前言
malloc与free带来的内存管理是应付小区块的,即SBH(small block heap),这点也可以从源代码中看出:
VC6下会做门槛检测
if(size <= __sbh_threshold) {
pvReturn = __sbh_alloc_block(size);
return pvReturn;
}
...
return HeapAlloc(_crtheap,0,size)
VC10下不会做门槛检测,它总是会调用系统提供的HeapAlloc。这是因为操作系统提供的函数也有类似的功能了。
当然还需要注意,我们分析的步骤是按照函数调用的次序来的:(从下往上的函数调用次序如下)

1、heap初始化
首先向操作系统要一大块内存(如4096),称为_crtheap.
然后使用HeapAlloc从_crtheap中获取16个HEADER大小的内存,并获取内存指针。
每个HEADER长这样:
 图1 图1
|
 图2 图2
|
2、第一次分配内存,计算真正区块大小
在debug模式下,通过调用malloc_dbg,分配得到32个8字节的内存,即100h.
然后调整大小,扩充一个如下的结构:nDataSize记录真正大小。gap用户调试器检查保护nsize内存。注意gap一共上下两个,但是结构体里面只定义了上面的那个。
 图1 图1
|
 图2 图2
|

通过调用_heap_alloc_base来获取每个blockSize内存的头指针。
然后通过头尾指针将所有分配出来的block串接起来,变为一个链表:
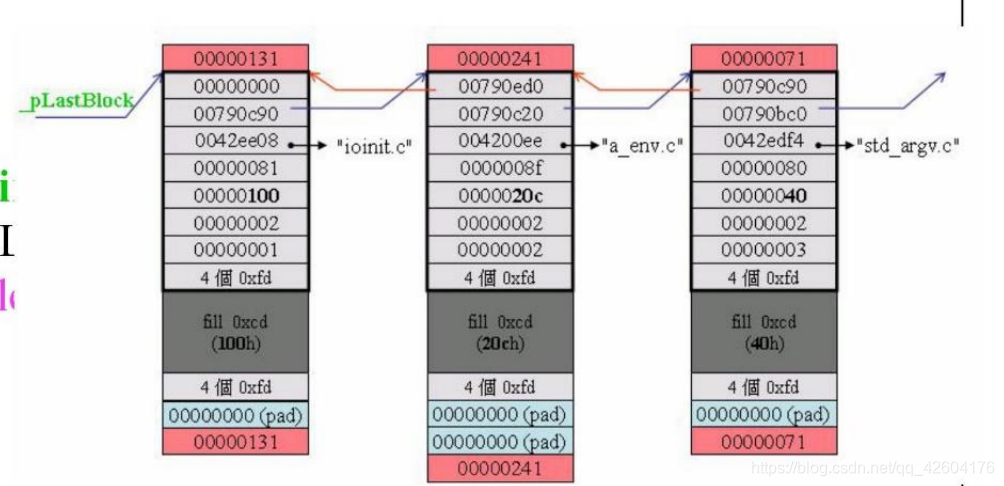
头指针为_pFirstBlock;
尾指针为_pLastBlock;
_heap_alloc_base具体内容
之前在通过heap_alloc_dbg中调用_heap_alloc_base来获取每个blockSize内存的头指针。
现在来看看它具体步骤:
1、首先将扩充完的大小与__sbh_threshold进行比较,所过是小区块就用shb服务,否则由操作系统服务。
小区块的定义是:这块内存大小+cookie大小 < 1024个字节
if(size <= __sbh_threshold) {
pvReturn = __sbh_alloc_block(size);
return pvReturn;
}
...
return HeapAlloc(_crtheap,0,size)
接下来看__sbh_alloc_block具体细节:
对扩充完的区块再次进行扩充,加上8个字节(上下cookie)并且进行roundup操作(变为16的整数倍)
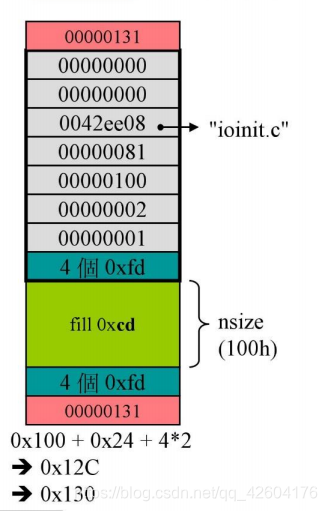
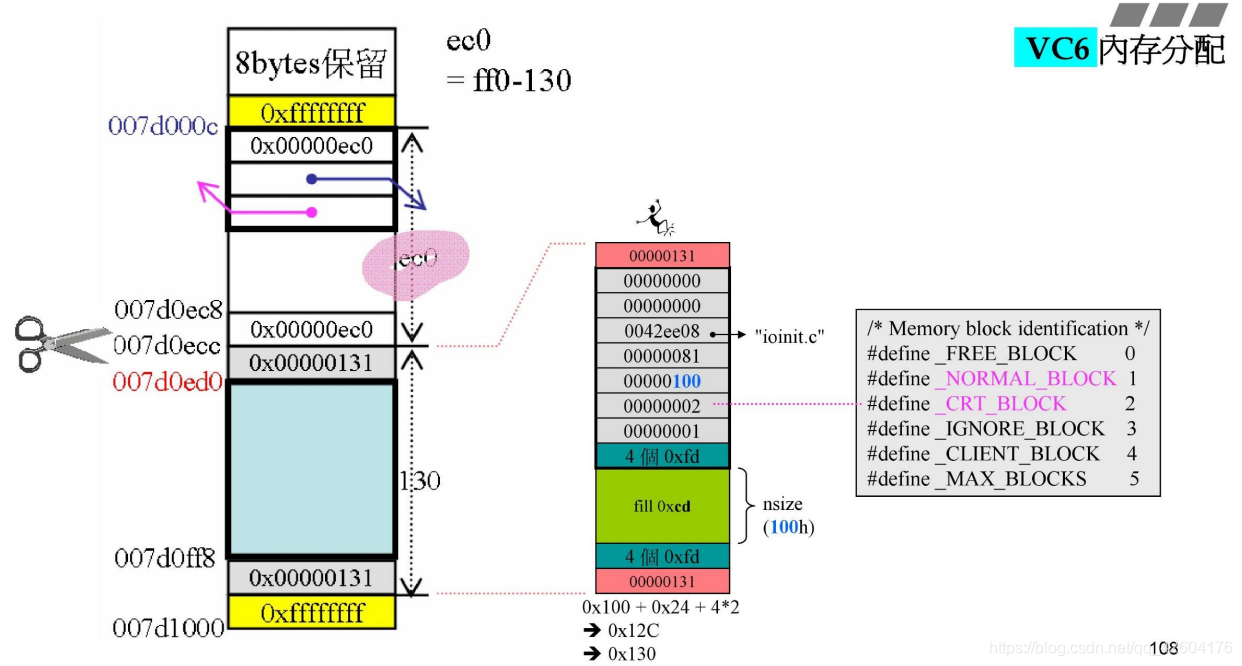
以上图为例,最终得到的结果是0x130,但是在cookie中写入的却是131。这是因为由于是16的倍数,所以最后一位一定是0。最后一位0/1表示是在SBH手上还是已经分配出去了。
3、new_region管理中心
之前在第一步heap初始化的时候分配了16个HEADER,每个HEADER现在用来管理1MB的内存。每个HEADER有两根指针:一根指向虚拟地址空间,一根指向管理中心。
管理中心被称为new_region。
region设计如下:
它含有:
1个整数
64个char
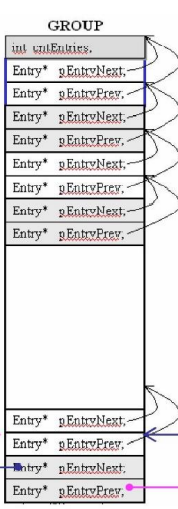
32个Hi和32个Lo并起来,构成32组,每组64个bit。(用来管理哪些区块有或者没有)
32个group,每个group由64根双向链表组成。
 图1 图1
|
 图2 图2
|
4、__sbh_alloc_new_group()切割第一次分配好的内存
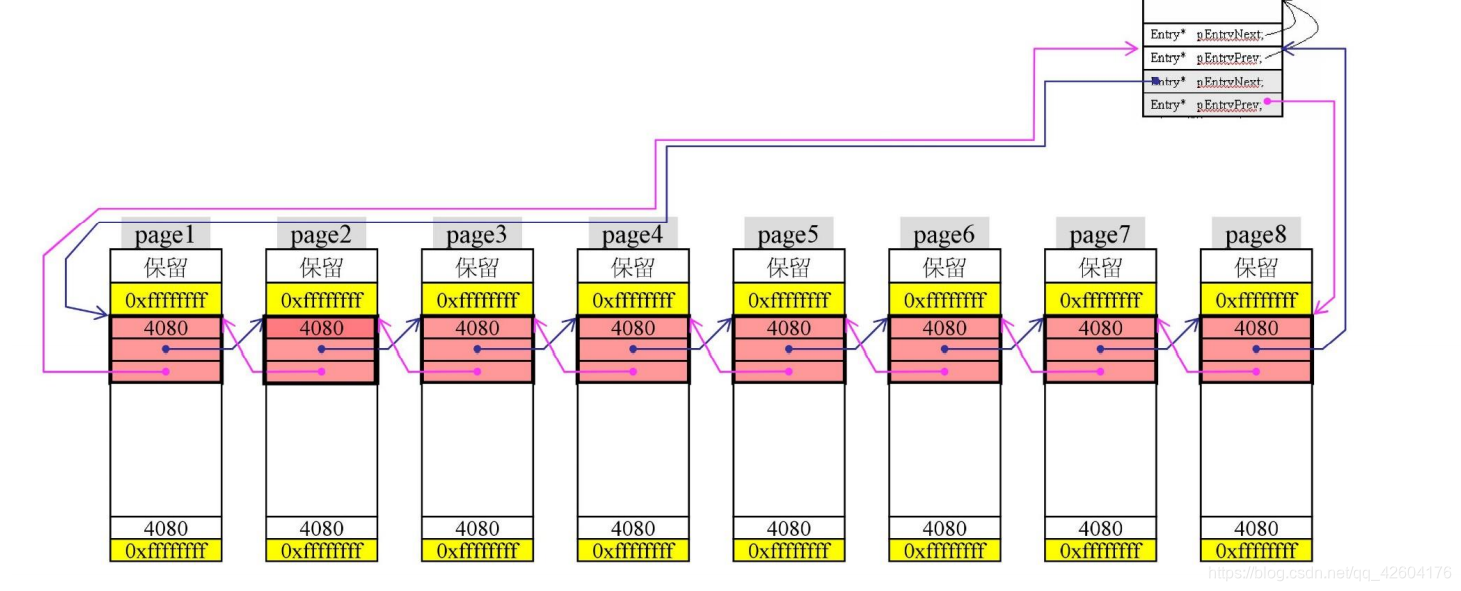
已知拥有32个group,对应了1MB的虚拟内存空间,平均下来每个group管理32KB内存。
每32KB的内存还要再分割,分成8page(注意这里的内存都是连续的),每page4KB,然后用指针把8个page串起来。串起来之后将它们挂到group的最后一条链表。这便是SBH现在所作的事情。
下面红色部分便是group与32KB内存的具体衔接图。

0xfff…实际上就是-1,作用:
将来回收内存的时候需要合并内存,合并的过程中需要用-1作为阻隔器,即只能合并-1与-1之间的内存。
上-1下面有3格,第一格记录的是两个-1之间的内存,一开始大小为4080,后两格作为指针将page从前到后串联起来。
每个page大小4096字节,去掉两个-1,剩下4088个字节。由于每个红色区块要保证大小是16倍数。所以需要将4088再分割出去8个字节(也就是保留)。
每个4K都这样处理,形成如下的图:
5、开始切割内存
先前讲到了每个group中有64根双向链表,平均分配下来:
第一条链表管理16个字节的内存
第二条链表管理32个字节的内存
…
最后一条管理1024个字节的内存(实际上大于1k的内存全都归最后一条管理)
现在开始想象开始切割page1的内存,当page1内存小于1k的时候就不应该由最后一条链表来管,应该要计算,然后将指定链表拉过来。现在来看具体的切割:
在之前的步骤中我们以及知道我们需要的内存是多大了:130h(100h+debugHeader+cookie+roundup)
所以,现在还剩下ec0h的内存。切割完后,系统将红色的地址:007d0ed0,传出去。
客户程序拿到该指针,便认为拥有了这一块内存。
由上可知,切割其实只是cookie的调整 + 指针的传送。
注意红色指针还需要调整(扣除debugHeader),调整到右边的结构块的绿色部分,该部分才是使用者(ioinit)真正拿到的地址。