目录
一、前言
前不久线上环境出现了一次postgresql的cpu飙升的生产故障,cpu飙到95%且高居不下,最后发现是迭代中改过的一段sql导致,虽然直到现在都还没想好怎么优化,但这边还是先记录下这次故障以及从这次故障中学习到的postgresql中的一些知识点。
二、关于故障
1、故障现象
大部分操作加载缓慢,出现加载超时报错问题
2、故障解决过程
1、查看服务器告警及日志信息,cpu使用率持续上升,在10:10时接近百分百,数据库连接数超过所设阈值,引起应用响应缓慢
2、分析数据库sql,发现多条异常sql(20条),多次手动kill异常SQL无效
3、分析数据库sql,发现很多大量等待的sql为某个服务相关的sql
4、查看服务器日志,发现接口端某家公司频繁调用员工更新接口,对应服务响应缓慢,运维同事调节Ngnix接口访问频率,由原来的每秒5个,缩减到每分钟5个
5、调节Ngnix接口的访问频率后,数据库CPU仍未明显下降
6、在11:18分切换数据库实例的主从,切换后并重启主应用,切换后CPU仍未明显下降
7、此时初步判定为应用代码中sql的性能问题,上迭代sql改动较大的为待审批查询
8、11:25后准备待审批部分的代码回滚,并在dev环境进行测试
9、13:00在dev环境验证完代码后,开始线上环境的打包部署
10、13:10 线上环境数据库逐渐下降,并趋于稳定
3、故障原因分析
故障恢复后,基本确定是待审批的sql引发,随即从以下几方面分析查找此次故障原因:
1、查看数据库监控与告警页面
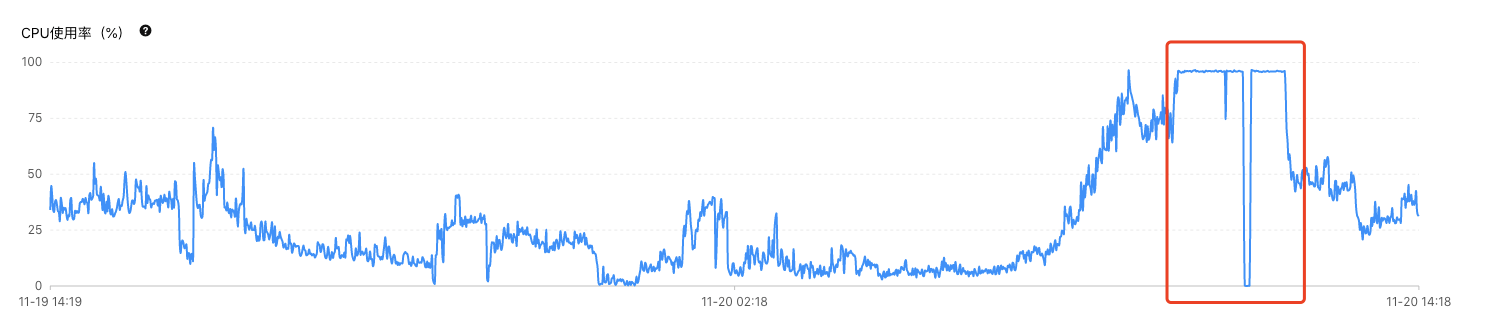
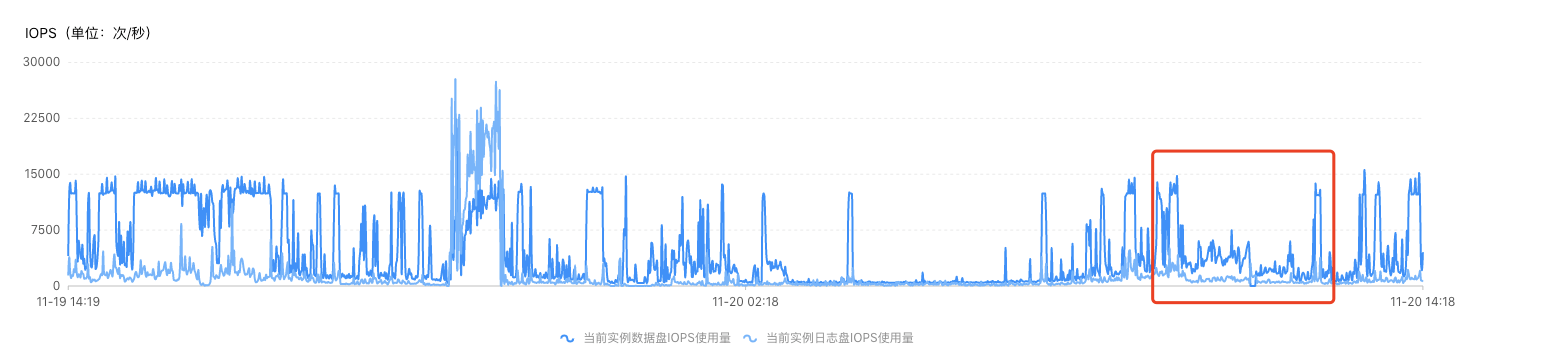
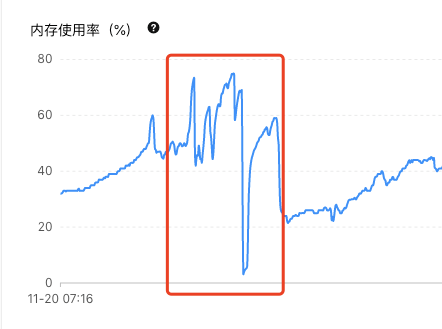
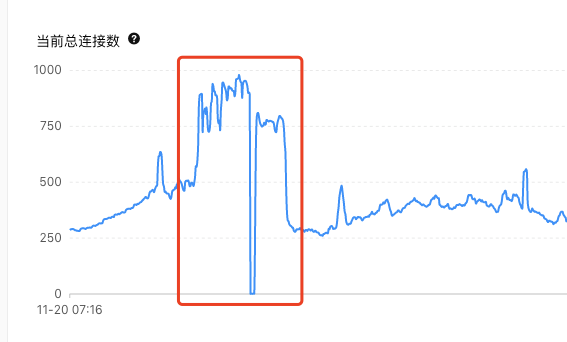
由这部分图可得,cpu使用率持续上升,内存使用率上升,但是iops在这段时间内并未飙升且比正常更低,得知实际访问磁盘进行读写的sql相比正常更少,连接数在这段时间内也疯狂增长且无法释放,即使重启应用后,连接数也瞬间飙升,说明这部分待审批相关sql执行较慢,连接无法释放,而这部分sql慢的主要原因也并不是因为磁盘压力大,而是由于cpu和内存的压力过大导致绝大部分sql都处于等待状态,说明这部分sql对内存压力很大,可能是查询一直命中缓存或者是sql计算过程较长
2、查看日志管理中的慢日志明细
发现在cpu从正常飙升到95%这段过程中,待审批相关sql出现的频率非常高,大部分都在1s或2s,当飙高之后其实这里的慢sql就没啥意义了,整个应用延迟都较高,因此各种各样的慢sql都有,而一开始我们其实就被这个给忽悠了。
3、对比前后sql,寻找故障最主要原因
引发此次最主要的问题主要是使用了gist索引,再加上原sql本身又比较复杂,导致需要进行的计算过大,使得cpu进行飙升
下面先看下原sql(不全):
select proc_task_id
from (
(
select t.id_ proc_task_id
from act_ru_task t
join reimburse_data rd on rd.proc_inst_id = t.proc_inst_id_
left join act_ru_variable v_al on v_al.task_id_ = t.id_ and v_al.name_ = 'allocationCode'
left join reimburse_allocation ra on v_al.text_ = ra.allocation_code and rd.reimburse_data_code =
ra.reimburse_data_code
where t.suspension_state_ = 1
and t.category_ = 'APPROVAL'
and t.assignee_ = 'UI2008051OZLZ8QO'
and rd.flag != -1
and t.create_time_ < (current_timestamp - interval '10 seconds')
)
union all
(
select t.id_ proc_task_id
from act_ru_task t
join reimburse_data rd on rd.proc_inst_id = t.proc_inst_id_
left join act_ru_variable v_al on v_al.task_id_ = t.id_ and v_al.name_ = 'allocationCode'
left join reimburse_allocation ra on v_al.text_ = ra.allocation_code and rd.reimburse_data_code =
ra.reimburse_data_code
where t.suspension_state_ = 1
and t.category_ = 'APPROVAL'
and t.assignee_ is null
and t.create_time_ < (current_timestamp - interval '10 seconds')
and exists(
select 1
from act_ru_identitylink i
where i.task_id_ = t.id_
and i.type_ = 'candidate'
and (
i.user_id_ = 'UI2008051OZLZ8QO'
OR i.group_id_ = 'UI2008051OZLZ8QO'
or
i.user_id_ = 'UG200902X4ZMDEE_'
OR i.group_id_ = 'UG200902X4ZMDEE_'
or
i.user_id_ = 'UG200714ZA49XXS_'
OR i.group_id_ = 'UG200714ZA49XXS_'
or
i.user_id_ = 'UG2008191VRRW9OS_'
OR i.group_id_ = 'UG2008191VRRW9OS_'
)
)
and rd.flag != -1
)
) reim
left join form_ru_task ft
on reim.enterprise_code = ft.ent_code and reim.reimburse_data_code = ft.form_data_code and
proc_task_id = ft.task_id
where reim.enterprise_code = 'EC2002241IQ4WI9T'
and (ft.auto_complete = 'N' or ft.auto_complete is null);这部分sql本身因为业务关系就很庞大,当查询者本人被多人授权时,整个sql又会进行多次union操作,且每个授权情况下又分为审批人和审批组情况,当所在的用户组过多时便会产生较多or操作,由于activiti是将审批人和审批组单独存在另外一张表里且都建了btree索引,因此用户组匹配这里不会产生大问题,整段sql唯一的问题就是对磁盘读写压力较大
下面看下故障sql:
select proc_task_id
from (
(
select t.task_id as proc_task_id
from form_ru_task t
join reimburse_data rd on rd.proc_inst_id = t.proc_inst_id
left join reimburse_allocation ra
on t.allocation_code = ra.allocation_code and rd.reimburse_data_code =
ra.reimburse_data_code
where t.skip = 'N'
and t.deleted = 'N'
and t.is_current = 'Y'
and t.valid = 'Y'
and t.suspend_at is null
and (t.auto_complete = 'N' or t.auto_complete is null)
and (
t.assignee = 'UI1709212MG35TK' or (
t.assignee is null and (
t.valid_users like '%' || 'UI1709212MG35TK' || '%'
or (
t.valid_groups like '%' || 'UGSG1911041C502M5W' || '%'
or
t.valid_groups like '%' || 'UG1811201ELR0J9C_' || '%'
or
t.valid_groups like '%' || 'UG17103010CTDBEO_' || '%'
or
t.valid_groups like '%' || 'UGSG1908131DH64C2F' || '%'
or
t.valid_groups like '%' || 'UI1709212MG35TK' || '%'
or
t.valid_groups like '%' || 'UGSG1909171EWS2HCP' || '%'
or
t.valid_groups like '%' || 'UGSG2005061HZUK0CD' || '%'
or
t.valid_groups like '%' || 'UGSG1908131DH64C1Z' || '%'
or
t.valid_groups like '%' || 'UG1908131DH64C1V_' || '%'
or
t.valid_groups like '%' || 'UGSG1909052OE7DXB' || '%'
or
t.valid_groups like '%' || 'UGSG1908131DH64C21' || '%'
))
)
)
and t.task_type != 'TELLER'
and t.task_type != 'FINANCE_AUDIT'
and rd.flag != -1
and t.created_at < (current_timestamp - interval '10 seconds')
)
) reim
where reim.enterprise_code = 'EC1710251LQT24G1';切换查询主表后,可以看到明显少关联了三张表,且将审批人和审批组合并成一段查询语句,但是若存在授权情况,该sql仍会存在多次union all操作,因为业务关系这部分逻辑始终无法优化,这段sql所修改的查询条件也只有 valid_users 字段改动较大,因为需要全模糊搜索,但是pg的gist索引或gin索引是支持这种模糊查询的,所以这段sql在性能上是超过原先sql的,其性能较好的主要原因也就是减少了磁盘的读写,但增大了内存和cpu的计算压力,这段sql整体需要查询的数据块(查询语句中的缓存)远远低于旧sql
创建索引语句如下:
CREATE INDEX idx_frt_group_task_ent ON maycur.form_ru_task USING gist
(valid_groups gist_trgm_ops, task_type, ent_code);目前以自己的理解来看,由于系统中本身已经有gist索引的实践,但之前并未出现类似cpu压力持续增长的情况,猜测是之前的访问次数并不是很大,本次调整的sql又较为复杂,pg需要的计算可能更大一点,加上gist的分词索引算法扫描的索引项实在太多,而大部分索引项都直接命中缓存,因此直接访问内存,导致需要较多cpu计算,由于整个pg是共用一个缓存空间,导致这部分sql持续访问内存增大了内存压力。
4、从此次故障学到的东西
1、此次故障排查过程较慢,确定故障sql的过程较慢,由于是第一次遇到cpu飙升的问题,之前都是iops飙升,因此主观上认为是之前老出问题的服务导致,浪费较长时间;在确定故障sql时,还是应该排查cpu从正常飙升到95%这段过程中慢sql日志出现次数最多的几条sql,该重点分析这部分sql。
2、对某部分sql做出大调整时,最好先保留原部分sql,以争取在出现问题时能尽快回滚,这次由于代码回滚时也浪费了较多时间,因此整个故障解决也较慢。
3、重大调整的代码应尽量code review。
4、当出现数据库级别的重大改动时,测试需要从多维度进行压测观察,提高并发量,观察iops、cpu等指标的运行情况,避免出现一个指标较好而另一个指标较差。
三、关于PG
1、缓存
pg主要缓存了表数据、索引、查询计划(这部分随session断开后便会释放),缓存数据均存在于内存之中,这部分内存区域可以看成是一个以8kb的block为单位的数组,即最小分配单位是8kb(正好是一个page的大小),当pg想要从磁盘获取(主要是table和index)数据(page)时,他会(根据page的元数据)先搜索shared_buffers,确认该page是否在shared_buffers中,如果存在,则直接命中,返回缓存的数据以避免I/O。
如果不存在,pg才会通过I/O访问磁盘获取数据(显然要比从shared_buffers中获取慢得多)。
2、gist索引
gist即通用的搜索树,是一种平衡树结构的访问,是一个通用的索引接口,可以使用它实现任意索引模式,主要解决如范围是否相交,是否包含,地理位置中的点面相交,或者按点搜索附近的点等等。
gist是由节点页组成的高度平衡树,节点由索引行组成,叶节点的每一行都包含一些谓词(布尔表达式,索引字段运算符)和对表行(TID)的引用,索引数据(键)必须符合此谓词。内部节点的每一行(内部行)还包含一个谓词和对子节点的引用,并且子树的所有索引数据都必须满足此谓词。 换句话说,内部行的谓词包括所有子行的谓词。gist索引的这一重要特征取代了B树的简单排序。
不过gist索引是有损耗的,意味着该索引可能会产生错误的匹配,并且有必要检查实际的表行消除这种错误匹配(pg在需要时自动执行),因此我们这部分sql在业务复杂时可能产生了较多性能损耗消耗了太多cpu计算。
创建gist索引的前提是已经编译并安装了gist的扩展,然后在数据库中直接创建扩展即可:
create extension btree_gist;一般在建立gist索引时都会使用到trgm插件(分词索引),该插件对文本搜索性能提升非常有效,100万左右的数据量,性能提升有500倍以上。pg_trgm使用时是将字符串前端添加两个空格,末端添加一个空格,其余每三个连续的字符串作为一个token进行拆分,对token建立gist索引,下面即pg_trgm的分词效果:
SELECT SHOW_TRGM('viid');
{ v, vi,id ,iid,vii}由于pg_trgm是以三个连续的字符作为token,当你查询的词是一个或者两个时效果并不好,因此建议查询至少三个字符的情况,具体查询时是采用数组搜索的方式,如搜索%viid%,那么就是对应的字段token需要包含{ v, vi,id ,iid,vii},此时该字段的数据类型属于集合,由于RD-Tree索引算法作为集合索引,在索引项目包含的元素很多时其key的大小会急剧膨胀,因此pg中的一些gist操作符实现类中,使用签名的方法对索引项目的key进行了压缩,pg_trgm的集合类型便使用了这个作为gist索引算法,因此其大概步骤为:pg_trgm模块提供的gist_trgm_ops操作符先把数据拆分成若干三元词,并使用签名向量的形式压缩存储这些三元词,叶节点的索引项存储pg_trgm三元词的数组(pg_trgm生成三元词时,内部用了3个字节存储三元词,如果三元词中包含多字节字符,通过先计算CRC再取前3个字节的方法压缩),非叶节点的索引项存储其包含的所有三元词集合的签名向量,签名向量的大小为96bit,由于pg_trgm的gist索引的签名向量比较小,每次查询需要扫描的索引节点数必然很多,会很影响cpu计算速度。创建扩展如下:
create extension pg_trgm; 创建索引类似:
create index idx_tbl_1 on tbl using gist(info gist_trgm_ops); gist索引与btree索引的一个区别是在多字段索引时,前者只要是包含索引字段的任何子集都会使用索引扫描,而后者需要满足最左前缀原则,gist索引创建耗时和索引大小相比btree都较大,在and和or这种操作符时来说,gist索引性能与btree相比并没有提升多少。
四、后续优化
根据网上资料来看,gin索引+pg_trgm的性能在全模糊搜索上会大于gist+pg_trgm,经过测试,在我这种业务场景下甚至还慢了好多且命中的数据块相对而言更多,然后也测试过使用gin索引+数组匹配的方式来替代全模糊搜索,因为使用数组匹配会少很多or的情况,从理论上来说会好一点,但经过测试发现没什么区别甚至还是前者略胜一筹...
创建数组匹配索引:
CREATE INDEX idx_frt_array_group_task ON form_ru_task USING gin (string_to_array(valid_groups, ','), task_type);使用pg的 && 重叠函数,关于pg的数组函数可参考:https://www.cnblogs.com/alianbog/p/5665411.html
2020.12.21 目前没在继续优化,估计等明年和老大一起继续分析,如果有大佬经历过,恳请指点一二