所用版本:<version>2.2.0</version>
- 架构图
- KafkaProducer
- send()方法
- ProducerInterceptor 拦截器
- Metadata 元数据
- Serializer & Deserializer 序列化和反序列化器
- Partitioner 分区
- RecordAccumulator 暂存器
- BufferPool 内存管理类
- Sender
1. 架构图
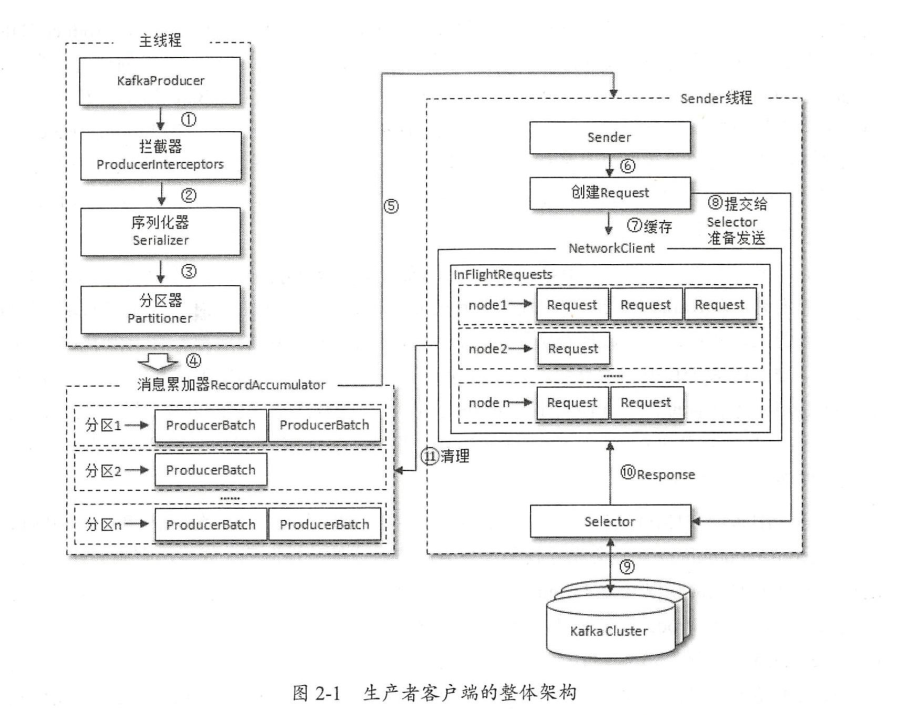
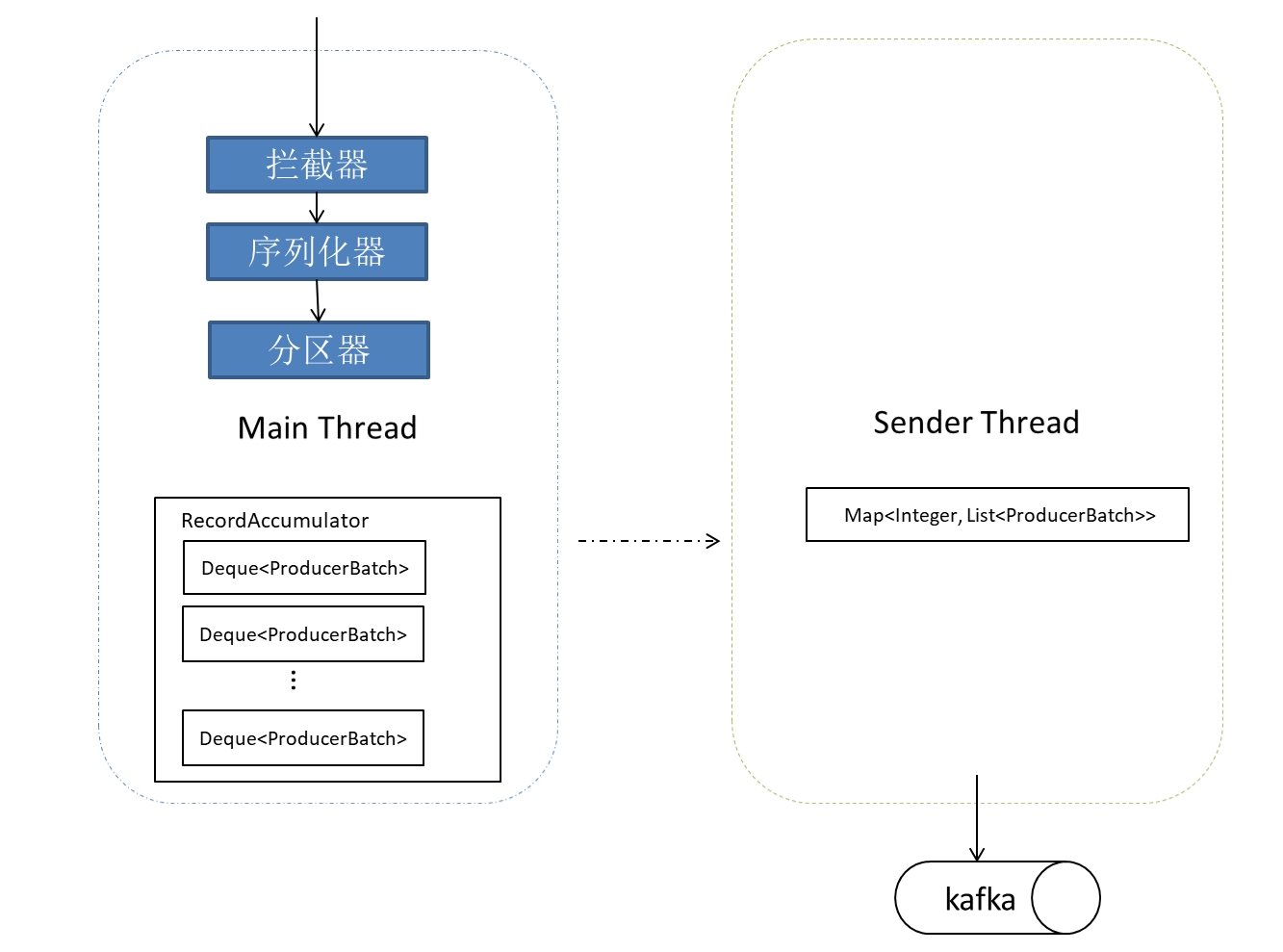
- Producer中有几个线程?——> 2个
- Main Thread和 sender Thread
- Producer首先使用用户主线程将待发送的消息封装进一个ProducerRecord类实例中
- 进行interceptor、序列化、分区等其他操作,发送到Producer程序中RecordAccumulator中
- Producer的另一个工作线程(即Sender线程),则负责实时地从该缓冲区中提取出准备好的消息封装到一个批次的内,统一发送给对应的broker中
2. KafkaProducer
- 属性
-
public class KafkaProducer<K, V> implements Producer<K, V> { private final Logger log; private final Sensor errors; private final ApiVersions apiVersions; ------------------------------------------------------------------------------------------------------------------ private static final AtomicInteger PRODUCER_CLIENT_ID_SEQUENCE = new AtomicInteger(1); //clientId的生成器,如果没有指定clientId,生成一个clientId private final String clientId; //此消费者的唯一标识 ------------------------------------------------------------------------------------------------------------------ private static final String JMX_PREFIX = "kafka.producer"; public static final String NETWORK_THREAD_PREFIX = "kafka-producer-network-thread"; public static final String PRODUCER_METRIC_GROUP_NAME = "producer-metrics"; final Metrics metrics; ------------------------------------------------------------------------------------------------------------------ private final Partitioner partitioner; //分区选择器 ------------------------------------------------------------------------------------------------------------------ private final int maxRequestSize; //消息最大长度:消息头+key+value private final long totalMemorySize; //发送单个消息的缓冲区大小 private final RecordAccumulator accumulator; //用于收集并缓存消息 private final CompressionType compressionType; //压缩算法,针对accumulator中多条消息进行压缩 private final Serializer<K> keySerializer; //key序列化器 private final Serializer<V> valueSerializer; //value序列化器 private final Metadata metadata; //整个kafka集群的元数据 private final long maxBlockTimeMs; //等待更新kafka集群元数据的最大时长 private final Time time; //消息超时时间,从消息发送到收到ack的最长时间 ------------------------------------------------------------------------------------------------------------------ private final Sender sender; //实现了runnable的sender任务 private final Thread ioThread; //Sender线程,执行sender的任务 ------------------------------------------------------------------------------------------------------------------ private final ProducerInterceptors<K, V> interceptors; //可以在消息发送前进行拦截 ------------------------------------------------------------------------------------------------------------------ private final ProducerConfig producerConfig; //配置对象 private final TransactionManager transactionManager; //事务 private TransactionalRequestResult initTransactionsResult; //事务初始化
-
- 构造器
-
KafkaProducer(Map<String, Object> configs, Serializer<K> keySerializer, Serializer<V> valueSerializer, Metadata metadata, KafkaClient kafkaClient, ProducerInterceptors interceptors, Time time) { //1.配置类 ProducerConfig config = new ProducerConfig(ProducerConfig.addSerializerToConfig(configs, keySerializer, valueSerializer)); //2.设置clientId,如果没有给定的话 clientId = "producer-" + PRODUCER_CLIENT_ID_SEQUENCE.getAndIncrement(); //3.设置transactionalId String transactionalId = userProvidedConfigs.containsKey("transactional.id") ? (String)userProvidedConfigs.get("transactional.id") : null; //4.设置metrics相关 Map<String, String> metricTags = Collections.singletonMap("client-id", clientId); MetricConfig metricConfig = (new MetricConfig()).samples(config.getInt("metrics.num.samples")).timeWindow(config.getLong("metrics.sample.window.ms"), TimeUnit.MILLISECONDS).recordLevel(RecordingLevel.forName(config.getString("metrics.recording.level"))).tags(metricTags); List<MetricsReporter> reporters = config.getConfiguredInstances("metric.reporters", MetricsReporter.class, Collections.singletonMap("client.id", clientId)); reporters.add(new JmxReporter("kafka.producer")); this.metrics = new Metrics(metricConfig, reporters, time); //5.设置partitioner this.partitioner = (Partitioner)config.getConfiguredInstance("partitioner.class", Partitioner.class); //6.设置key和value的序列化器 if (keySerializer == null) { this.keySerializer = (Serializer)config.getConfiguredInstance("key.serializer", Serializer.class); this.keySerializer.configure(config.originals(), true); } else { config.ignore("key.serializer"); this.keySerializer = keySerializer; } if (valueSerializer == null) { this.valueSerializer = (Serializer)config.getConfiguredInstance("value.serializer", Serializer.class); this.valueSerializer.configure(config.originals(), false); } else { config.ignore("value.serializer"); this.valueSerializer = valueSerializer; } //7.设置interceptors List<ProducerInterceptor<K, V>> interceptorList = configWithClientId.getConfiguredInstances("interceptor.classes", ProducerInterceptor.class); if (interceptors != null) { this.interceptors = interceptors; } else { this.interceptors = new ProducerInterceptors(interceptorList); } //8.设置其他参数 this.maxRequestSize = config.getInt("max.request.size"); this.totalMemorySize = config.getLong("buffer.memory"); this.compressionType = CompressionType.forName(config.getString("compression.type")); this.maxBlockTimeMs = config.getLong("max.block.ms"); this.transactionManager = configureTransactionState(config, logContext, this.log); int deliveryTimeoutMs = configureDeliveryTimeout(config, this.log); this.apiVersions = new ApiVersions(); this.accumulator = new RecordAccumulator(...) //9.设置metadata this.metadata = new Metadata(retryBackoffMs, config.getLong("metadata.max.age.ms"), true, true, clusterResourceListeners); this.metadata.bootstrap(addresses, time.milliseconds()); //10.设置sender和ioThread this.errors = this.metrics.sensor("errors"); this.sender = this.newSender(logContext, kafkaClient, this.metadata); String ioThreadName = "kafka-producer-network-thread | " + clientId; this.ioThread = new KafkaThread(ioThreadName, this.sender, true); this.ioThread.start(); }
-
- KafkaProducer.send()方法

3. ProducerInterceptor和ProducerInterceptors
- ProducerInterceptor作用
- interceptor使得用户在消息发送前以及producer回调逻辑前有机会对消息做一些定制化需求,比如修改消息等
- 相当于Java Web里的filter
- 使用方法
- 实现ProducerInterceptor接口,重写方法
- configure():获取配置信息
- onSend():序列化前调用该方法,允许提前对ProducerRecord作更改
- onAcknowledgement():回调后处理
- close():关闭资源
- 在主类中将ProducerInterceptor添加到ProducerInterceptors中,写入配置
- 实现ProducerInterceptor接口,重写方法
- 其他
- 线程安全问题
- interceptor可能被运行在多个线程中,因此在具体实现时用户需要自行确保线程安全
- 拦截链
- 同时,producer允许用户指定多个interceptor按序作用于同一条消息从而形成一个拦截链(interceptor chain)
- 线程安全问题
- ProducerInterceptor:抽象接口
-
public interface ProducerInterceptor<K, V> extends Configurable { //1. 父类Configurable接口中的方法 void configure(Map<String, ?> var1); //获取配置信息和初始化数据时调用 //2. 自己的抽象方法 //该方法封装进KafkaProducer.send方法中,即它运行在用户主线程中。Producer确保在消息被序列化以及计算分区前调用该方法。用户可以在该方法中对消息做任何操作,但最好保证不要修改消息所属的topic和分区,否则会影响目标分区的计算 ProducerRecord<K, V> onSend(ProducerRecord<K, V> var1); //该方法会在消息被应答或消息发送失败时调用,并且通常都是在producer回调逻辑触发之前。onAcknowledgement运行在producer的IO线程中,因此不要在该方法中放入很重的逻辑,否则会拖慢producer的消息发送效率 void onAcknowledgement(RecordMetadata var1, Exception var2); //关闭interceptor,主要用于执行一些资源清理工作 void close(); }
-
- ProducerInterceptors:类,封装了ProducerInterceptor的List
-
public class ProducerInterceptors<K, V> implements Closeable { private final List<ProducerInterceptor<K, V>> interceptors; ... }
-
-
使用方法
-
ProducerInterceptor的实现类,重写实现方法
-
public class TimeStampPrependerInterceptor implements ProducerInterceptor<String, String> { @Override public void configure(Map<String, ?> configs) {} @Override public ProducerRecord onSend(ProducerRecord record) { return new ProducerRecord(record.topic(), record.partition(), record.timestamp(), record.key(), System.currentTimeMillis() + "," + record.value().toString()); } @Override public void onAcknowledgement(RecordMetadata metadata, Exception exception) {} @Override public void close() {} } public class CounterInterceptor implements ProducerInterceptor<String, String> { private int errorCounter = 0; private int successCounter = 0; @Override public void configure(Map<String, ?> configs) {} @Override public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) { return record; } @Override public void onAcknowledgement(RecordMetadata metadata, Exception exception) { if (exception == null) { successCounter++; } else { errorCounter++; } } @Override public void close() { // 保存结果 System.out.println("Successful sent: " + successCounter); System.out.println("Failed sent: " + errorCounter); } }
-
-
在producer主程序中添加
-
Properties props = new Properties(); props.put(...); // 构建拦截链 List<String> interceptors = new ArrayList<>(); interceptors.add("huxi.test.producer.TimeStampPrependerInterceptor"); // interceptor 1 interceptors.add("huxi.test.producer.CounterInterceptor"); // interceptor 2 props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors); ... String topic = "test-topic"; Producer<String, String> producer = new KafkaProducer<>(props); for (int i = 0; i < 10; i++) { ProducerRecord<String, String> record = new ProducerRecord<>(topic, "message" + i); producer.send(record).get(); } // 一定要关闭producer,这样才会调用interceptor的close方法 producer.close();
-
-
4. Metadata 元数据
- 概念
- Metadata中记录了kafka集群的元数据
- 更新
- controller也会监听ZooKeeper集群的变化,在集群产生变化时更改自己的元数据信息。并且follower也会去它们的老大controller那里去同步元数据信息,所以一个Kafka集群中所有服务器上的元数据信息都是一致的

- org.apache.kafka.clients.Metadata
-
public class Metadata implements Closeable { -----------------------与更新时间相关------------------------------------------- public static final long TOPIC_EXPIRY_MS = 300000L; //多久更新一次,5分钟 private static final long TOPIC_EXPIRY_NEEDS_UPDATE = -1L; private final long refreshBackoffMs; //两次发出更新元数据的最小时间差,防止更新太频繁造成服务器压力,默认100ms private final long metadataExpireMs; //多久更新一次,默认5分钟一次 private int version; //元数据版本,元数据每次更新成功就+1 private long lastRefreshMs; //上次更新时间(包含更新失败的) private long lastSuccessfulRefreshMs; //上次更新成功的时间 -----------------------其他------------------------------------------- private final Map<String, Long> topics; //当前所有topics,与其过期时间的对应关系 private AuthenticationException authenticationException; private MetadataCache cache = MetadataCache.empty();; 元数据信息的Cache缓存,存放cluster private boolean needUpdate; //是否强制更新cluster private final List<org.apache.kafka.clients.Metadata.Listener> listeners; //监听器集合,在更新cluster之前,会通知list里所有的Listener private final ClusterResourceListeners clusterResourceListeners; private boolean needMetadataForAllTopics; // 是否强制更新所有的metadata private final boolean allowAutoTopicCreation; private final boolean topicExpiryEnabled; // 默认为true,Producer会定时移除过期的topic ,consumer 则不会移除 private boolean isClosed; private final Map<TopicPartition, Integer> lastSeenLeaderEpochs; } - org.apache.kafka.clients.MetadataCache
-
------------------Kafka集群中关于node,topic和partition的信息(是只读的)------------------ class MetadataCache { private final String clusterId; private final List<Node> nodes; private final Set<String> unauthorizedTopics; private final Set<String> invalidTopics; private final Set<String> internalTopics; private final Node controller; private final Map<TopicPartition, MetadataCache.PartitionInfoAndEpoch> metadataByPartition; private Cluster clusterInstance; }
-
- org.apache.kafka.common.Cluster
-
----------------------保存Topic的详细信息(leader所在节点,replica所在节点,isr列表)---------------------- public final class Cluster { // 从命名直接就看出了各个变量的用途 private final boolean isBootstrapConfigured; private final List<Node> nodes; // node 列表 private final Set<String> unauthorizedTopics; // 未认证的 topic 列表 private final Set<String> internalTopics; // 内置的 topic 列表 private final Map<TopicPartition, PartitionInfo> partitionsByTopicPartition; // partition 的详细信息 private final Map<String, List<PartitionInfo>> partitionsByTopic; // topic 与 partition 的对应关系 private final Map<String, List<PartitionInfo>> availablePartitionsByTopic; // 可用(leader 不为 null)的 topic 与 partition 的对应关系 private final Map<Integer, List<PartitionInfo>> partitionsByNode; // node 与 partition 的对应关系 private final Map<Integer, Node> nodesById; // node 与 broker id 的对应关系 private final ClusterResource clusterResource; } // 包含topic,partition,partition的主副本节点,replicas,isr,osr public class PartitionInfo { private final String topic; private final int partition; private final Node leader; private final Node[] replicas; private final Node[] inSyncReplicas; private final Node[] offlineReplicas; }
-
-
- Reference
5. Serializer & Deserializer
- 序列化和反序列化器
- kafka已经提供了基本的实现,在org.apache.kafka.common.serialization包下
- 自己实现,可以参考StringSerializer 和 IntegerSerializer
6. Partitioner
- 分区策略,kafka提供了Partitioner接口的默认实现DefaultPartitioner
- Partitoner接口
-
public interface Partitioner extends Configurable, Closeable { //根据给定的数据,找到 partition int partition(String var1, Object var2, byte[] var3, Object var4, byte[] var5, Cluster var6); // 关闭 partition void close(); }
-
- Kafka 2.4 版本
- 三个默认实现
- DefaultPartitioner
- RoundRobinPartitioner
- UniformStickyPartitioner
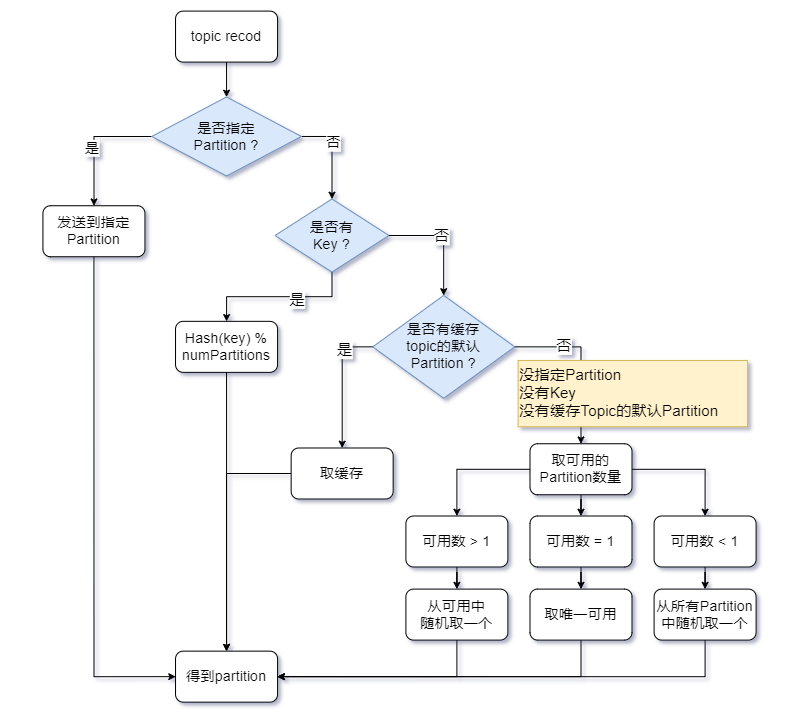
- 三个默认实现
- Reference
7. RecordAccumulator
- 概念
- 主线程调用KafkaProducer.send()方法将消息存入RecordAccumulator这个暂存器,就可以从send()方法中返回了,此时消息并没有发送给kafka,而是暂存在RecordAccumulator中,当 RecordAccumulator 达到一定阀值之后唤醒 sender 线程发送消息
- 线程安全
- RecordAccumulator类至少有一个主线程和一个sender线程并发操作,所以需要保证线程安全
- org.apache.kafka.clients.producer.internals.RecordAccumulator
-
public final class RecordAccumulator { private final Logger log; private volatile boolean closed; private final AtomicInteger flushesInProgress; private final AtomicInteger appendsInProgress; //它是标记往recordAccumulator 添加数据的线程的数量 private final int batchSize; //ProducerBatch底层byteBuffer的大小 private final CompressionType compression; //这是消息压缩的方式默认是 none 其他方式有 gzip,snappy,lz4,zstd private final long lingerMs; private final long retryBackoffMs; private final long deliveryTimeoutMs; private final BufferPool free; //BufferPool对象; kafka的内存模型 private final Time time; private final ApiVersions apiVersions; private final ConcurrentMap<TopicPartition, Deque<ProducerBatch>> batches; //TopicPartition 与 ProducerBatch的映射关系 类型是 CopyOnwriteMap 是线程安全的 private final IncompleteBatches incomplete; //未完成发送的 ProducerBatch 集合,类型是 HashSet private final Map<TopicPartition, Long> muted; private int drainIndex; private final TransactionManager transactionManager; private long nextBatchExpiryTimeMs = 9223372036854775807L; }
-
- append方法
- 主线程send()方法里调用了accumulator.append()方法
- RecordAccumulator内部有一个类型为ConcurrentMap<TopicPartition, Deque<ProducerBatch>>的成员变量batches
- key是Topic的分区信息
- value是一个批次的双端队列,ProducerBatch是一个批次,里面存放具体的消息
- 整个append方法重点步骤如下
- 拿到对应TopicPartition的批次队列Deque<ProducerBatch>,找不到则创建新的,添加到batches中去
- 第一次tryAppend
- 成功则返回,如果失败分配缓冲区
- 第二次tryAppend
- 成功则返回,失败则创建新批次ProducerBatch
- 第三次tryAppend
- 释放缓冲区
- Reference
7.1 BufferPool
- 概念
- ByteBuffer的创建和释放是比较消耗资源的,为了提高内存效率。kafka利用BufferPool来实现ByteBuffer复用
- org.apache.kafka.clients.producer.internals.BufferPool
-
public class BufferPool { static final String WAIT_TIME_SENSOR_NAME = "bufferpool-wait-time"; private final long totalMemory; // 整个Pooll的大小 private final int poolableSize; // 指定ByteBuffer的大小 private final ReentrantLock lock; // 多线程并发分配和回收ByteBuffer,用锁控制并发 private final Deque<ByteBuffer> free; // 缓存了指定大小的ByteBuffer对象(poolableSize指定) private final Deque<Condition> waiters; // 记录因申请不到足够空间而阻塞的线程,此队列中实际记录的是阻塞线程对应的Condition对象 private long nonPooledAvailableMemory; // 可用的空间大小,totalMemory减去free列表中所有ButeBuffer的大小 private final Metrics metrics; private final Time time; private final Sensor waitTime; }
-
- Reference