪枝生成频繁项集。
一、一些概念
1.关联规则的一般形式
- 关联规则的支持度(相对支持度)
项集A、B同时发生的概率称为关联规则的支持度(相对支持度)。 S u p p o r t ( A = > B ) = P ( A ∪ B ) Support(A=>B)=P(A∪B) Support(A=>B)=P(A∪B) - 关联规则的置信度
项集A发生,则项集B发生的概率为关联规则的置信度。 C o n f i d e n c e ( A = > B ) = P ( B ∣ A ) Confidence(A=>B)=P(B|A) Confidence(A=>B)=P(B∣A)
2.最小支持度和最小置信度
- 最小支持度是衡量支持度的一个阈值,表示项目集在统计意义上的最低重要性
- 最小置信度是衡量置信度的一个阈值,表示关联规则的最低可靠性
- 强规则是同时满足最小支持度阈值和最小置信度阈值的规则
3.项集
- 项集是项的集合。包含 k k k个项的集合称为 k k k项集,如集合{牛奶,麦片,糖}是一个三项集
- 项集出现的频率是所有包含项集的事务计数,又称为绝对支持度或支持度计数
- 如果项集 I I I的相对支持度满足预定义的最小支持度阈值,则 I I I是频繁项集。如果有 k k k项,记为 L k L_k Lk
4.支持度计数
- 项集A的支持度计数是事务数据集中包含项集A的事务个数,简称项集的频率或计数
- 一旦得到项集 A 、 B 和 A ∪ B A、B和A∪B A、B和A∪B的支持度计数以及所有事务个数,就可以导出对应的关联规则 A = > B A=>B A=>B和 B = > A B=>A B=>A,并可以检查该规则是否为强规则。

其中 N N N表示总事务个数, σ σ σ表示计数
二、Apriori算法:使用候选产生频繁项集
Apriori算法的主要思想是找出存在于事务数据集中最大的频繁项集,再利用得到的最大频繁项集与预先设定的最小置信度阈值生成强关联规则。
1.Apriori的性质
频繁项集的所有非空子集一定是频繁项集。根据这一性质可以得出:向不是频繁项集 I I I的项集中添加事务 A A A,新的项集 I ∪ A I∪A I∪A一定不是频繁项集。
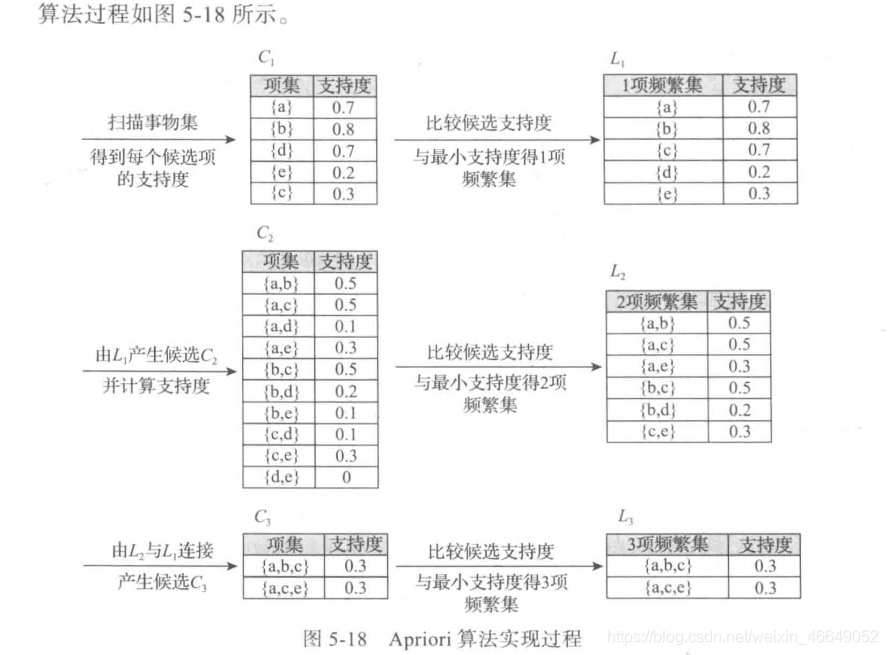
2.Apriori算法实现过程
第一步:
找出所有频繁项集(支持度必须大于等于给定的最小支持度阈值),在这个过程中连接步与剪枝步相互融合,最终得到最大频繁项集 L k L_k Lk
- 连接步
连接步的目的是找到 K K K项集。对于给定的最小支持度阈值,分别对1项候选集 C 1 C_1 C1,剔除小于该阈值的项集得到1项频繁集 L 1 L_1 L1;下一步由 L 1 L_1 L1自身连接产生2项候选集 C 2 C_2 C2,剔除小于该阈值的项集得到2项频繁集 L 2 L_2 L2;再下一步由 L 2 和 L 1 L_2和L_1 L2和L1连接产生3项候选集 C 3 C_3 C3,剔除小于该阈值的项集得到3项频繁集 L 3 L_3 L3,这样循环下去,直至由 L k − 1 和 L 1 L_{k-1}和L_1 Lk−1和L1连接产生 k k k项候选集 C k C_k Ck,剔除小于该阈值的项集得到最大频繁集 L k L_k Lk - 剪枝步
剪枝步紧接着连接步,在产生候选项 C k C_k Ck的过程中起到了减小搜索空间的目的。根据Apriori的性质:频繁项集的所有非空子集也必须是频繁项集,所以不满足该性质的项集将不会存在于 C k C_k Ck中,该过程就是剪枝
第二步:
由频繁项集产生强关联规则。由第一步可知,未超过预定的最小支持阈值的项集已被剔除,如果剩下的这些项集又满足了预定的最小置信度阈值,那么就挖掘出了强关联规则。
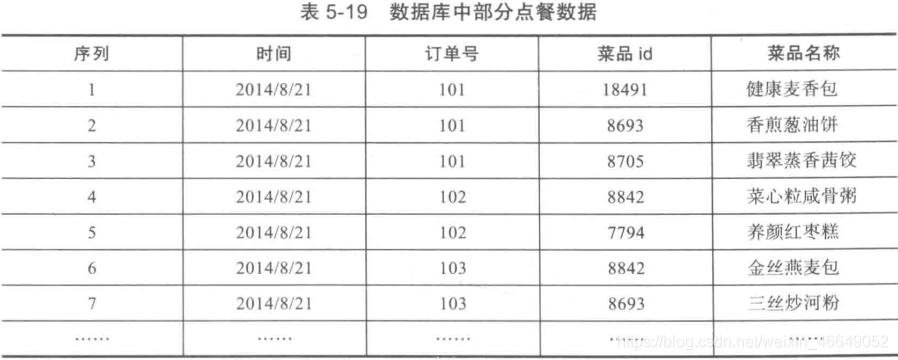
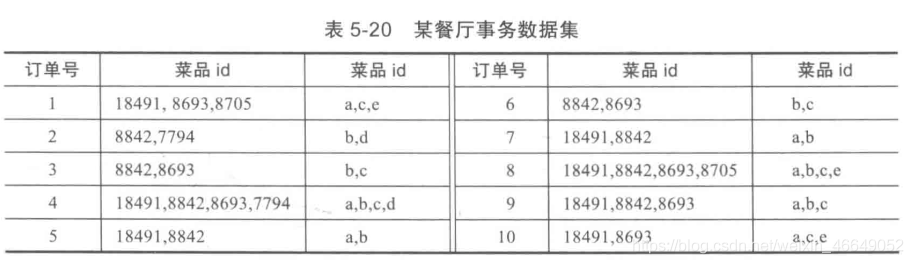
3.Apriori算法实现过程实例
以餐饮行业点餐数据为例,首先先将事务数据整理成关联规则模型所需的数据结构。设最小支持度为0.2,将菜品id编号



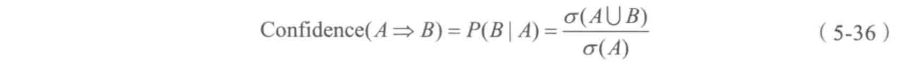


三、Apriori算法—python实现
import numpy as np
import pandas as pd
def connect_string(x, ms):
"""
与1项频繁集连接生成新的项集
:param x: 项集
:param ms:
:return: 新的项集
"""
x = list(map(lambda i: sorted(i.split(ms)), x))
l = len(x[0])
r = []
for i in range(len(x)):
for j in range(i, len(x)):
if x[i][:l - 1] == x[j][:l - 1] and x[i][l - 1] != x[j][l - 1]:
r.append(x[i][:l - 1] + sorted([x[j][l - 1], x[i][l - 1]]))
return r
def find_rule(d, support, confidence, ms=u'-'):
"""
寻找关联规则
:param d: 数据集
:param support: 最小支持度
:param confidence: 最小置信度
:param ms: 项集之间连接符号
:return: 强关联规则以及其支持度与置信度
"""
# 存储输出结果
result = pd.DataFrame(index=['support', 'confidence'])
# 1项集的支持度序列
support_series = 1.0 * d.sum(axis=0) / d.shape[0]
# 基于给定的最小支持度进行筛选,得到1项频繁集
column = list(support_series[support_series > support].index)
# 当1项频繁集个数大于1时
k = 0
while len(column) > 1:
k = k + 1
print(u'\n正在进行第%s次搜索...' % k)
column = connect_string(column, ms)
print(u'数目:%s...' % len(column))
# 乘积为1表示两个项集同时发生,乘积为0表示不同发生
sf = lambda i: d[i].prod(axis=1, numeric_only=True) # 新一批支持度的计算函数
# 创建连接数据,这一步耗时、耗内存最严重。当数据集较大时,可以考虑并行运算优化。
d_2 = pd.DataFrame(list(map(sf, column)), index=[ms.join(i) for i in column]).T
# 计算连接后的支持度
support_series_2 = 1.0 * d_2[[ms.join(i) for i in column]].sum() / len(d)
column = list(support_series_2[support_series_2 > support].index) # 新一轮支持度筛选
support_series = support_series.append(support_series_2)
column2 = []
# 遍历可能的推理,如{A,B,C}究竟是A+B-->C还是B+C-->A还是C+A-->B?
for i in column:
i = i.split(ms)
for j in range(len(i)):
column2.append(i[:j] + i[j + 1:] + i[j:j + 1])
# 定义置信度序列
cofidence_series = pd.Series(index=[ms.join(i) for i in column2])
# 计算置信度序列
for i in column2:
cofidence_series[ms.join(i)] = support_series[ms.join(sorted(i))] / support_series[ms.join(i[:len(i) - 1])]
for i in cofidence_series[cofidence_series > confidence].index: # 置信度筛选
result[i] = 0.0
result[i]['confidence'] = cofidence_series[i]
result[i]['support'] = support_series[ms.join(sorted(i.split(ms)))]
result = result.T.sort_values(['confidence', 'support'], ascending=False) # 结果整理,输出
print(u'\n结果为:')
print(result)
return result
if __name__ == '__main__':
# 加载数据
data = pd.read_excel('../data/menu_orders.xls', header=None)
print('转换原数据到0-1矩阵')
ct = lambda x: pd.Series(1, index=x[pd.notnull(x)])
b = map(ct, data.values)
data = pd.DataFrame(list(b)).fillna(0)
# 删除中间变脸b
del b
support = 0.2 # 最小支持度
confidence = 0.5 # 最小置信度
find_rule(data, support, confidence)
转换原数据到0-1矩阵
正在进行第1次搜索...
数目:6...
正在进行第2次搜索...
数目:3...
正在进行第3次搜索...
数目:0...
结果为:
support confidence
e-a 0.3 1.000000
e-c 0.3 1.000000
c-e-a 0.3 1.000000
a-e-c 0.3 1.000000
c-a 0.5 0.714286
a-c 0.5 0.714286
a-b 0.5 0.714286
c-b 0.5 0.714286
b-a 0.5 0.625000
b-c 0.5 0.625000
a-c-e 0.3 0.600000
b-c-a 0.3 0.600000
a-c-b 0.3 0.600000
a-b-c 0.3 0.600000
其中,'e—a’表示e发生能够推出a发生,置信度为100%,支持度30%。搜索出的关联规则并不一定有实际意义,需要根据问题背景筛选适当的有意义的规则,并赋予合理的解释。
参考:
《python数据分析与挖掘实战》
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论留言!
