最近,一家名为 BigPanda 的初创公司邀请我对数据科学项目的结构和流程发表自己的看法,这让我思考是什么让它们独一无二。初创公司的经理和不同团队可能会发现,数据科学项目和软件开发之间存在差异,这种差异并不那么直观,而且令人困惑。如果没有明确的说明和解释,这些根本差异可能会引起数据科学家和同事之间的误解和冲突。
分别来说,来自学术界(或高度研究型的行业研究小组)的研究人员在进入初创公司或小型公司时,可能会面临各自的挑战。他们可能会发现,将新类型的输入(如产品和业务需求、更紧密的基础设施和计算限制以及客户反馈)纳入他们的研究和开发过程中具有挑战性。
因此,本文写作目的就是介绍我和同事在近年来的工作中所发现的具有特色的项目流程。希望本文能够帮助数据科学家与他们一起工作的人,以反映他们独特性的方式来构建数据科学项目。
这个流程是基于小型初创公司的想法建立起来的:一个由数据科学家(通常是一到四个人)组成的小团队,一次只负责一个人领导的中小型项目。规模更大的团队或那些以机器学习为先的高科技初创公司的团队,可能会仍然认为这是一个有用的结构,但在许多情况下,流程会更长,结构也会有所不同。
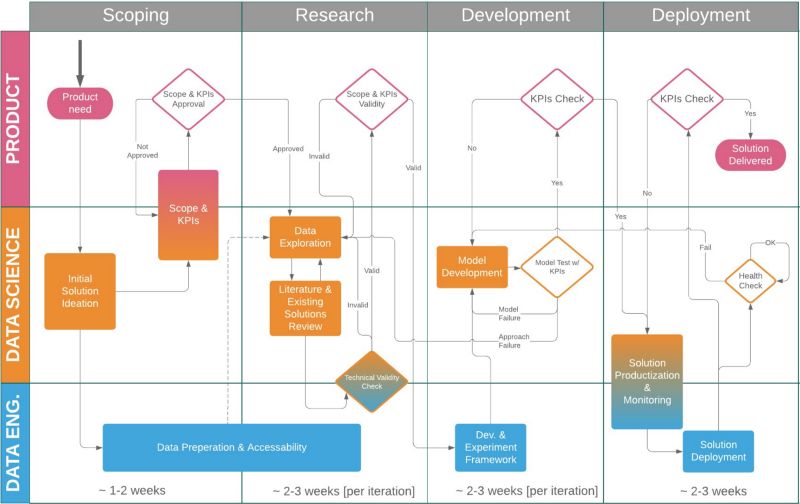
图 1:初创公司的数据科学项目流程
我将流程分为三个并行运行的方面:产品、数据科学和数据工程。在许多情况下(包括我工作过的大多数地方),可能并没有数据工程师来执行这些职责。在这种情况下,数据科学家通常负责与开发人员合作,帮助他解决这些方面的问题(如果他是全能大神:全栈数据科学家,那么他自己就可以凭一己之力解决所有的问题✨