2.4 INT8量化实现-校准实现(python)
下一篇详细说说代码实现的细节部分,以及相关的知识,比如我们为什么要做分布的smooth处理。
第三章INT8移动端实现
在这部分,我将以自顶向下的方式叙述INT8的kernel实现原理及过程,其中包括开源的NCNN INT8版本以及我优化后INT8版本(QNNPACK INT8版本在《QNNPACK调研》中有详细论述,此文略过仅在最后做数据对比)。
3.1 NCNN INT8实现
3.1.1 底层量化处理整体流程
在每层计算时是需要先将feature map量化到INT8,然后将weights量化到INT8,最后卷积计算得到INT32的输出值,输出值乘以scale(float)值反量化到float,然后加上浮点格式的bias作为下一层的输入。
3.1.2 量化前处理
NCNN的quantize.cpp函数里面有其量化的实现,所有的input,weights均是float32的,都通过此方法进行处理,核心代码是:
for (int i=0; i<size; i++)
{
outptr[i] = float2int8(ptr[i] * scale);
}
static inline signed char float2int8(float v)
{
int int32 = round(v);
if (int32 > 127) return 127;
if (int32 < -128) return -128;
return (signed char)int32;
}
代码的思路很直接,就是把你上位机校准程序得到的scale参数乘以浮点值,给压缩到int8的范围内来,然后直接float2int转换,最后做下边界处理,这样量化的前处理就处理好了。(注: 跟int16定点的处理方式没有本质的差异的,对比我之前的Int16量化原理分析文章。)
3.1.3 量化计算
NCNN的convolution_1x1_int8.h中有其实现,分别支持了Armv7跟Armv8,这里仅就Armv7进行讲解,最后再点出Armv8跟其的不同之处即可类推。
static void conv1x1s1_int8_neon(const Mat& bottom_blob,
Mat& top_blob,
const Mat& _kernel,
const Option& opt)
{
int size = top_blob.h * top_blob.w;
int remain = size & 7;
typedef void (*conv_func_int8)(const Mat&, Mat&, const Mat&, const Option&);
conv_func_int8 conv_func_table[8] =
{
conv1x1s1_neon_s8, //0
conv1x1s1_neon_s8, //1
conv1x1s1_neon_s8, //2
conv1x1s1_neon_s8, //3
conv1x1s1_neon_s8_left4, //4
conv1x1s1_neon_s8, //5
conv1x1s1_neon_s8, //6
conv1x1s1_neon_s8, //7
};
conv_func_int8 conv = conv_func_table[remain];
conv(bottom_blob, top_blob, _kernel, opt);
return;
}
这个是int8计算的统一入口,根据输出blob的size来对8求余,根据余数来决定使用哪种kernel实现,这也是常规的边界处理方法,这里只有在余数是4的情况下需要特别处理的,我们不看特例就只看通常情况下的conv1x1s1_neon_s8吧!
/*
* Convolution 1x1 quantized with int8,unroll 8 x 4
*/
static void conv1x1s1_neon_s8(const Mat& bottom_blob, Mat& top_blob,
const Mat& _kernel,
const Option& opt)
根据接口描述可知Armv7模式下是按照4*8展开的,具体如何展开我们进去一探究竟。
简化代码逻辑后流程如下:
int nn_outch = outch >> 2; //输出channel除以4;
for (int pp=0; pp<nn_outch; pp++)
{
int p = pp * 4;
Mat out0 = top_blob.channel(p); // 取出4channel位置。
Mat out1 = top_blob.channel(p+1);
Mat out2 = top_blob.channel(p+2);
Mat out3 = top_blob.channel(p+3);
out0.fill(0); // 填充为0;
out1.fill(0);
out2.fill(0);
out3.fill(0);
int q = 0;
for (; q+7<inch; q+=8)
{
int* outptr0 = out0; // 注意是按照int格式定位数据的!因为我们是按照int32输出
int* outptr1 = out1;
int* outptr2 = out2;
int* outptr3 = out3;
// 输入层是int8的,也就是在进行forward之前就已经把之quantize好了。输入channel取8个;
const signed char* r0 = bottom_blob.channel(q);
const signed char* r1 = bottom_blob.channel(q+1);
const signed char* r2 = bottom_blob.channel(q+2);
const signed char* r3 = bottom_blob.channel(q+3);
const signed char* r4 = bottom_blob.channel(q+4);
const signed char* r5 = bottom_blob.channel(q+5);
const signed char* r6 = bottom_blob.channel(q+6);
const signed char* r7 = bottom_blob.channel(q+7);
// 同样的kernel也是在初始化的时候就已经quantize好了。取4个kernel的前8个;
const signed char* kernel0 = (const signed char*)kernel + p*inch + q;
const signed char* kernel1 = (const signed char*)kernel + (p+1)*inch + q;
const signed char* kernel2 = (const signed char*)kernel + (p+2)*inch + q;
const signed char* kernel3 = (const signed char*)kernel + (p+3)*inch + q;
int size = outw * outh;
int nn = size >> 3;
int remain = size & 7;
if (nn > 0)
{
// 以汇编的方式从你选定的4个kernel位置,分别取8个*8bit到D寄存器;
asm volatile(
"vld1.s8 d18, [%0] \n"
"vld1.s8 d19, [%1] \n"
"vld1.s8 d24, [%2] \n"
"vld1.s8 d25, [%3] \n"
: "=r"(kernel0), // %0
"=r"(kernel1), // %1
"=r"(kernel2), // %2
"=r"(kernel3) // %3
: "0"(kernel0),
"1"(kernel1),
"2"(kernel2),
"3"(kernel3)
:
);
asm volatile(
"0: \n"
//ld r0-r7,分别预加载8个输入channel的H*W面中的前8个元素。
"pld [%5, #64] \n"
"vld1.s8 {d0}, [%5 :64]! \n" //r0
"pld [%6, #64] \n"
"vld1.s8 {d1}, [%6 :64]! \n" //r1
"pld [%7, #64] \n"
"vld1.s8 {d2}, [%7 :64]! \n" //r2
"pld [%8, #64] \n"
"vld1.s8 {d3}, [%8 :64]! \n" //r3
"pld [%9, #64] \n"
"vld1.s8 {d4}, [%9 :64]! \n" //r4
"pld [%10, #64] \n"
"vld1.s8 {d5}, [%10 :64]! \n" //r5
"pld [%11, #64] \n"
"vld1.s8 {d6}, [%11 :64]! \n" //r6
"pld [%12, #64] \n"
"vld1.s8 {d7}, [%12 :64]! \n" //r7
//###########################################
//load inch kernel_0 k0-k7
"vdup.s8 d8, d18[0] \n"
"vdup.s8 d9, d18[1] \n"
"vdup.s8 d10, d18[2] \n"
"vdup.s8 d11, d18[3] \n"
"vdup.s8 d12, d18[4] \n"
"vdup.s8 d13, d18[5] \n"
"vdup.s8 d14, d18[6] \n"
"vdup.s8 d15, d18[7] \n"
//mla
"vmull.s8 q8, d0, d8 \n"
"vmlal.s8 q8, d1, d9 \n"
"vmlal.s8 q8, d2, d10 \n"
"vmlal.s8 q8, d3, d11 \n"
"vmlal.s8 q8, d4, d12 \n"
"vmlal.s8 q8, d5, d13 \n"
"vmlal.s8 q8, d6, d14 \n"
"vmlal.s8 q8, d7, d15 \n"
//outptr0_s32
"pld [%1, #256] \n"
"vld1.32 {d20-d23}, [%1:128] \n" //outptr0_s32
"vaddw.s16 q10, q10, d16 \n"
"vaddw.s16 q11, q11, d17 \n"
"vst1.32 {d20-d23}, [%1:128]!\n"
//###########################################
//load inch kernel_1 k0-k7
"vdup.s8 d8, d19[0] \n"
"vdup.s8 d9, d19[1] \n"
"vdup.s8 d10, d19[2] \n"
"vdup.s8 d11, d19[3] \n"
"vdup.s8 d12, d19[4] \n"
"vdup.s8 d13, d19[5] \n"
"vdup.s8 d14, d19[6] \n"
"vdup.s8 d15, d19[7] \n"
//mla
"vmull.s8 q8, d0, d8 \n"
"vmlal.s8 q8, d1, d9 \n"
"vmlal.s8 q8, d2, d10 \n"
"vmlal.s8 q8, d3, d11 \n"
"vmlal.s8 q8, d4, d12 \n"
"vmlal.s8 q8, d5, d13 \n"
"vmlal.s8 q8, d6, d14 \n"
"vmlal.s8 q8, d7, d15 \n"
//outptr1_s32
"pld [%2, #256] \n"
"vld1.32 {d20-d23}, [%2:128] \n" //outptr1_s32
"vaddw.s16 q10, q10, d16 \n"
"vaddw.s16 q11, q11, d17 \n"
"vst1.32 {d20-d23}, [%2:128]!\n"
//############################################
//load inch kernel_2 k0-k7
"vdup.s8 d8, d24[0] \n"
"vdup.s8 d9, d24[1] \n"
"vdup.s8 d10, d24[2] \n"
"vdup.s8 d11, d24[3] \n"
"vdup.s8 d12, d24[4] \n"
"vdup.s8 d13, d24[5] \n"
"vdup.s8 d14, d24[6] \n"
"vdup.s8 d15, d24[7] \n"
//mla
"vmull.s8 q8, d0, d8 \n"
"vmlal.s8 q8, d1, d9 \n"
"vmlal.s8 q8, d2, d10 \n"
"vmlal.s8 q8, d3, d11 \n"
"vmlal.s8 q8, d4, d12 \n"
"vmlal.s8 q8, d5, d13 \n"
"vmlal.s8 q8, d6, d14 \n"
"vmlal.s8 q8, d7, d15 \n"
//outptr2_s32
"pld [%3, #256] \n"
"vld1.32 {d20-d23}, [%3:128] \n" //outptr2_s32
"vaddw.s16 q10, q10, d16 \n"
"vaddw.s16 q11, q11, d17 \n"
"vst1.32 {d20-d23}, [%3:128]!\n"
//#############################################
//load inch kernel_3 k0-k7
"vdup.s8 d8, d25[0] \n"
"vdup.s8 d9, d25[1] \n"
"vdup.s8 d10, d25[2] \n"
"vdup.s8 d11, d25[3] \n"
"vdup.s8 d12, d25[4] \n"
"vdup.s8 d13, d25[5] \n"
"vdup.s8 d14, d25[6] \n"
"vdup.s8 d15, d25[7] \n"
//mla
"vmull.s8 q8, d0, d8 \n"
"vmlal.s8 q8, d1, d9 \n"
"vmlal.s8 q8, d2, d10 \n"
"vmlal.s8 q8, d3, d11 \n"
"vmlal.s8 q8, d4, d12 \n"
"vmlal.s8 q8, d5, d13 \n"
"vmlal.s8 q8, d6, d14 \n"
"vmlal.s8 q8, d7, d15 \n"
//outptr3_s32
"pld [%4, #256] \n"
"vld1.32 {d20-d23}, [%4:128] \n" //outptr3_s32
"vaddw.s16 q10, q10, d16 \n"
"vaddw.s16 q11, q11, d17 \n"
"vst1.32 {d20-d23}, [%4:128]!\n"
//next
"subs %0, #1 \n"
"bne 0b \n"
: "=r"(nn), // %0
"=r"(outptr0), // %1
"=r"(outptr1), // %2
"=r"(outptr2), // %3
"=r"(outptr3), // %4
"=r"(r0), // %5
"=r"(r1), // %6
"=r"(r2), // %7
"=r"(r3), // %8
"=r"(r4), // %9
"=r"(r5), // %10
"=r"(r6), // %11
"=r"(r7) // %12
: "0"(nn),
"1"(outptr0),
"2"(outptr1),
"3"(outptr2),
"4"(outptr3),
"5"(r0),
"6"(r1),
"7"(r2),
"8"(r3),
"9"(r4),
"10"(r5),
"11"(r6),
"12"(r7)
: "cc", "memory", "q0", "q1", "q2", "q3", "q4", "q5", "q6", "q7", "q8", "q10", "q11", "q13", "q14", "q15"
);
}
分析:
上述代码总结如下图所示,先看整体架构,以CHW方式内存排布的输入输出blob以及kernnel如图所示,每次计算输出的4个channel(也就是计算4个kernnel),每个通道中计算H*W面上的8个元素,在输出的H*W中沿图示方向轮循计算完当前4(Cout)*H*W内的计算量(只计算完了8/Cin),然后再接着跳到Cin方向上的下一个r0~r7,再次轮回,周而复始,直至4(Cout)*H*W的所有计算量算完;
算完上一个部分后,进入下一个更大的轮回,也就是输出的下一个4(Cout)*H*W,直至宇宙毁灭。
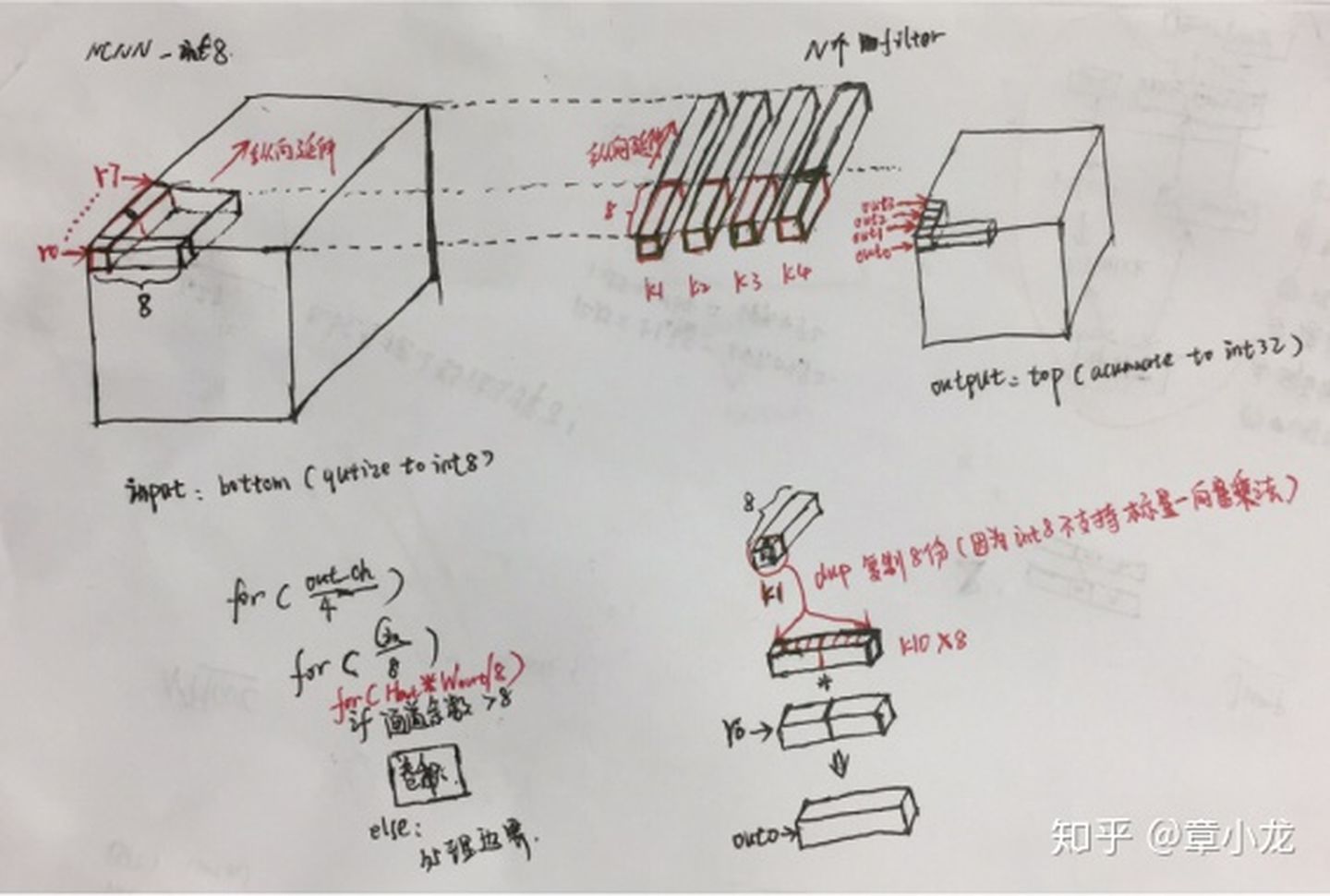
图1-5 NCNN INT8方案
根据3x3s1优化的经验可知,上面重复需要把输出给读进读出,这样会造成更多的消耗,但是假如我按下图所示的以HWC的方式沿Cin方向纵向延伸呢?只有最后计算完才写回内存,这样就节省很多时间了!
图1-5 我认为会更好的方案
代码的循环架构如下:
For(Cout/4)
{
For(Cin/8)
{
For(Hout*Wout/8)
{
核心卷积;
}
边界卷积计算;
}
}
最核心的部分就是计算卷积了,这里剖析如下,这里每次是计算4个kernenl的前8个元素,而这4个kernnel的计算方式是一致的,因此我们随便选择一个讨论就行,假设计算k1的卷积是func(K1),那么上述的计算卷积就是:
核心卷积 = {
func(K1),
func(K2),
func(K3),
func(K4)
}
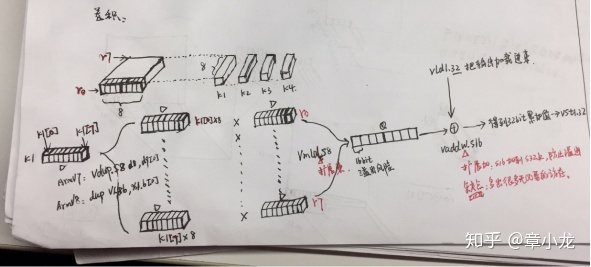
图1-5 核心卷积原理
小结:
- 加载kernel去掉了4(N)*8(Cin)*8bit=4D=2Q=256bit;
- 加载input去掉了8(Cin)*8(W)*8bit=8D=4Q=512bit;
- 由于每次计算输出H*W内的8个点,同时int8是无法向量-标量乘法的,因此需要把k1[0]扩展到一个D寄存器中,扩展为8个单元,再据此跟输入对应位置W方向上的八个元素相乘,从而得到8个输出,详细见下图,共消耗8D=4Q个矢量寄存器;
//load inch kernel_3 k0-k7
"vdup.s8 d8, d25[0] \n"
"vdup.s8 d9, d25[1] \n"
"vdup.s8 d10, d25[2] \n"
"vdup.s8 d11, d25[3] \n"
"vdup.s8 d12, d25[4] \n"
"vdup.s8 d13, d25[5] \n"
"vdup.s8 d14, d25[6] \n"
"vdup.s8 d15, d25[7] \n"
4. 累加的32bit输出共计需要2个Q寄存器,代码如下所示,先加载进来32bit值,然后把16bit的中间值累加上去,然后再写回内存;接着再开始HWC方式下的下一次Cin/8计算;
//outptr1_s32
"pld [%2, #256] \n"
"vld1.32 {d20-d23}, [%2:128] \n" //outptr1_s32
"vaddw.s16 q10, q10, d16 \n"
"vaddw.s16 q11, q11, d17 \n"
"vst1.32 {d20-d23}, [%2:128]!\n"
因此总共花费了12个Q寄存器,寄存器还没用完呐!优化不到位啊!
3.1.4 量化后处理
NCNN的dequantize.cpp函数里面有其去量化的实现,把卷积最后输出的int32乘以scale值放大回原来的值变为float,然后加上浮点格式的bias,最后输出作为下一层的输入feature map。
for (int i=0; i<h; i++)
{
const int* intptr = bottom_top_blob.row<const int>(i);
float* ptr = bottom_top_blob.row(i);
float bias = bias_data_size > 1 ? bias_data[i] : bias_data[0];
for (int j=0; j<w; j++)
{
ptr[j] = intptr[j] * scale + bias;
}
}
原理也很直接,输入一个INT32的Mat矩阵,然后由于float32也是32bit的,因此我以int指针intptr的方式从Mat的当前位置处加载32bit数进来到普通int寄存器然后乘以scale值就到了FP寄存器了,接着再加上bias,最后把这个浮点寄存器里面的值写回到你刚读数据的位置,这样就完美地节省内存了。(注:可能存在的问题是把数据从int通用寄存器搬运到浮点寄存器一般是V矢量指令,这种指令会消耗额外的cycles,因此性能不会很好就对了。)
3.2 优化INT8实现逻辑
这一章在后续再详细写写吧。
3.2.1优化-直接减少访存
我们把指令的排布不做改变,访存方式不做改变(保留CHW方式)仅修改访存size也即输入int8计算累加到int16进行输出,此时L1 cache的访问情况如下:
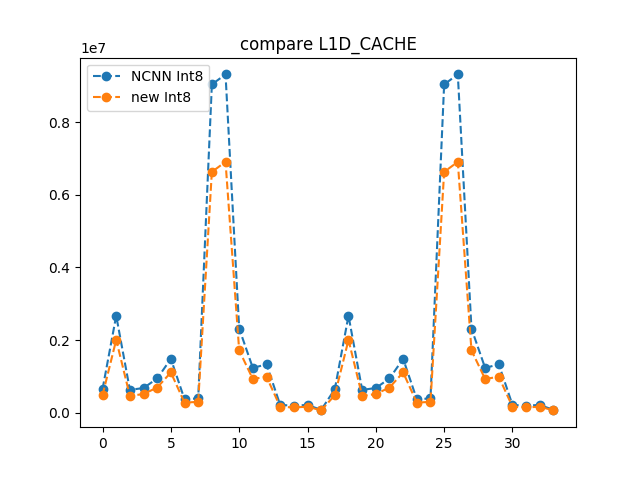
3.2.1优化-展开更充分
3.2.2优化-指令重排调整流水线
PowerPerf界面部分