词频统计、词云+实战
这里主要是介绍了词频统计和词云,至于分词,如果您有什么困惑可以参考我的上一篇 【文本挖掘】——中文分词哦~
一、词频统计:
1.基本概念及原理
这一步是在做完分词之后进行的,所以以下所有步骤都基于分词后构建的词条的list进行。说白了他就是统计每个词在文中出现过多少次,主要目的是为找出频次高的”关键词“打基础。
词频统计的伪代码:

2.词频统计方法
①基于pandas的词频统计:
输出结果为一个序列,该序列每一行的标签就是进行统计的词,数值就是其频数。
#使用pandas进行词频统计
word_list=['july','可爱','傻fufu','聪明','好可爱','精致','猪猪女孩','猪猪女孩','聪明','聪明']
df=pd.DataFrame(word_list,columns=['word'])
result=df.groupby(['word']).size()
freqlist=result.sort_values(ascending=False)
freqlist[:30]
>>word
聪明 3
猪猪女孩 2
精致 1
好可爱 1
可爱 1
傻fufu 1
july 1
dtype: int64
②基于nltk进行词频统计:
其输出结果为频数字典,这就很方便,也很适合后边词云时候用。
#使用NLTK进行词频统计
import nltk
word_list=['july','可爱','傻fufu','聪明','好可爱','精致','猪猪女孩','猪猪女孩','聪明','聪明']
fdlist=nltk.FreqDist(word_list)
print("聪明的词频:",fdlist['聪明'])#查看某个词的频数
print("词条列表:",fdlist.keys())#列出词条列表
print("前五个高频词及其频次为:",fdlist.most_common(5))#输出前五个高频词及其频次
fdlist#输出全部词频统计结果
#fdlist.tabulate(5)#输出前五个高频词,以列表形式输出
>>聪明的词频: 3
词条列表: dict_keys(['july', '可爱', '傻fufu', '聪明', '好可爱', '精致', '猪猪女孩'])
前五个高频词及其频次为: [('聪明', 3), ('猪猪女孩', 2), ('july', 1), ('可爱', 1), ('傻fufu', 1)]
FreqDist({
'聪明': 3, '猪猪女孩': 2, 'july': 1, '可爱': 1, '傻fufu': 1, '好可爱': 1, '精致': 1})
二、词云
将分词结果频数表可视化。对文本中出现频率较高的“关键词”予以视觉上的突出,从而过滤掉大量的文本信息,使读者可以直观领略文本的主旨。
1.词云绘制工具:
主流工具有:Python、R、Tableaus、WordArt.com、Tagxedo.com
R可以展示不同类别间的词云比较和彩色动态效果(这点python做不到,突然感叹R的强大ww)
Tableaus可以实现词云结果的动态监测和展示(这个软件真的超好用,关键是不用写代码,直接拖拽就行,不要太方便~)
WordArt.com、Tagxedo.com是不用下载,不用代码的,直接网页上就可以做,很方便
2.python词云绘制——Wordcloud
①Wordcloud包的安装:
看人品!没错!看人品!所以,pip之前请先扶老奶奶过马路~
很幸运,一下成功,炫耀一下啦,是赤裸裸的炫耀无疑了(捂脸)
你以为successfully你就成功了?太单纯了孩子,赶紧去测试一下吧!Hhh我还真成功了~

这真的是一件很佛的事情,如果你没有一下成功,不要悲伤,请自行百度解决吧,预祝早日成功(手动狗头)
②Wordcloud用法:
首先这是一个类Class。
① 设定字体:大小:min_font_size=1/max_ font_size=None有最小值,上不封顶
字号增加步长:font_step=1
词条频数比例和字号大小比例的换算关系:relative_scaling=0.5默认50%
词条水平显示的比例:Prefer_horizontal=0.9默认90%是水平的,太多竖着的 不方便看
② 设定颜色:图形背景色:background_color=’black’
图形颜色编码:Mode=’RGB’/’RGBA’
调色板:color_func=None这是一个可以生成新颜色的函数,让词云更美观
③ 背景掩模:词云使用的背景图:mask=None
***Text有格式要求:必须用空格或标点符号分割每个词
举个小栗子:
import wordcloud
font='C:/Windows/Fonts/simhei.ttf'#默认不支持中文,这里要从自己电脑上找到喜欢的字体
text='july,可爱,傻fufu,聪明,好可爱,精致,猪猪女孩'
mycloud=wordcloud.WordCloud(font_path=font).generate(text)
print(mycloud)
>><wordcloud.wordcloud.WordCloud object at 0x000001F7F063AE20>
诶?发现词云并没有出来啊,不要急,还有一步可视化:
import matplotlib.pyplot as plt
plt.imshow(mycloud)
plt.axis("off")#隐藏坐标轴,不然巨丑
plt.show()
结果如下:

这个图片乌漆嘛黑的好丑,作为颜狗,我需要给它美化一下:
#更改参数,让它更好看呀
mycloud=wordcloud.WordCloud(font_path=font,width=150,height=150,mode='RGBA',background_color=None).generate(text)
plt.imshow(mycloud)
plt.axis("off")#隐藏坐标轴,不然巨丑
plt.show()

en~这样顺眼多了。
接下来将词云保存成图片:
mycloud.to_file("猪猪词云.png")
这里如果前边用的mode='RGBA‘保存图片时,图片格式要用png,如果mode='RGB‘那就jpg和png都可以。
三、基于分词频数绘制词云
其内部原理为:调用分词函数process_text()和基于频数的绘制函数fit_words(dict),其中dict是一个包括词条和其频数的字典。
1.利用词频绘制词云
话不多说,直接干代码:
#基于分词频数的词云
txt_freq={
'小可爱':10,'菜鸟':5,'聪明':20,'精致':30,'猪猪女孩':40,'傻fufu':38,'july':29}
mycloud=wordcloud.WordCloud(font_path=font).fit_words(txt_freq)
plt.imshow(mycloud)
plt.axis("off")
plt.show()

2.美化词云
毕竟谁都喜欢美女,那今天给词云也打扮一下,让它美美哒~前面提到过的mask派上用场啦!
①自定义词云形状
Mask是用于控制词云的整体形状的,可以让它不只是一个长方形。指定mark后就不需要设定图片的宽度和高度,遮罩形状会被我们所选的形状掩盖。
#设定词云形状
from imageio import imread
mask=imread('D:/zwz/wwxn.png')#这里是一个自己想要的形状的图片
mycloud=wordcloud.WordCloud(font_path=font,mode='RGBA',background_color=None).fit_words(txt_freq)
plt.imshow(mycloud)
plt.axis("off")
plt.show()

这里词太少了,不太能显出形状,但可以看出他不是一个长方形啦。
两点要注意:①选择图形的时候要避免细长的,因为太细太窄的地方,可能词条宽度没有那么小,就会失去控制,做不出来想要的现状。②要用白底没有背景的图片
②自定义图片色系
步骤:读取指定图片的色系设定
获取图片颜色
重置词云颜色
#指定图片色系
import numpy as np
imgo=imread("D:/zwz/wwxn.png")#这里是一个自己想要的颜色的图片
image_color=wordcloud.ImageColorGenerator(np.array(imgo))
mycloud.recolor(color_func=image_color)
plt.imshow(mycloud)
plt.axis("off")#隐藏坐标轴,不然巨丑
plt.show()

后边还有<微微一笑很倾城>的实战哦~ 今天太累了,明天再搞,晚安 To 陌生人
四、实战篇——《微微一笑很倾城》
1.语料库准备
这篇小说《微微一笑很倾城》可以点击该链接直接下载txt版,然后将其导入进来:
import jieba
import pandas as pd
ww=pd.read_table('D:/zwz/ww.txt',names=['txt'],sep='aaa',encoding='utf_8')
print(len(ww))
ww
其导入结果为一个4821行一列的Dataframe:
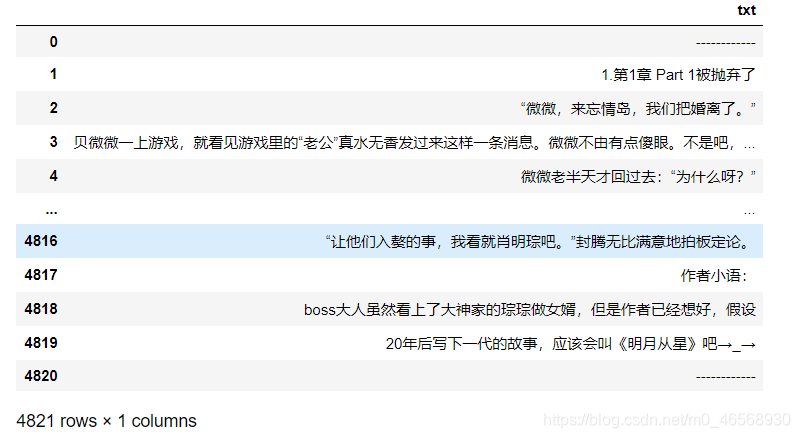
如果我们只想分析其中的某一章或某几章,可以通过下面的章节标识进行:分析该文章发现,每一章的开头是“1.第一章xxx、2.第二章xxx…"因此要进行章节识别,只需要找到符合该开头的位置即可。在这里ww[‘head’]用来识别一句话开头的第三个字符,在第一到第九章时,第三个字符均为”第“,在第十到最后一章,第三个字符均为”.“。ww[‘mid’]用来查找字符”章“,ww[‘len’]在后文用来限制查找的一句话的长度:
#加入章节标识
def m_head(tmpstr):
return tmpstr[2:3]
def m_mid(tmpstr):
return tmpstr.find("章 ")
ww['head']=ww.txt.apply(m_head)
ww['mid']=ww.txt.apply(m_mid)
ww['len']=ww.txt.apply(len)
ww.head(30)
返回一个包含每一行文本以及其开头字符、中间字符和字符长度的Dataframe:
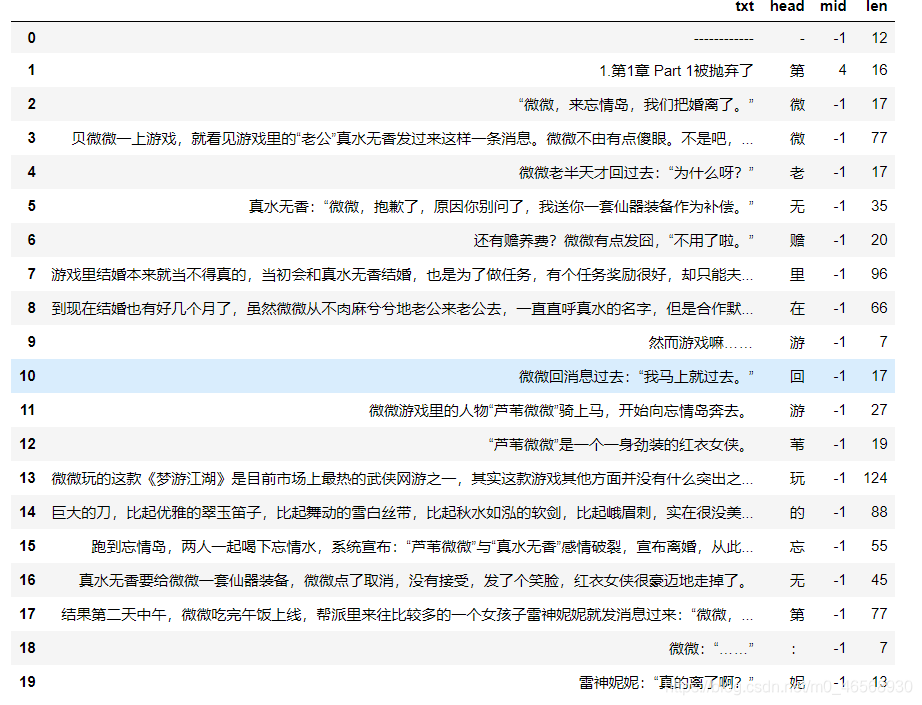
接下来就可以提取想要的章节了:首先要找到一章的开头,是靠这句实现的:<if ww[‘head’][i]"第"and ww[‘mid’][i]>0 and ww[‘len’][i]<30 or ww[‘head’][i]"." >。在这里我只想要正文,不要后记和番外,因此筛选条件为:if chapnum>=50 and ww[‘txt’][i]==“50.番外一 A大美女排行榜”。
chapnum=0
for i in range(len(ww)):
if ww['head'][i]=="第"and ww['mid'][i]>0 and ww['len'][i]<30 or ww['head'][i]=="." :
chapnum+=1
if chapnum>=50 and ww['txt'][i]=="50.番外一 A大美女排行榜":
chapnum=0
ww.loc[i,'chap']=chapnum
del ww['head']
del ww['mid']
del ww['len']
#提取所需章节
ww[ww.chap==49]
这样我就可以随心所欲提取任何一章啦~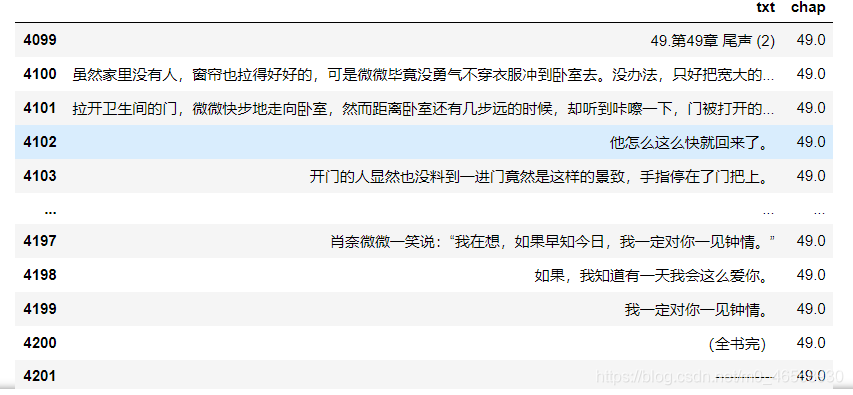
下面我要进行分词、词频统计等处理,需要将提取的章节放进一个list,这里放进了chapter.txt[1]:
wwgrp=ww.groupby('chap')
chapter=wwgrp.agg(sum)
chapter=chapter[chapter.index!=0]
chapter.txt[1]
len(chapter)
>>49
2.分词
首先从搜狗细胞词库下载《微微一笑很倾城》的词典。在分词中,词典和停用库的修改是一个比较重要的点,需要根据结果和对原文的理解不断完善:
#分词
import pandas as pd
#词典
dict='D:/zwz/cikuww.txt'
jieba.load_userdict(dict)
#停用词
tyc=pd.read_csv('D:/zwz/停用词.txt',names=['w'],sep="aaa",encoding='utf-8')
word_list=[w for w in jieba.cut(chapter.txt[1]) if w not in list(tyc.w)]
print(len(word_list))
word_list
在这里我总共是分出来790个词,但我还有一个问题没有解决:怎么在停用库里添加空格呢?这里分词结果里还有空格想要去除,但没有实现,如果有大佬看到了,麻烦指教,不胜感激~

3.词频统计
我后面要做词云,将词频统计结果输出为字典会很方便,所以就用NLTK啦:
#使用NLTK进行词频统计
import nltk
fdlist=nltk.FreqDist(word_list)
fdlist['微微']#查看某个词的频数
fdlist.keys()#列出词条列表
fdlist.tabulate(5)#输出前五个高频词,以列表形式输出
fdlist.most_common(5)#输出前五个高频词及其频次
>>微微 林教授 名字 游戏
45 16 14 9 6
[('微微', 45),
('林教授', 16),
('名字', 14),
('游戏', 9),
(' ', 6)]
3.词云绘制及美化
跟前面一样的就不多叨叨了:
mycloud=wordcloud.WordCloud(font_path=font,width=1080,height=1080,mode='RGBA',background_color=None).fit_words(fdlist)
plt.imshow(mycloud)
plt.axis("off")#隐藏坐标轴,不然巨丑
plt.show()
呐~就是这样啦:

我想把它做成微微和肖奈合照形状的:(这里还没有抠图,形状显示不出来…后面有时间了再更改吧)
#设定微微和大神形状和颜色
from imageio import imread
mask=imread('D:/zwz/wwxn.png')
mycloud=wordcloud.WordCloud(font_path=font,mode='RGBA',background_color=None).fit_words(fdlist)
image_color=wordcloud.ImageColorGenerator(np.array(imgo))
mycloud.recolor(color_func=image_color)
plt.imshow(mycloud)
plt.axis("off")#隐藏坐标轴,不然巨丑
plt.show()
效果图就是这个样子了:

好啰嗦搞了这么长一篇,虽然很简单,但还是比较有成就感嘻嘻**。如果您看到了这里,麻烦指教我里边关于去掉空格停用词的困惑呢,欢迎指出其他问题,我们一起学习一起进步鸭!(当然也希望您能点个小赞支持一下)感谢~