最近看了清华大学刘知远老师团队在2017年顶会ACL上发表的最新成果《Improved Word Representation Learning with Sememes》。之所以题目叫做knowledge-based的方法来提升词向量的生成质量,是因为在这篇论文中利用了Hownet词典所关于现实世界中所有实体之间的关系信息,下面首先来介绍一下Hownet词典。
Hownet
在《Hownet》有三个主要的概念,即sememe(义元),sense(词义)和word(词语)。三者的关系可以从下图的例子看出
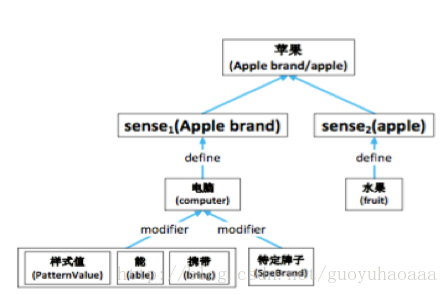
word(苹果)包含了两个sense,sense1是水果,sense2是电脑。对于每一个sense来说是由sememe来描述其属性,这些属性通过比价复杂的层级结构来对目标sense进行说明。在这篇paper中,为了简化,省去了这些复杂的层级结构,将每个sense对应的sememe看成是一个集合。从中我们可以知道,在hownet的描述体系中,sememe是最小的描述单元,相似的sense会包含相同的sememe,这些sememe就相当于是整个世界所有事物最基本的单元(个人感觉和中学化学中学到的元素有些类似,世界上所有的事物都由元素组成)。而且sememe的数量相对词语的数量来说是非常有限的,在hownet中大概就是几百个。
既然引入了sememe的概念,下一步就要把这些信息引入到词向量的生成过程中去,而所谓的knowledge-based方法指的就是sememe和其对应的sense之间的描述关系。需要注意的是,作者是根据word2vec的skip-gram架构进行改造的,下面就先来简要的介绍一下skip-gram语言模型的原理,该模型的整体需要优化的函数如下所示:
其中K代表了滑动窗口的大小,它定义了target词语所对应的上下文的范围,也就是说它的整体目标是利用当前词语target,来最大化的预测其上下文的信息,skip-gram对于上下文的信息做了简化处理,即从K大小的窗口内随机抽取一个词语来作为其上下文的替代,故上面的最优化式子简化如下:
在介绍完了传统的skip-gram框架之后,就开始介绍这篇paper提出的框架。
这篇paper一共提出了三种融入了sememe的框架结构,需要注意的是在任意一种框架之中都会有word embedding 和sememe embedding两种向量,两种向量都会随着模型的训练进行微调,最后有用的只是word embedding,而sememe embedding只是在训练过程中起到了辅助的作用:
1 Simple Sememe Aggregation Model (SSA)
从名字上可以看出,这种模型比较简单。在传统的skip-gram模型基础之上,对target word部分进行改造,使用target word 由对应的所有sense包含的所有的sememe embedding相加求均值得到,target word w的sememe生成方式如下:
其中
和传统的skip-gram相比,这种方式里sememe向量会被一些词语共享,模型可以利用sememe之间的共享信息来表征词语之间的某些语义关联关系。在这种模式之下,拥有相同sememe的词语最终会有比较相似的向量表征形式。
2 Sememe Attention over Context Model (SAC)
从名字可以看出,在这部分应用了attention机制,而且是在context内容上进行应用的。因为在上面的SSA模型中,target word直接由对应的所有sense包含的所有的sememe embedding相加求均值得到,就没有考虑到这个词语所对应的sense之间重要关系。因为对于一个词语的表征,在不同的语境中其对应的sense集合中的元素之间的重要性也是不同的,这里很好的应用了attentin机制来对于重要性进行标识,模型如下所示:
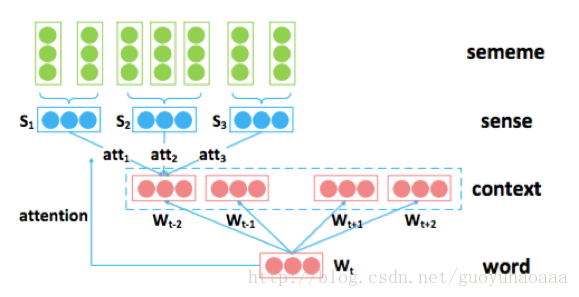
从图中可以看出,一个词语的sense向量是由其对应的sememe向量直接相加求均值得到。然后三个不同的sense向量s1,s2,s3通过attention机制相加得到最终context的word 级别的embedding形式,具体三种权值的大小的选取由这三种sense向量和target 向量的相似程度得到,计算公式如下:
其中,
3 Sememe Attention over Target Model (SAT)
从名字可以看出,这部分同样应用了attention机制,而且是在target上应用的。和SAC不同的是,这里是应用context去对target word的sememe 形式的生成进行挑选,模型如下:
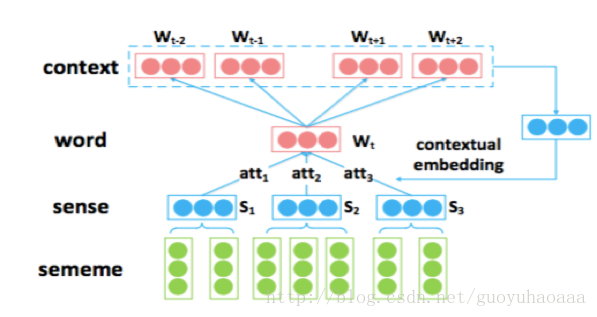
从图中可以看出,SAT和SAC模型正好是互相对称的,但是需要注意的是,这里作者在应用context信息的时候,不是从上下文随机挑选了一个词,而是应用了一定窗口内的词,这样的context可以更好的去生成target word 的向量表征形式,公式如下:
其中,
其中i是当前target 词语的位置
上面就是提出的所有模型,经过试验的反复验证,确实引入了hownet信息的词向量质量相对于传统的方法来说更好一些,特别是对于词频比较低的词语,因为它们会和一些词频高的词语共享一部分sememe,故模型对于低频词来说会有比较好的适应性。
(ps:刘老师团队的人都非常nice,中间因为论文的内容和他的团队有过多次的邮件交流,刘老师总是耐心的解答,感觉真是获益良多。)