目录
(1)窗口概述
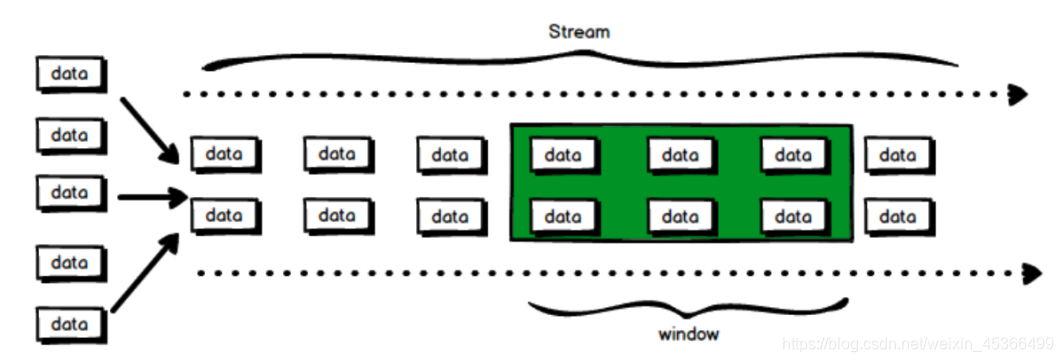
在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。 当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在 过去的 1 分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用 来收集最近一分钟内的数据,并对这个窗口内的数据进行计算。
流式计算是一种被设计用于 处理无限数据集 的数据处理引擎,而无限数据集是指一种 不断增长的本质上无限的数据集,而 Window 窗口是一种切割无限数据为有限块进行处理的 手段。
在 Flink 中, 窗口(window)是处理无界流的核心. 窗口把流切割成有限大小的多个"存 储桶"(bucket), 我们在这些桶上进行计算.
(2)窗口的分类
窗口分为 2 类:
1. 基于时间的窗口(时间驱动)
2. 基于元素个数的(数据驱动)
(2.1)基于时间的窗口
时间窗口包含一个开始时间戳(包括)和结束时间戳(不包括), 这两个时间戳一起限制 了窗口的尺寸.
在代码中, Flink 使用 TimeWindow 这个类来表示基于时间的窗口. 这个类提供了 key 查询开始时间戳和结束时间戳的方法, 还提供了针对给定的窗口获取它允许的最大时间差 的方法(maxTimestamp())
时间窗口又分 4 种:
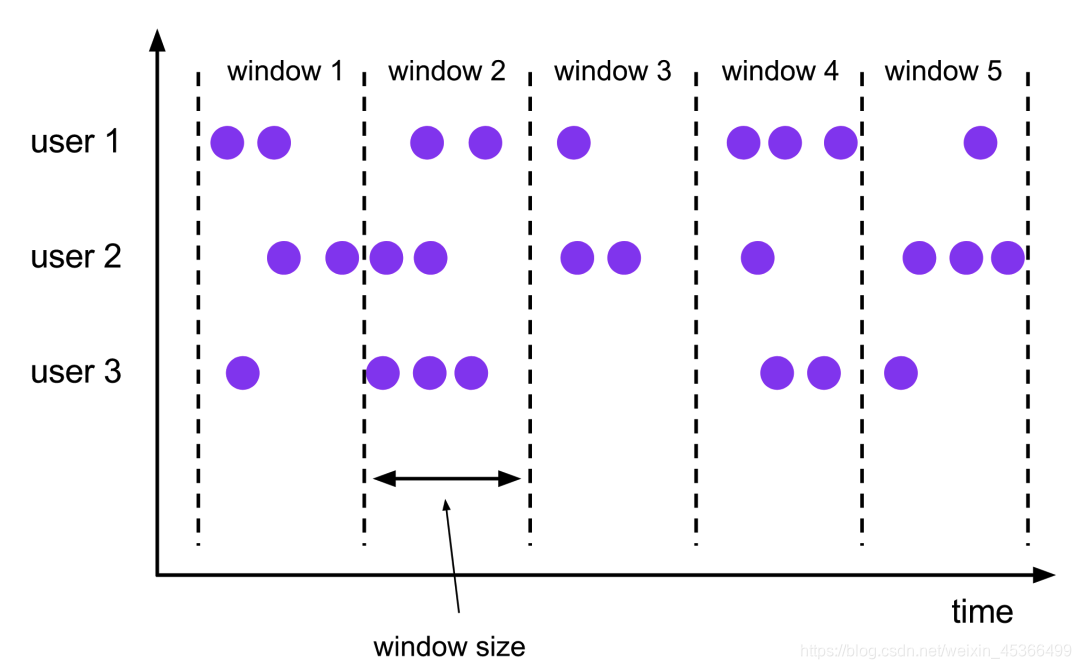
(2.1.1)滚动窗口(Tumbling Windows)
滚动窗口有固定的大小, 窗口与窗口之间不会重叠也没有缝隙.比如,如果指定一个长度为 5 分钟的滚动窗口, 当前窗口开始计算, 每 5 分钟启动一个新的窗口.
滚动窗口能将数据流切分成不重叠的窗口, 每一个事件只能属于一个窗口 。
示例代码:
package com.aikfk.flink.datastream.window;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
/**
* @author :caizhengjie
* @description:TODO
* @date :2021/3/19 10:10 上午
*/
public class TimeTumbling {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.读取端口数据
DataStreamSource<String> socketTextStream = env.socketTextStream("bigdata-pro-m07",9999);
//3.压平并转换为元组
SingleOutputStreamOperator<Tuple2<String, Integer>> wordToOneDS = socketTextStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}
});
//4.按照单词分组
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordToOneDS.keyBy(data -> data.f0);
//5.添加滚动窗口
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));
/**
* 6.增量聚合窗口计算方式一:reduce
*/
DataStream<Tuple2<String,Integer>> result = windowedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
return new Tuple2<>(t1.f0,t1.f1 + t2.f1);
}
});
//7.打印
result.print();
//8.执行任务
env.execute();
}
}
说明:
-
时间间隔可以通过:
Time.milliseconds(x), Time.seconds(x), Time.minutes(x) -
我们传递给 window 函数的对象叫 窗口分配器 .
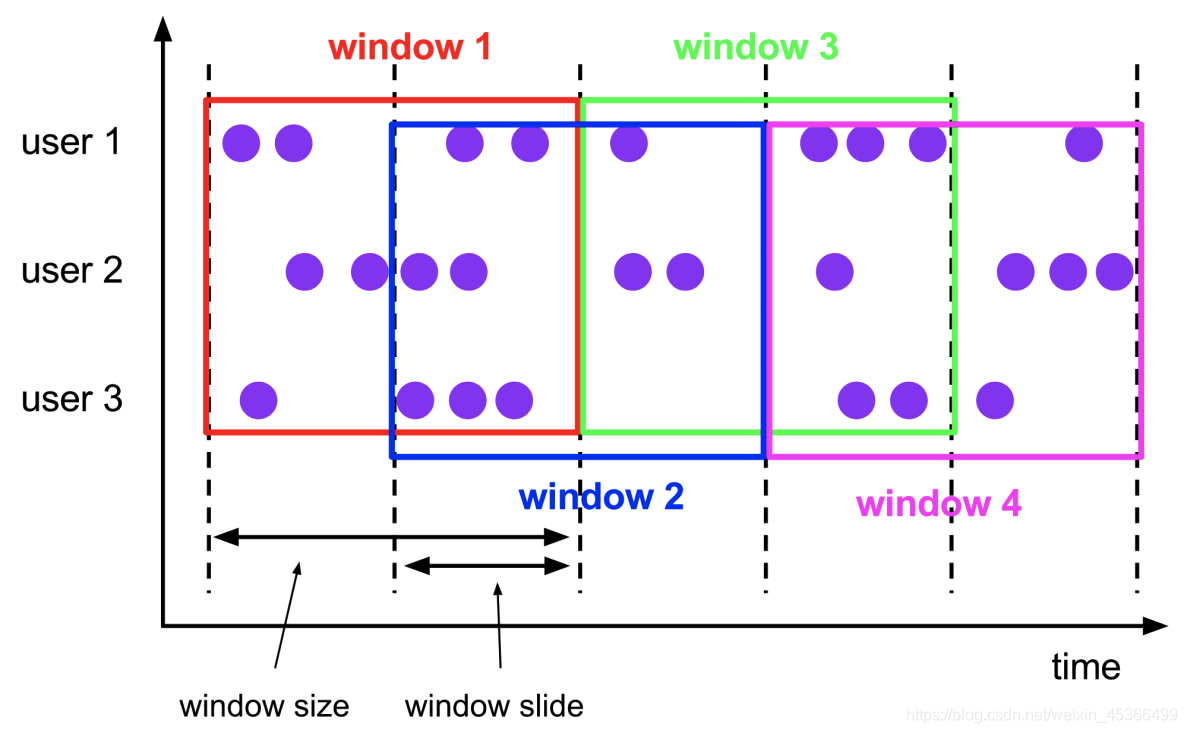
(2.1.2)滑动窗口(Sliding Windows)
与滚动窗口一样, 滑动窗口也是有固定的长度. 另外一个参数我们叫滑动步长, 用来 控制滑动窗口启动的频率.
所以, 如果滑动步长小于窗口长度, 滑动窗口会重叠. 这种情况下, 一个元素可能会 被分配到多个窗口中
例如, 滑动窗口长度 10 分钟, 滑动步长 5 分钟, 则, 每 5 分钟会得到一个包含最近 10 分钟的数据.
示例代码:
//5.开滑动窗,6s窗口,2s聚合一次
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = keyedStream
.window(SlidingProcessingTimeWindows.of(Time.seconds(6),Time.seconds(2)));
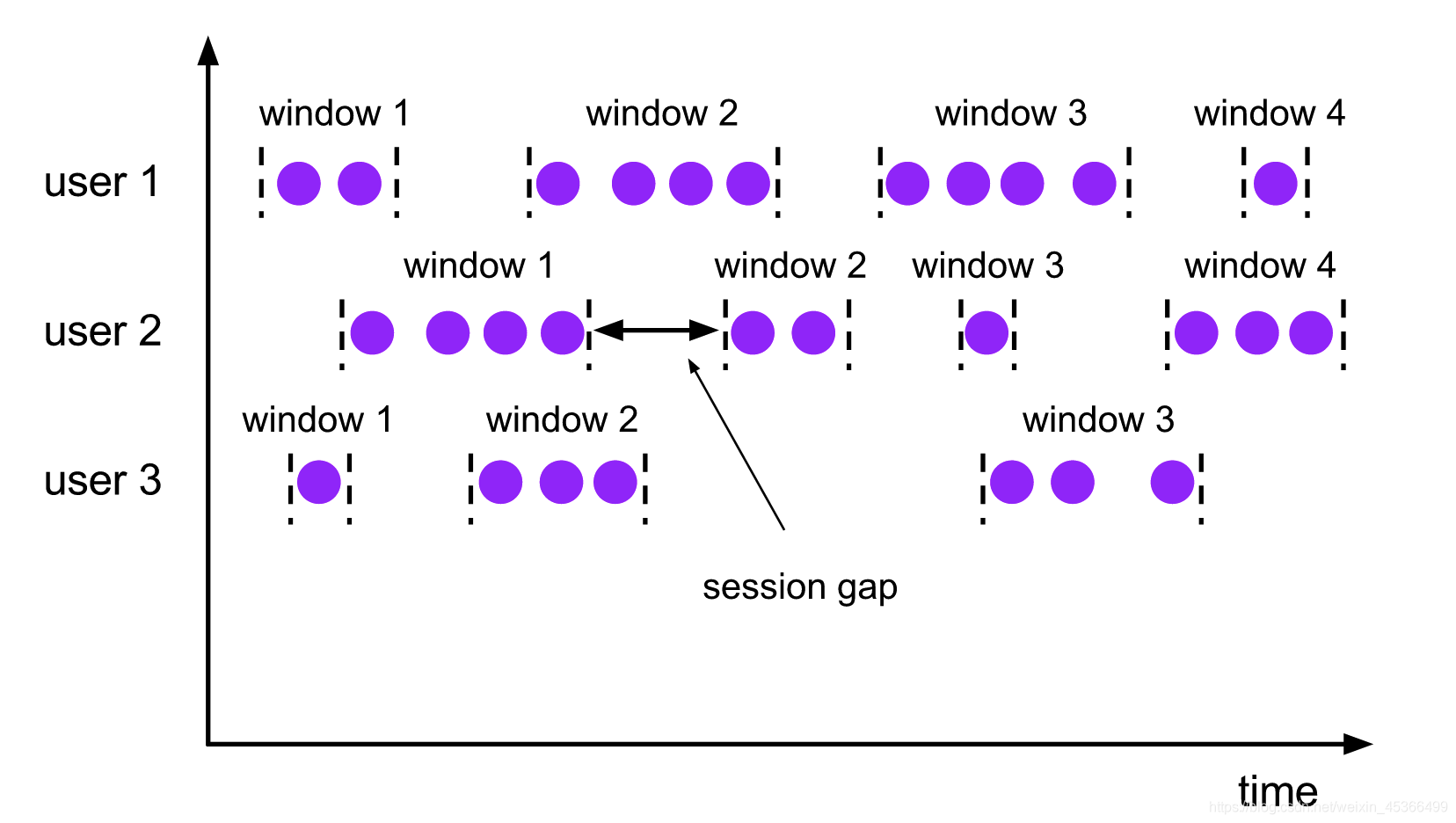
(2.1.3)会话窗口(Session Windows)
会话窗口分配器会根据活动的元素进行分组. 会话窗口不会有重叠, 与滚动窗口和滑 动窗口相比, 会话窗口也没有固定的开启和关闭时间.
如果会话窗口有一段时间没有收到数据, 会话窗口会自动关闭, 这段没有收到数据的 时间就是会话窗口的 gap(间隔)
我们可以配置静态的 gap, 也可以通过一个 gap extractor 函数来定义 gap 的长度. 当时间超过了这个 gap, 当前的会话窗口就会关闭, 后序的元素会被分配到一个新的会话 窗口
示例代码:
- 静态 gap
//5.开启会话窗口,会话间隔时间为5s
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = keyedStream
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5 )));
- 动态 gap
.window(ProcessingTimeSessionWindows.withDynamicGap(new
SessionWindowTimeGapExtractor<Tuple2<String, Long>>() {
@Override
public long extract(Tuple2<String, Long> element) {
// 返回 gap值, 单位毫秒
return element.f0.length() * 1000;
}
}))
创建原理:
因为会话窗口没有固定的开启和关闭时间, 所以会话窗口的创建和关闭与滚动,滑动窗 口不同. 在 Flink 内部, 每到达一个新的元素都会创建一个新的会话窗口, 如果这些窗口 彼此相距比较定义的 gap 小, 则会对他们进行合并. 为了能够合并, 会话窗口算子需要合并触发器和合并窗口函数:ReduceFunction, AggregateFunction, or ProcessWindowFunction
(2.1.4)全局窗口(Global Windows)
全局窗口分配器会分配相同 key 的所有元素进入同一个 Global window. 这种窗口机制 只有 指定自定义的触发器 时才有用. 否则, 不会做任务计算, 因为这种窗口没有能够处理聚 集在一起元素的结束点.

示例代码:
.window(GlobalWindows.create());
(2.2)基于元素个数的窗口
按照指定的数据条数生成一个 Window,与时间无关,分 2 类:
(2.2.1)滚动窗口
默认的 CountWindow 是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到 窗口大小时,就会触发窗口的执行。
示例代码:
//5.开启计数的滚动窗口
WindowedStream<Tuple2<String, Integer>, String, GlobalWindow> windowedStream = keyedStream.countWindow(5L);
说明:那个窗口先达到 3 个元素, 哪个窗口就关闭. 不影响其他的窗口.
(2.2.2)滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数, 一个是 window_size,一个是 sliding_size。下面代码中的 sliding_size 设置为了 2,也就 是说,每收到两个相同 key 的数据就计算一次,每一次计算的 window 范围 最多 是 3 个 元素。
示例代码:
//5.开启计数的滚动窗口
WindowedStream<Tuple2<String, Integer>, String, GlobalWindow> windowedStream = keyedStream.countWindow(5L, 2L);
(3)Window Function
前面指定了窗口的分配器, 接着我们需要来指定如何计算, 这事由 window function 来 负责. 一旦窗口关闭, window function 去计算处理窗口中的每个元素.
window function 可以是 ReduceFunction,AggregateFunction, ProcessWindowFunction 中的任意一种.
ReduceFunction,AggregateFunction 更加高效, 原因就是 Flink 可以对到来的元素进 行 增量聚合 . ProcessWindowFunction 可以得到一个包含这个窗口中所有元素的迭代器, 以及这些元素所属窗口的一些元数据信息.
ProcessWindowFunction 不能被高效执行的原因是 Flink 在执行这个函数之前, 需要在 内部缓存这个窗口上所有的元素
ReduceFunction(增量聚合函数)
/**
* 6.增量聚合窗口计算方式一:reduce
*/
DataStream<Tuple2<String,Integer>> result1 = windowedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
return new Tuple2<>(t1.f0,t1.f1 + t2.f1);
}
});
AggregateFunction(增量聚合函数)
/**
* 6.增量聚合窗口计算方式三:aggregate
* 既能进行增量聚合,又能拿到窗口信息
*/
DataStream<Tuple2<String, Integer>> result3 = windowedStream.aggregate(new AggregateFunction<Tuple2<String, Integer>, Integer, Integer>() {
// 创建累加器: 初始化中间值
@Override
public Integer createAccumulator() {
return 0;
}
// 累加器操作
@Override
public Integer add(Tuple2<String, Integer> stringIntegerTuple2, Integer integer) {
return integer + 1;
}
// 获取结果
@Override
public Integer getResult(Integer integer) {
return integer;
}
// 累加器的合并: 只有会话窗口才会调用
@Override
public Integer merge(Integer a, Integer b) {
return a + b;
}
}, new WindowFunction<Integer, Tuple2<String, Integer>, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow timeWindow, Iterable<Integer> iterable, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 取出迭代器中的数据
Integer next = iterable.iterator().next();
// 输出数据并计算出窗口时间(既能进行增量聚合,又能拿到窗口信息)
collector.collect(new Tuple2<>(new Timestamp(timeWindow.getStart()) + ":" + key,next));
}
});
ProcessWindowFunction(全窗口函数)
/**
* 6.全量聚合窗口计算方式二:process
* 进行全量聚合,拿到窗口信息
*/
DataStream<Tuple2<String,Integer>> result5 = windowedStream.process(
new ProcessWindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String, TimeWindow>() {
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Integer>> iterable,
Collector<Tuple2<String, Integer>> collector) throws Exception {
// 取出迭代器的长度
ArrayList<Tuple2<String, Integer>> arrayList = Lists.newArrayList(iterable.iterator());
// 输出数据并计算出窗口时间(进行全量聚合,拿到窗口信息)
collector.collect(new Tuple2<>(new Timestamp(context.window().getStart()) + ":" + key,arrayList.size()));
}
});
总代码:
package com.aikfk.flink.datastream.window;
import org.apache.commons.compress.utils.Lists;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.util.ArrayList;
/**
* @author :caizhengjie
* @description:TODO
* @date :2021/3/19 10:10 上午
*/
public class TimeWindowFunction {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.读取端口数据
DataStreamSource<String> socketTextStream = env.socketTextStream("bigdata-pro-m07",9999);
//3.压平并转换为元组
SingleOutputStreamOperator<Tuple2<String, Integer>> wordToOneDS = socketTextStream.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(new Tuple2<>(word, 1));
}
}
});
//4.按照单词分组
KeyedStream<Tuple2<String, Integer>, String> keyedStream = wordToOneDS.keyBy(data -> data.f0);
//5.开窗
WindowedStream<Tuple2<String, Integer>, String, TimeWindow> windowedStream = keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));
/**
* 6.增量聚合窗口计算方式一:reduce
*/
DataStream<Tuple2<String,Integer>> result1 = windowedStream.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) throws Exception {
return new Tuple2<>(t1.f0,t1.f1 + t2.f1);
}
});
/**
* 6.增量聚合窗口计算方式二:map
*/
DataStream<Tuple2<String,Integer>> result2 = windowedStream.sum(1);
/**
* 6.增量聚合窗口计算方式三:aggregate
* 既能进行增量聚合,又能拿到窗口信息
*/
DataStream<Tuple2<String, Integer>> result3 = windowedStream.aggregate(new AggregateFunction<Tuple2<String, Integer>, Integer, Integer>() {
// 创建累加器: 初始化中间值
@Override
public Integer createAccumulator() {
return 0;
}
// 累加器操作
@Override
public Integer add(Tuple2<String, Integer> stringIntegerTuple2, Integer integer) {
return integer + 1;
}
// 获取结果
@Override
public Integer getResult(Integer integer) {
return integer;
}
// 累加器的合并: 只有会话窗口才会调用
@Override
public Integer merge(Integer a, Integer b) {
return a + b;
}
}, new WindowFunction<Integer, Tuple2<String, Integer>, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow timeWindow, Iterable<Integer> iterable, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 取出迭代器中的数据
Integer next = iterable.iterator().next();
// 输出数据并计算出窗口时间(既能进行增量聚合,又能拿到窗口信息)
collector.collect(new Tuple2<>(new Timestamp(timeWindow.getStart()) + ":" + key,next));
}
});
/**
* 6.全量聚合窗口计算方式一:apply
* 进行全量聚合,拿到窗口信息
*/
DataStream<Tuple2<String,Integer>> result4 = windowedStream.apply(new WindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow timeWindow, Iterable<Tuple2<String, Integer>> iterable, Collector<Tuple2<String, Integer>> collector) throws Exception {
// 取出迭代器的长度
ArrayList<Tuple2<String, Integer>> arrayList = Lists.newArrayList(iterable.iterator());
// 输出数据并计算出窗口时间(进行全量聚合,拿到窗口信息)
collector.collect(new Tuple2<>(new Timestamp(timeWindow.getStart()) + ":" + key,arrayList.size()));
}
});
/**
* 6.全量聚合窗口计算方式二:process
* 进行全量聚合,拿到窗口信息
*/
DataStream<Tuple2<String,Integer>> result5 = windowedStream.process(
new ProcessWindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String, TimeWindow>() {
@Override
public void process(String key, Context context, Iterable<Tuple2<String, Integer>> iterable,
Collector<Tuple2<String, Integer>> collector) throws Exception {
// 取出迭代器的长度
ArrayList<Tuple2<String, Integer>> arrayList = Lists.newArrayList(iterable.iterator());
// 输出数据并计算出窗口时间(进行全量聚合,拿到窗口信息)
collector.collect(new Tuple2<>(new Timestamp(context.window().getStart()) + ":" + key,arrayList.size()));
}
});
//7.打印
result5.print();
//8.执行任务
env.execute();
}
}
(4)Keyed vs Non-Keyed Windows
其实, 在用 window 前首先需要确认应该是在 keyBy 后的流上用, 还是在没有 keyBy 的流上使用.
在 keyed streams 上使用窗口, 窗口计算被并行的运用在多个 task 上, 可以认为每个 task 都有自己单独窗口. 正如前面的代码所示.
在非 non-keyed stream 上使用窗口, 流的并行度只能是 1, 所有的窗口逻辑只能在一 个单独的 task 上执行.
.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(10)))
需要注意的是: 非 key 分区的流, 即使把并行度设置为大于 1 的数, 窗口也只能在某 个分区上使用
(5)Trigger触发器
数据接入窗口之后,窗口是否触发WindowFunction计算,取决于窗口是否满足触发条件,每种类型的窗口都有对应的窗口触发机制,保障每一次接入窗口的数据都能按照规定的触发逻辑进行统计计算。
EventTimeTrigge
通过对比Watermark和窗口EndTime确定是否触发窗口,如果Watermark的时间大于WindowsEndTime则触发计算,否则窗口继续等待;
ProcessTimeTrigge
通过对比ProcessTime和窗口EndTime确定是否触发窗口,如果窗口Process大于WindowsEndTime则触发计算,否则窗口继续等待;
CountTrigge
根据接入数据量是否超过设定的阈值确定是否触发窗口计算
(6)Evictors数据剔除器
Evictors是F1ink窗口机制中一个可选的组件,其主要作用是对进入WindowFunction前后的数据进行剔除处理,Flink内部实现了CountEvictor、DeltaEvitor、TimeEvictor三种。
CountEvictor
保持在窗口中具有固定数据量的记录,将超过指定大小的数据在窗口计算前剔除。
DeltaEvictor
通过定义DeltaFucntion和指定threshold,并计算Windows中的元素与最新元素之间的Delta大小,如果超过threshold则将当前数据元素剔除
TimeEvictor
通过指定时间间隔,将当前窗口中最新元素的时间减去Interval,然后将小于该结果的数据全部剔除,其本质是将具有新时间的数据选择出来,删除过时的数据。

以上内容仅供参考学习,如有侵权请联系我删除!
如果这篇文章对您有帮助,左下角的大拇指就是对博主最大的鼓励。
您的鼓励就是博主最大的动力!