 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录
引言
最近总喜欢没事的时候想一想上了大学以后究竟学了哪些东西,身为小组Linux/C服务端的一名成员,显然需要思考下对服务端编程来说有哪些需要注意的知识点。因为就写RabbitServer时的感受来说,确实感觉到了很多细小的知识点对于整体性能的影响也是巨大的,而这些是很多人未曾注意过的。我想这篇文章也是一个不但是一个很好的总结机会,同时也是给其他同学一个很好的学习资料。
当然这行水太深,凭借我这功力显然没办法在一篇文章中描述的清清楚楚,所以基本上这篇文章把范围限定在我去写RabbitServer时遇到的问题,解决的过程与更深的思考上。当然也欢迎大家来Fork/Star,这是RabbitServer的地址。
一次连接的断开与关闭
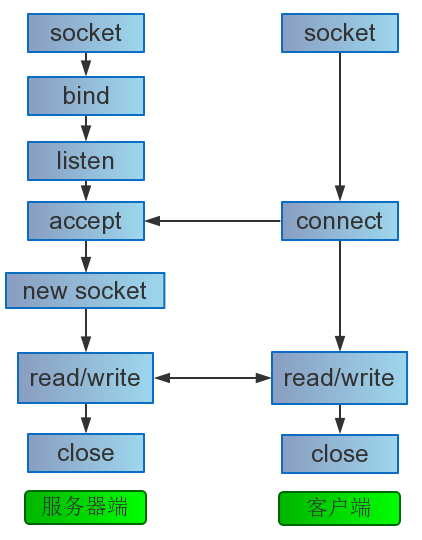
首先我们要聊的是一次客户端与服务器的连接究竟发生了什么,这个问题其实是一个非常有意思的问题,我们首先从函数调用的先后顺序上来看一看:
int socket(int domain, int type, int protocol);
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
int listen(int sockfd, int backlog);
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
int close(int fd);
int shutdown(int sockfd, int how);
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
以上这些函数我想每一个从事Linux服务端开发的朋友都不会陌生,这些可以说是最最基础的东西了,但是不妨每一个看官和我一起做一件事情,让我们把上面每一个函数的每一个参数过一遍。
当然,本篇文章不会浪费篇幅去描述每一项的含义,我想对于这种类型的知识点,man手册往往才是最优的选择。希望每一个看到这里的朋友能够把上面列出的函数每一项的含义再过一遍。但是对于几个重要的地方还是想提一提。
- 能使用
accept4就不要使用accept,因为服务端编程我们往往需要非阻塞的套接字,而accept创建的套接字默认是阻塞的,我们不得不调用一次fcntl来改变其属性,一次系统调用显然是昂贵的。 - 和上面的原因一样,
socket在内核2.6.27版本以后在type字段中也可以加入SOCK_NONBLOCK来使得套接字非阻塞,以在某些场合下节省一次系统调用。 - 对于
listen的第二个参数,一个老生常谈的问题,直接抛出结论,可以参与影响全连接队列长度,最终长度为min(SOMAXCONN, backlog),在socket.h中定义有SOMAXCONN. - 因为一次通信的两端可能中间的路由器跳数非常多,这可能导致一次通信会花费很长时间,如果把connect设置为非阻塞,这意味着最好的情况在一个RTT后connect才会返回,而这个开销可能长达数十秒,这驱动着我们必须使用非阻塞,所以对于
connect我们必须清楚其各种返回值,这个方面的教科书式代码应该就是muduo客户端中用户态重传部分的代码了,处理的非常精彩,也考虑到了一个非常让人匪夷所思的问题(我一直认为是内核的bug),即自连接问题。当然通过ip_local_port_range和设定小于前者左区间端口号可以避免,或者用户态重传,这分别在两端解决了这个问题。 - 显然
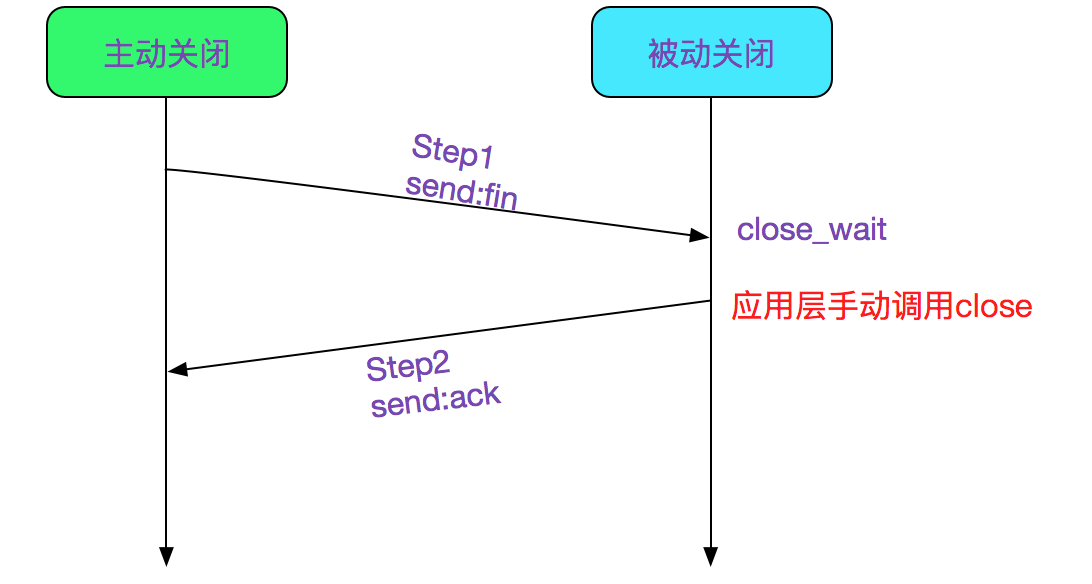
shutdown对于理解TCP四次挥手有巨大的好处,比如为什么fin和ack要分开发送? - 一直以来一直有一个言论在传播,就是
我感觉read/write和recv/send差不多呀,代码中也可以混用。只能说在某种程度上讲是对的,但是第四个参数中有些也是很有意思的,比如MSG_PEEK和MSG_WAITALL。
我们接下来看看一次TCP连接和关闭的过程中,以上函数和状态转移的关系:
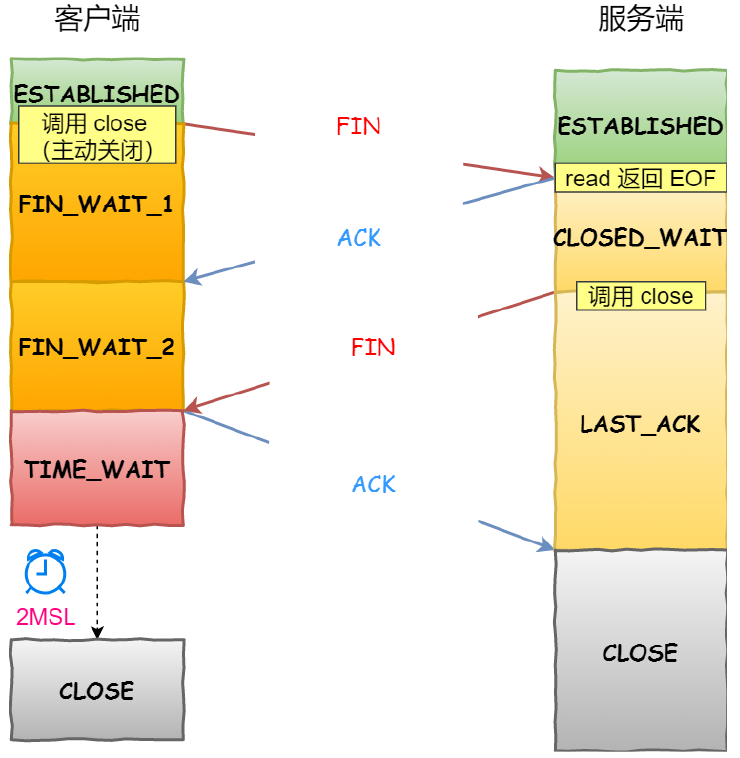
这里的第二幅图具有误导性,主动发起close会在收到Fin进入TIME_WAIT状态的时候才结束。而被动close在收到最后一个ack进入CLOSE的时候才结束,这也是为什么在RabbitServer压测分析的时候close的开销如此恐怖的原因。
客户端在ESTABLISHED状态的时候调用close,而服务端在CLOSED_WAIT的时候调用close,这里可以参考[2]。
这里暂时不想花大量的精力去描述TCP中每一步中的可以针对于不同业务场景进行优化的部分,这里其实说这话有点大言不惭了,其实也就是/proc/sys/net/ipv4中参数的修改,后面可能会单独列出一篇文章去描述一下,具体可参考[3]。
这里TIME_WAIT是一个很重要的点,面试常问。。这个本篇文章也不讨论,仅仅提一点,就是MSL一般被设置为2分钟,别问为什么,问就是规定,见[4]。
那么了解这些对于我们服务端编程是否有帮助呢?答案是当然的,不然我为什么要写呢(这不是废话)。了解这个过程可以让我们清楚什么时候哪一步是可以省略的,哪一步的重传间隔和重传次数是可以调整的。在一些交互比较频繁的场合连接和断开的开销相比与数据传输是巨大的,因为可能传输数据只需要两个包就结束了,连接和断开却需要七个包。
有时我们也希望能够更加了解在非预期情况下TCP的行为,比如三次握手的第三个ACK丢失(当然第三个ACK本来就不是必要的),此时双方的行为是怎样的(我们可以在服务端配置防火墙,墙掉客户端的ACK报文)?显然服务器会不停的重传,重传次数收tcp_synack_retries控制,默认次数为5,其实很多时候两三次的连续丢包就已经可以判断出网络状态很差了,那后面的包就是没什么意义的,此时我们就可以进行调整。诸如此类的例子很多,就不一一描述了。
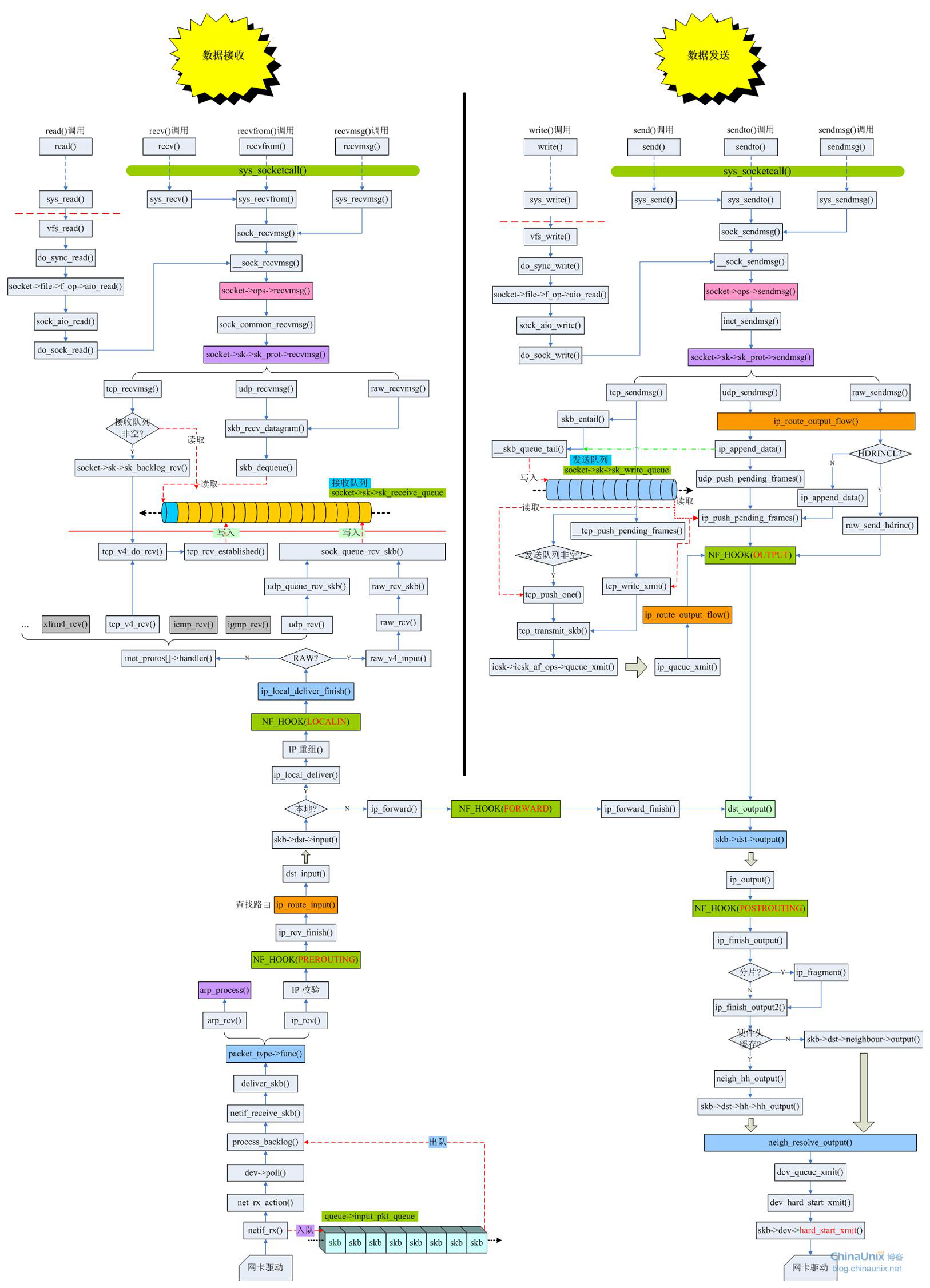
这里放一张图镇楼,图是从欢神那里拿的,描述了Linux内核数据接收和写入的完整过程,当然不清楚这张图是哪个内核版本的,所以当做一般学习参考即可:
套接字选项
int getsockopt(int sockfd, int level, int optname,
void *optval, socklen_t *optlen);
int setsockopt(int sockfd, int level, int optname,
const void *optval, socklen_t optlen);
这是一个新手非常容易忽视的点,我个人认为本质原因就是资料太少,因为下面列出的很多点不是从书本上看来的,而是在进行性能优化的时候从各种文档博客中学习到的。当然有人可能会说UNP151页,游双高性能的88页都描述了这些选项,为什么我还会说资料少呢?两个原因,一是不全,二是描述简单,不去用的话根本无法有更深的理解。当然文档肯定是有的[5],描述也很全,但是不用的话还是有没有用。
下面列出几点我认为比较常用和重要的选项,其中很多已经应用到了RabbitServer中:
TCP_DEFER_ACCEPT:
具体的操作结果可以参考[7],这个选项其实很多文章中都提到了此选项的作用是有效的防止针对于全连接队列的攻击,我个人认为就是扯淡,首先看看文档中的描述[5]:
Allow a listener to be awakened only when data arrives on the socket. Takes an integer value (seconds), this can bound the maximum number of attempts TCP will make to complete the connection. This option should not be used in code intended to be portable.
固然此选项可以防止针对于全连接队列的攻击,因为服务器收到第三个ACK的时候不进入ESTABLISHED,仍处于SYN_RECV,在第一个数据包到达的时候进入ESTABLISHED,这个过程因为处于SYN_RECV,所以重传次数仍受tcp_synack_retries影响,但是这绝对不是其价值所在。其作用是在客户端也设置相同参数的时候使得整个握手交互过程可以减少一个包。
TCP_NODELAY 和 TCP_CORK
这两者都可以避免Nagle算法对高性能服务器带来的负面影响,当然Nagle的描述可以参考[10],前者就不提了,直接取消小包延迟发送已提升响应速度。那么后者如何避免Nagle算法带来的影响呢?这里其实很多文章描述的都不详细,我们可以参考[5]中对TCP_CORK的描述:
If set, don’t send out partial frames. All queued partial frames are sent when the option is cleared again. This is useful for prepending headers before calling sendfile(2), or for throughput optimization. As currently implemented, there is a 200 millisecond ceiling on the time for which output is corked by TCP_CORK. If this ceiling is reached, then queued data is automatically transmitted. This option can be combined with TCP_NODELAY only since Linux 2.5.71. This option should not be used in code intended to be portable.
这里面第一句是最重要的,即如果设置了TCP_CORK,不会发送小包,注意,是不会。而Nagle的描述是:任意时刻,最多只能有一个未被确认的小段。这就是它们之间的区别。更多的可参考[9]。
SO_REUSEADDR
在服务器当即以后可以立即启动服务器,不会受TIME_WAIT状态的影响(会在bind时出错)。当然也允许多IP(多网卡)绑定同一个端口。可参考[11]。
SO_RECVBUF / SO_SNDBUF
套接字的发送接收缓冲区的值,设置以后内核会把此值加倍,可参考[12]。
TCP_QUICKACK
我们看看文档对其的解释:
Enable quickack mode if set or disable quickack mode if cleared. In quickack mode, acks are sent immediately, rather than delayed if needed in accordance to normal TCP operation. This flag is not permanent, it only enables a switch to or from quickack mode. Subsequent operation of the TCP protocol will once again enter/leave quickack mode depending on internal protocol processing and factors such as delayed ack timeouts occurring and data transfer. This option should not be used in code intended to be portable.
显然在我们知道后面不会传输数据的时候延迟确认是一个很影响交互响应时间的一件事情,可以设置以后禁用掉,这个选项是一次性的。
TCP_KEEPIDLE / TCP_KEEPINTVL / TCP_KEEPCNT
TCP保活机制的开始时间、间隔、次数参数。从TCP_KEEPIDLE时间开始,向对端发送一个探测信息,然后每过TCP_KEEPINTVL发送一次探测信息,共发送TCP_KEEPCNT次。
正如《TCP/IP详解》第十七章p793中所言,TCP包活机制本身是有争议的,反对因为它完全可以放在用户态去实现,而且并不难,高效时间轮甚至于一条链表就可以实现(libco的实现),而支持者认为如果需要应用程序需要这一功能我们就可以在TCP/IP中包含它。如此乱世下,导致了这个选项目前默认是关闭的。
SO_LINGER
TCP的优雅关闭和粗暴关闭,可参考[13]。
以上是RabbitServer中用到的部分,当然现在经验尚浅,就暂时写这些啦。
buffer必要性与设计
以前其实写过这个主题的文章,即[14],其中基本阐述清楚了为什么需要用户态buffer。当然这里还想要再提一提关于buffer的其他东西。
首先抛出一个问题,当接收的数据大于buffer的长度时怎么办?
[14]中阐明了一种方法,就是每个线程中分配一个大buffer(thread_local),接收数据的时候使用readv,然后在处理的时候直接使用,这样也有一个问题,就是如果这个包还是没收全,这些数据需要被缓存下来,此时还是需要把这些数据存到用户的类中,而不是那个thread_local的buffer中,这依然需要一次拷贝(当然可以交换指针)。这其实就是muduo的做法。
在RabbitServer中我没有使用这种方法,而是给每个用户分配两个buffer,一个在用户创建的时候被使用,一个在第一个buffer填满时再分配,当然这样其实和前面的做法差不多。
其次就是outputbuffer的设计其实需要动动脑子。
因为我们当然希望在静态请求时直接使用sendfile发送数据,而一个http响应报文中文件内容处于报文中间,后面还有一个\r\n,显然这个buffer就不能像前面一样组织成一个字节流了,我最终选择的方案是一个deque<function>,代码位于https://github.com/Super-long/RabbitServer/tree/master/src/tool中的writeloop.*中。
还有一点很有意思,就是环形buffer的使用显然是很有意义的,这样我们就可以减少数据的向前拷贝了。
当然日志库中的double buffer就不提了。
如此一算,一个服务端的程序中至少应该使用三种逻辑上不同的buffer,即:
inputbufferextrabuffer,作为inputbuffer的备用buffer。outputbuffer,至少需要支持sendfile。
网络编程模型的选择
这是一个非常有意思的话题,但是很多人都没有真正的思考过这个问题就急着写东西,那显然是事倍功半的。
首先我们来看看有哪些模型是广为人知的,即至少有一个常见的用处:
perfork模型:CGI程序,一定程度上来说是有好处的,比如并发。半同步半异步模型领导者追随者模型多进程模型
对了,再提一句Reactor和Proactor是事件处理模式,不是网络框架,很多人好像对它们之间的界限有些模糊。
在此主题做其他讨论之前首先抛出我的结论:多进程模型(搭配SO_REUSEPORT)最优,而且就事件处理来说绝不应该使用线程池(这里的意思是用线程池处理从recv到send,而不是异步处理一个大型的计算任务)。
为什么这么说,我们一个模型一个模型看,首先我们直接抛开perfork模型不谈,每个用户使用一个进程的模型放到2021年,实在是有一种穿着礼服喝着红酒吃炒面的违和感。
而半同步半异步模型可以说是比较广泛的一种模型,RabbitServer也采用了这种模型。
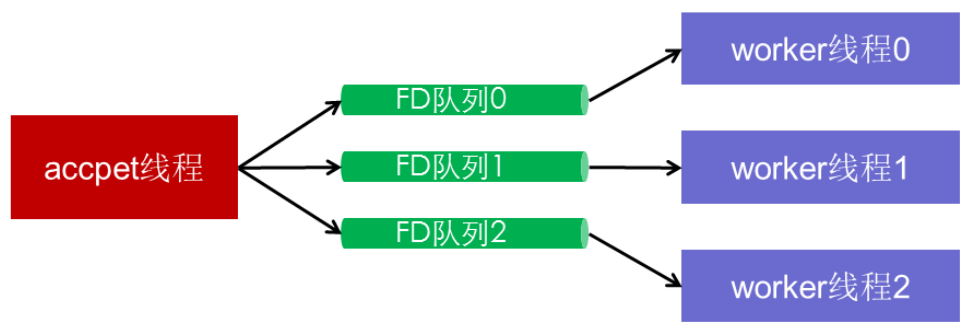
它的优点是显而易见的,每个worker线程持有一个epoll,所有的accept操作由accept线程来做,然后分发fd到worker线程,加入到每线程的epoll中。这种模型天然的避免了惊群效应,其次各个线程之间没有任何的条件竞争,锁的去除大大的增加了我们的效率。
当然问题的关键在于如何高效的分发fd,得益于与吕海东的头脑风暴,RabbitServer利用eventfd做到了完全无锁的向多消费者分发fd,有兴趣可以查阅源码,代码路径位于RabbitServer/src/server/channel.cc\channel.h。
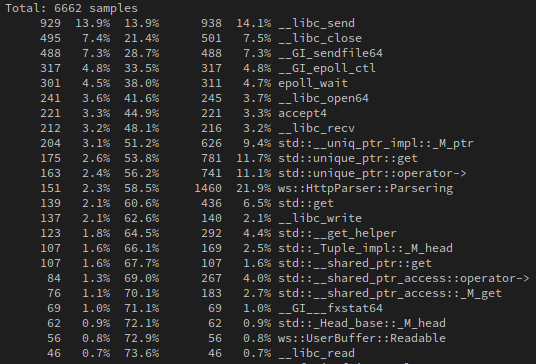
当然缺陷非常明显,即accept线程的单点问题,这是必然会发生的,这是RabbitServer在使用Apache bench跑一百线程一百万请求(短连接)时候的CPU负载情况:

显然单点问题非常严重。
改进的方法就是多进程(多线程)模型,同时搭配SO_REUSEPORT使用,这显然是目前最优的一种模型,无单点,无条件竞争,无惊群效应。
唯一一点问题可能就是负载均衡了,因为内核在设置SO_REUSEPORT以后,收包时不管查找到哪个socket,都能映射到他们所属的reuseport数组,再通过五元组哈希选择一个socket。此时可能某个线程非常繁忙,有大量的计算任务存在,但是还是会不停的分配任务。
而以上负载均衡在半同步半异步模型就不是问题,RabbitServer的做法是设置一个全局无锁队列,其中存放每个工作线程的吞吐量与长连接数,基于此做一个负载均衡,算法的选择上使用了Nginx中特殊的加权轮询负载均衡算法。
至于领导者追随者模型就不谈了,我个人并不看好这种模型,因为它虽说可以使得新领导者等待新的IO事件和原来的领导者处理IO事件两者并行(当然需要多CPU)处理,但是等到所有线程中都有任务需要处理时呢?对于此了解尚浅,还是不妄下定论了。
我们前面提到了就事件处理来说不需要线程池,现在明白了吗?(或者我理解有问题,请在评论区留言讨论)
至于事件分发模型Reactor和Proactor的讨论,我不想多言,因为我坚信未来随着io_uring的发展这个世界一定是Proactor的天下。虽然RabbitServer使用的是半Reactor半Proactor,因为工作线程直接拿到了fd。
前面聊到了惊群效应,虽然常用的半同步半异步模型摆脱了惊群问题的困扰,但我想每一个人都应该深刻的理解这个问题的来龙去脉,我不想在这篇文章中详谈惊群效应,但是我想留下几个问题,如果所有问题你都能够信手拈来,我想惊群问题你也算是理解了:
- Linux目前是否存在accept惊群?
- epoll为解决epoll_wait惊群做了哪些努力?
SO_REUSEPORT如何解决惊群?EPOLLEXCLUSIVE如何解决惊群?
异步框架的威力
这一节讨论的是worker线程上运行的代码。
每每考虑到这个问题,我就忍不住要吹一下libco的设计,站在当时微信的角度来看,libco简直是神一样的设计!
好了,回到正题,其实就我的理解来说,异步框架有两种方法:
- 原生的异步框架,RabbitServer就是这样设计的。
- 协程的异步化改造。
要说哪一种简单,那当然是后者,我想Golang如此火爆的原因之一就是其非常强大的网络服务编写能力,因为我们不再需要拘泥于异步框架繁琐的细节,只需要简单跑Goroutine就行了。
Go语言原生支持协程,这直接在编写服务端代码的时候颠覆了原有的编程思维,我们只需要简单的跑协程就可以,为什么?因为这简单的一步操作和异步框架的本质是一样的,都是在遇到会发生阻塞的代码的时候不至于切换线程而消耗资源,直接在本线程重新执行其他逻辑段,从这个角度来说可能协程还要更优秀一点。
举个例子,比如write出现写入不足的时候(发送缓冲区已满造成),此时异步框架的做法是直接退出,维护outputbuffer,等待此套接字可写时触发事件,此时写入,多执行一次write和epoll_wait(没有其他事件的情况下),显然一到两个系统调用的开销并不小,且还需要维护buffer。协程的做法呢?就是直接在write的时候就已经切换到其他协程(开销就是寄存器的切换和协程调度花费),等待事件已经就绪的时候再执行(就绪队列里直接取出来)。
显然后者的做法更加优雅,且向用户隐藏了繁琐的细节,开销也不一定更大(寄存器的切换和协程调度相比于少量系统调用与buffer的维护)。
再比如在服务器中的一次处理请求中,有一个巨大的计算任务,可能会消耗数秒,显然我们不应该直接在worker线程中进行处理,因为这会使得这一段时间内这个worker无法为其他连接服务,甚至在数秒内整个服务器的吞吐量为0!此时异步框架的做法可能是把这个大计算任务放到线程池中进行计算,计算结束以后通知worker线程,由worker线程向客户端返回数据,显然在这段时间内worker线程可以不停的处理任务,这样吞吐量就上去了,上限此时就是机器的算力了。
而协程的改造和第一个样例中一样,直接扔到协程中去跑就可以,这样就不会阻塞当前线程的执行流了。
这里有兴趣的朋友可以了解下libco[16]与Goroutinue的设计[17]。
包格式的设计
首先我们要抛出一句人人都知道的定义:
TCP 是一个面向连接的、可靠的流协议。
定义不愧称为定义,每一个字都是必不可少的。
面向连接和可靠暂且不提,本篇文章的重点是希望大家能把放在流这个字上,这个字意味着对于TCP协议来说,没有包这个概念。如此看来所谓的粘包问题就是一个笑话。
其实从数据通信的角度来讲,信道上传输数据一定是逐比特,或者一个信号代表多个比特,显然就不可能一个包一个包的传输。
当然从定义上讲有些协议则是以包为单位收发数据的,比如链路层,结点之间交换的就是数据块而不是比特流,所以网卡在接收到一个比特流的时候首先要识别这个比特序列的帧结构,一次判断帧从哪里开始,到哪里结束。显然可以看出本质还是流,不过是抽象成了包(帧)而已。
那么这些问题会如何影响我们的编程呢?
先提一个简单的问题:
如何保证服务器收到的包是完整的?
这个问题其实就是考你知不知道TCP是流式传输,因为它是流式的,所以基于一般的编程接口根本没办法知道这个包是否是完整的,此时我们要做的事情就是自己指定协议。其实也没什么,就是在用户态由我们自己判断包的边界,数据以特定的某种客户端和服务端协商好的格式排布。
举几个简单例子:
- 通过特殊标识符表示数据包的边界,例如\n\r,\t,或者一些隐藏字符。
- 利用包本身的格式解析(如XML、JSON等)。
- 在TCP报文的头部加上表示数据长度。
- 应用层发送数据时定长发送。
第一点没什么好说的,其实就是遇到这样的字符的时候包解析结束,或者说部分解析结束,当然这些个字符在正常的内容中显然不应该出现,这也是这种方法的一个缺点,当然这也决定了这种方法无法使用二进制编码。
第二点第四点就不提了。我们主要聊聊第三点,其实也可以理解为TLV(target length value)模式,这也是Protocol Buffer中使用的编码方式,基本的格式如下图所示:

当然中间的数字部分还是可以优化一点点,就是采用Varint进行编码,基本在大多数情况下可以减少几个字节,这其实也是Protocol Buffer对string的编码方式。可参考[21][1]。
当然TLV并不一定要仿照Protocol Buffer去做,我们完全可以基于此自己设计一个简单的协议,可以参考沈昭萌学长的博客[22]。这种方式其实也很好理解,因为第一次一定可以由tag位判断出是哪种类型,然后读取length位,这个过程中解析失败就知道没收齐,得知长度字段以后很容易判断包是否收齐。这种方法还可以让我们以二进制的形式传输数据,因为整个解析的过程中与特殊字符无关。
这里有一个隐晦的小知识点要知道,就是在某个结构体用于通信的时候,比如沈昭萌学长设定的那个结构体,一定要注意内存对齐,最好加上__attribute__((packed)),因为同一个结构体不同的机器上解释的方式是不一样的,当然字节序这种东西也要注意,具体可参考[23]:
x86、MOS Technology 6502、Z80、VAX、PDP-11等处理器为小端序;
Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除V9外)等处理器为大端序;
ARM、PowerPC(除PowerPC 970外)、DEC Alpha、SPARC V9、MIPS、PA-RISC及IA64的字节序是可配置的。
busy_loop问题
这个问题其实第一次见到是在muduo中,其实问题的名字看着高大上,其实就是说在连接数到达系统的上限时候(一个进程可以打开的文件的上限)如何处理新到来的连接(在proc/xxx/limits中可以查看,最大不能超过硬限制),因为我们没办法创建一个新的套接字,自然也没办法close,这个连接就一直积在全连接队列中。这个问题其实现在在网上除了muduo以外没见讨论过这个问题(是因为太简单了吗。),解决思路是有的,不过具体的实施方案还是看服务器的网络编程模型,这个大家可以思考一下为什么。
muduo解决的思路就是在服务器启动的时候就打开一个fd,在accept失败的时候释放这个fd,然后直接close,再打开那个fd,这样就优雅的关闭了这个连接。
其实代码也很好写,如下:
class fileopen : public Nocopy{
private:
std::mutex mutex_;
int File_Description;
constexpr const static char* prevent_busyloop = "/dev/null";
public:
fileopen() : File_Description(::open(prevent_busyloop, O_RDONLY | O_CREAT | O_EXCL)){
}
void Close(){
std::lock_guard<std::mutex> guard(mutex_); //It will be slow, but it must not ne wrong.
::close(File_Description);
}
void Open(){
std::lock_guard<std::mutex> guard(mutex_);
::open(prevent_busyloop,O_RDONLY);
}
};
class fileopen_helper{
private:
fileopen& File_;
public:
explicit fileopen_helper(fileopen& File) : File_(File){
File_.Close();
}
~fileopen_helper(){
File_.Open();
}
};
在accept的时候判断一下就可以了,Fileopen是一个类中的成员:
ret = ::accept4(fd(), nullptr, nullptr, SOCK_NONBLOCK);
if (ret == -1 && errno == EMFILE){
fileopen_helper prevent(FileOpen);
ret = ::accept4(fd(), nullptr, nullptr, SOCK_NONBLOCK);
::close(fd());
break;
}
当然还有一个方法,就是规定一个连接的上限,到达上限以后直接拒绝,当然这个上限i其实并不好指定,因为limits中规定的是files的上限,而且是进程的上限,多个线程可能会打开很多的文件,也占用了这个数字,所以仅仅依靠一个队列长度是没有安全性的保证的,因为我们没办法保证我们的进程一定可以接收这么多连接。
当然第一种方法还是没办法保证,可能刚把FileOpen中的文件描述符释放,其他线程就打开了一个文件,此时还是违反正确性的。
那有没有什么一定保证安全性且高效的做法呢(每次创造文件描述符都加锁就别说了)?我不知道。
不过大胆猜想如何才能保证安全,显然需要内核的支持,因为文件描述符的分配需要内核,而内核并不知道哪个文件描述符是特殊的,如果能在此方面做一点贡献那定是极好的。
对了,其实上面代码写的有问题。
日志系统
一个好的服务器显然离不开一套好的日志库。规范的日志也是服务端编程规范的一条,显然我们希望有一个高效的日志系统。
如果想自己撸一个的话muduo的日志库异步日志库就是很好的例子,基本每秒二百万条日志没什么问题(4 x Intel® Core i5-7200U CPU @ 2.50GHz)。
开源的也有很多:
- Blackhole - Attribute-based logging framework, which is designed to be fast, modular and highly customizable. [MIT]
- Boost.Log - Designed to be very modular and extensible. [Boost]
- Easylogging++ - Extremely light-weight high performance logging library for C++11 (or higher) applications. [MIT] website
- G3log - Asynchronous logger with Dynamic Sinks. [PublicDomain]
- glog - C++ implementation of the Google logging module.
- Log4cpp - A library of C++ classes for flexible logging to files, syslog, IDSA and other destinations. [LGPL]
- log4cplus - A simple to use C++ logging API providing thread-safe, flexible, and arbitrarily granular control over log
- management and configuration. [BSD & Apache2]
- loguru - A lightweight C++ logging library. [PublicDomain]
- plog - Portable and simple log for C++ in less than 1000 lines of code. [MPL2]
- reckless - Low-latency, high-throughput, asynchronous logging library for C++. [MIT]
- spdlog - Super fast, header only, C++ logging library.
- templog - A very small and lightweight C++ library which you can use to add logging to your C++ applications. [Boost]
- P7Baical - An open source and cross-platform library for high-speed sending telemetry & trace data with minimal usage of CPU and memory. [LGPL]
- Quill - Asynchronous cross platform low latency logging library. [MIT]
我当然没那么多闲时间这么多的开源软件,以后有此类需求直接来这里吧 awesome C++。
性能评估标准
这个没有一个大家都认同的标准来评估,所以完全是看个人的想法了,当然很多人(包括我在内),对于其实现的服务器评估的途径就是和Nginx和Apache去做比较,WebBench也好,ApacheBench也好,它们本质都是多线程去发一个空包,然后服务器返回一个回复。
说实话,我自己都想吐槽这个评判标准,但是没办法,大家都这样,面试官也认,那还能说什么呢。
难道你不觉得这样的评判标准一个多线程epoll,啥都不要那是最快的吗,所以这也就出现了很多网上的老哥一个线程池处理跑的和Nginx差不多还沾沾自喜,功能那么少,逻辑处理那么简单,能不快吗。算了,罢了,与我无关。
所以到底什么才是评判的标准呢?
参考CodeBox大神的想法,就是有效的榨干系统资源,两个词,代表却是世间万物啊。
有效代表查看Server运行时的CPU分配图(top以后摁1),us远小于sy和si。榨干代表重复上述动作,基本上id是一个很小的数字。
当然我个人还想补上一句,就是负载均衡,各种架构对于负载均衡的处理是不一样的,这个需要个人去摸索。
RabbitServer是半同步半异步模型,我对于负载均衡的处理方案是设置一个全局无锁队列,基于worker的吞吐量和长连接数在accept线程分发是做一个负债均衡。
Linux服务器程序规范
这个先放上游双书中的六条标准:
- Linux服务器程序一般以后台形式运行。后台程序又称守护进程。它没有控制终端,因而也不会意外接受用户输入。守护进程的父进程一般是init进程(pid=1)。
- Linux服务器程序通常有一套日志系统,它至少能输出日志到文件,有的高级服务器可以输出日志到专门的UDP服务器。大部分后台进程都在
/var/log下有自己的日志目录。 - Linux服务器程序一般以某个专门的非root身份运行。mysqld, httpd, syslogd等后台进程,并分别有自己的运行账户mysql, apache, syslog。‘
- Linux服务器通常时可配置的。服务器程序通常处理很多命令选项,如果一次运行的选项太多,则可以用配置文件来管理。绝大多数服务器程序都有配置文件并存放在
/etc下 - Linux服务器程序通常在启动时生成一个PID文件并存入
/var/run目录中,以记录该后台进程的PID。 - Linux服务器程序通常需要考虑系统资源和限制,以预测自身能承受多大负荷,比如进程可用文件描述符总数和内存总量等。
算了,不想写了,具体参考[24]。
最后聊聊
这行水很深,一个新东西写出来没有一个权威的大牛跑出来说这个没问题的话大家敢用吗?尤其是这个存在了这么多年的东西,远的不说,就说TX。我相信从QQ刚出来到现在TX的体量,光WebServer估计都换了N多个版本了,而且每次一定是有了某种需求,而不是说想换就换。
再说回来,欢神以前说过,目前网络编程领域近些年来在编程模型上都没有什么值得一说的新东西,更高要求的需求基本把目光转向了协议栈优化和bypass kernel,而不是WebServer。
什么意思,这个东西没啥油水可刮了,大家都玩透了,就是这样。我说的话没人信就算了,阿里云技术专家的话总该信吧。
那么我们就不学了吗?那必然不是,学的是原理,学的那么多东西又不是为了写WebServer,眼光放长远些,从内核到用户,从单机到多机,左可搞基础架构,右可转Golang,嗯,我们确实是个万能的螺丝钉,别丧气,少年仔。
分布式系统开发
好了,前面的东西其实我都不太懂,是瞎说的,这里是真的懂一点。
咳咳,开个小小的玩笑,我们正经一点接着聊。
已经到了文末,不想太过咬文嚼字,所以我们姑且先使用分布式系统开发这个词。
我在大概一个半月以前和19级Server组的同学有过一次对于此方向看法的深入讨论,我的看法就是我们这个方向的深入发展有两个选择,其中一个就是分布式开发。因为目前这个信息爆炸的时代,无论是数据存储还是计算,又或者是前两者需要的分布式通信,哪一个不是要承受海量的流量。
就说说我稍微熟悉一点的分布式存储,为了不同类型的数据类型,分布式缓存,分布式文件系统,又或者是被誉为NewSql的分布式数据库,哪一个不是需要投身一辈子的东西,东西是学不完的,而我们目前掌握的这些知识对于这些对性能有要求的场合又可以很好的派上用场,所以这确实是一个很好的深造方向。
对于这个话题再谈就是另一个事情了,况且目前能力也不足以做到说清楚来龙去脉,希望以后会有机会来补充这个话题吧。
总结
不知是不是太久没写文章的缘故,一写就停不下来,也许也是因为最近总是太压抑了吧,赶上快春招,而且感情也不顺利,还天天失眠,从一点能瞎想到三点。希望一切安好,不要猝死吧。
参考:
- 《浅谈服务端编程》
- 《从linux源码看socket的close》
- https://www.kernel.org/doc/Documentation/networking/ip-sysctl.txt
- 《RFC1122》
- https://linux.die.net/man/7/tcp
- 《提高 Linux 上 socket 性能》
- 《Linux TCP_DEFER_ACCEPT的作用》
- 《tcp半连接和全连接学习笔记》
- 《关于TCP_NODELAY 和 TCP_CORK选项》
- 《百度百科 Nagle算法》
- 《Socket中SO_REUSEADDR详解》
- https://man7.org/linux/man-pages/man7/socket.7.html
- 《SO_LINGER和优雅关闭连接以及短链接TIME_WAIT问题解决方法》
- 《网络套接字的读写问题与buffer的必要性》
- 《再聊聊Linux IO》
- 《libco源码解析(0) 概述与总结》
- 书籍《Golang源码剖析》
- 书籍《Linux 高性能服务端编程》
- 书籍《TCP/IP详解 卷一》
- 《使用 Protocol Buffers 代替 JSON 的五个原因》
- 《Protocol Buffer 序列化原理大揭秘 - 为什么Protocol Buffer性能这么好?》
- 《TLV-简单的数据传输协议》
- https://zh.wikipedia.org/wiki/%E5%AD%97%E8%8A%82%E5%BA%8F
- 《史上最全Linux服务器程序规范》