- 概述
- 节点和集群
- 命令(conf + 握手 + 查看)
- 数据结构
- clusterState
- clusterNode
- clusterLink
- 槽(slot)和分片
- 概述
- 命令
- 结构(clusterState.slots[] 和 clusterNode.slots[])
- 自动转发操作机制(MOVED错误)
- hash分配 - CRC16
- 跳跃表
- slot重新分片
- redis-trib 重新分片原理
- ASK错误(cf MOVED错误)
- 复制和故障转移
- 消息
1. 概述
Redis有三种集群方式:主从模式,Sentinel模式(哨兵模式),Cluster模式(集群模式)
- 主从模式
- master主服务器用于读写,slave从服务器用于读
- master挂了,数据不一定会丢失,因为slave备份了,但是redis不再提供写服务
- 使用:SLAVE OF指令,或者conf配置
- 优缺点:简单,但不高可用,master挂了不再提供写服务
- Sentinel模式(哨兵模式)
- 一个sentinel或sentinel集群可以管理多个主从Redis,多个sentinel也可以监控同一个redis
- sentinel最好不要和Redis部署在同一台机器,不然Redis的服务器挂了以后,sentinel也挂了
- 优缺点:具备高可用,sentinel会自动选举新的master(如果原来的宕机)
- Cluster模式(集群模式)
- sentinel和主从模式的结合体:解决单机Redis容量有限的问题,将Redis的数据根据一定的规则分配到多台机器
- 所有的节点都是一主一从(也可以是一主多从),其中从不提供服务,仅作为备用。如果配置两个副本三个分片的话,就需要六个Redis实例
- 客户端可以连接任何一个主节点进行读写
- 优缺点:高可用 + 支持横向扩容
2. 节点和集群
- 命令
- 配置文件:cluster-enabled配置项需要设为 yes
- 握手命令:各个独立节点之间,建立集群关系,需要先握手(handshake):CLUSTER MEET ip port
- 实现原理:类似TCP三次握手
- client向节点A发送CLUSTER MEET,发起请求与B握手
- A向B发送MEET消息
- B回复PONG
- A回复PING
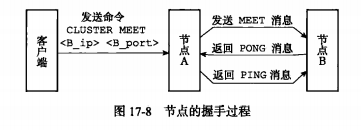
- 实现原理:类似TCP三次握手
- 查看集群信息:CLUSTER NODES
- eg. 127.0.0.1:7000向127.0.0.1:7002发送握手命令,请求建立集群,之后查看集群信息
- 数据结构
- clusterState:记录集群目前的状态
- 每个节点都保存了一个clusterState结构,记录集群状态,比如集群是否在上线状态,集群包含多少个node,当前的配置epoch
-
typedef struct clusterState { //指向当前节点的指针 clusterNode *myself; //集群当前的配置纪元,用于实现故障转移 uint64_t currentEpoch; //集群当前状态:上线或下线 int state; //集群中至少处理着一个slot的节点的数量 int size; //集群节点名单(包括myself节点),key是node的名字,value是clusterNode结构 dict *nodes; //... }clusterState;
-
clusterNode:保存节点的状态
-
所有主从节点都有一个clusterNode结构来保存状态(创建时间,名字,ip+port)。可以类比redisServer,sentinelRedisInstance等结构
-
struct clusterNode{ //创建节点的时间 mstime_t ctime; //节点的名字,40个十六进制组成,类似run_id char name[REDIS_CLUSTER_NAMELEN]; //节点标识:节点角色(主/从),节点状态(上线/下线) int flags; //节点当前的epoch,用于故障转移 uint64_t configEpoch; //节点的IP地址 char ip[REDIS_IP_STR_LEN]; //节点的端口号 int port; //保存连接节点所需的有关信息,类似redisClient clusterLink *link; //... };
-
-
clusterLink:连接该节点所需的有关信息
-
比如socket描述符,输入缓冲区和输出缓冲区,类比redisClient
-
typedef struct clusterLink{ //连接的创建时间 mstime_t ctime; //TCP套接字描述符 int fd; //输出缓冲区,保存着等待发送给其他node的消息 sds sndbuf; //输入缓冲区,保存着从其他node接收到的消息 sds rcvbuf; //与这个连接相关联的节点,没有则书出NULL struct clusterNode *node; }clusterLink;
-
-
结构图
-
- clusterState:记录集群目前的状态


3. 槽(slot)和分片
- 概述
- redis集群内部使用自动分片机制,将所有的key映射到16384个slot中,集群中的每个Redis Instance负责其中的一部分的Slot的读写
- 集群客户端连接集群中任一Redis Instance即可发送命令,当Redis Instance收到自己不负责的Slot的请求时,会将负责请求Key所在Slot的Redis Instance地址返回给客户端,客户端收到后自动将原请求重新发往这个地址,对外部透明
- 一个Key到底属于哪个Slot由crc16(key) % 16384 决定
- 必须保证所有16384个slot都被分配到集群才会ok状态,不然集群会处于fail状态
- 命令
- 分配slot:CLUSTER ADDSLOTS <slot> [slot...]
- 原理:每次执行 ADDSLOTS 命令:(1)会for循环遍历 clusterState.slots[],检查是否为null,如果不是则已经被占用,返回错误(2)执行成功后,向其他node发送clusterNode.slots[]数组,告知自己负责哪些slot
-
# 逐个分配 127.0.0.1:8000> CLUSTER ADDSLOTS 0 1 2 3 OK # 逐个分配太累,智能连续分配 127.0.0.1:8000> CLUSTER ADDSLOTS 0 1 2 ... 10000 OK
- 分配slot:CLUSTER ADDSLOTS <slot> [slot...]
-
内部结构:两种 slots[] 数组
- clusterNode中的 char slots数组 和 numslots。
- 优点:对于查找检查某slot是否被占用,复杂度O(1)
- 作用:集群间Node相互通信,需要将slot[]数组发送,告知对方自己分配的slot有哪些
- eg. 该节点的 0 到 7 号slot已经被分配,numslots = 8
- clusterState中的 clusterNode *slots数组,指向对应Node的地址
- 优点:假如有三个node,则原先 查找/操作 某一slot需要遍历这3个节点,复杂度O(n)。现在复杂度O(1)
-
struct clusterNode{ //长度为 16384/8 = 2048 的char数组,等价于 16384 个bit //1表示被分配,0表示未分配 unsigned char slots[16384/8]; //该node一共被分配了多少个slot int numslots } struct clusterState{ //指针,指向每个slot属于的那个node clusterNode *slots[16384]; } -
图例:
-
- clusterNode中的 char slots数组 和 numslots。
-
自动转发操作机制
-
例如:nodeA收到client的操作之后,如果该key对应的slot不是自己负责,则会返回client一个MOVED错误,指引client转向正确的nodeB
-
MOVED错误,nodeA会给nodeB发送 MOVED <slot> <nodeB_ip>:<nodeB_port> 命令,但该命令会对client端隐藏
-
-

-
-
hash散列
-
代码:return CRC16(key) & 16383; 先计算CRC-16校验和,再与操作
-
-
存储方式
-
node与正常服务器的存储方式完全相同,除了一点:node只使用0号数据库
-
除此之外:node还会额外使用clusterState. *slots_to_key 跳跃表来保存slots和key的关系,方便进行批量操作(例如 CLUSTER GETKEYSINSLOT <slot> <count>命令)
-
struct clusterState{ zskiplist *slots_to_keys; }
-
-



4. slot重新分片
-
当有新node加入,或者重新分slot时:Redis提供自动 / 手动 重新分配slot
-
原理:redis-trib程序负责管理重新分片操作,该程序位于redis文件夹src目录下

- eg. node_A分配了一部分自己的 slot 给node_B
-
(1)redis-trib通知 node_B 开始准备:向node_B发送 CLUSTER SETSLOT <slot> IMPORTING <source_id> 命令
-
//IMPORTING和MIGRATING命令原理: typedef struct clusterState{ //迁移时,importing_slots_from[i]指向一个clusterNode结构,表示正在从该node迁移过来,平时指向null clusterNode *importing_slots_from[16384]; //迁移时,migrating_slots_to[i]指向一个clusterNode结构,表示正在迁移去该node,平时指向null clusterNode *migrating_slots_to[16384]; }clusterState;
-
-
(2)redis-trib通知 node_A 开始准备:向node_A发送 CLUSTER SETSLOT <slot> MIGRATING <target_id> 命令
-
(3)redis-trib获取 node_A 中要复制的key名称:向node_A发送 CLUSTER GETKEYSINSLOT <slot> <count> 命令,count为上限多少个
-
(4)for循环每个key,让node_A发送给node_B:向node_A发送 MIGRATE <target_ip> <target_port> <key_name> 0 <timeout> 命令(表示发送)
-
(5)通知整个集群:先向任意一个节点发送 CLUSTER SETSLOT <slot> NODE <target_id> 命令,之后通过node间的相互通信传播
-
-
ASK错误
-
在重新分配期间,如果某node的slot恰好正在迁移,而client在访问,则会返回ASK错误,自动跳转,类似MOVED错误
-
ASK错误:重新分配期间没访问到;MOVED错误:没访问到
-
-
5. 复制和故障转移
- 发现故障节点
- 集群内的节点会向其他节点发送PING命令,检查是否在线
- 如果未能在规定时间内做出PONG响应,则会把对应的节点标记为疑似下线
- 集群中一半以上负责处理槽的主节点都将主节点X标记为疑似下线的话,那么这个主节点X就会被认为是已下线
- 向集群广播主节点X已下线,大家收到消息后都会把自己维护的结构体里的主节点X标记为已下线
- 从节点选举
- 当从节点发现自己复制的主节点已下线了,会向集群里面广播一条消息,要求所有有投票权的节点给自己投票(所有负责处理槽的主节点都有投票权)
- 主节点会向第一个给他发选举消息的从节点回复支持
- 当支持数量超过N/2+1的情况下,该从节点当选新的主节点
- 故障的迁移
- 新当选的从节点执行 SLAVEOF no one,修改成主节点
- 新的主节点会撤销所有已下线的老的主节点的槽指派,指派给自己
- 新的主节点向集群发送命令,通知其他节点自己已经变成主节点了,负责哪些槽指派
- 新的主节点开始处理自己负责的槽的命令
- 集群模式和哨兵模式的区别
- 哨兵模式监控权交给了哨兵系统,集群模式中是工作节点自己做监控
- 哨兵模式发起选举是选举一个leader哨兵节点来处理故障转移,集群模式是在从节点中选举一个新的主节点,来处理故障的转移
6. 消息
节点发送的消息主要有以下五种
- MEET
- PING
- PONG
- FAIL
- PUBLISH