泛型
不使用泛型,使用集合时编程比较复杂
List list=new ArrayList();
list.add(123); //自动向上转型 int–>Integer–>Object
//获取数据还需要窄化操作
int kk=(Integer)list.get(0); //不进行类型判断,有可能出现 ClassCastException
使用泛型,可以将运行时的类型检查搬到编译期实现;同时获取数据时不需要再编码进行类型转换List list=new ArrayList<>(); //从 JDK1.7+支持泛型推导
list.add(123);
list.add(new Random());//编译报错
int kk=list.get(0); //不需要进行强制类型转
什么是泛型
泛型是 jdk5 引入的类型机制,就是将类型参数化,泛型作为一种安全机制而产生
泛型在本质上是指类型参数化。所谓类型参数化,是指用来声明数据的类型本身,也是可以改变的,它由实际参数来决定。在一般情况下,实际参数决定了形式参数的值。而类型参数化,则是实际参数的类型决定了形式参数的类型。
使用泛型的优势
1、可读性,从字面上就可以判断集合中的内容类型;
2 、类型检查,避免插入非法类型。
3 、获取数据时不在需要强制类型转换。
带两个类型参数的泛型类
如果引用多个类型,可以使用逗号分隔:<S, D>
类型参数名可以使用任意字符串,建议使用有代表意义的单个字符,以便于和普通类型名区分,如:T 代表 type,有源数据和目的数据就用 S/D,子元素类型用 E 等。当然,你也可以定义为 XYZ,甚至 xyZ。泛型中的类型参数严格说明集合中装载的数据类型是什么和可以加入什么类型的数据,记住:Collection 和 Collection 是两个没有转换关系的参数化的类型
带两个类型参数的泛型类
如果引用多个类型,可以使用逗号分隔:<S, D>
类型参数名可以使用任意字符串,建议使用有代表意义的单个字符,以便于和普通类型名区
分,如:T 代表 type,有源数据和目的数据就用 S/D,子元素类型用 E 等。当然,你也可
以定义为 XYZ,甚至 xyZ。泛型中的类型参数严格说明集合中装载的数据类型是什么和可以加入什么类型的数据,记
住:Collection 和 Collection 是两个没有转换关系的参数化的类型集合类中定义范型
有界类型
public class MyClass{ }表示允许传入给 T
的类型必须是 Number 类型的子类型或者 Number 类型MyClass mc=new MyClass(); 语法正确,因为 Integer 是Number 的子类型MyClass mc=new MyClass<>(); 语法错误,因为 String 不是 Number 类型
声明泛型可以给泛型添加约束
Java 提供了有界类型 bounded types。在指定一个类型参数时,可以指定一个上界,声明所有的实际类型都必须是这个超类的直接或间接子类。class classname
接口和类都可以用来做上界。
类充当上界 public class Oper
接口充当上界 class Stats这里需要注意:针对上界接口使用的关键字仍然是 extends 而非 implements
通配符参数
使用一般用于接收参数void doSomething(Stats<?> ob) 表示这个参数 ob 可以是任意的 Stats 类型。其中?表示一个不确定的类型,它的值会在调用时确定下来。 List<?> list = new ArrayList();
泛型方法
所谓泛型方法,就是带有类型参数的方法,它既可以定义在泛型类中(例如 public void show(T aa),在使用泛型上没有任何特殊语法要求),也可以定义在普通类中(需要自定义参数类型,那么把泛型参数放在方法上就可以了,就是放在返回值类型之前,例如 public void show(T aa)), 静态方法不能访问类的泛型,如果需要泛型只能在方法上使用泛型,例如 public static void show(T aa)
在泛型类中包含泛型的方法
Set接口的定义
Set接口是Collection接口的子接口
无序、不允许重复[重复元素的添加会产生覆盖]
没有新方法
boolean add(E e);向集合中追加元素e对象,如果出现重复则后盖前
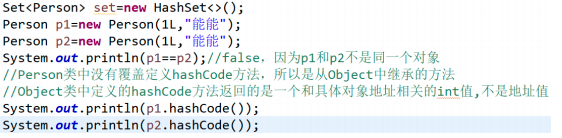
问题:如何判断两个元素相等
首先比较两个对象的hashcode值是否相等,如果hashcode值不相等则不会调用equals,认为两个对象不相等
如果hashcode值相等才调用equals进行比较,否则不相等
潜规则【不是语法】:SUN要求当两个对象的equals为true时,hashcode值应该相等
实现类HashSet
类定义

数据的存储方式

底层实现方法:存储到 Set 中的所有数据最终都存储在一个 HashMap 中,其中存储的数
据采用 key 的方式进行存储,值为 PRESENT 常量
常用算法
boolean add(E e)向集合 Set 中添加元素,注意不保证顺序
同一个内容的对象,为什么没有出现覆盖的效果?
- 设置 hashCode 和 equals 方法的调用

比对两个对象相等,调用流程为:1、调用对象的 hashcode 方法,如果 hashCode 不相
等则返回,认为两个对象不相等。2、如果 hash 值相等则调用 equals 判断
潜规则要求:定义类时需要定义对应的 hashCode 和 equals 方法,要求:当 equals 为 true
时,hash 值必须相等;当 hash 值相等时不一定 equals 为 true
选择参与比较的属性值即可,IDE 工具自动生成对应的方法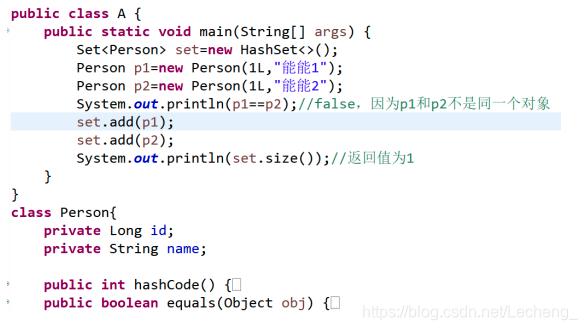
boolean remove(Object o) 删除指定对象,同样需要 hashCode 和 equals 方法
void clear()清空集合中的所有元素
boolean contains(Object o)判断集合中是否有指定的对象,同样需要 hashCode 和equals 方法
int size()获取集合中的元素个数
Iterator iterator()用于遍历所存储的数据
Set<String> set = new LinkedHashSet<>();
set.add("abcd");
set.add("123");
Iterator<String> it=set.iterator();
while(it.hasNext()) {
String tmp=it.next();
System.out.println(tmp);
}
HashSet 的特征
无序:不仅不能保证元素插入的顺序(如果需要顺序则可以使用
LinkedHashSet),而且在元素在以后的顺序中也可能变化(这是由 HashSet 按 HashCode 存储对象(元素)决定的,对象变化则可能导致 HashCode 变化)如果需要访问的顺序和插入的顺序一致,可以使用 HashSet 的子类 LinkedHashSet不允许重复 [equals 和 hashcode]
结论:当 HashSet 判定对象重复时,首先调用的是对象的 hashCode 方法,如果两个对象的 hashCode 值相同时,才调用 equals 进行判定。如果 hashCode 值不相等则不会调用equals 判断。如果 hashcode 相等而且 equals 为 true,则后盖前。
HashSet 是线程非安全的,方法上没有同步约束。
HashSet 元素值可以为 NULL。
LinkedHashSet
类定义

没有什么新方法,仅仅只是在 HashSet 的基础上添加了一个链表结构记录存取的顺序
LinkedHashSet 是 HashSet 的一个子类,LinkedHashSet 也根据 HashCode 的值来决定元素的存储位置,但同时它还用一个链表来维护元素的插入顺序,插入的时候即要计算hashCode 又要维护链表,而遍历的时候只需要按链表来访问元素
TreeSet
TreeSet 实现了 SortedSet 接口,顾名思义这是一种排序的 Set 集合

数据存储采用的是

在 map 中以 key 为需要存放的数据,以 PERSENT 常量为值存放数据
内部实现
底层是用 TreeMap 实现的,本质上是一个红黑树原理。正因为它是排序了的,所以相对HashSet 来说,TreeSet 提供了一些额外的按排序位置访问元素的方法,例如 first(), last(), lower(), higher(), subSet(), headSet(), tailSet()
基本用法

TreeSet 的排序分两种类型,一种是自然排序,另一种是定制排序。
编程使用 TreeSet
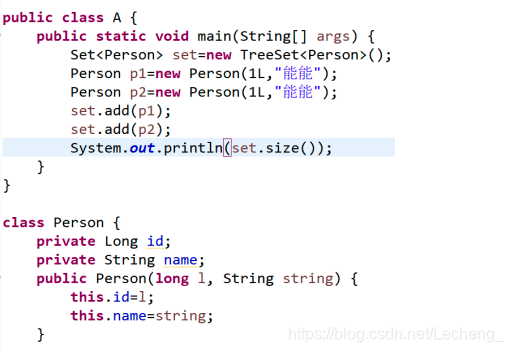

原因是:添加到 TreeSet 中要求对象必须是可比较的
注意: 要求添加到 TreeSet 中的元素类型必须实现 Comparable 接口
public class A {
public static void main(String[] args) {
Set<Person> set=new TreeSet<Person>();
Person p1=new Person(1L,"能能");
Person p2=new Person(1L,"能能");
set.add(p1);
set.add(p2);
System.out.println(set.size());
System.out.println(p1==p2);
System.out.println(p1.equals(p2));
}
}
class Person implements Comparable<Person>{
private Long id;
private String name;
public Person(long l, String string) {
this.id=l;
this.name=string;
}
@Override
public int compareTo(Person o) {
//判空处理省略
int res=name.compareTo(o.name);
if(res==0) {
res=id.compareTo(o.id);
}
return res;
}
}
如果使用 TreeSet 时不会依靠 hashcode 和 equals 进行比较,相等性判断是依靠
compareTo 实现的
自然排序(在元素中写排序规则)
TreeSet 会调用 compareTo 方法比较元素大小,然后按升序排序(从小到达)。所以自然排序中的元素对象,都必须实现了 Comparable 接口,否则会抛出异常。对于 TreeSet 判断元素是否重复的标准,也是调用元素从 Comparable 接口继承而来 compareTo 方法,如果返回 0 则是重复元素。Java 的常见类都已经实现了 Comparable 接口给 Person 类上添加针对 Comparable 接口的实现:考虑具体的业务规则,按照类中什么属性进行排序比较。
