一、简介
1 概述
BP(Back Propagation)神经网络是1986年由Rumelhart和McCelland为首的科研小组提出,参见他们发表在Nature上的论文 Learning representations by back-propagating errors 。
BP神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的 输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断 调整网络的权值和阈值,使网络的误差平方和最小。
2 BP算法的基本思想
上一次我们说到,多层感知器在如何获取隐层的权值的问题上遇到了瓶颈。既然我们无法直接得到隐层的权值,能否先通过输出层得到输出结果和期望输出的误差来间接调整隐层的权值呢?BP算法就是采用这样的思想设计出来的算法,它的基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。
正向传播时,输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出(教师信号)不符,则转入误差的反向传播阶段。
反向传播时,将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
这两个过程的具体流程会在后文介绍。
BP算法的信号流向图如下图所示
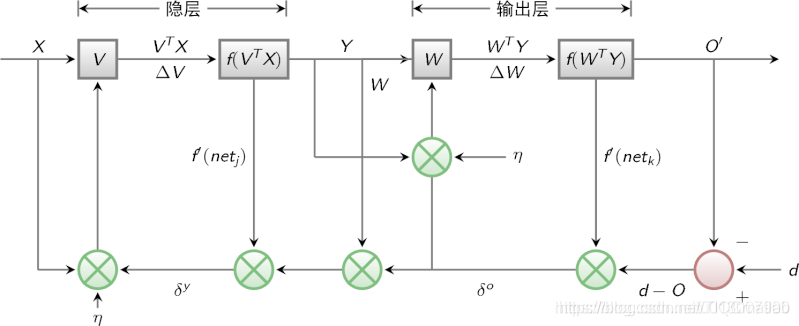
3 BP网络特性分析——BP三要素
我们分析一个ANN时,通常都是从它的三要素入手,即
1)网络拓扑结构;
2)传递函数;
3)学习算法。
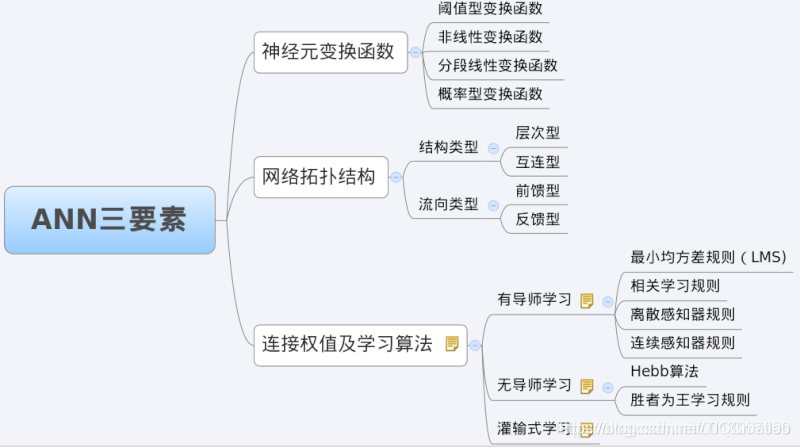
每一个要素的特性加起来就决定了这个ANN的功能特性。所以,我们也从这三要素入手对BP网络的研究。
3.1 BP网络的拓扑结构
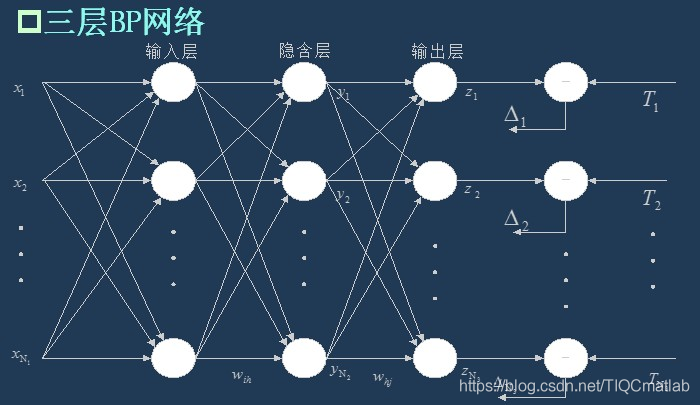
上一次已经说了,BP网络实际上就是多层感知器,因此它的拓扑结构和多层感知器的拓扑结构相同。由于单隐层(三层)感知器已经能够解决简单的非线性问题,因此应用最为普遍。三层感知器的拓扑结构如下图所示。
一个最简单的三层BP:
3.2 BP网络的传递函数
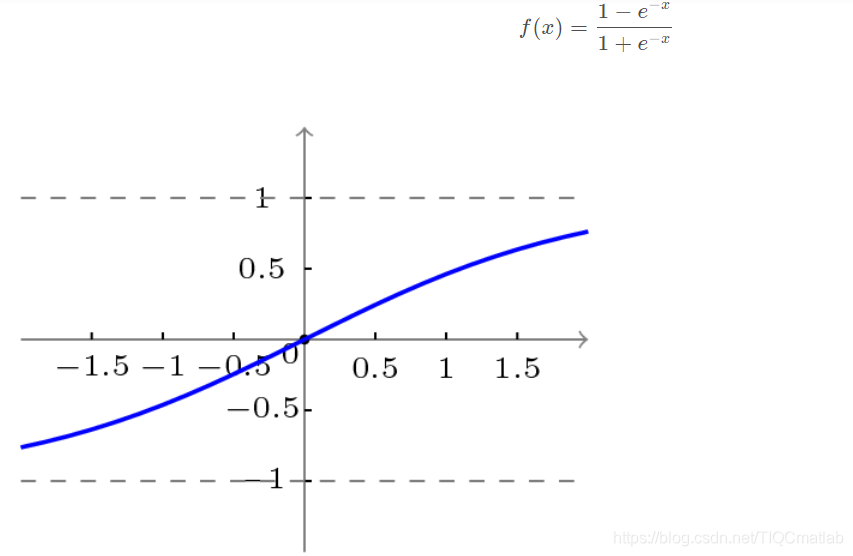
BP网络采用的传递函数是非线性变换函数——Sigmoid函数(又称S函数)。其特点是函数本身及其导数都是连续的,因而在处理上十分方便。为什么要选择这个函数,等下在介绍BP网络的学习算法的时候会进行进一步的介绍。
单极性S型函数曲线如下图所示。
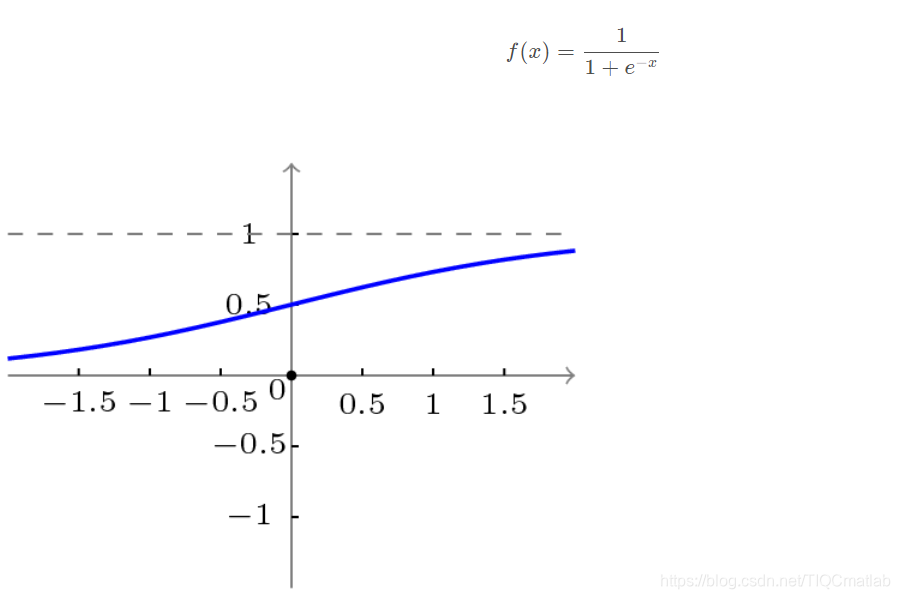
双极性S型函数曲线如下图所示。
3.3 BP网络的学习算法
BP网络的学习算法就是BP算法,又叫 δ 算法(在ANN的学习过程中我们会发现不少具有多个名称的术语), 以三层感知器为例,当网络输出与期望输出不等时,存在输出误差 E ,定义如下



下面我们会介绍BP网络的学习训练的具体过程。
4 BP网络的训练分解
训练一个BP神经网络,实际上就是调整网络的权重和偏置这两个参数,BP神经网络的训练过程分两部分:
前向传输,逐层波浪式的传递输出值;
逆向反馈,反向逐层调整权重和偏置;
我们先来看前向传输。
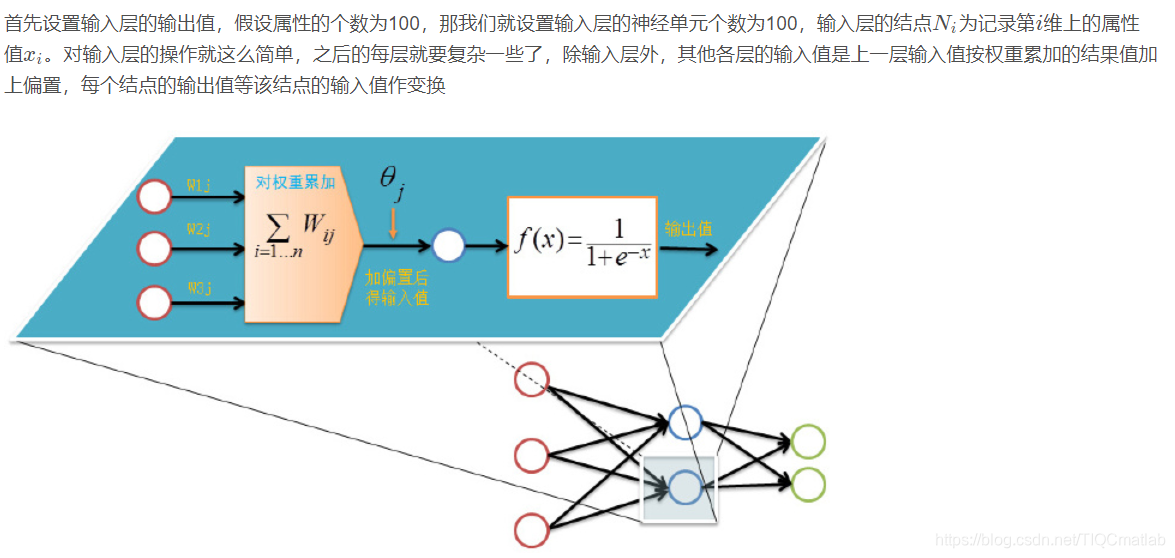
前向传输(Feed-Forward前向反馈)
在训练网络之前,我们需要随机初始化权重和偏置,对每一个权重取[ − 1 , 1 ] [-1,1][−1,1]的一个随机实数,每一个偏置取[ 0 , 1 ] [0,1][0,1]的一个随机实数,之后就开始进行前向传输。
神经网络的训练是由多趟迭代完成的,每一趟迭代都使用训练集的所有记录,而每一次训练网络只使用一条记录,抽象的描述如下:
while 终止条件未满足:
for record:dataset:
trainModel(record)

4.1 逆向反馈(Backpropagation)


4.2 训练终止条件
每一轮训练都使用数据集的所有记录,但什么时候停止,停止条件有下面两种:
设置最大迭代次数,比如使用数据集迭代100次后停止训练
计算训练集在网络上的预测准确率,达到一定门限值后停止训练
5 BP网络运行的具体流程
5.1 网络结构
输入层有n nn个神经元,隐含层有p pp个神经元,输出层有q qq个神经元。
5.2 变量定义


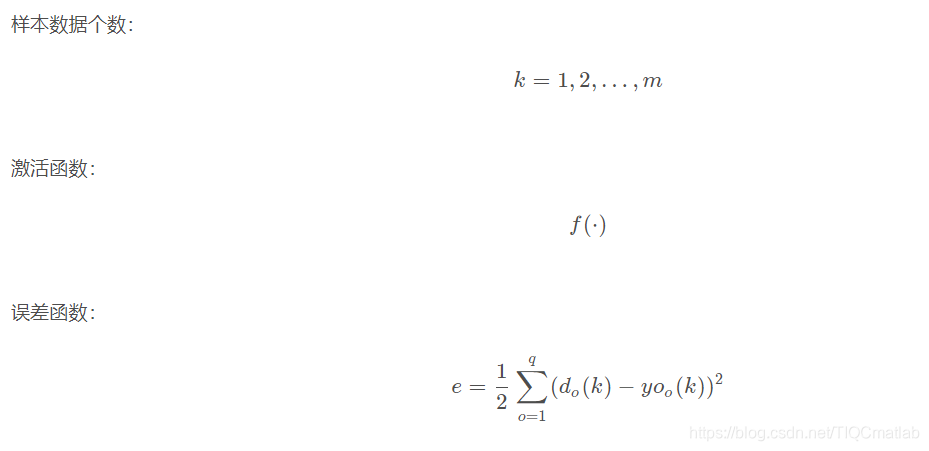


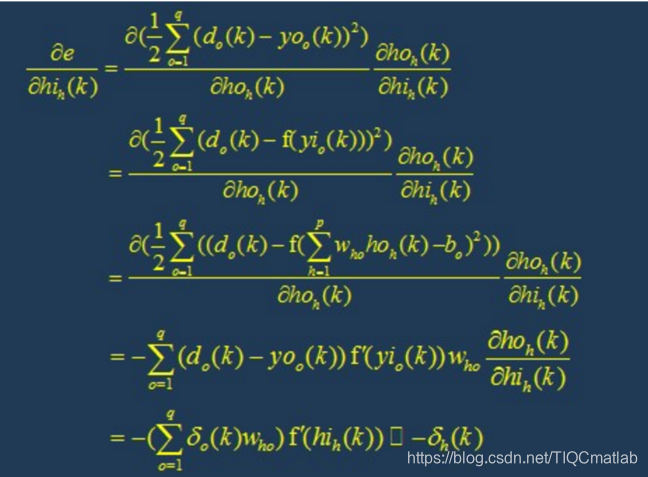


第九步:判断模型合理性
判断网络误差是否满足要求。
当误差达到预设精度或者学习次数大于设计的最大次数,则结束算法。
否则,选取下一个学习样本以及对应的输出期望,返回第三部,进入下一轮学习。
6 BP网络的设计
在进行BP网络的设计是,一般应从网络的层数、每层中的神经元个数和激活函数、初始值以及学习速率等几个方面来进行考虑,下面是一些选取的原则。
6.1 网络的层数
理论已经证明,具有偏差和至少一个S型隐层加上一个线性输出层的网络,能够逼近任何有理函数,增加层数可以进一步降低误差,提高精度,但同时也是网络 复杂化。另外不能用仅具有非线性激活函数的单层网络来解决问题,因为能用单层网络解决的问题,用自适应线性网络也一定能解决,而且自适应线性网络的 运算速度更快,而对于只能用非线性函数解决的问题,单层精度又不够高,也只有增加层数才能达到期望的结果。
6.2 隐层神经元的个数
网络训练精度的提高,可以通过采用一个隐含层,而增加其神经元个数的方法来获得,这在结构实现上要比增加网络层数简单得多。一般而言,我们用精度和 训练网络的时间来恒量一个神经网络设计的好坏:
(1)神经元数太少时,网络不能很好的学习,训练迭代的次数也比较多,训练精度也不高。
(2)神经元数太多时,网络的功能越强大,精确度也更高,训练迭代的次数也大,可能会出现过拟合(over fitting)现象。
由此,我们得到神经网络隐层神经元个数的选取原则是:在能够解决问题的前提下,再加上一两个神经元,以加快误差下降速度即可。
6.3 初始权值的选取
一般初始权值是取值在(−1,1)之间的随机数。另外威得罗等人在分析了两层网络是如何对一个函数进行训练后,提出选择初始权值量级为s√r的策略, 其中r为输入个数,s为第一层神经元个数。
6.4 学习速率
学习速率一般选取为0.01−0.8,大的学习速率可能导致系统的不稳定,但小的学习速率导致收敛太慢,需要较长的训练时间。对于较复杂的网络, 在误差曲面的不同位置可能需要不同的学习速率,为了减少寻找学习速率的训练次数及时间,比较合适的方法是采用变化的自适应学习速率,使网络在 不同的阶段设置不同大小的学习速率。
6.5 期望误差的选取
在设计网络的过程中,期望误差值也应当通过对比训练后确定一个合适的值,这个合适的值是相对于所需要的隐层节点数来确定的。一般情况下,可以同时对两个不同 的期望误差值的网络进行训练,最后通过综合因素来确定其中一个网络。
7 BP网络的局限性
BP网络具有以下的几个问题:
(1)需要较长的训练时间:这主要是由于学习速率太小所造成的,可采用变化的或自适应的学习速率来加以改进。
(2)完全不能训练:这主要表现在网络的麻痹上,通常为了避免这种情况的产生,一是选取较小的初始权值,而是采用较小的学习速率。
(3)局部最小值:这里采用的梯度下降法可能收敛到局部最小值,采用多层网络或较多的神经元,有可能得到更好的结果。
8 BP网络的改进
P算法改进的主要目标是加快训练速度,避免陷入局部极小值等,常见的改进方法有带动量因子算法、自适应学习速率、变化的学习速率以及作用函数后缩法等。 动量因子法的基本思想是在反向传播的基础上,在每一个权值的变化上加上一项正比于前次权值变化的值,并根据反向传播法来产生新的权值变化。而自适应学习 速率的方法则是针对一些特定的问题的。改变学习速率的方法的原则是,若连续几次迭代中,若目标函数对某个权倒数的符号相同,则这个权的学习速率增加, 反之若符号相反则减小它的学习速率。而作用函数后缩法则是将作用函数进行平移,即加上一个常数。
二、源代码
%这是用BP神经网络通过MATLAB预测我国CPI指数的源码
%以2010年4月前的CPI指数为原始数据,预测2010年4、5、6三月的CPI指数
p=[101.2
100
100.8
101.6
101.7
101.4
101.5
101
99.9
100.2
99.7
99
100
99.2
98.7
98.9
99.2
99.1
99.3
99.3
99.2
99.3
99.6
100.4
100.2
100.9
101
100.7
100.3
100.5
100.9
101.1
101.8
103
103.2
103.2
102.1
103
103.8
104.4
105
105.3
105.3
105.2
104.3
102.8
102.4
101.9
103.9
102.7
101.8
101.8
101.6
101.8
101.3
100.9
101.2
101.3
101.6
101.9
100.9
100.8
101.2
101.4
101.5
101
101.3
101.5
101.4
101.9
102.8
102.2
102.7
103.3
103
103.4
104.4
105.6
106.5
106.2
106.5
106.9
106.5
107.1
108.7
108.3
108.5
107.7
107.1
106.3
104.9
104.6
104
102.4
101.2
101
98.4
98.8
98.5
98.6
98.3
98.2
98.8
99.2
99.5
100.6
101.9
101.5
102.7
102.4];%CPI原始数据
p=p';
q=length(p)
input=5;
c=q-input;
P=zeros(5,c);%以每5年进行一次训练
P(1,1:c)=p(1,1:c);
P(2,1:c)=p(1,2:c+1);
P(3,1:c)=p(1,3:c+2);
P(4,1:c)=p(1,4:c+3);
P(5,1:c)=p(1,5:c+4);
T=p(1,6:c+5);
%net=newlin([95,130;95,130;95,130;95,130;95,130],1)
%net.trainParam.epochs=200
%[net,tr]=train(net,P,T)
net=newlind(P,T)
a=sim(net,P);
na=norm(a-T);
plot(a,T,'*')%散点图
三、运行结果

四、备注
完整代码或者代写添加QQ 1564658423