方法一
实现思路
主要思路是将字符串映射到来数字
将问题抽象为求解最短路
当两个单词之间只有一个字符不相同时就会有一条无向边
求最短路的方法使用的dfs
tip:在这里要注意,如果beginWrod没有出现在wordList中的话,要将这个提前压入
实现代码(超时)
class Solution {
public:
int re;
void dfs(vector<int> &book,vector<set<int>> &path,int start,int end,int step,int &re){
book[start]=1;
if(start==end){
if(re==0||(re!=0&&step<re))
{
re=step;
}
return;
}
for(set<int>::iterator it=path[start].begin();it!=path[start].end();it++){
if(!book[*it])
{
dfs(book,path,*it,end,step+1,re);
book[*it]=0;
}
}
}
bool compare(string s1,string s2){
int same=0;
for(int i=0;i<s1.size();i++)
if(s1[i]==s2[i])
same++;
return (same+1)==s1.size();
}
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
int ff=0;
for(int i=0;i<wordList.size();i++){
if(wordList[i]==beginWord)
ff=1;
}
if(!ff) wordList.push_back(beginWord);
vector<set<int>> path(wordList.size());
map<string,int> word_map;
vector<int> book(wordList.size(),0);
for(int i=0;i<wordList.size();i++){
word_map[wordList[i]]=i;
}
if(word_map.count(endWord)==0||wordList.size()==1)
return 0;
for(int i=0;i<wordList.size()-1;i++){
for(int j=i+1;j<wordList.size();j++){
if(compare(wordList[i],wordList[j]))
{
path[i].insert(j);
path[j].insert(i);
}
}
}
re=0;
bool flag=false;
cout<<"ok"<<endl;
dfs(book,path,word_map[beginWord],word_map[endWord],0,re);
if(re) return re+1;
return 0;
}
};
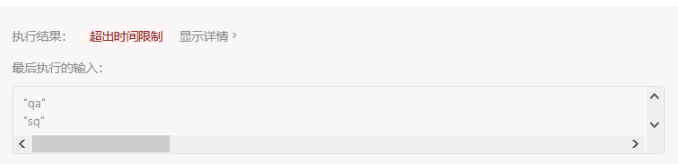
提交结果及分析
优化
1)我将求最短路的方法换成来spfa算法+前向星表示法(后续会整理spfa算法的模板)
2)在测试的时候发现将Edge数组设置为固定的不够用,又换成来vector类型的
3)同时发现程序上逻辑的BUG,就是没有考虑所有字符串长度为1的情况,可以发现这种情况下,结果就为2,当成一种特殊的情况直接返回了
代码
#define MAX 999999
const int maxn=5000+5;
int head[maxn],dis[maxn],vis[maxn];
int cnt;
struct Edge{
int u,v,next;
Edge():next(-1){
;}
};
vector<Edge> edge;//[maxn*5];
void init(){
cnt=0;
edge.clear();
for(int i=0;i<maxn;i++){
dis[i]=MAX;
head[i]=-1;
vis[i]=0;
}
}
void add(int u,int v){
Edge t;
t.u=u;
t.v=v;
t.next=head[u];
edge.push_back(t);
head[u]=cnt;
cnt++;
}
class Solution {
public:
int re;
void spfa(int begin){
dis[begin]=0;
vis[begin]=1;
queue<int> q;
q.push(begin);
while(!q.empty()){
int u=q.front();
q.pop();
vis[u]=0;
for(int i=head[u];i!=-1;i=edge[i].next){
int v=edge[i].v;
if(dis[u]+1<dis[v]){
dis[v]=dis[u]+1;
if(!vis[v]){
vis[v]=1;
q.push(v);
}
}
}
}
}
bool compare(string s1,string s2){
int same=0;
for(int i=0;i<s1.size();i++)
if(s1[i]==s2[i])
same++;
return (same+1)==s1.size();
}
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
int ff=0;
for(int i=0;i<wordList.size();i++){
if(wordList[i]==beginWord)
ff=1;
}
if(!ff) wordList.push_back(beginWord);
vector<set<int>> path(wordList.size());
map<string,int> word_map;
vector<int> book(wordList.size(),0);
for(int i=0;i<wordList.size();i++){
word_map[wordList[i]]=i;
}
if(word_map.count(endWord)==0||wordList.size()==1)
return 0;
if(wordList[0].length()==1)
return 2;
init();
for(int i=0;i<wordList.size()-1;i++){
for(int j=i+1;j<wordList.size();j++){
if(compare(wordList[i],wordList[j]))
{
add(i,j);
add(j,i);
}
}
}
spfa(word_map[beginWord]);
if(dis[word_map[endWord]]==MAX) return 0;
else return dis[word_map[endWord]]+1;
}
};
提交的结果
 有点不值所错,在一顿优化之后显示49/49测试用例但还是超出时间限制
有点不值所错,在一顿优化之后显示49/49测试用例但还是超出时间限制
方法二
reference:小象学院
实现思路



 TIP: 如果是这样普通的搜索是不需要纠结是将节点放入队列时处理还是将节点取出时判断是否到达终点,如果要是有特殊的如优先级的需要考虑将节点取出时进行处理
TIP: 如果是这样普通的搜索是不需要纠结是将节点放入队列时处理还是将节点取出时判断是否到达终点,如果要是有特殊的如优先级的需要考虑将节点取出时进行处理
实现代码
 visit数组的含义代表的是当前已经放在队列中的节点
visit数组的含义代表的是当前已经放在队列中的节点

方法三
实现思路(BFS)
主要思路 使用宽度优先搜索
这里面并没有直接基于字符串判断字符串之间的关系,而是将每一个字符进行枚举,当枚举替换单个字符得到的新字符串在WordList中就可以接着往下进行
单向广度优先过程
 双向广度优先搜索过程
双向广度优先搜索过程
头、尾同时开始拓展,当两边拓展到同一个节点时,说明拓展成功

 第二个的步骤就是要两个集合交换前进,当有一个集合新拓展出的节点在另一个集合中就返回结果
第二个的步骤就是要两个集合交换前进,当有一个集合新拓展出的节点在另一个集合中就返回结果
实现代码
单向宽度优先搜索代码
class Solution {
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> dict(wordList.begin(),wordList.end());
if(dict.count(endWord)==0) return 0;
queue<string> q;
q.push(beginWord);
int step=0;
while(!q.empty()){
step++;
int nn=q.size();
for(int i=0;i<nn;i++){
//遍历这一层的所有节点
string w=q.front();q.pop();
int len=w.length();
for(int j=0;j<len;j++){
char ch=w[j];
for(int k=0;k<26;k++){
w[j]='a'+k;
if(w==endWord) return step+1;
if(!dict.count(w)) continue;
dict.erase(w);
q.push(w);
}
w[j]=ch;
}
}
}
return 0;
}
};
双向广度优先搜索
tips:优先拓展较小的那个集合
在后续编写126单词接龙2的时候发现一个重要的问题,就是在判断一个新的字符串,需要先判断是否在q2中然后再判断是否不再字典里,如果反过来可能会出现其实该字符串已经出现在q2里面了,所以dict中没有的情况
class Solution {
public:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> dict(wordList.begin(),wordList.end());
if(dict.count(endWord)==0) return 0;
set<string> q1={
beginWord};
set<string> q2={
endWord};
int step=0;
while(!q1.empty()&&!q2.empty()){
step++;
if(q1.size()>q2.size()){
std::swap(q1,q2);
}
set<string> q;
for(string w:q1){
int len=w.length();
for(int j=0;j<len;j++){
char ch=w[j];
for(int i=0;i<26;i++){
w[j]='a'+i;
if(q2.count(w)) return step+1;
if(!dict.count(w)) continue;
dict.erase(w);
q.insert(w);
}
w[j]=ch;
}
}
std:swap(q,q1);
}
return 0;
}
};
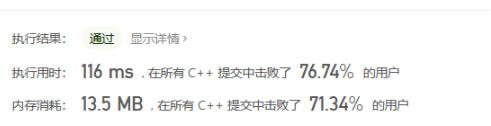
提交结果及分析
- 单向广度搜索提交结果:
- 双向广度搜索提交结果:
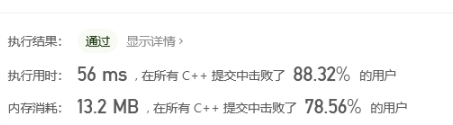
可以明显看到双向宽度搜索的时间减少来一半


总结
方法一优化超时的猜想: 之前有过题目是空间复杂度超了但给出的提示是超时,我估计可能是SPFA存储的大量无向边导致了这样的结果
方法一和方法三的比较: 方法三中每一个字母遍历所有字符看似时间复杂度很高,但方法一却需要付出十分巨大的空间代价,但其实在每一步拓展的时候是基于该字符在wordList里面且没有重复出现的条件,所以最后并没有超时,且代码的编写和实现也比方法一简单很多
所有方法的总结:
方法一和方法二都是先判断两个单词之间的可转换性,考虑最短路,分别用来DFS,SPFA,BFS
方法三里面的都是根据题意字符串所有位置遍历26个字符,看替换结果在wordList里面出现的
宽度优先搜索的应用 在所有路径长度是固定的情况下,使用宽度优先搜索效率较高,双向宽度优先搜索可以降低时间复杂度,当数据量大的情况下优势会更加明显