“爱”的宣言:本系列的目的是帮助一些零基础小白能够快速上手爬虫。因为作者本人也是一个刚入门不久的零基础小白,深知自学(乱学 )的痛苦。本系列的知识可能不会像一些大佬的文章那般系统,但仍希望能帮助到一些小伙伴,同时,也希望能结识一些小伙伴。
本系列可能会有多篇,为了方便您的阅读,下面给出各文章之间的超链接传送门。
系列文章链接(未完待续):
PyCharm自定义背景图片、更换主题
面向零基础小白的爬虫系列(一):字符串
面向零基础小白的爬虫系列(二):列表与元组
面向零基础小白的爬虫系列(三):字典
面向零基础小白的爬虫系列(四):库
面向零基础小白的爬虫系列(五):循环语句与条件语句
面向零基础小白的爬虫系列(六):正则表达式
一、前言
上一篇讲到使用正则表达式来定位获取目标数据。这一篇来简单的看一下,使用Beautiful Soup来定位获取数据。
本系列文章,代码运行展示,将使用PyCharn进行运行。
二、Beautiful Soup
像上一篇一样,先给大家安利一篇文章,简单看一下用法。
这位大佬写的,我感觉比较全面,我们今天就简单看一下,其中的CSS选择器。
| 格式 | 作用 |
|---|---|
| 节点名 | 指定标签来匹配 |
| . | 通过类名来查找 |
| # | 通过id来查找 |
怎么理解呢?
直接进入实战对抗!
实战对抗
首先,打开上一篇进行爬取的目标网页:4k汽车壁纸
接着导库
import requests
import bs4
接着获取响应
url = 'https://pic.netbian.com/4kqiche/'
response = requests.get(url=url)
text = response.text
进行爬虫的第一步和第二步都是一样的,那么直接跳转到第三步。
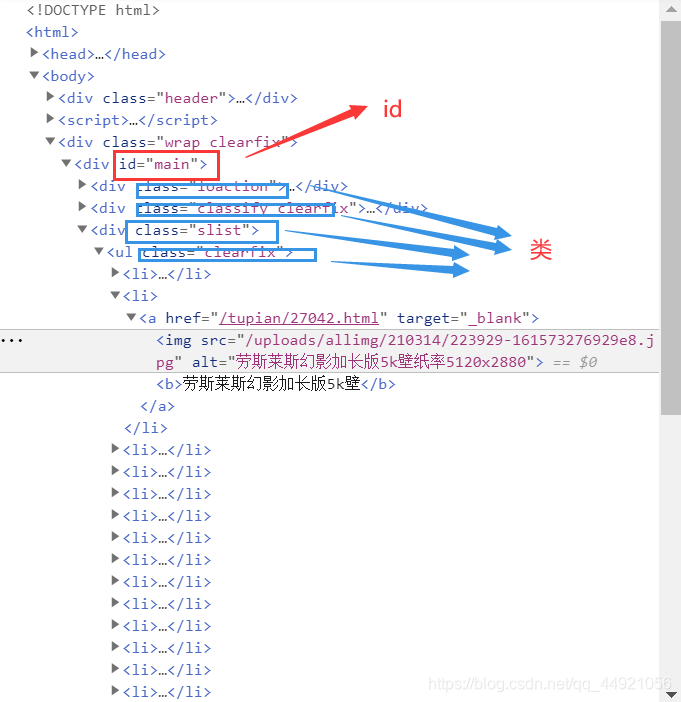
还是昨天那张图,不过和昨天标注的不太一样。
进行定位之前,我们要对“汤”进行包装一下。
soup = bs4.BeautifulSoup(text, 'html.parser')
接着,就可以定位了,尽量根据id定位,当然,根据类名也是可以的,这个小实战就适合类名定位。
image_urls = soup.select('.clearfix li a img') # 注意.clearfix和li中间是有空格的
这个定位的目的就是先找到类名为
clearfix的节点,在找到它下面名为li的子节点,再找到a节点,再找到img节点
打印一下,可以看到是一个列表,那么久需要对列表进行遍历,得到每一个结果。
那么接下来就是对图片链接的提取了。
使用get方法
for i in range(len(image_urls)):
image_url = image_urls[i]
image = image_url.get('src')

完整代码
import requests
import bs4
url = 'https://pic.netbian.com/4kqiche/'
response = requests.get(url=url)
text = response.text
soup = bs4.BeautifulSoup(text, 'html.parser')
image_urls = soup.select('.clearfix li a img') # 注意.clearfix和li中间是有空格的
for i in range(len(image_urls)):
image_url = image_urls[i]
image = image_url.get('src')
print(image)
三、Blogger’s speech
可以根据上一篇的思路,使用这种方法来练习bs4的使用嗷,补赶紧尝试一下吗?
如有不足,还请大佬评论区留言或私信我,我会进行补充。
感谢您的支持,希望可以点赞,关注,收藏,一键三连哟。
作者:远方的星
CSDN:https://blog.csdn.net/qq_44921056
腾讯云:https://cloud.tencent.com/developer/column/91164
本文仅用于交流学习,未经作者允许,禁止转载,更勿做其他用途,违者必究。