一. HashSet初识
HashSet是Java集合Set的一个实现类,Set是一个接口,其实现类除HashSet之外,还有TreeSet,并继承了Collection,HashSet集合很常用,同时也是程序员面试时经常会被问到的知识点,下面是结构图
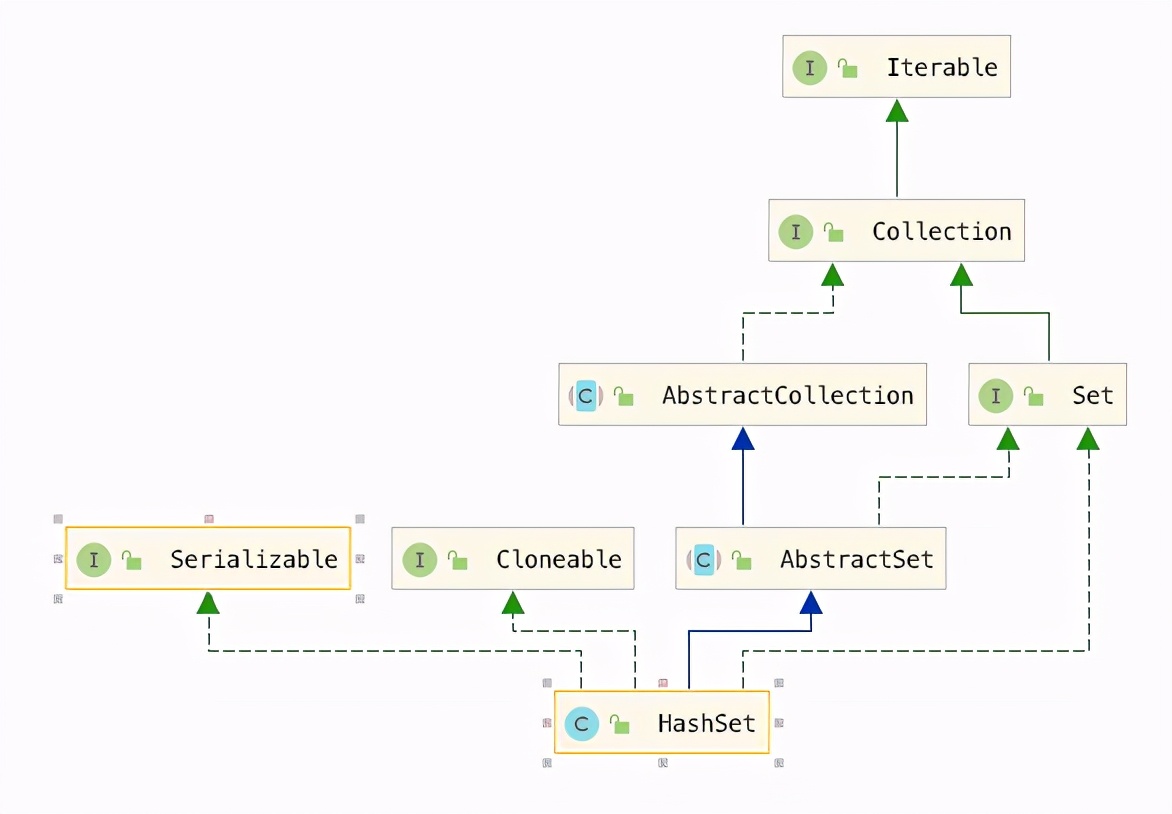
还是一如既往地看一下类的注释
/**
* This class implements the <tt>Set</tt> interface, backed by a hash table (actually a <tt>HashMap</tt> instance). It makes no guarantees as to the iteration order of the set;
* in particular, it does not guarantee that the order will remain constant over time. This class permits the <tt>null</tt> element.
* 这个类实现了set 接口,并且有hash 表的支持(实际上是HashMap),它不保证集合的迭代顺序
* This class offers constant time performance for the basic operations(<tt>add</tt>, <tt>remove</tt>, <tt>contains</tt> and <tt>size</tt>),
* assuming the hash function disperses the elements properly among the buckets.
* 这个类的add remove contains 操作都是常数级时间复杂度的
* Iterating over this set requires time proportional to the sum of the <tt>HashSet</tt> instance's size (the number of elements) plus the
* "capacity" of the backing <tt>HashMap</tt> instance (the number of buckets).
* 对此集合进行迭代需要的时间是和该集合的大小(集合中存储元素的个数)加上背后的HashMap的大小是成比列的
* Thus, it's very important not to set the initial capacity too high (or the load factor too low) if iteration performance is important.
* 因此如果迭代的性能很重要,所以不要将初始容量设置的太大(因为这意味着背后的HashMap会很大)
* <p><strong>Note that this implementation is not synchronized.</strong> If multiple threads access a hash set concurrently,
* and at least one ofthe threads modifies the set, it <i>must</i> be synchronized externally.
* 注意次集合没有实现同步,如果多个线程并发访问,并且至少有一个线程会修改,则必须在外部进行同步(加锁)
* This is typically accomplished by synchronizing on some object that naturally encapsulates the set.
* 通常在集合的访问集合的外边通过对一个对象进行同步实现(加锁实现)
* If no such object exists, the set should be "wrapped" using the @link Collections#synchronizedSet Collections.synchronizedSet} ethod.
* 如果没有这样的对象,可以尝试Collections.synchronizedSet 方法对set 进行封装(关于Collections工具类我单独写了一篇,可以自行查看)
* this is best done at creation time, to prevent accidental unsynchronized access to the set:<pre> Set s = Collections.synchronizedSet(new HashSet(...));</pre>
* 这个操作最好是创建的时候就做,防止意外没有同步的访问,就像这样使用即可 Set s = Collections.synchronizedSet(new HashSet(...))
* <p>The iterators returned by this class's <tt>iterator</tt> method are <i>fail-fast</i>: if the set is modified at any time after the iterator is
* created, in any way except through the iterator's own <tt>remove</tt> method, the Iterator throws a {@link ConcurrentModificationException}.
* 这一段我们前面也解释过很多次了关于fail-fast 我们不解释了(可以看ArrayList 一节)
* Thus, in the face of concurrent modification, the iterator fails quickly and cleanly, rather than risking arbitrary, non-deterministic behavior at an undetermined time in the future.
* <p>Note that the fail-fast behavior of an iterator cannot be guaranteed as it is, generally speaking, impossible to make any hard guarantees in the
* presence of unsynchronized concurrent modification. Fail-fast iterators
* throw <tt>ConcurrentModificationException</tt> on a best-effort basis.
* Therefore, it would be wrong to write a program that depended on this exception for its correctness: <i>the fail-fast behavior of iterators should be used only to detect bugs.</i>
*
* @author Josh Bloch
* @author Neal Gafter
* @see Collection
* @see HashMap
* @since 1.2
*/
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{ ... }1. HashSet 构造方法
首先我们总体看一下,它就下面这几个构造方法,后面我们再一一细看
private transient HashMap<E,Object> map;
//默认构造器
public HashSet() {
map = new HashMap<>();
}
//将传入的集合添加到HashSet的构造器
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
//仅明确初始容量的构造器(装载因子默认0.75)
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
//明确初始容量和装载因子的构造器
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
//
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
通过对下面的源码进行阅读和对类注释的理解,我们发现了HashSet就TM是一个皮包公司,它就对外接活儿,活儿接到了就直接扔给HashMap处理了。因为底层是通过HashMap实现的,这里简单提一下:
HashMap的数据存储是通过数组+链表/红黑树实现的,存储大概流程是通过hash函数计算在数组中存储的位置,如果该位置已经有值了,判断key是否相同,相同则覆盖,不相同则放到元素对应的链表中,如果链表长度大于8,就转化为红黑树,如果容量不够,则需扩容(注:这只是大致流程)。
无参构造
默认的构造函数,也是最常用的构造函数
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has default initial capacity (16) and load factor (0.75).
* 创建一个新的、空的set, 背后的HashMap实例用默认的初始化容量和加载因子,分别是16和0.75
*/
public HashSet() {
map = new HashMap<>();
}基于集合构造
/**
* Constructs a new set containing the elements in the specified collection. The <tt>HashMap</tt> is created with default load factor (0.75) and
* an initial capacity sufficient to contain the elements in the specified collection.
* 创建一个新的包含指定集合里面全部元素的set,背后的HashMap 依然使用默认的加载因子0.75,但是初始容量是足以容纳需要容纳集合的(其实就是大于该集合的最小2的指数,更多细节可以查看HashMap 那一节的文章)
* @param c the collection whose elements are to be placed into this set
* @throws NullPointerException if the specified collection is null 当集合为空的时候抛出NullPointerException
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}指定初始容量构造
其实下面是有三种构造类型的,但是我把它读归结到了这一类中,因为它们都指定了初始容量
只指定了初始容量
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has the specified initial capacity and default load factor (0.75).
* 创建一个新的,空的集合,使用了默认的加载因子和以参数为参考的初始化容量
* @param initialCapacity the initial capacity of the hash table
* @throws IllegalArgumentException if the initial capacity is less than zero 参数小于0的时候抛出异常
*/
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}以参数为参考的初始化容量,具体为什么这样表述,也可以看深度剖析Hashmap
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has the specified initial capacity and the specified load factor.
* 创建一个新的,空的集合,使用了指定的加载因子和以参数为参考的初始化容量
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @throws IllegalArgumentException if the initial capacity is less than zero, or if the load factor is nonpositive 加载因子和初始容量不合法
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}dummy
关于这个我们后面在LinkedHashSet中详细讲解,其实就是在LinkedHashSet中会给这个参数一个True,那么这个时候map 就是LinkedHashMap的引用了,而不是HashMap
/**
* Constructs a new, empty linked hash set. (This package private constructor is only used by LinkedHashSet.) The backing HashMap instance is a LinkedHashMap with the specified initial
* capacity and the specified load factor.
* 忽略 dummy 参数的话和前面一样,这个构造方法主要是在LinkedHashSet中使用,而且你看到这个时候map 不再直接是HashMap 而是 LinkedHashMap
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @param dummy ignored (distinguishes this constructor from other int, float constructor.)
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}HashSet 的重要属性
map
前面说了,HashSet 就是一皮包公司,这里就是它后面的大老板,也就是真正干活的人,HashSet 的所有数据都是存在这个HashMap里的
private transient HashMap<E,Object> map;PRESENT
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();这个值有点意思啊,就是HashMap 接受的实一个key-value 键值对,所以每次当你add 一个元素到HashSet 的时候,它都把你的参数e 和这个元素组成键值(e-PRESENT)对交给HashMap
天哪,我就没见过这么不要脸的数据结构,还给自己起名 HashSet 搞得跟 HashMap 是同一级别上的,对外糊弄用户,对内欺骗HashMap,每次value 都给人一不变的数据这不跟蛋壳一样了吗,一刀双割
二 . HashSet 的常用方法
1. add方法
public static void main(String[] args) {
HashSet hashSet=new HashSet<String>();
hashSet.add("a");
}
复制代码HashSet的add方法时通过HashMap的put方法实现的,不过HashMap是key-value键值对,而HashSet是集合,那么是怎么存储的呢,我们看一下源码
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
/**
* Adds the specified element to this set if it is not already present,If this set already contains the element, the call leaves the set unchanged and returns <tt>false</tt>.
* 添加一个 不存在的元素到集合,如果已经存在则不作改动,然后返回false
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified 不存在在返回true,存在返回false
*/
public boolean add(E e) {
// map.put(e, PRESENT) 的返回值就是oldValue
return map.put(e, PRESENT)==null;
}
复制代码看源码我们知道,HashSet添加的元素是存放在HashMap的key位置上,而value取了默认常量PRESENT,是一个空对象,其实看到这里我忍不住吐槽啊,给个null 不香吗,HashMap 是支持null 作为key和value 的啊,更何况这里只是value 呢,虽然这里你都是使用的实同一个对象PRESENT,但是这个时候null 才是正解啊
还有一点要说的就是关于返回值的问题,我们知道HashMap.put() 方法的返回值是oldValue,当然可能是null——也就是不存在oldValue,而HashSet就是根据oldValue是否为空来决定返回值的,也就是说oldValue不为空的时候返回false 说明已经存在,其实大家可以考虑一个问题那就是这里为什么不先判断一下是否存在呢,当不存在的时候再添加,不是更合理吗,欢迎讨论
HashMap 不判断是否存在,是因为它的value 是有意义的,因为value 要更新,但是HashSet 呢
至于map的put方法,大家可以看深度剖析Hashmap
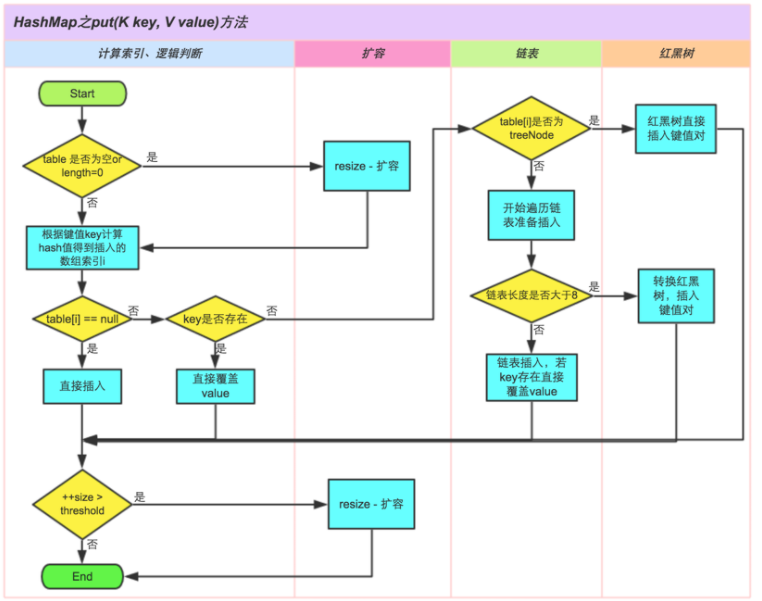
当然add 方法也有其他的变体,例如addAll(Collection<? extends E> c) 方法
2. remove方法
HashSet的remove方法通过HashMap的remove方法来实现
/**
* Removes the specified element from this set if it is present. More formally, removes an element if this set contains such an element. Returns <tt>true</tt>
* 如果set 中有这个元素的话,remove 操作会将它删除,通常情况下,如果存在的话返回True
* @param o object to be removed from this set, if present 如果存在则删除
* @return <tt>true</tt> if the set contained the specified element
*/
public boolean remove(Object o) {
// 调用了HashMap 的remove 方法
return map.remove(o)==PRESENT;
}
//map的remove方法
public V remove(Object key) {
Node<K,V> e;
//通过hash(key)找到元素在数组中的位置,再调用removeNode方法删除
return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
//步骤1.需要先找到key所对应Node的准确位置,首先通过(n - 1) & hash找到数组对应位置上的第一个node
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
//1.1 如果这个node刚好key值相同,运气好,找到了
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
/**
* 1.2 运气不好,在数组中找到的Node虽然hash相同了,但key值不同,很明显不对, 我们需要遍历继续
* 往下找;
*/
else if ((e = p.next) != null) {
//1.2.1 如果是TreeNode类型,说明HashMap当前是通过数组+红黑树来实现存储的,遍历红黑树找到对应node
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
//1.2.2 如果是链表,遍历链表找到对应node
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
//通过前面的步骤1找到了对应的Node,现在我们就需要删除它了
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
/**
* 如果是TreeNode类型,删除方法是通过红黑树节点删除实现的,具体可以参考【TreeMap原理实现
* 及常用方法】
*/
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
/**
* 如果是链表的情况,当找到的节点就是数组hash位置的第一个元素,那么该元素删除后,直接将数组
* 第一个位置的引用指向链表的下一个即可
*/
else if (node == p)
tab[index] = node.next;
/**
* 如果找到的本来就是链表上的节点,也简单,将待删除节点的上一个节点的next指向待删除节点的
* next,隔离开待删除节点即可
*/
else
p.next = node.next;
++modCount;
--size;
//删除后可能存在存储结构的调整,可参考【LinkedHashMap如何保证顺序性】中remove方法
afterNodeRemoval(node);
return node;
}
}
return null;
}
复制代码removeTreeNode方法具体实现可参考 TreeMap原理实现及常用方法
afterNodeRemoval方法具体实现可参考深度剖析LinkedHashMap,但是在这里它使用的是HashMap中的空方法,其实没有实际意义
3. 遍历
顺序性的问题
HashSet作为集合,有多种遍历方法,如普通for循环,增强for循环,迭代器,我们通过迭代器遍历来看一下
public static void main(String[] args) {
HashSet<String> setString = new HashSet<> ();
setString.add("星期一");
setString.add("星期二");
setString.add("星期三");
setString.add("星期四");
setString.add("星期五");
Iterator it = setString.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
}
复制代码打印出来的结果如何呢?
星期二
星期三
星期四
星期五
星期一
复制代码意料之中吧,HashSet是通过HashMap来实现的,HashMap通过hash(key)来确定存储的位置,是不具备存储顺序性的,因此HashSet遍历出的元素也并非按照插入的顺序。
快速失败的问题
关于这个演示在前面的其他集合里面我已经给出了,但是为了强调这个问题,这里我也再给出一个,当然这个使用的场景就是你想在遍历的过程中,根据情况的集合进行一下操作
@Test
public void iterator() {
HashSet<String> setString = new HashSet<> ();
setString.add("星期一");
setString.add("星期二");
setString.add("星期三");
setString.add("星期四");
setString.add("星期五");
System.out.println(setString.size());
Iterator<String> it = setString.iterator();
while (it.hasNext()) {
String tmp=it.next();
if (tmp.equals("星期三")){
setString.remove(tmp);
}
System.out.println(tmp);
}
System.out.println(setString.size());
}
复制代码运行结果
5
星期二
星期三
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.HashMap$HashIterator.nextNode(HashMap.java:1445)
at java.util.HashMap$KeyIterator.next(HashMap.java:1469)
at datastructure.java数据类型.hash.JavaHashSet.main(JavaHashSet.java:17)
复制代码你只要稍作修改即可
@Test
public void iterator() {
HashSet<String> setString = new HashSet<> ();
setString.add("星期一");
setString.add("星期二");
setString.add("星期三");
setString.add("星期四");
setString.add("星期五");
System.out.println(setString.size());
Iterator<String> it = setString.iterator();
while (it.hasNext()) {
String tmp=it.next();
if (tmp.equals("星期三")){
it.remove();
}
System.out.println(tmp);
}
System.out.println(setString.size());
}
复制代码5
星期二
星期三
星期四
星期五
星期一
4
复制代码三. 总结
HashSet 其实就是一个在某种场景下,催化出来的一个数据结构,几乎没有自己的实现,都是借助HashMap 来实现了种种功能,文章中我们也给出了一些思考题,就是关于HashSet add 方法为什么不先判断一下是否存在,而是直接走了HashMap put 方法,然后在根据put 的返回值进行判断结果
HashSet 性能
需要注意的是,容量是对HashSet 的迭代性能是有影响的,因为迭代要考虑实际存储元素个数和容量大小的
