传统方式:
insert into tableA select xx from tableB
或者使用
<foreach collection="pd.mapListImpt" item="item" index="index" open="begin" close=";end;" separator=";" >
update tableA
<set>
a= #{pd.mapListImpt[${index}].a,jdbcType=VARCHAR},
b= #{pd.mapListImpt[${index}].b,jdbcType=VARCHAR},
c=#{pd.mapListImpt[${index}].c,jdbcType=VARCHAR},
d= #{pd.mapListImpt[${index}].d,jdbcType=VARCHAR},
e= #{pd.mapListImpt[${index}].e,jdbcType=VARCHAR},
f= #{pd.mapListImpt[${index}].f,jdbcType=VARCHAR},
g= #{pd.mapListImpt[${index}].g,jdbcType=VARCHAR},
h=#{pd.h,jdbcType=VARCHAR},
UpdateOperater=#{pd.userCode,jdbcType=VARCHAR},
UpdateDate=to_date(to_char(sysdate,'yyyy-MM-dd'),'yyyy-MM-dd'),
UpdateTime=to_char(sysdate, 'HH24:mi:ss')
</set>
where ad=#{pd.mapListImpt[${index}].ad,jdbcType=VARCHAR}
</foreach>
优化方式
使用merge into
以下写的例子,以供以后参考
<insert id="insertCEBPN_Con_ContriLs" statementType="PREPARED" parameterType="pd">
merge into PN_Con_ContriLs pnc
using(
select
pcc.contrilsid contrilsid,
pcc.contributionid contributionid,
pcc.PlanID PlanID,
pcc.EnterprisedeID EnterprisedeID,
pcc.SubEnterprisedeID SubEnterprisedeID,
pcc.productid productid,
pcc.StaffID StaffID,
pcc.name name,
pcc.IdNo IdNo,
nvl(pcc.EContTaxApply,'0') + pcc(pnc.ECMoney,'0') ECTotal,
nvl(pcc.SContTaxApply,'0') + pcc(pnc.SCMoney,'0') SCTotal,
pcc.CSumMoney CSumMoney,
pcc.EContTaxApply EContTaxApply,
pcc.SContTaxApply SContTaxApply,
pcc.ECMoney ECMoney,
pcc.SCMoney SCMoney,
pcc.expandfield2 expandfield2
from pn_con_contrils_temp pcc
where pcc.contributionid = #{pd.ContributionID,jdbcType=VARCHAR}
and pcc.expandfield4 = #{pd.ContriLsIDLSPay,jdbcType=VARCHAR}
)t on(pnc.contributionid=t.contributionid)
when not matched then
insert (pnc.ContriLsID,pnc.ContributionID,pnc.planid,pnc.EnterprisedeID,pnc.SubEnterprisedeID,pnc.ProductID,pnc.StaffID,pnc.name, pnc.IdNo,
pnc.EContTotalLs,pnc.SContTotalLs, pnc.ContTotalLs,pnc.EContTaxTotalLs,pnc.SContTaxTotalLs,pnc.EContApply,pnc.SContApply,
pnc.OperateOrg, pnc.Operater,pnc.MakeDate, pnc.MakeTime,pnc.UpdateOperater,pnc.UpdateDate,pnc.UpdateTime,pnc.ContriListFileID,pnc.ContriAccountType)
values(
t.contrilsid,
t.contributionid,
t.PlanID,
t.EnterprisedeID,
t.SubEnterprisedeID,
t.productid,
t.StaffID,
t.name,
t.IdNo,
t.ECTotal,
t.SCTotal,
t.CSumMoney,
t.EContTaxApply,
t.SContTaxApply,
t.ECMoney,
t.SCMoney,
#{pd.comCode, jdbcType = VARCHAR},
#{pd.userCode, jdbcType = VARCHAR},
to_date(to_char(sysdate, 'yyyy-MM-dd'), 'yyyy-MM-dd'),
to_char(sysdate, 'HH24:mi:ss'),
#{pd.userCode, jdbcType = VARCHAR},
to_date(to_char(sysdate, 'yyyy-MM-dd'), 'yyyy-MM-dd'),
to_char(sysdate, 'HH24:mi:ss'),
#{pd.FileID, jdbcType = VARCHAR},
t.expandfield2
)
</insert>
<insert id="updateCEBPN_Con_ContriLs" statementType="PREPARED" parameterType="pd">
merge into PN_Con_ContriLs pnc
using(
select
pcc.contrilsid ContriLsID,
pcc.contributionid ContributionID,
pcc.name Name,
pcc.idno IDNo,
pcc.EContTaxApply,
pcc.ECMoney,
(nvl(pcc.EContTaxApply,'0')+nvl(pcc.ECMoney,'0')) EContTotalLs,
pcc.SContTaxApply,
pcc.SCMoney,
(nvl(pcc.SContTaxApply,'0')+nvl(pcc.SCMoney,'0')) SContTotalLs,
pcc.CSumMoney
from pn_con_contrils_temp pcc
where pcc.contributionid = #{pd.ContributionID,jdbcType=VARCHAR}
and pcc.expandfield4 = #{pd.ContriLsIDLSPay,jdbcType=VARCHAR}
)t on(t.contributionid = pnc.contributionid and pnc.Name = t.Name and pnc.IDNo = t.IDNo)
WHEN MATCHED THEN
UPDATE SET
pnc.EContTotalLs = t.EContTotalLs,
pnc.SContTotalLs = t.SContTotalLs,
pnc.EContTaxTotalLs = t.EContTaxApply,
pnc.SContTaxTotalLs = t.SContTaxApply,
pnc.ContTotalLs = t.CSumMoney,
pnc.EContApply= t.ECMoney,
pnc.SContApply= t.SCMoney,
pnc.ContriListFileID=#{pd.FileID,jdbcType=VARCHAR},
pnc.UpdateOperater=#{pd.userCode,jdbcType=VARCHAR},
pnc.UpdateDate=to_date(to_char(sysdate,'yyyy-MM-dd'),'yyyy-MM-dd'),
pnc.UpdateTime=to_char(sysdate, 'HH24:mi:ss')
</insert>
下面是参考的其他博主的记录,以供日后学习
转载自:https://blog.csdn.net/jeryjeryjery/article/details/70047022
merge into的形式:
MERGE INTO [target-table] A USING [source-table sql] B ON([conditional expression] and [...]...)
WHEN MATCHED THEN
[UPDATE sql]
WHEN NOT MATCHED THEN
[INSERT sql]
作用:判断B表和A表是否满足ON中条件,如果满足则用B表去更新A表,如果不满足,则将B表数据插入A表但是有很多可选项,如下:
1.正常模式
2.只update或者只insert
3.带条件的update或带条件的insert
4.全插入insert实现
5.带delete的update(觉得可以用3来实现)
下面一一测试。
测试建以下表:
-
create
table A_MERGE
-
(
-
id
NUMBER
not
null,
-
name VARCHAR2(
12)
not
null,
-
year
NUMBER
-
);
-
create
table B_MERGE
-
(
-
id
NUMBER
not
null,
-
aid
NUMBER
not
null,
-
name VARCHAR2(
12)
not
null,
-
year
NUMBER,
-
city VARCHAR2(
12)
-
);
-
create
table C_MERGE
-
(
-
id
NUMBER
not
null,
-
name VARCHAR2(
12)
not
null,
-
city VARCHAR2(
12)
not
null
-
);
-
commit;
A_MERGE表结构:
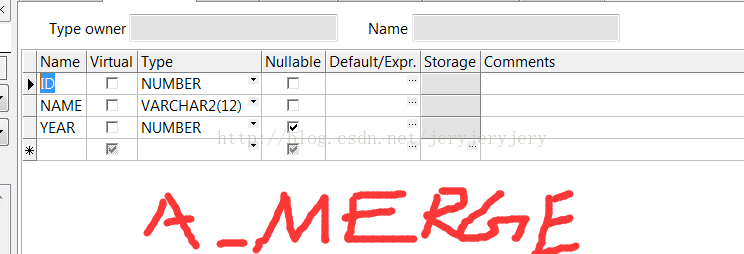
B_MERGE表结构
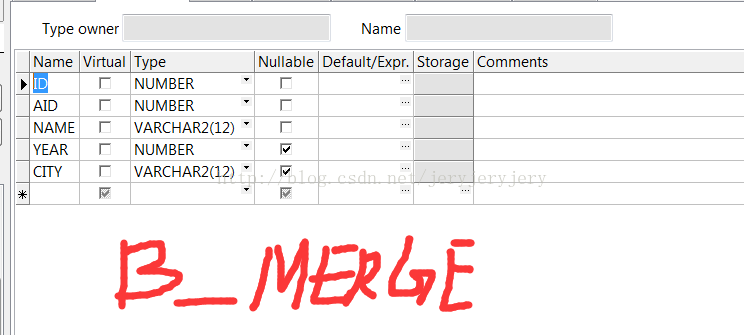
C_MERGE表结构
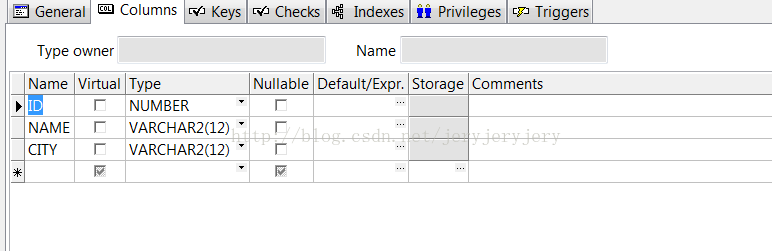
1.正常模式
先向A_MERGE和B_MERGE插入测试数据:
-
insert
into A_MERGE
values(
1,
'liuwei',
20);
-
insert
into A_MERGE
values(
2,
'zhangbin',
21);
-
insert
into A_MERGE
values(
3,
'fuguo',
20);
-
commit;
-
-
insert
into B_MERGE
values(
1,
2,
'zhangbin',
30,
'吉林');
-
insert
into B_MERGE
values(
2,
4,
'yihe',
33,
'黑龙江');
-
insert
into B_MERGE
values(
3,
3,
'fuguo',,
'山东');
-
commit;
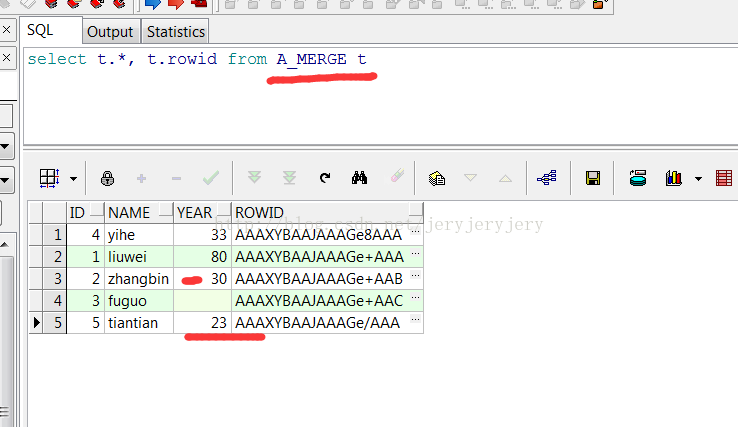
此时A_MERGE和B_MERGE表中数据截图如下:
A_MERGE表数据:
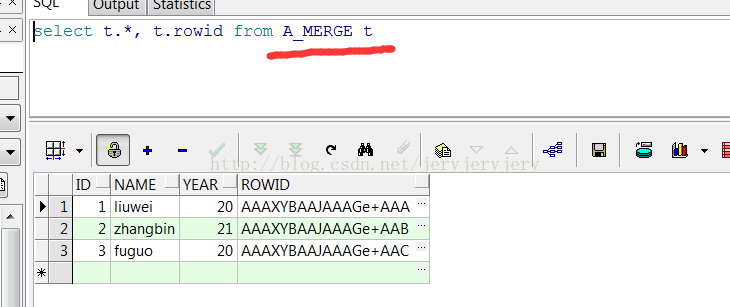
B_MERGE表数据:
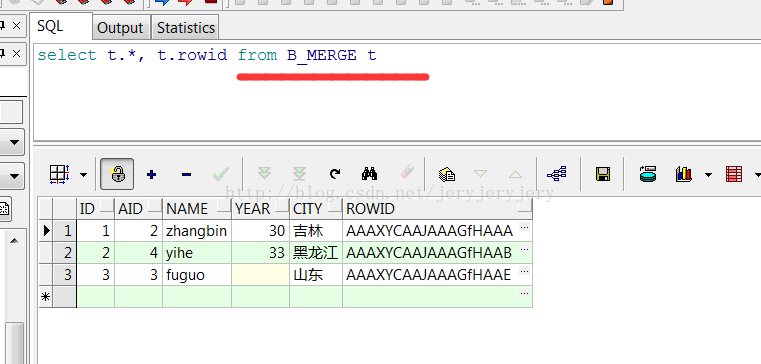
-
MERGE
INTO A_MERGE A
USING (
select B.AID,B.NAME,B.YEAR
from B_MERGE B) C
ON (A.id=C.AID)
-
WHEN
MATCHED
THEN
-
UPDATE
SET A.YEAR=C.YEAR
-
WHEN
NOT
MATCHED
THEN
-
INSERT(A.ID,A.NAME,A.YEAR)
VALUES(C.AID,C.NAME,C.YEAR);
-
commit;
2.只update模式
首先向B_MERGE中插入两个数据,来为了体现出只update没有insert,必须有一个数据是A中已经存在的
另一个数据时A中不存在的,插入数据语句如下:
-
insert
into B_MERGE
values(
4,
1,
'liuwei',
80,
'江西');
-
insert
into B_MERGE
values(
5,
5,
'tiantian',
23,
'河南');
-
commit;
A_MERGE表数据截图:
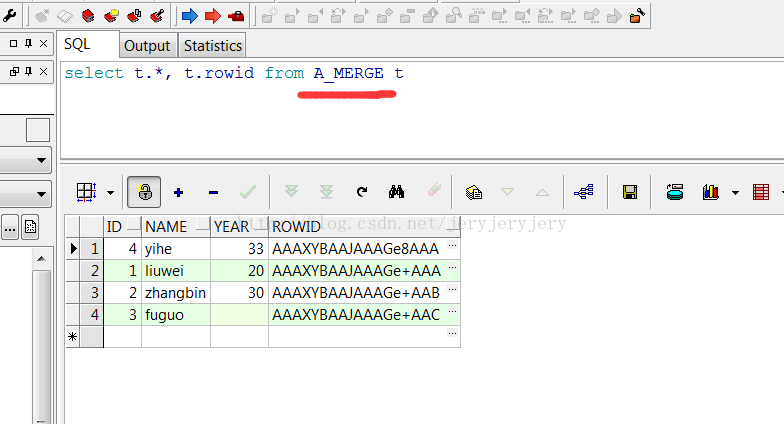
B_MERGE表数据截图:
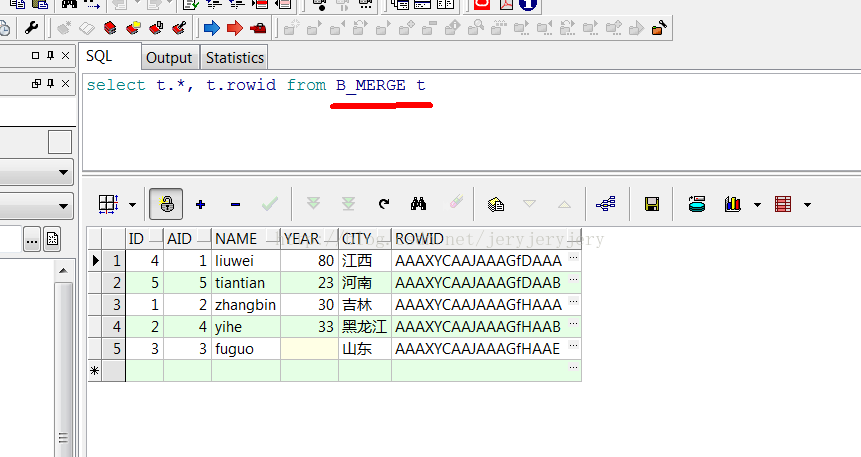
然后再次用B_MERGE来更新A_MERGE,但是仅仅update,没有写insert部分。
-
merge
into A_MERGE A
USING (
select B.AID,B.NAME,B.YEAR
from B_MERGE B) C
ON(A.ID=C.AID)
-
WHEN
MATCHED
THEN
-
UPDATE
SET A.YEAR=C.YEAR;
-
-
commit;
3.只insert模式
首先改变B_MERGE中的一个数据,因为上次测试update时新增的数据没有插入到A_MERGE,这次可以用。
-
update B_MERGE
set
year=
70
where AID=
2;
-
commit;
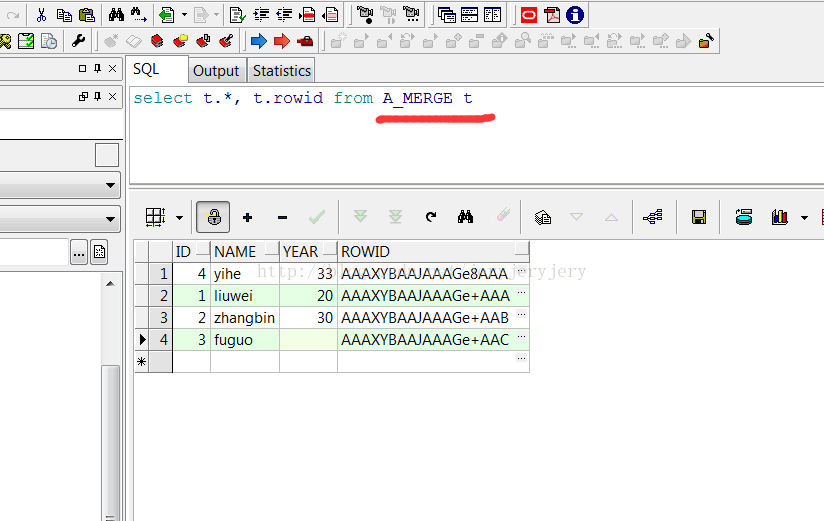
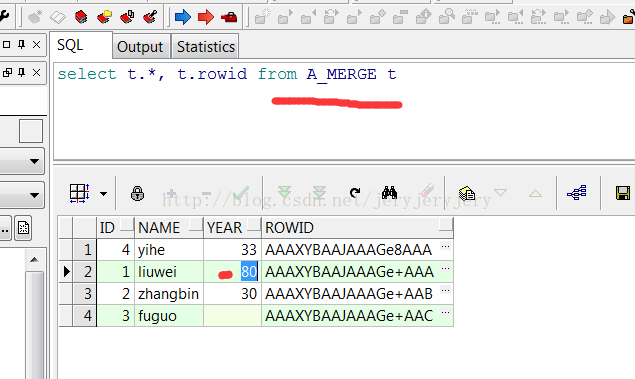
A_MERGE表数据:
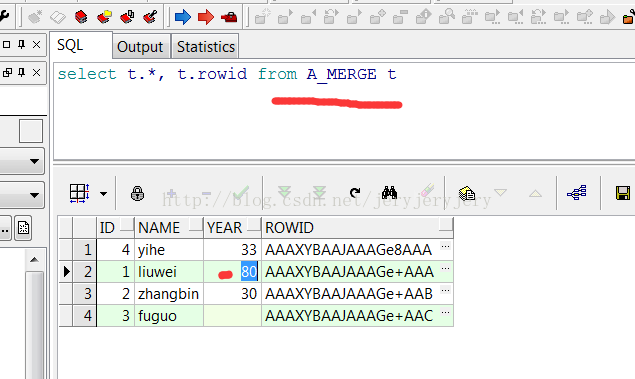
B_MERGE表数据:
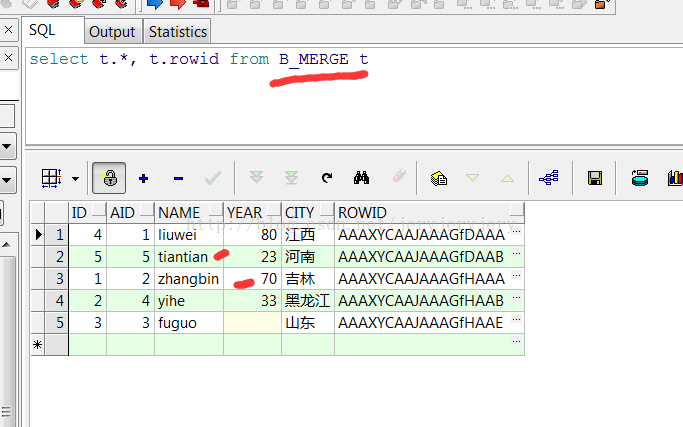
然后用B_MERGE来更新A_MERGE中的数据,此时只写了insert,没有写update:
-
merge
into A_MERGE A
USING (
select B.AID,B.NAME,B.YEAR
from B_MERGE B) C
ON(A.ID=C.AID)
-
WHEN
NOT
MATCHED
THEN
-
insert(A.ID,A.NAME,A.YEAR)
VALUES(C.AID,C.NAME,C.YEAR);
-
commit;
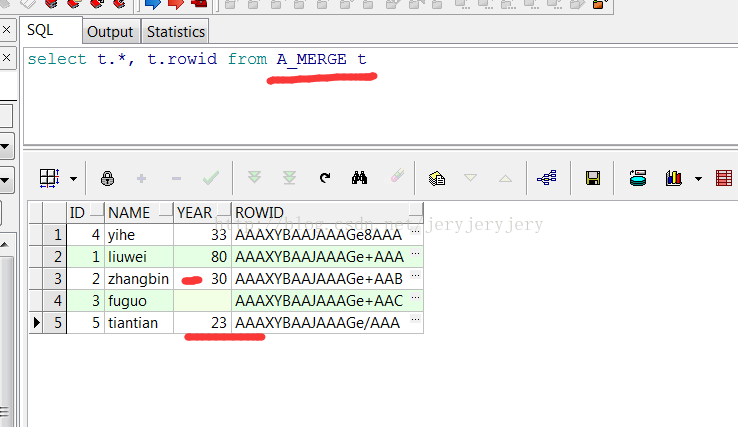
4.带where条件的insert和update。
我们在on中进行完条件匹配之后,还可以在后面的insert和update中对on筛选出来的记录再做一次条件判断,用来控制哪些要更新,哪些要插入。
测试数据的sql代码如下,我们在B_MERGE修改了两个人名,并且增加了两个人员信息,但是他们来自的省份不同,
所以我们可以通过添加省份条件来控制哪些能修改,哪些能插入:
-
update B_MERGE
set
name=
'yihe++'
where
id=
2;
-
update B_MERGE
set
name=
'liuwei++'
where
id=
4;
-
insert
into B_MERGE
values(
6,
6,
'ningqin',
23,
'江西');
-
insert
into B_MERGE
values(
7,
7,
'bing',
24,
'吉安');
-
commit;
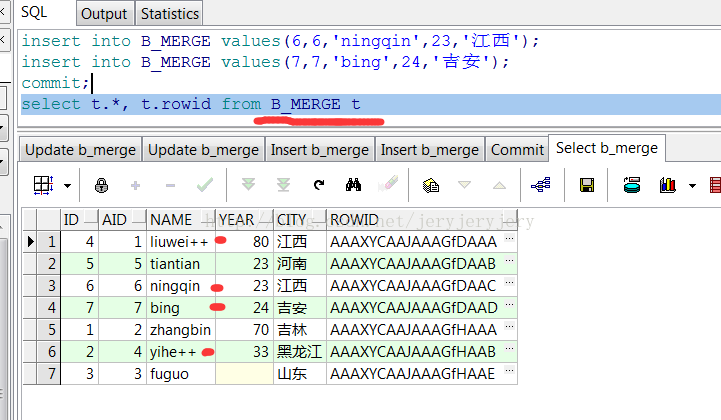
B_MERGE表数据:
然后再用B_MERGE去更新A_MERGE,但是分别在insert和update后面添加了条件限制,控制数据的更新和插入:
-
merge
into A_MERGE A
USING (
select B.AID,B.name,B.year,B.city
from B_MERGE B) C
-
ON(A.id=C.AID)
-
when
matched
then
-
update
SET A.name=C.name
where C.city !=
'江西'
-
when
not
matched
then
-
insert(A.ID,A.name,A.year)
values(c.AID,C.name,C.year)
where C.city=
'江西';
-
commit;
此时A_MERGE截图如下:
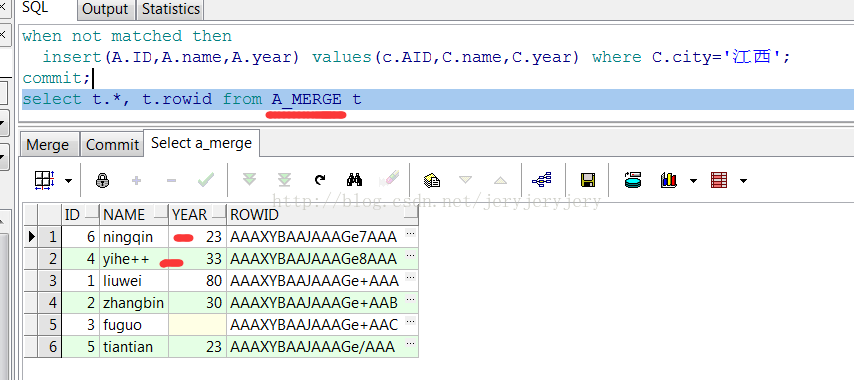
5.无条件的insert。
有时我们需要将一张表中所有的数据插入到另外一张表,此时就可以添加常量过滤谓词来实现,让其只满足
匹配和不匹配,这样就只有update或者只有insert。这里我们要无条件全插入,则只需将on中条件设置为永假
即可。用B_MERGE来更新C_MERGE代码如下:
-
merge
into C_MERGE C
USING (
select B.AID,B.NAME,B.City
from B_MERGE B) C
ON (
1=
0)
-
when
not
matched
then
-
insert(C.ID,C.NAME,C.City)
values(B.AID,B.NAME,B.City);
-
commit;
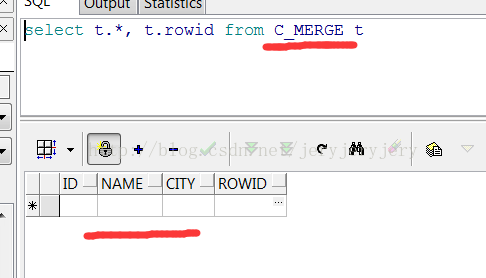
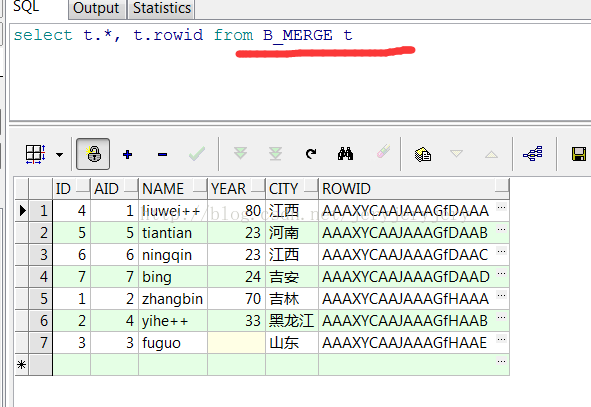
B_MERGE数据截图如下:
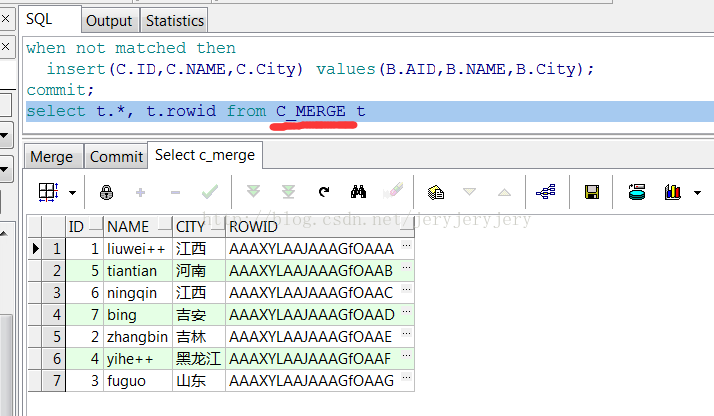
C_MERGE表在merge之后数据截图如下:
6.带delete的update
MERGE提供了在执行数据操作时清除行的选项. 你能够在WHEN MATCHED THEN UPDATE子句中包含DELETE子句.
DELETE子句必须有一个WHERE条件来删除匹配某些条件的行.匹配DELETE WHERE条件但不匹配ON条件的行不会被从表中删除.
但我觉得这个带where条件的update差不多,都是控制update,完全可以用带where条件的update来实现。
author:su1573