在网络基础------TCP/IP五层模型一文中笼统的介绍了有关TCP/IP五层模型的相关知识点,本文中将详细的说明TCP/IP五层网络模型中的应用层,及相关的应用层协议。
应用层概述
应用层的任务是通过应用程序间的交互来完成特定的网络应用。根据网络应用的不同,应用程序之间就需要根据不同的方式来实现交互。如:如果两个应用程序之间要传递整型数据,那么二者之间必须遵循这样的方式:二者之间必须以整型来接收和发送数据。我们把这样的方式也可以成为双方约定好的“协议”。
我们可以将上述的网络应用理解为一个个实际需要解决的问题。由于需要解决的实际问题不同,应用程序与应用程序之间就需要制定不同的协议。这些为解决某一类应用问题所制定的协议称为应用层协议。而问题的解决是通过不同主机上的多个应用进程之间的交互来实现的,因此,应用层协议定义为应用进程间通信和交互的规则。
下面我们自己来指定一个应用层协议来完成特定的网络应用。
例如:实现一个网络版的整数加法计算器。通过在客户端读取两个加数,然后发送给服务器端,经服务器端计算后将结果反馈给客户端并显示出结果。
这里,我们首先要明确一个概念。网络中的数据是以字节流(二进制流)的方式进行传送的。所以在对客户端的两个整数加数进行传输时,要将其转化为二进制流的形式。从网络中接收的数据也是一串字节流(二进制流)。所以,客户端接收到二进制流之后要将其转化为对应的整数进行输出。
我们可以将两个加数封装为一个结构体,而结构体中的数据都是以“0”“1”这样的数据进行存储的。所以可以将该结构体直接通过网络进行发送。待客户端接收到结果对应的二进制流之后,再将其存放在整型变量中。
上述中,将结构化的数据转化为二进制流称为序列化。将二进制流转化为结构化的数据称为反序列化。
因此,根据前面所说过的TCP协议以及相关的接口来编写代码如下:
结构体封装:
//将两个加数和被加数封装为结构体
typedef struct
{
int x;
int y;
}Request;
//加法计算的结果
typedef struct
{
int sum;
}Response;
服务器端部分代码:
void server_work(int client_sock,char* ip,int port)
{
Request req;//定义结构体变量用于接受客户端发来的两个加数
Response res;//定义结构体变量用于存储计算的结果
while(1)
{
//从客户端读取两个加数
ssize_t s = read(client_sock,&req,sizeof(req));
if(s < 0)//读取失败
{
//错误处理
printf("read error\n");
break;
}
else if(s == 0)
{
///客户端已断开连接
printf("client:[%s][%d] quit\n",ip,port);
break;
}
//计算结果
res.sum = req.x + req.y;
//将结果发送给客户端
write(client_sock,&res,sizeof(res));
}
}
客户端部分代码:
while(1)
{
Request req;//定义结构体变量用于存储两个加数
Response res;//定义结构体变量用于接受来自服务器端计算的结果
printf("please enter:");
fflush(stdout);
scanf("%d%d",&req.x,&req.y);//从键盘读取两个加数
write(sock,&req,sizeof(req));//将两个加数发送给服务器端
read(sock,&res,sizeof(res));//接收来自服务器端的结果
printf("%d + %d = %d\n",req.x,req.y,res.sum);//输出结果
}
以上关于服务器端和客户端的其余代码见:这篇博客,其中多进程多线程版本都可以实现计算器的功能。
运行结果如下:
服务器端结果:

客户端结果:
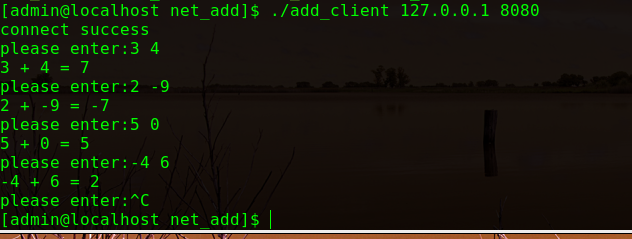
上述代码中实现的是我们自定义的应用层协议。即通信双方都以结构体类型来发送和接收数据。
现有的已经制定好的应用层协议有很多,如支持万维网应用的HTTP协议,支持电子邮件的SMTP协议,支持文件传送的FTP协议。这些协议可以直接使用,在使用时,我们需要明白这些协议的格式,知道如何来使用它们。
下面我们主要介绍HTTP协议。在介绍HTTP协议之前,先介绍一下万维网。
万维网WWW(World Wide Web)
首先要明确:万维网不是某种特殊的计算机网络。它是一个大规模的,联机式的信息储藏所。
万维网上的各站点都必须连接在因特网上(因特网:是当前全球最大的,开放的,由众多网络互连而成的特定计算机网络,采用TCP/IP协议簇作为通信的规则)。每个站点上存放了许多文档。这些文档通过某种方式形成链接可以被其他站点通过该链接来访问该文档。该文档中也可以包含一些其他文档所形成的链接来访问其他文档。所以,万维网通过链接的方式从一个站点访问另一个站点。
万维网是一个分布式的超媒体系统。超媒体是超文本的扩充。超文本是指包含指向其他文档的链接的文本。超文本的内容是一些文本内容,而超媒体中除了文本外,还有一些图像,音频之类的文档。分布式是指万维网上的文档分布在整个因特网上,每个站点主机上都包含一些万维网文档。每台主机对这些文档进行独立管理。相对的非分布式是指所有文档都保存在同一主机上。因为万维网是分布式的,所以可能存在文档与链接不一致的情形。
万维网以客户--服务器的方式进行工作。我们日常使用的浏览器就是在用户主机上的万维网客户端程序。万维网文档驻留的主机运行服务器程序,也称为万维网服务器。如一些360,搜狗浏览器等都是万维网客户端程序,我们在浏览器上比如要访问“清华大学”的官网主页面,该主页面所在的主机的服务器程序就是万维网服务器。客户程序向服务其程序发出访问请求,服务器程序向客户程序提供它所请求的万维网文档。
在万维网中:
(1)用统一资源定位符URL来唯一标识万维网上的文档。
(2)使用超文本传输协议HTTP实现客户程序与服务器程序之间的交互。
(3)使用超文本标记语言HTML来创作万维网文档。
统一资源定位符URL
URL的格式:
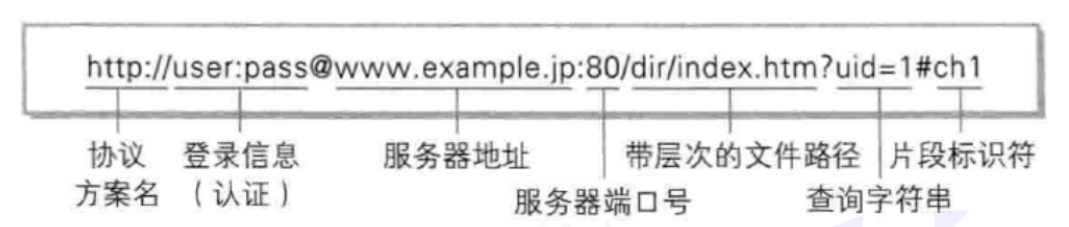
协议名:访问万维网文档时所遵循的协议(一般为http,https)
登录信息:一般省略,进行匿名登录
服务器地址:即访问的万维网文档所在的主机地址。此处给的是域名,也可以为点分十进制形式的字符串IP地址。后台会根据DNS协议将域名解析为IP地址的形式,在进行访问。
服务器端口号:服务器程序是该主机中的哪个进程,由端口号给出。一般也可以省略。因为http协议默认的端口号为80,https默认的端口号为443
带层次的文件路径:所请求的万维网文档在该主机的什么地方,由该路径给出
查询字符串:?之后的为查询字符串,所请求的具体内容(可省略)
片段标识符:可省略。
urlencode和urldecode
在上述的URL中我们可以看到有一些特殊字符:“//”,“?”等。如“?”之后的表示用户要查询的内容。那如果用户要查询的内容中又有“?”这样的字符,如果将?直接标记在URL中就会出现误解。所以在如果用户查询的内容中有某些特殊的字符,首先要对这些特殊字符进行转义。
转义规则:将需要转码的字符根据它的ASCII码将其转化为16进制,然后从右到左,取4位(不足四位直接处理),每两位为一位,前面加%,编码为%XY的格式。
如对“+”进行转义。“+”的ASCII码是43,43转为16进制为2B,此时不足四位直接处理。直接在2B前加%即可。所以“+”转义后的编码格式为:%2B。
上述的特殊字符转义的过程就成为urlencode。与之对应的urldecode就是其转义逆过程。
超文本传输协议HTTP
http协议是一个应用层协议,它使用TCP协议进行可靠的传送。HTTP协议定义了浏览器(万维网客户进程)以什么样的格式向万维网服务进程请求万维网文档,以及服务器以什么样的格式将文档传送给客户程序。每个万维网网点都有一个服务器进程(如果该服务器处理http请求,则端口号绑定为为80,如果为https请求,则端口号绑定为443),它不断监听来自客户端的请求。当有浏览器发送TCP连接请求时,服务器就与其建立连接,并处理请求,返回相应的页面。最后释放链接。
下面来说明HTTP的报文格式。
请求报文:客户程序向服务程序发送的请求报文格式如下:

具体如下:
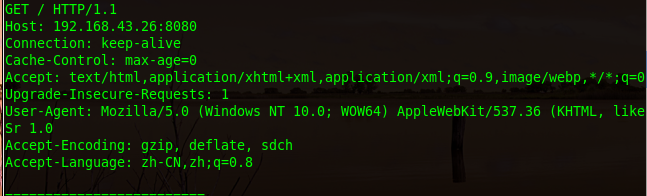
在请求报文中一般由三到四部分组成:
第一部分(第一行)为请求行:以空格分隔三个区域。第一个是请求的方法(下面再介绍)。第二个为请求的资源对应的URL即上述所描述的URL。第三个为HTTP的版本号
常用方法为:
GET:请求由URL标志的信息
POST:给服务器添加信息
HEAD:请求由URL标志信息的首部
PUT:在指定URL下存储一个文档
DELETE:删除URL指定的资源
第二部分(从第二行到空行前)为请求报头:它是由name:value格式的键值对组成(后面介绍)。
第三部分为空行:该行作为请求报头与请求正文的分隔行
第四部分为请求正文(一般不用):HTTP的有效载荷,用户真正请求的信息
响应报文:服务器程序向客户程序发送响应报文
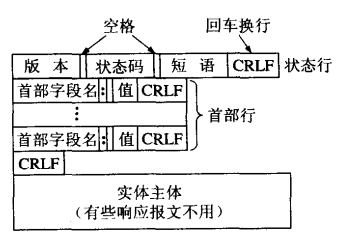
具体如下(这是访问百度主页的响应报文,其中响应正文只列举了部分):
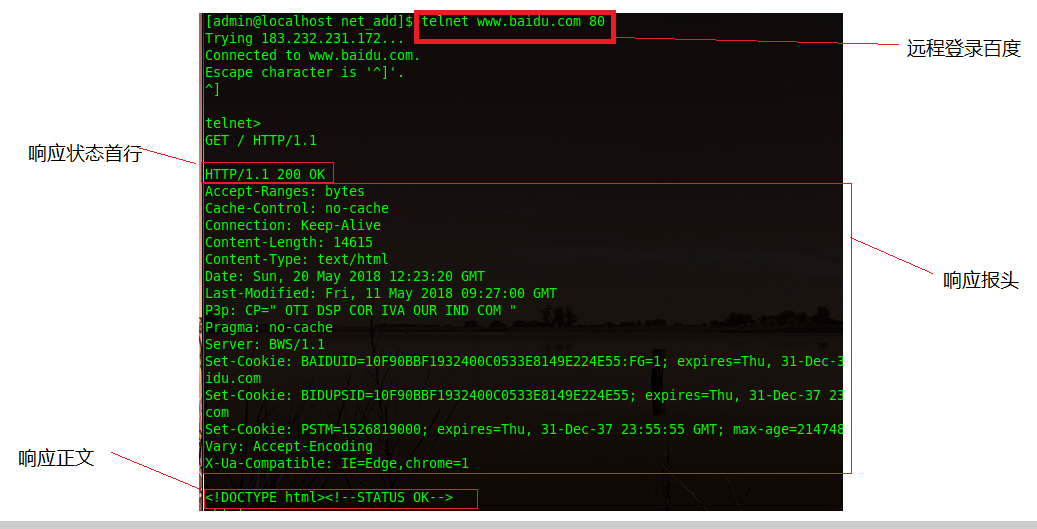
在响应报文中一般也是由三到四部分组成:
第一部分(第一行)为:响应状态行。也是由空格分为三部分:第一个是HTTP的版本号,第二个为状态码,第三个为状态描述。
常用状态码和状态描述如下:
1xx:表示通知消息,如收到请求了或正在处理
2xx:表示成功
3xx:表示重定向
4xx:表示客户的差错
5xx:表示服务器的差错
第二部分(第二行到空行前)为:响应报头,也是有一些键值对组成
第三部分为空行:分隔响应报头和响应正文
第四部分为:响应正文(由HTML超文本标记语言书写)
其中上述请求报头和响应报头的部分键值对为:
Host表示要访问的主机域名。
Connection表示访问资源的连接类型:长连接Keep-alive:只有后续申请的文档还在该服务器上就不释放链接;短连接close:本次请求完得到相应之后即释放连接。
Content-Length:正文的字节长度
Content-Type:数据类型
referer:当前页面从哪个页面跳转过来的
User-Agent:用户操作系统和浏览器的相关信息
location:告诉客户端接下来要去哪访问(搭配状态码3xx使用)
Cookie:在这里,我们首先要知道HTTP是无状态的。当用户访问一次网站得到某页面之后。再次访问该网站想得到同样的页面。服务器并不知道该用户曾经访问过同样的页面。但在实际中,有时是希望网站能识别用户的。所以此时就要用到Cookie。它的工作过程为:
当用户访问某个带Cookie的网站时,该网站的服务器该用户产生一个标识符,并将该标识符作为索引在后台的数据库中生成一个项目。然后在响应报文中添加一个“Set-Cookie:标识符”的键值对。当浏览器收到响应之后,会将“服务器的主机名和标识符”添加在它管理的Cookie文件中。当用户继续浏览该网站时,浏览器会将在请求报文中添加“Cookie:标识符”的键值对,发送给服务器,这样服务器便可以根据标识符知道用户之前的活动状态了。当用户在登录某网站输入姓名,密码等信息时,同样也会保存在Cookie文件中,在下一次登录时服务器就可以利用Cookie文件来识别验证该用户,用户就可以不用再次输入密码等信息了。因为Cookie文件中可能存储用户密码等信息,可能会造成一些安全问题(可以进行手动删除)。
在了解了HTTP协议的相关内容之后。除了万维网中的服务器(http端口号绑定为80,https端口号绑定为443)可以使用HTTP协议进行数据传输,我们自己也可以使用HTTP协议来编写服务器。
下面使用HTTP协议编写简单的HTTP服务器。以浏览器作为客户端,向我们自己编写的HTTP服务器发送连接请求,连接成功之后,服务器直接在浏览器上显示一个字符串。
该服务器也是在tcp协议网络程序中的多进程或多线程网络程序上进行修改。
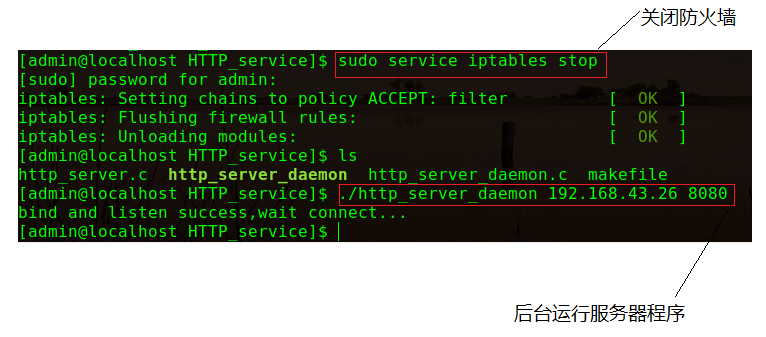
在main函数中在的到监听套接字之后,将进程转化为守护进程,这样该服务器就可以一直在后台运行。
//将套接字设置为监听套接字
int listen_sock = listen_work(sock,inet_addr(argv[1]),htons(atoi(argv[2])));
printf("bind and listen success,wait connect...\n");
daemon(0,0);//创建守护进程
然后进程或线程提供给客户端的服务为:
void server_work(int client_sock)
{
while(1)
{
char client_buf[1024];
client_buf[0] = 0;
ssize_t s = read(client_sock,client_buf,sizeof(client_buf));
if(s > 0)
{
client_buf[s] = 0;
printf("%s\n",client_buf);//将客户端发送的请求报文打印出来
}
const char* buf = "<h1>hello</h1>";//用HTML超文本标记语言HTML书写响应正文
char server_buf[1024];
//按照HTTP协议的格式来书写响应报文
sprintf(server_buf,"HTTP/1.0 200 OK\nContent-Length:%d\n\n%s\n",strlen(buf),buf);
//无论客户端发送什么请求,都不做处理,只给客户端返回一条字符串
write(client_sock,server_buf,strlen(server_buf));
}
}
在服务器运行前先关闭防护墙,当服务器运行起来之后,在任意浏览器(浏览器要与服务器连接同一局域网)上以HTTP协议访问服务器绑定的IP地址和端口号,如下图:
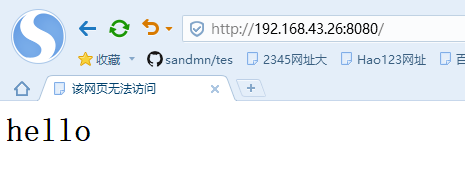
浏览器页面:
所以只要与服务器连接同一局域网,并且按服务器绑定的IP地址和端口号进行访问,就可以得到上述结果。注意:我们自己编写的HTTP服务器只要不与万维网上的HTTP服务器默认绑定的端口号以及常用的应用层协议绑定的端口号重合即可。