一张别人家的插图
如何绘制
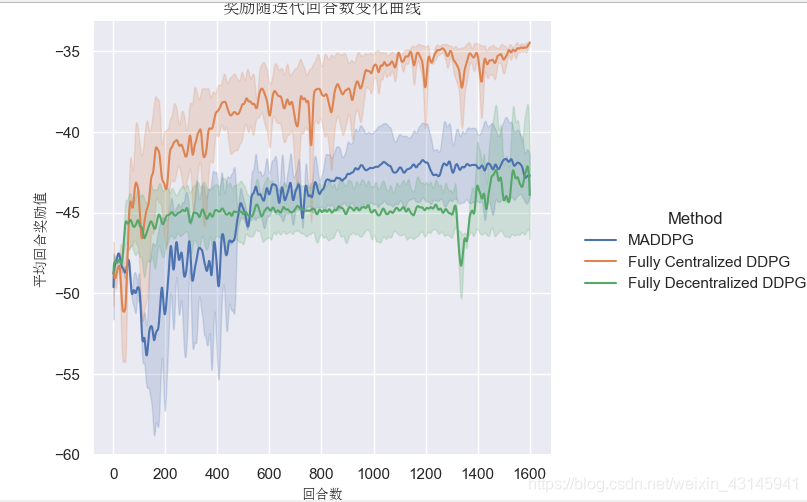
relplot可以自动绘制置信区间,因此我们要做的就是把多次试验结果保存下来,保证一个横坐标上有多个纵坐标,它便能自动绘制置信区间。假设我跑了个DDPG的模型,拿到了一个reward_list=[0,1,2,4,4,…],第二次拿到了一个reward_list=[2,3,4,4…],又跑了个SAC模型,拿到了一个reward_list=[0,1,2,4,5,…],第二次拿到了一个reward_list=[2,3,4,6…],用模型名称、迭代次数(索引)、reward值作为pandas dataframe的列名创建一个dataframe,这里为了方便我写了个Painter类:
#!/usr/bin/python
# -*- coding: utf-8 -*-
# Time: 2021-3-19
# Author: ZYunfei
# File func: draw func
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
from matplotlib.font_manager import FontProperties
myfont=FontProperties(fname=r'C:\Windows\Fonts\simsun.ttc')
sns.set(font=myfont.get_name())
class Painter:
def __init__(self, load_csv, load_dir):
if not load_csv:
self.data = pd.DataFrame(columns=['episode reward','episode', 'Method'])
else:
self.load_dir = load_dir
self.data = pd.read_csv(self.load_dir).iloc[:,1:] # csv文件第一列是index,不用取。
def addData(self, dataSeries, method, smooth = True):
if smooth:
dataSeries = self.smooth(dataSeries)
size = len(dataSeries)
for i in range(size):
dataToAppend = {
'episode reward':dataSeries[i],'episode':i+1,'Method':method}
self.data = self.data.append(dataToAppend,ignore_index = True)
def drawFigure(self):
sns.set_theme(style="darkgrid")
sns.set_style(rc={
"linewidth": 1})
sns.relplot(data = self.data, kind = "line", x = "episode", y = "episode reward",
hue= "Method")
plt.title(u'奖励随迭代回合数变化曲线',fontproperties = myfont,fontsize = 12)
plt.xlabel(u"回合数",fontproperties = myfont)
plt.ylabel(u"平均回合奖励值",fontproperties = myfont)
plt.show()
def saveData(self, save_dir):
self.data.to_csv(save_dir)
def addCsv(self, add_load_dir):
"""将另一个csv文件合并到load_dir的csv文件里。"""
add_csv = pd.read_csv(add_load_dir).iloc[:,1:]
self.data = pd.concat([self.data, add_csv],axis=0,ignore_index=True)
def deleteData(self,delete_data_name):
"""删除某个method的数据,删除之后需要手动保存,不会自动保存。"""
self.data = self.data[~self.data['Method'].isin([delete_data_name])]
def smoothData(self, smooth_method_name,N):
"""对某个方法下的reward进行MA滤波,N为MA滤波阶数。"""
begin_index = -1
mode = -1 # mode为-1表示还没搜索到初始索引, mode为1表示正在搜索末尾索引。
for i in range(len(self.data)):
if self.data.iloc[i]['Method'] == smooth_method_name and mode == -1:
begin_index = i
mode = 1
continue
if mode == 1 and self.data.iloc[i]['episode'] == 1:
self.data.iloc[begin_index:i,0] = self.smooth(
self.data.iloc[begin_index:i,0],N = N
)
begin_index = -1
mode = -1
if self.data.iloc[i]['Method'] == smooth_method_name:
begin_index = i
mode = 1
if mode == 1 and i == len(self.data) - 1:
self.data.iloc[begin_index:,0]= self.smooth(
self.data.iloc[begin_index:,0], N=N
)
@staticmethod
def smooth(data,N=7):
n = (N - 1) // 2
res = np.zeros(len(data))
for i in range(len(data)):
if i <= n - 1:
res[i] = sum(data[0:2 * i+1]) / (2 * i + 1)
elif i < len(data) - n:
res[i] = sum(data[i - n:i + n +1]) / (2 * n + 1)
else:
temp = len(data) - i
res[i] = sum(data[-temp * 2 + 1:]) / (2 * temp - 1)
return res
if __name__ == "__main__":
painter = Painter(load_csv=True,load_dir='F:/MasterDegree/PytorchLearning/test.csv')
painter.smoothData('Fully Decentralized DDPG',33)
painter.drawFigure()
API介绍:
- 初始化:load_csv表示是否加载已有的csv文件,如果为True,在load_dir中写上文件路径,painter会自动在文件基础上进行后续操作。
- painter.addData: 将一个reward数组添加进csv文件,按顺序作为episode=1,2,…。method为这个数据对应的模型(例如DDPG)。
- painter.drawFigure: 对当前读入的csv文件进行绘图,无参数。
- painter.addCsv:将一个csv文件加在当前csv文件末端。(这个不常用)
- painter.deletaData:删除某一个模型名称对应的所有数据。参数为模型名称(例如:‘DDPG’)
- painter.smoothData:对当前csv文件中某个模型对应的数据进行MA滤波,第一个参数为模型名称(例如:‘DDPG’),第二个参数为MA滤波的阶数(奇数,例如7)。
- painter.smooth:一个静态方法,MA滤波。
调用例子:
if __name__ == "__main__":
painter = Painter(load_csv=True,load_dir='F:/MasterDegree/PytorchLearning/test.csv')
painter.smoothData('Fully Decentralized DDPG',11)
painter.smoothData('Fully Centralized DDPG', 11)
painter.smoothData('MADDPG', 11)
painter.drawFigure()
数据越多绘制效果越好,但是相应的需要计算很久置信区间(几分钟的绘图时间),耐心等待即可。