jdk和jre区别
jre是运行Java程序时的环境,jdk时编译Java代码的工具,包括一些简单的库
Oracle jdk和 open jdk的区别
前者更新慢后者更新快,前者是被收购后的,后者是被收购前的
Java 和javax区别
javax是拓展的,后来两个合在一起了
线程的启动方式
实现 Runnable 接口,继承 Thread 类
如果一个类继承 Thread类,则不适合于多个线程共享资源,而实现了 Runnable 接口,就可以方便的实现资源的共享。
集合的类型,哪些有序无序
list,set,map,queue,
list有序,set和map无序
set底层是map,map是key和value
set的值唯一,list的值可以不唯一,map下标唯一,值不唯一
hashmap底层
底层就是一个哈希表
jdk1.8之前,使用数组+链表的形式
jdk1.8之后,冲突小于8用数组+链表的形式,>=8使用红黑树
为什么不用平衡二叉树?因为平衡二叉树在特定情况下还是线性树
然后设置容量的话,就是幂指的形式了
MySQL调优
emmm
事务的特性
4个特性,acid
ACID,指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
GC垃圾回收算法
常用的有标记清除,复制,标记整理和分代收集算法
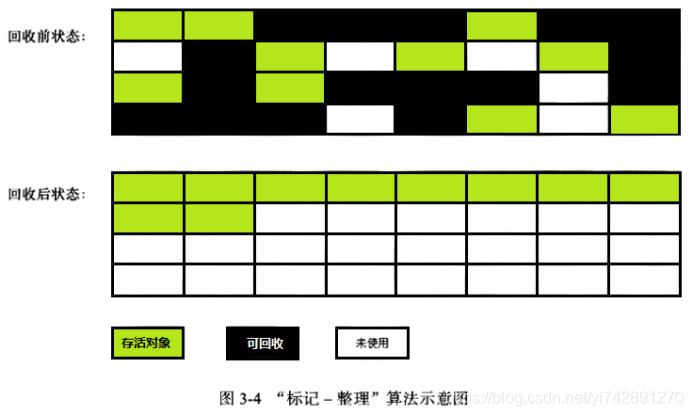
标记清除
标记清除算法就是分为“标记”和“清除”两个阶段。标记出所有需要回收的对象,标记结束后统一回收。这个套路很简单,也存在不足,后续的算法都是根据这个基础来加以改进的。
其实它就是把已死亡的对象标记为空闲内存,然后记录在一个空闲列表中,当我们需要new一个对象时,内存管理模块会从空闲列表中寻找空闲的内存来分给新的对象。
人话:把已经死亡,已经没用的对象标记,然后记录在一个空闲列表中,当要new一个对象时,从空闲的内存中拿。
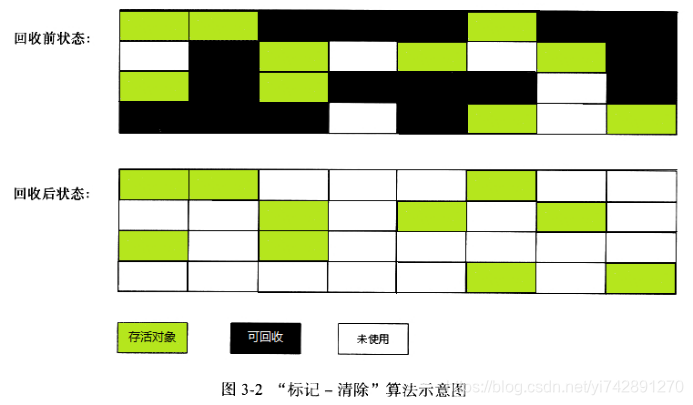
复制算法
将内存平均划分为2边,一边空,一边用。用的一边就平常使用,垃圾的,未用的,还在用的,都放一起,然后满的时候,就清除垃圾,把还在用的放在另一边,自己这一边就全部清空
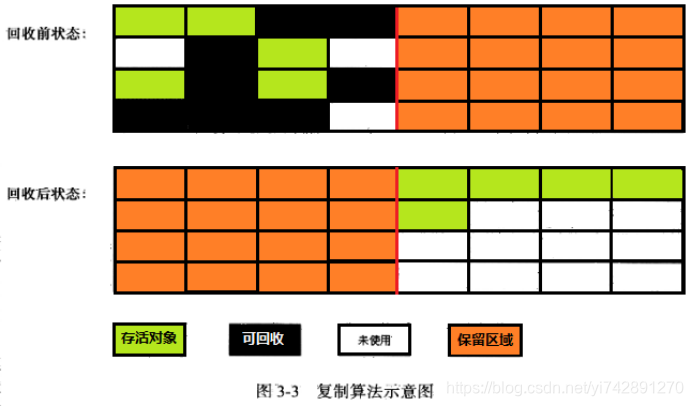
标记整理算法
复制算法在对象存活率高的时候会有一定的效率问题,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉边界以外的内存
分代收集算法
这种算法并没有什么新的思想,只是根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清理”或者“标记-整理”算法来进行回收。
人话:就是把内存划分出来,没批空间放不同的类型,然后哪些空间就按照上面的算法去清除
三范式
第一范式:即表的列的具有原子性,不可再分解,即列的信息,不能分解。
人话:每个字段分得不能再分下去了,已经是最小元素了
第二范式:满足第一范式得情况下,有主键就是第二范式
第三范式:满足第二范式得情况下,非主键字段不能相互依赖
MySQL用了什么引擎
Innodb:默认、支持事务安全,支持行级锁,用于增改,
默认的,
支持事务,是事务安全的,提供行级锁与外键约束,有缓冲池,用于缓冲数据和索引
适用场景:用于事务处理,具有ACID事物支持,应用于执行大量的insert和update操作的表
MyISAM:不支持事务、外键、锁,用于查
不支持事务,不支持外键约束,不支持行级锁,操作时需要锁定整张表,不过会保存表的行数,所以当执行select count(*) from tablename时执行特别快
适用场景:用于管理非事务表,提供高速检索及全文检索能力,适用于有大量的select操作的表,如 日志表
MEMORY:用于精准查找
使用存在于内存中的内容创建表,每一个memory只实际对应一个磁盘文件。因为是存在内存中的,所以memory访问速度非常快,而且该引擎使用hash索引,可以一次定位,不需要像B树一样从根节点查找到支节点,所以精确查询时访问速度特别快,但是非精确查找时,比如like,这种范围查找,hash就起不到作用了。另外一旦服务关闭,表中的数据就会丢失,因为没有存到磁盘中。
适用场景:主要用于内容变化不频繁的表,或者作为中间的查找表。对表的更新要谨慎因为数据没有被写入到磁盘中,服务关闭前要考虑好数据的存储
==和equals的区别
基本类型(int ,float)中,==和equals没有区别
引用类型中(String),==比较两者的地址,equals比较地址中的值
String 、Stringbuffer 、Stringbuilder
3者的原理,区别
String 的存储char数组中,有final限制,就是不会被其他类继承
比如修改String中的东西,其本质不是修改,而是新建一个char[]数组,赋值进去,然后将char [] 赋值给String
Stringbuffer 没有final限制,有同步锁
Stringbuilder 没有final限制,没同步锁
哪些安全哪些不安全
String 、Stringbuffer 是安全的,因为String有final,Stringbuffer 有同步锁
Stringbuilder是不安全的,因为没有final和同步锁
各自的应用范围
单线程数据量大,用Stringbuilder
多线程数据量大,用Stringbuffer
怎么记?
String 有final都知道对吧
Stringbuffer 嘛,有buff,所以有锁和处理多线程
Stringbuilder 还在build中,啥也没有,所以不安全,只能处理单线程大的东西
MySQL的数据类型
数值类型
tinyint smallint mediumint int bigint float double mecimal
其中精度mecimal>double>float
时间类型
date time datetime timestamp
字符类型
char varchar BLOB text
Java基本类型
布尔、byte、short、int、long、float、double、char
tcp和udp协议的区别
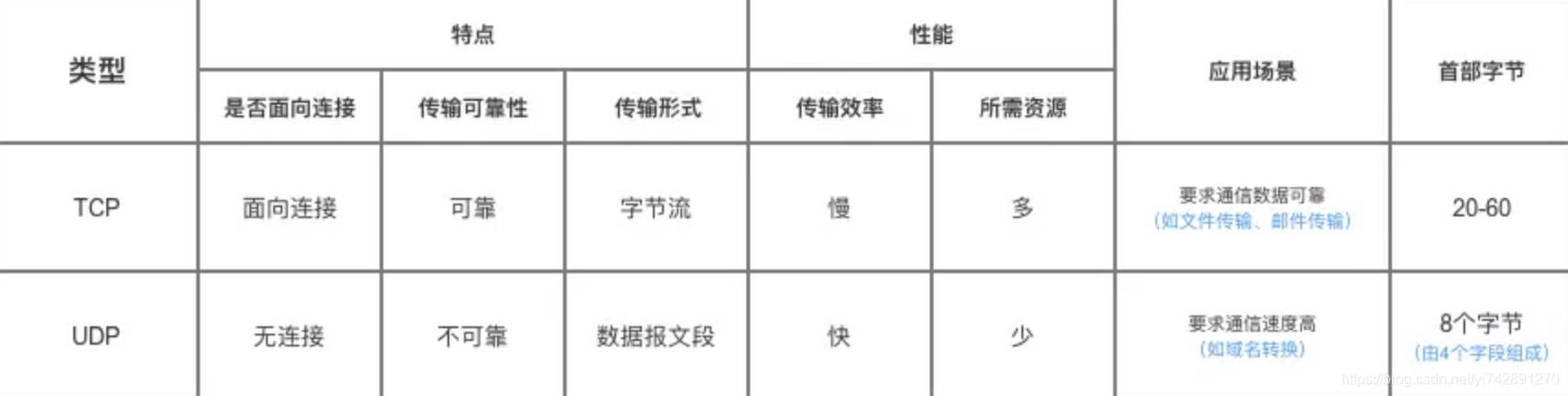
UDP用于网络通话这方面,TCP用于短信发送
速度上
udp比tcp快
个数上
udp:一对一、一对多
tcp:一对一、点对点
可靠性
tcp可靠,因为3次握手
udp不可靠,就发送,没有握手
3次握手
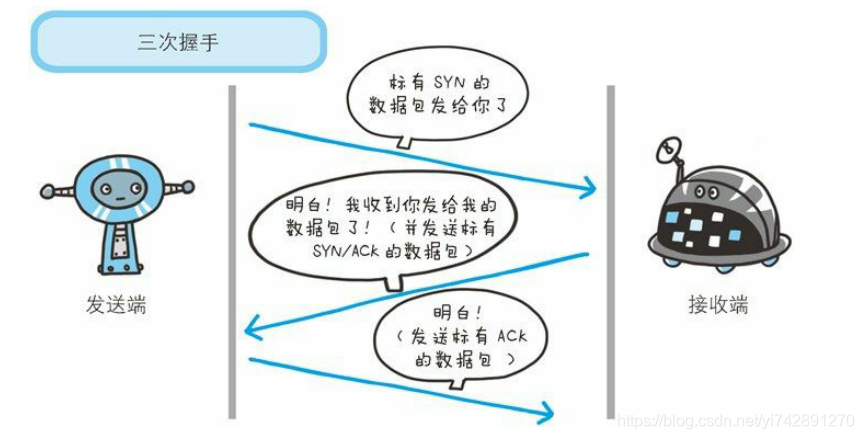

客户端–发送带有 SYN 标志的数据包–一次握手–服务端
服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
为什么要三次握手
三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。
第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常
第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:对方发送正常,自己接收正常
第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
所以三次握手就能确认双发收发功能都正常,缺一不可。
HashMap 和 TreeMap 区别
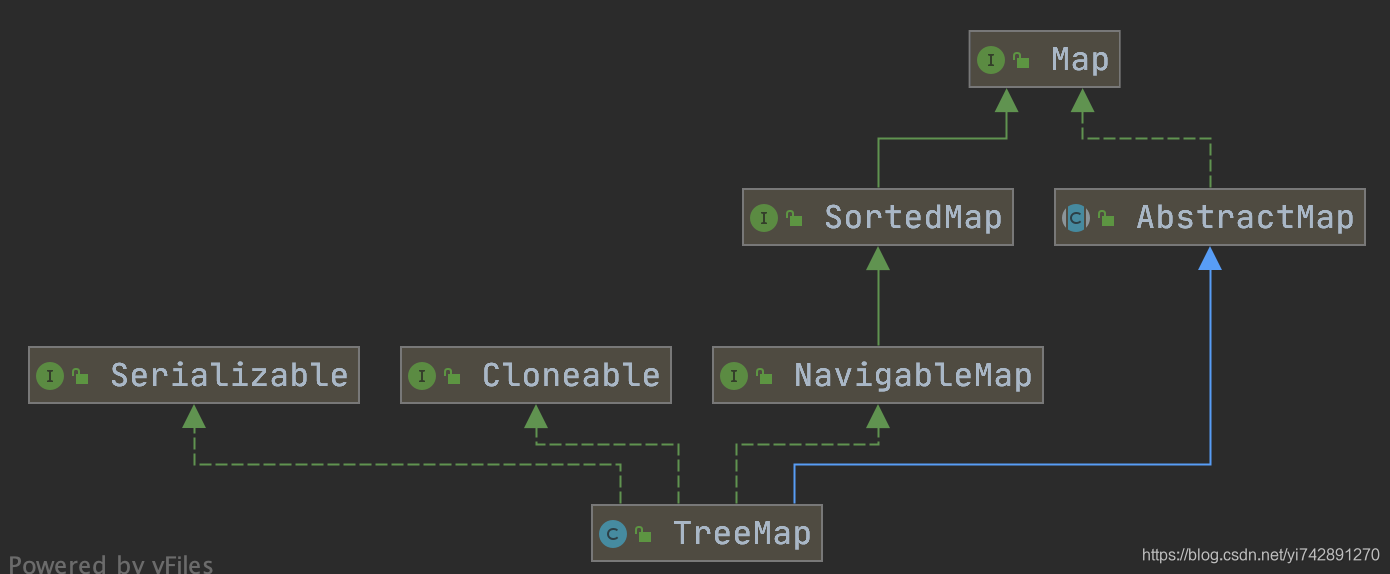
实现 NavigableMap 接口让 TreeMap 有了对集合内元素的搜索的能力。
实现SortMap接口让 TreeMap 有了对集合中的元素根据键排序的能力。默认是按 key 的升序排序