 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。
 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。
文章目录

其他文章
引言
千思万想的C++20它终于来了!其实早在今年七月二十三号的时候GCC最新的10.2.0版本已经发布了。9月4日C++20的国际标准草案投票已经结束,并且获得了全票通过!
因为C++的入门圣经《C++ Primer》是基于C++11的,所以导致很多C++玩家在提起某个C++11的特性时还停留在“C++11新特性”这个词汇上,多么具有魔幻现实主义色彩啊,恍惚间遥不可及的C++23都已经在向我们招手了。

对于C++20各种特性的编译支持可以参考[7]。
C++20是一个可以媲美C++11的核弹级更新,其中很多概念甚至可以影响未来基本的C++编程模式,其中颠覆性的特性有四个,分别为:
- range
- coroutinue
- module
- concepts
除去这些,其他的特性也很有意思,我们一起来看一看。
正文
range
range提供给我们一种函数式处理容器元素的方法,可以使得我们的代码简洁不少。以往此类代码的一般方法是在算法库函数上指定一个迭代器范围,搭配Lambda使用,但是在遇到transform这样的需求时我们不得不手动拷贝一个容器,在其之上做一些其他改动,range的引入使得我们可以非常简答的随意组合(用逻辑运算符就可以),并直接在容器上操作,其实可以看做一个简化版的MapReduce。
void cpp_11() {
std::vector<int> v{
1, 2, 3, 4, 5};
std::vector<int> even;
std::copy_if(v.begin(), v.end(), std::back_inserter(even),
[](int i) {
return i % 2 == 0; });
std::vector<int> results;
std::transform(even.begin(), even.end(),
std::back_inserter(results),
[](int i) {
return i * 2; });
for (int n : results) std::cout << n << ' ';
putchar('\n');
}
void cpp_20() {
std::vector<int> v{
1, 2, 3, 4, 5};
for(int i : v | ranges::views::filter([](int i) {
return i % 2 == 0; })
| ranges::views::transform([](int i) {
return i * 2; })){
cout << i << " ";
}
putchar('\n');
}
两个代码实现的是同一个功能,但是显然后者要优雅的多。
coroutine
千呼万唤始出来!并不是库特性,而是语言功能特性,其引入了几个全新的关键字用来支持协程,但是说实话,C++20的协程在我看来给人的感觉是它还并不完整,适合于库编写者而不是一般的用户,因为它的上手复杂度确实比较高,可以用“难用”来形容。
在我自己实现的协程库RocketCo中为了与C++20的协程进行性能测试我参考网上的文章简单实现了C++20协程的性能测试代码,现在还记得那天的感觉,生不如死。有兴趣的朋友可以看看当时的测试代码 传送门。
就连官网的测试代码想看懂也得花点时间,我们加上了一些标准输出试着让其更好理解一点,我们一起看一看:
auto switch_to_new_thread(std::jthread& out) {
//关键字 co_await 是一个操作符,所以我们只要实现这个操作符重载就可以实现协程等待任意类型。
struct awaitable {
std::jthread* p_out;
bool await_ready() {
std::cout << "ready\n";
sleep(1);
return false;
}
// 返回值为void。将控制立即返回给当前协程的调用方
// 因为协程在进入,await_suspend() 前已完全暂停,所以该函数可以自由地在线程间转移协程柄,而无需额外同步,其他持有句柄的线程可以调用resume
// 转移句柄是非常有必要的,不调用resume无法返还控制权给调用方,这是裸协程,而不是用户态线程。
void await_suspend(std::coroutine_handle<> h) {
std::cout << "suspend\n";
std::jthread& out = *p_out;
if (out.joinable())
throw std::runtime_error("Output jthread parameter not empty");
out = std::jthread([h] {
sleep(2);
h.resume();
});
// Potential undefined behavior: accessing potentially destroyed *this
// std::cout << "New thread ID: " << p_out->get_id() << '\n';
std::cout << "New thread ID: " << out.get_id() << '\n'; // this is OK
}
void await_resume() {
std::cout << "resume\n";
}
};
return awaitable{
&out};
}
// 要支持协程函数,首先要准备一个包装的类型,里面包含 promise_type ,然后提供基本的创建、维护handle的函数
struct task{
struct promise_type {
task get_return_object() {
return {
}; }
std::suspend_never initial_suspend() {
return {
}; }
std::suspend_never final_suspend() noexcept {
return {
}; }
void return_void() {
}
void unhandled_exception() {
}
};
};
task resuming_on_new_thread(std::jthread& out) {
std::cout << "Coroutine started on thread: " << std::this_thread::get_id() << '\n';
co_await switch_to_new_thread(out);
// awaiter destroyed here
std::cout << "Coroutine resumed on thread: " << std::this_thread::get_id() << '\n';
}
int main() {
std::jthread out;
resuming_on_new_thread(out);
}
输出为:
Coroutine started on thread: 139875008661312
ready
睡眠1s
suspend
New thread ID: 139875008656960
睡眠2s
resume
Coroutine resumed on thread: 139875008656960
基本的流程先把执行权转移到协程switch_to_new_thread,执行await_ready根据返回值调用await_suspends(false)或者await_resume(true),await_suspend中转移协程句柄到另一个线程, 另一个线程可以视情况执行resume切换执行权,这也可以看出C++20的协程是一个典型的对称协程,允许在线程之间转移执行权,而且在一些资料中可以看到其实现是无栈协程,这样的话理论来说效率也会高一些,此方面知识可以参考[10]。
我们可以看到从上面代码中看到需要我们自己转移协程执行权,并且什么时候切回来也需要自己判断,所以我觉得后面可以会有一些基于C++20协程接口的协程库,那样会使得使用方便的多,就现在来看libgo依然是个不错的选择。就我的性能测试结果来看libgo在切换时优于coroutinue,而创建逊色于coroutinue。
module
module的引入至少有如下几个优点[11]:
- 更快的编译时间
- 宏的隔离
- 可以将大量代码划分为逻辑部分
- 让头文件成为“过去式”
- 摆脱丑陋的宏环境
C++分离编译带来的一个问题就是编译会非常慢,因为C++ 的编译器在处理一个源代码文件的时候,首先要做的就是用相应的头文件的内容替换 #include 预编译指令。这就存在一个问题,对每一个源代码文件编译器都要重复一遍内容替换,这会占用大量的处理器时间。而引入module以后就不存在这个问题了,只需要import一下就可以在所有的源代码文件中使用,没有头文件的替换动作,使得编译时间可以大大减小。
可以看出以后C++使用module提供标准库应该会成为一个趋势,当然如何兼容已有的这些庞大的标准库也是一个问题。

目前GCC11才支持module,我的机器是GCC10.2,跑不了module的代码,那就来看看官网上的样例吧:
// helloworld.cpp
export module helloworld; // module declaration
import <iostream>; // import declaration
export void hello() {
// export declaration
std::cout << "Hello world!\n";
}
// main.cpp
import helloworld; // import declaration
int main() {
hello();
}
Constraints and concepts
官网中对其的解释如下:
- Class templates, function templates, and non-template functions (typically members of class templates) may be associated with a constraint, which specifies the requirements on template arguments, which can be used to select the most appropriate function overloads and template specializations.
Named sets of such requirements are called concepts. Each concept is a predicate, evaluated at compile time, and becomes a part of the interface of a template where it is used as a constraint:- 类模板,函数模板和非模板函数(通常是类模板的成员)可以与constraint关联,该constraint指定对模板参数的要求,该constraint可用于选择最合适的函数重载和模板特化。
这种要求的命名集称为concept。 每个概念都是一个谓词,在编译时进行评估,并成为模板接口的一部分,并在其中用作约束条件:
对于我们这些普通开发者来说,其最大的作用就是可以在模板参数类型出现问题的时候不会一次报出几千行错误。我们可以使用concept来限制模板参数的类型。如果某处实例化的类型与concept相悖的话就会报错。当然含有concept的模板声明更像是一个特殊的实例化,如下列代码,如果把不含concept的模板注释掉的话就会报错了,因为meow不满足Hashable的约束
#include <string>
#include <cstddef>
#include <concepts>
#include <iostream>
// Declaration of the concept "Hashable", which is satisfied by any type 'T'
// such that for values 'a' of type 'T', the expression std::hash<T>{}(a)
// compiles and its result is convertible to std::size_t
template<typename T>
concept Hashable = requires(T a) {
{
std::hash<T>{
}(a) } -> std::convertible_to<std::size_t>;
};
struct meow {
};
// Constrained C++20 function template:
template<Hashable T>
void f(T) {
std::cout << "hello" << std::endl;
}
template<class T>
void f(T) {
std::cout << "world" << std::endl;
}
int main() {
using std::operator""s;
f("abc"s);
f(meow{
});
}
官网对Constraints的描述如下:
- A constraint is a sequence of logical operations and operands that specifies requirements on template arguments. They can appear within requires-expressions (see below) and directly as bodies of concepts.
- constraint是一系列逻辑运算和操作数,用于指定对模板参数的要求。 它们可以出现在require表达式中,并且可以直接作为concepts主体出现。
Constraints在我的理解其实就是指定concept的规则,具体的样例可以参考[13][14]。
span
这个玩意儿与其叫span不如叫array_ref或者array_view,它的作用其实就是引用一个对象的连续序列,[9]中对它的描述非常详细,给出了哪些情况建议使用与不建议使用:
- Don’t use it in code that could just take any pair of start & end iterators, like std::sort, std::find_if, std::copy and all of those super-generic templated functions.
- Don’t use it if you have a standard library container (or a Boost container etc.) which you know is the right fit for your code. It’s not intended to supplant any of them.
- 不要在可能需要任何一对开始和结束迭代器的代码中使用它,例如std :: sort,std :: find_if,std :: copy和所有这些超通用模板化函数。
- 如果您有一个标准库容器(或Boost容器等),并且知道该容器适合您的代码,请不要使用它。 并不是要取代它们中的任何一个。
我想我们可以在需要对某个容器的某个区间进行操作的时候使用span,当然这个区间不是begin和end,而是中间的某个区间;或者要把容器的部分传递给某个函数,以前我们可能只能拷贝,现在我们可以选择更加轻量级的span。
#include <algorithm>
#include <cstddef>
#include <iostream>
#include <span>
template<class T, std::size_t N> [[nodiscard]]
constexpr auto slide(std::span<T,N> s, std::size_t offset, std::size_t width) {
return s.subspan(offset, offset + width <= s.size() ? width : 0U);
}
void print(const auto& seq) {
for (const auto& elem : seq) std::cout << elem << ' ';
std::cout << '\n';
}
int main()
{
constexpr int a[] {
0, 1, 2, 3, 4, 5, 6, 7, 8 };
constexpr int b[] {
8, 7, 6 };
for (std::size_t offset{
}; ; ++offset) {
constexpr std::size_t width{
6};
auto s = slide(std::span{
a}, offset, width);
if (s.empty())
break;
print(s);
}
}
output:
0 1 2 3 4 5
1 2 3 4 5 6
2 3 4 5 6 7
3 4 5 6 7 8
#include <algorithm>
#include <cstdio>
#include <numeric>
#include <ranges>
#include <span>
void display(std::span<const char> abc)
{
const auto columns{
20U };
const auto rows{
abc.size() - columns + 1 };
for (auto offset{
0U }; offset < rows; ++offset) {
std::ranges::for_each(
abc.subspan(offset, columns),
std::putchar
);
std::putchar('\n');
}
}
int main()
{
char abc[26];
std::iota(std::begin(abc), std::end(abc), 'A');
display(abc);
}
output:
ABCDEFGHIJKLMNOPQRST
BCDEFGHIJKLMNOPQRSTU
CDEFGHIJKLMNOPQRSTUV
DEFGHIJKLMNOPQRSTUVW
EFGHIJKLMNOPQRSTUVWX
FGHIJKLMNOPQRSTUVWXY
GHIJKLMNOPQRSTUVWXYZ
jthread
第一次接触这个东西是在看官网的协程测试代码的时候,也就是上面介绍协程的那段代码。其与std::thread仅有两点不同:
- automatically rejoins on destruction
- can be cancelled/stopped in certain situations.
也就是可以在析构时自动join,且允许加入中断点已实现在线程执行时合法终止线程。
在std::thread的析构函数中,std::terminate会被调用如果:
- 线程没有被Joined(用t.join())
- 线程也没有被detached(用t.detach())
既然只多了这两个功能,为什么要重新搞一个类呢?因为 std::jthread 为了实现上述新功能,带来了额外的性能开销 (主要是多了一个成员变量)。而根据 C++ 一直以来 “不为不使用的功能付费” 的设计哲学,他们自然就把这些新功能拆出来新做了一个类[15]。
#include <thread>
#include <iostream>
using namespace std::literals::chrono_literals;
void f(std::stop_token stop_token, int value)
{
while (!stop_token.stop_requested()) {
std::cout << value++ << " -> jthread" << std::endl;
std::this_thread::sleep_for(200ms);
}
std::cout << std::endl;
}
void ff(int value){
while (true) {
std::cout << value++ << " -> thread"<< std::endl;
std::this_thread::sleep_for(200ms);
}
}
int main(){
std::jthread thread1(f, 5); // prints 5 6 7 8... for approximately 3 seconds
std::thread thread2(ff, 5);
std::this_thread::sleep_for(3s);
// jthread析构时调用request_stop()和join().
}
g++ jthread.cpp -std=c++20 -pthread
如果去掉创建thread那一句的话就不会出现std::terminate了。
attribute[likely, unlikely,no_unique_address]
很有意思的三个attribute, 前两个与分支预测有关,后一个与空类优化有关。
其实在[16]中我曾经简单写过分支预测相关的东西,其中gnu的内置属性__builtin_expect与likely作用类似,llikely的出现使其从编译器特性提升到语言特性,使得跨平台的代码更加好写。
no_unique_address也很有意思。C++中希望每一个类都拥有自己独一无二的标识符,意味着其必须在运行时拥有一块内存中的地址,哪怕只有1个字节,空类在被创建确实也是这样的。no_unique_address可以使得某个类中的空类成员和其他成员共享地址,从而减少一个字节的内存使用。当然一个空类成员只能和一个成员共享。
#include <iostream>
struct Empty {
}; // 空类
struct X {
int i;
Empty e;
};
struct Y {
int i;
[[no_unique_address]] Empty e;
};
struct Z {
char c;
[[no_unique_address]] Empty e1, e2;
};
struct W {
char c[2];
[[no_unique_address]] Empty e1, e2;
};
int main()
{
// 任何空类类型对象的大小至少为 1
static_assert(sizeof(Empty) >= 1);
// 至少需要多一个字节以给 e 唯一地址
static_assert(sizeof(X) >= sizeof(int) + 1);
// 优化掉空成员
std::cout << "sizeof(Y) == sizeof(int) is " << std::boolalpha
<< (sizeof(Y) == sizeof(int)) << '\n';
// e1 与 e2 不能共享同一地址,因为它们拥有相同类型,尽管它们标记有 [[no_unique_address]]。
// 然而,其中一者可以与 c 共享地址。
static_assert(sizeof(Z) >= 2);
// e1 与 e2 不能拥有同一地址,但它们之一能与 c[0] 共享,而另一者与 c[1] 共享
std::cout << "sizeof(W) == 2 is " << (sizeof(W) == 2) << '\n';
}
其实看起来no_unique_address很像适配范围更广的空基类优化,可以参考[17]。
barrier ,latch,semaphore
countlatch与semaphore,基础的东西,没什么说的。barrier相比于latch就是多了复用的功能,
这两个工具(barrier /latch看做一个)在GCC11被支持,而在 gcc.gnu.org 我们可以看到GCC11还在测试中。


<=> 飞船运算符
飞船运算符的学名叫做Three-way comparison,其比较规则如下:
- (a <=> b) < 0 if lhs < rhs
- (a <=> b) > 0 if lhs > rhs
- (a <=> b) == 0 if lhs and rhs are equal/equivalent.
它的作用我猜测是增加标准库代码的简洁性,依据来自:
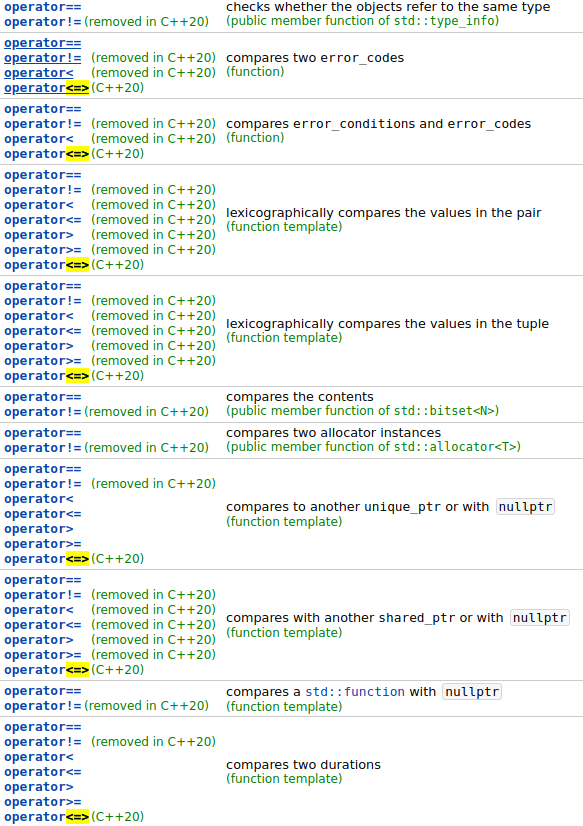
有了<=>,库的编写可以减少很多代码,以前曾看过std::string的源码,运算符重载部分可以说非常的丑陋,通篇的代码全都一样,因为一般来说函数体就一句话,模板部分却要一大段。
formatting library
终于不需要忍受IO流格式化的煎熬了,犹记得当时写日志库的时候格式化输出有多折磨人,写的难看不说,多次operator函数操作也是有开销的。
- The text formatting library offers a safe and extensible alternative to the printf family of functions. It is intended to complement the existing C++ I/O streams library and reuse some of its infrastructure such as overloaded insertion operators for user-defined types.
- 文本格式库提供了printf系列功能的安全且可扩展的替代方案。 它旨在补充现有的C ++ I / O流库,并重用其某些基础结构,例如用于用户定义类型的重载插入运算符。
来看看具体是怎么样的:
std::cout << std::format("Hello {}!\n", "world");
std::cout << std::format("{} {}!\n", "Hello", "world", "something");
std::cout << std::format("The answer is {}.", 42);
不幸的是GCC目前没有实现这个库。

这幅图让我想起来一句以前朋友间的调侃,WA声一片哈哈哈。
consteval
C++20引入的新关键字。
- specifies that a function is an immediate function, that is, every call to the function must produce a compile-time constant
- 指定函数是立即函数(immediate function),即每次调用该函数必须产生编译时常量
从字面上看是比constexpr更强的约束,constexpr[18]在传入参数不是字面量的时候退化为普通函数。官网中这样描述:
- every potentially evaluated call (i.e. call out of an unevaluated context) to the function must (directly or indirectly) produce a compile time constant expression.
- 对函数的每个可能评估的调用(从未评估的上下文中调用)都必须(直接或间接)产生一个编译时间常数表达式。
这个特性GCC11才会支持完全,到时可以仔细探究一下。但是官网仍给出了部分测试代码:
consteval int sqr(int n) {
return n*n;
}
constexpr int r = sqr(100); // OK
int x = 100;
int r2 = sqr(x); // 错误:调用不产生常量
consteval int sqrsqr(int n) {
return sqr(sqr(n)); // 在此点非常量表达式,但是 OK
}
constexpr int dblsqr(int n) {
return 2*sqr(n); // 错误:外围函数并非 consteval 且 sqr(n) 不是常量
}
Designated Initializers
列表初始化的一种特殊用法,也支持指派初始化,不过有一些约束。
每个指派符必须指名目标结构体的一个直接非静态数据成员,而表达式中所用的所有指派符必须按照与结构体的数据成员相同的顺序出现。
struct A {
int x; int y; int z; };
A a{
.y = 2, .x = 1}; // 错误:指派符的顺序不匹配声明顺序
A b{
.x = 1, .z = 2}; // OK:b.y 初始化为 0
to_array
#include <type_traits>
#include <utility>
#include <array>
#include <memory>
int main()
{
// 复制字符串字面量
auto a1 = std::to_array("foo");
static_assert(a1.size() == 4);
// 推导元素类型和长度
auto a2 = std::to_array({
0, 2, 1, 3 });
static_assert(std::is_same_v<decltype(a2), std::array<int, 4>>);
// 推导长度而元素类型指定
// 发生隐式转换
auto a3 = std::to_array<long>({
0, 1, 3 });
static_assert(std::is_same_v<decltype(a3), std::array<long, 3>>);
auto a4 = std::to_array<std::pair<int, float>>(
{
{
3, .0f }, {
4, .1f }, {
4, .1e23f } });
static_assert(a4.size() == 3);
// 创建不可复制的 std::array
auto a5 = std::to_array({
std::make_unique<int>(3) });
static_assert(a5.size() == 1);
// 错误:不支持复制多维数组
// char s[2][6] = { "nice", "thing" };
// auto a6 = std::to_array(s);
}
这段代码让人想到一件事,即类型推导。我认为std::to_array的诞生很大一部分方便了auto的推导,以往直接用列表推导的话根据auto的推导规则会把所有带花括号的都匹配为initializer_list,甚至可以推导出前者模板的类型[19]条款2。现在可以很方便的推导出我们需要的类型。算是语法糖吧.
virtual constexpr function
看起来就很强大的特性,学过C++对象模型的都知道虚函数的匹配是根据index动态绑定的,该如何做到constexpr呢?
在[7]中可以看到这个特性已经i被支持,但是找了半天也没找到文档。

来写个代码看看就知道了:
#include <bits/stdc++.h>
using namespace std;
struct Memory {
virtual constexpr unsigned int capacity() const = 0;
};
struct SonMemory : Memory {
constexpr unsigned int capacity() const override {
return 2048;
}
};
int main(){
constexpr SonMemory para;
cout << para.capacity() << endl;
}
编译成功。得出结论,这个特性确实已经被支持了,但是官方没更新文档。
[20]写的不错。
总结
反射最终还是没有被引入,就官网目前资料来看,C++23也没有要引入的消息。网络库也是一个道理,前一阵asio转正的消息闹得沸沸扬扬,最终还是一场空。不过才2021年,慢慢走,慢慢看。
生命不息,学习不止,东西实在是太多了。天行健,君子以自强不息,希望能够一直坚持学习下去吧。
参考:
- 文档《cppreference.com》
- 博客《实战探究!C++ 20 标准都发布了哪些重要特性?》
- 博客《解读C++即将迎来的重大更新(一):C++20的四大新特性》
- 维基《C++20》
- 博客《对现代C++的一点看法》
- 博客《C++20 要来了!》
- 文档《C++ compiler support》
- 博客《back_inserter & front_inserter & inserter的用法》
- StackOverflow《What is a “span” and when should I use one?》
- 博客《有栈协程与无栈协程》
- 博客《C++20,说说 Module 那点事儿》
- 博客《concept for C++20用法简介》
- 文档《Constrains and concepts》
- 文档《Concepts library》
- 博客《C++ std::thread 和 std::jthread 使用详解 (含C++20新特性)》
- 博客《条件判断语句与分支预测》
- 文档《Empty base optimization》
- 文档《constexpr》
- 书籍《Effective Modern C++》
- 博客《Let’s try C++20 | virtual constexpr functions》