本篇文章参考以下博文
文章目录
前言
如题,这是一个经常在面试里出现的题目,主要目的是让你描述一下浏览器工作原理,通过这些流程,了解你个人对于整个前端整体的掌握程度,顺便了解一下你的知识深度和广度。
有些同学可能不解,作为前端开发,写好页面不就行了?知道这些有什么用?
最直接的结果就是,了解之后工资很可能翻倍!各位,诱惑大不大?
我个人的感受就像旅游一样,原来是在小山村,日出而作,日落而息。每一项活动都是安排好的,你只需要照着经验做就行了,至于为什么要这样没人会关心。
但是当慢慢了解了浏览器之后,就像开启了新世界的大门,所有的一切都是经过无数前辈的实验而总结下来的最优方案,在这里你可以知道页面为什么要这样写,请求为什么会跨域,一切的都会有一个合理的解释。
整体流程
回到标题,当输入 URL 之后,浏览器会做些什么?
- 输入 URL 并回车
- URL 解析 / DNS 解析查找域名 IP 地址
- 网络连接发起 HTTP 请求
- HTTP 报文传输过程
- 服务器接受数据
- 服务器响应请求 / MVC
- 服务器返回数据
- 客户端接收数据
- 浏览器加载 / 渲染页面
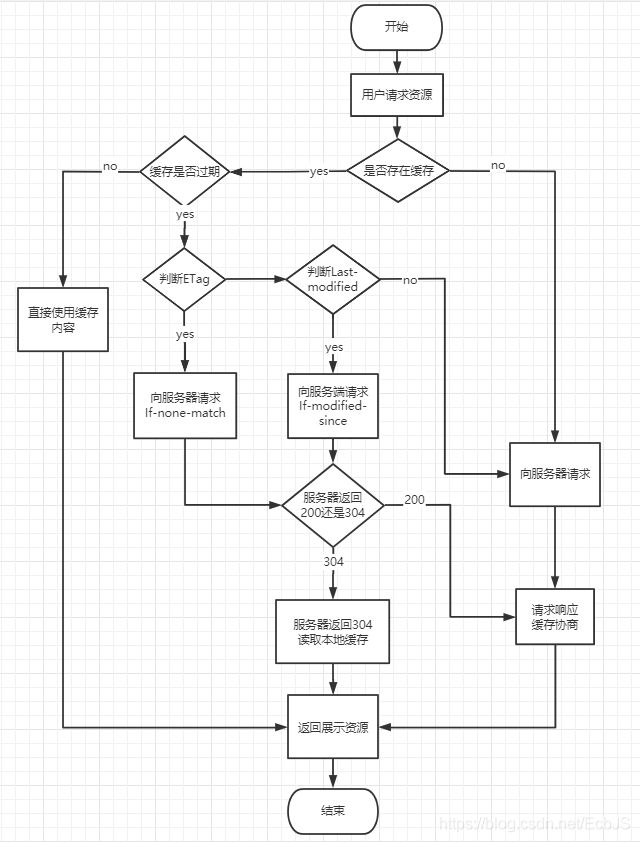
1. 输入URL并回车
在我们输入 url 之前,紧张有序的工作早就已经开始了。在某个阳光明媚,鸟语花香的午后,一台服务器被接通了电源,随着操作系统的唤醒,内部设定的 http 服务进程开始工作。
这个守护进程可能是 Apache、Nginx、IIS 等,无论是谁,这个 http 服务会开始定位到服务器上 www 文件夹,一般是在 var/www 。
然后启动一些附属模块,比如 php 等,准备的差不多了,就会向操作系统申请一个 tcp 链接,默默绑定在 80 端口,调用 accept 函数,开始了一丝不苟的监听工作,监听可能来自地球任何地方的请求,一级戒备,一旦有警,随时响应。
与此同时,服务器不是一个人在战斗,身旁不远处,就是他的老战友,数据库服务器,他们一个是枪炮,一个是弹药,时刻守卫着机房阵地。
如果是正规军,这支作战小队还可能拥有自动反击系统(缓存服务器),信息统一处理中心(负载均衡服务器)等。
历史背景接待完毕,接下来正式开始。
当点击回车后,这一信息会首先下达到 CPU ,经过处理后交给操作系统,再由操作系统 GUI 通知浏览器,浏览器接收到之后,知会内核开始工作。这一过程涉及的大部分都是底层知识,和问题无关,我们不进行讨论。
上面再操作系统将事件传递到浏览器的过程中,浏览器可能会做一些预处理,反正正式命令还没来,闲着也是闲着,最常见的会匹配 URL ,从历史记录或者书签等什么地方,找到有过记录的相似 URL 来预估想要访问的网站。
对于浏览器行业的老大哥 Chrome ,它会在启动时预先查询10个你有可能访问的域名等。
2.URL 解析 / DNS 查询
接下来是输入 URL 「回车」后,浏览器会对 URL 进行检查,检查内容如下:
①协议 :是从该计算机获取资源的方式,一般有 Http、Https、Ftp、File、Mailto、Telnet、News 等协议,不同协议有不同的通讯内容格式,协议主要作用是告诉浏览器如何处理将要打开的文件;
②网络地址 :指示该连接网络上哪一台计算机(服务器),可以是域名或者 IP 地址,域名或 IP 地址后面有时还跟一个冒号和一个端口号;
③资源路径 :指示从服务器上获取哪一项资源的等级结构路径,以斜线 / 分隔;
文件名一般是需要真正访问的文件,有时候,URL以斜杠 / 结尾,而隐藏了文件名,在这种情况下, URL 引用路径中最后一个目录中的默认文件(通常对应于主页),这个文件常被称为 index.html 或 default.htm 。
④动态参数 :有时候路径后面会有以问号 ? 开始的参数,这一般都是用来传送对服务器上的数据库进行动态询问时所需要的参数,有时候没有,很多为了 seo 优化,都已处理成伪静态了。要注意区分 url 和路由的区别。
URL完整格式为:协议://用户名:密码@子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标志
例如:https://blog.csdn.net/EcbJS?spm=1011.2124.3001.5343
协议部分: https
网络地址: blog.csdn.net (依次为 子/三级域名.二级域名.顶/一级域名)
资源路径: /EcbJS
参数: spm=1011.2124.3001.5343
浏览器对 URL 进行检查时首先判断协议,如果是 http/https 就按照 Web 来处理,另外还会对 URL 进行安全检查,然后直接调用浏览器内核中的对应方法,接下来是对网络地址进行处理。
如果地址不是一个 IP 地址而是域名则通过 DNS (域名系统)将该地址解析成 IP 地址。 IP 地址对应着网络上一台计算机, DNS 服务器本身也有 IP ,你的网络设置包含 DNS 服务器的 IP 。 例如: 116.211.167.187 www.zhihu.com域名请求对应获得的 IP是 。
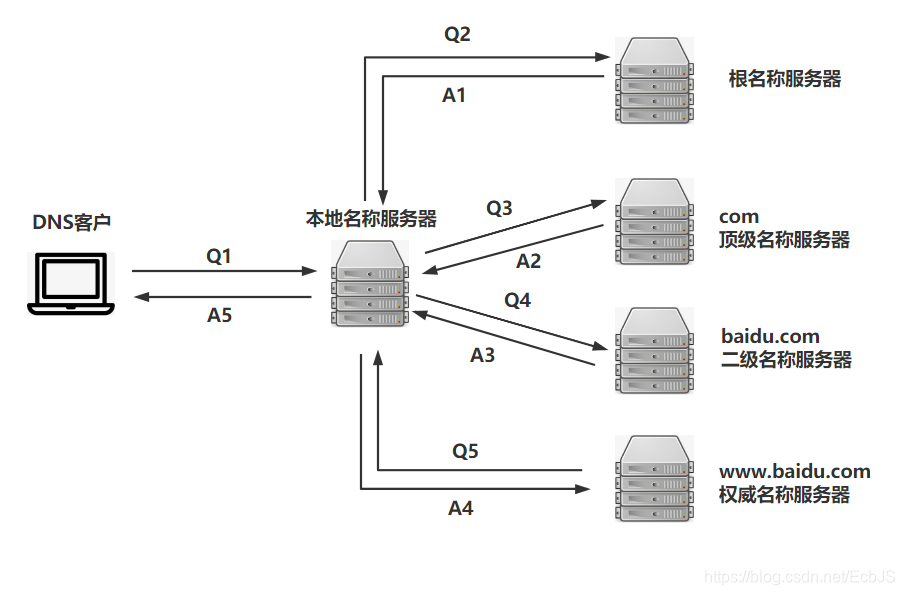
DNS 在解析域名的时候有两种方式:递归查询和迭代查询,
递归查询的流程如下:
一般来说,浏览器会首先查询浏览器缓存( DNS 在各个层级都有缓存的,相应的,缓存当然有过期时间, Time to live )。
如果没有找到,就会检查系统缓存,检查本地硬盘的 hosts 文件,这个文件保存了一些以前访问过的网站的域名和 IP 对应的数据。
它就像是一个本地的数据库。如果找到就可以直接获取目标主机的 IP 地址了(注意这个地方存在安全隐患,如果有病毒把一些常用的域名,修改 hosts 文件,指向一些恶意的 IP ,那么浏览器也会不加判断的去连接,是的,这正是很多病毒的惯用手法)
如果本地 hosts 也没有找到的话,则需要再向上层找路由器缓存,路由器有自己的 DNS 缓存,可能就包括了查询的内容;
如果还是没有,需要接着往上找,查询 ISP DNS 缓存(本地名称服务器缓存,就是客户端电脑 TCP/IP 参数中设置的首选 DNS 服务器,此解析具有权威性)。
一般情况下在不同的地区或者不同的网络,如电信、联通、移动的情况下,转换后的 IP 地址很可能是不一样的,这涉及到负载均衡,通过 DNS 解析域名时会将你的访问分配到不同的入口,先找附近的本地 DNS 服务器去请求解析域名,尽可能保证你所访问的入口是所有入口中较快的一个。
如果附近的本地 DNS 服务器还是没有缓存我们请求的域名记录的话,这时候会根据本地 DNS 服务器的设置(是否设置转发器)进行查询,如果未用转发模式,则本地名称服务器再以 DNS 客户端的角色发送与前面一样的 DNS 域名查询请求转发给上一层。
这里可能经过一次或者多次转发,从本地名称服务器到权威名称服务器再到顶级名称服务器最后到根名称服务器。(顺便一提,根服务器是互联网域名解析系统 DNS 中最高级别的域名服务器,全球一共 13 组,每组都只有一个主根名称服务器采用同一个 IP )。
所以,最终请求到了根服务器后,根服务器查询发现我们这个被请求的域名是由类似 A 或者 B 这样的服务器解析的,但是,根服务器并不会送佛送到西地找 A 或 B 之类的直接去解析,因为它没有保存全部互联网域名记录,并不直接用于名称解析,
它只是负责顶级名称服务器(如 .com/.cn/.net 等)的相关内容。所以它会把所查询得到的被请求的DNS域名中顶级域名所对应的顶级名称服务器 IP 地址返回给本地名称服务器。
本地名称服务器拿到地址后再向对应的顶级名称服务器发送与前面一样的 DNS 域名查询请求。对应的顶级名称服务器在收到 DNS 查询请求后,也是先查询自己的缓存。
如果有则直接把对应的记录项返回给本地名称服务器,然后再由本地名称服务器返回给 DNS 客户端,如果没有则向本地名称服务器返回所请求的 DNS 域名中的二级域名所对应的二级名称服务器(如 baidu.com/qq.com/net.cn 等)地址。
然后本地名称服务器继续按照前面介绍的方法一次次地向三级(如 www.baidu.com/bbs.taobao.com 等)、四级名称服务器查询。
直到最终的对应域名所在区域的权威名称服务器返回最终记录给本地名称服务器。同时本地名称服务器会缓存本次查询得到的记录项(每层都应该会缓存)。再层层下传,最后到了我们的 DNS 客户端机子,一次 DNS 解析请求就此完成。
如果最终权威名称服务器都说找不到对应的域名记录,则会向本地名称服务器返回一条查询失败的 DNS 应答报文,这条报文最终也会由本地名称服务器返回给 DNS 客户端。
当然,如果这个权威名称服务器上配置了指向其它名称服务器的转发器,则权威名称服务器还会在转发器指向的名称服务器上进一步查询。另外,如果 DNS 客户端上配置了多个 DNS 服务器,则还会继续向其它 DNS 服务器查询的。
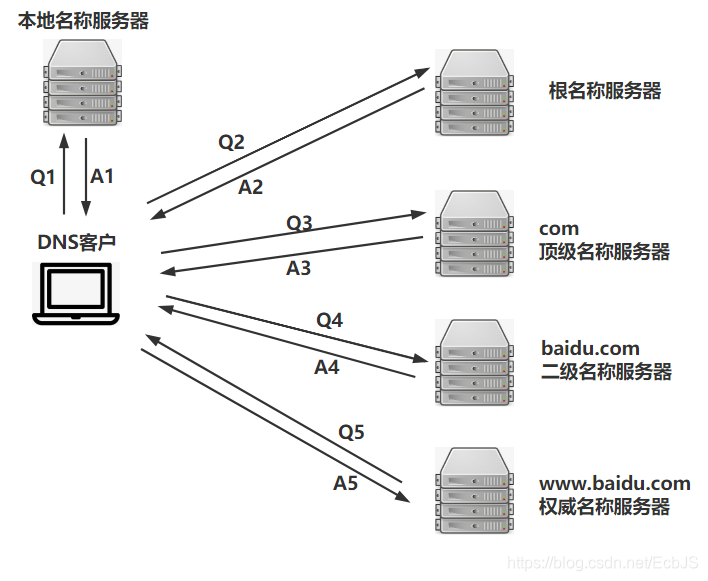
迭代查询的流程如下:
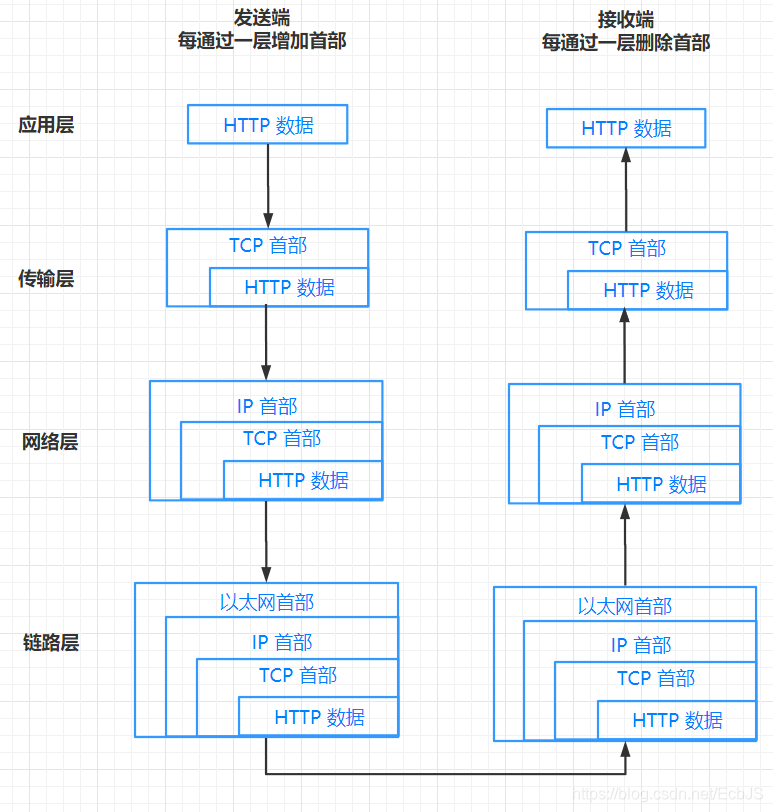
3. 应用层客户端发送HTTP请求
互联网内各网络设备间的通信都遵循 TCP/IP 协议,利用 TCP/IP 协议族进行网络通信时,会通过分层顺序与对方进行通信。分层由高到低分别为:应用层、传输层、网络层、数据链路层。发送端从应用层往下走,接收端从数据链路层网上走。如图所示:
从上面的步骤中得到 IP 地址后,浏览器会开始构造一个 HTTP 请求,应用层客户端向服务器端发送的 HTTP 请求包括:请求报头和请求主体两个部分。
其中请求报头( request header )包含了至关重要的信息,包括请求的方法( GET / POST ,一般的浏览器只能发起 GET 或者 POST 请求)、目标 url 、遵循的协议( HTTP / HTTPS / FTP …),返回的信息是否需要缓存,以及客户端是否发送 Cookie 等信息。需要注意的是,因为 HTTP 请求是纯文本格式的,所以在 TCP 的数据段中可以直接分析 HTTP 文本的。
Accept: 接收类型,表示浏览器支持的MIME类型
(对标服务端返回的Content-Type)
Accept-Encoding:浏览器支持的压缩类型,如gzip等,超出类型不能接收
Content-Type:客户端发送出去实体内容的类型
Cache-Control: 指定请求和响应遵循的缓存机制,如no-cache
If-Modified-Since:对应服务端的Last-Modified,用来匹配看文件是否变动,只能精确到1s之内,http1.0中
Expires:缓存控制,在这个时间内不会请求,直接使用缓存,http1.0,而且是服务端时间
Max-age:代表资源在本地缓存多少秒,有效时间内不会请求,而是使用缓存,http1.1中
If-None-Match:对应服务端的ETag,用来匹配文件内容是否改变(非常精确),http1.1中
Cookie: 有cookie并且同域访问时会自动带上
Connection: 当浏览器与服务器通信时对于长连接如何进行处理,如keep-alive
Host:请求的服务器URL
Origin:最初的请求是从哪里发起的(只会精确到端口),Origin比Referer更尊重隐私
Referer:该页面的来源URL(适用于所有类型的请求,会精确到详细页面地址,csrf拦截常用到这个字段)
User-Agent:用户客户端的一些必要信息,如UA头部等
4. 传输层TCP传输报文
当应用层的 HTTP 请求准备好后,浏览器会在传输层发起一条到达服务器的 TCP 连接,位于传输层的 TCP 协议为传输报文提供可靠的字节流服务。
它为了方便传输,将大块的数据分割成以报文段为单位的数据包进行管理,并为它们编号,方便服务器接收时能准确地还原报文信息。
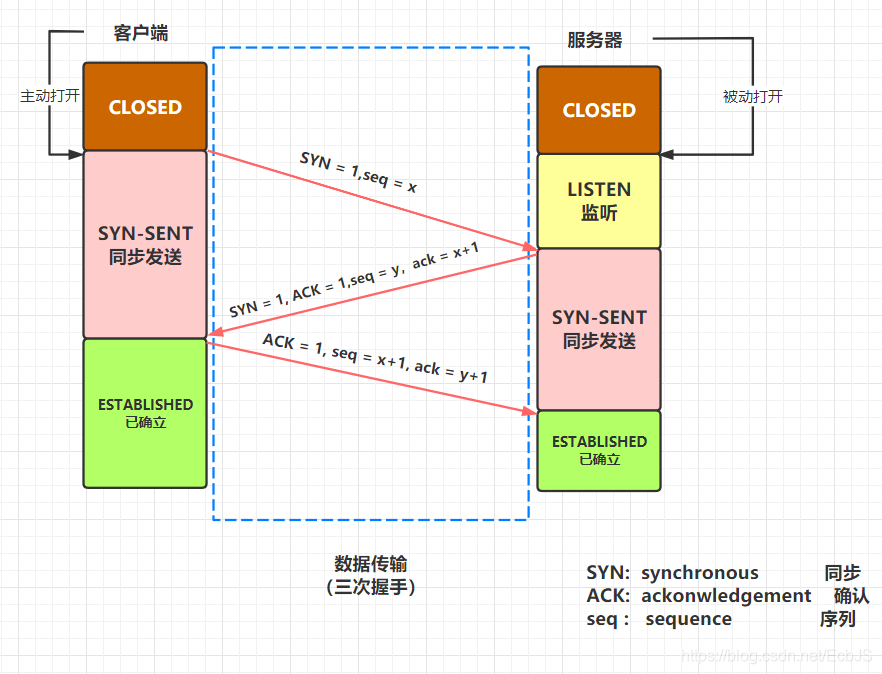
TCP 协议通过“三次握手”等方法保证传输的安全可靠。“三次握手”的过程是,发送端先发送一个带有 SYN(synchronize) 标志的数据包给接收端,在一定的延迟时间内等待接收的回复。
接收端收到数据包后,传回一个带有 SYN/ACK 标志的数据包以示传达确认信息。接收方收到后再发送一个带有 ACK 标志的数据包给接收端以示握手成功。
在这个过程中,如果发送端在规定延迟时间内没有收到回复则默认接收方没有收到请求,而再次发送,直到收到回复为止。
5. 网络层IP协议查询MAC地址
IP 协议的作用是把 TCP 分割好的各种数据包封装到 IP 包里面传送给接收方。而要保证确实能传到接收方还需要接收方的 MAC 地址,也就是物理地址才可以。
IP 地址和 MAC 地址是一一对应的关系,一个网络设备的 IP 地址可以更换,但是 MAC 地址一般是固定不变的。 ARP协议可以将IP地址解析成对应的 MAC 地址。当通信的双方不在同一个局域网时,需要多次中转才能到达最终的目标,在中转的过程中需要通过下一个中转站的 MAC 地址来搜索下一个中转目标。
6. 数据到达数据链路层
在找到对方的 MAC 地址后,已被封装好的IP包再被封装到数据链路层的数据帧结构中,将数据发送到数据链路层传输,再通过物理层的比特流送出去。这时,客户端发送请求的阶段结束。
这些分层的意义在于分工合作,数据链路层通过 CSMA/CD 协议保证了相邻两台主机之间的数据报文传递,而网络层的 IP 数据包通过不同子网之间的路由器的路由算法和路由转发,保证了互联网上两台遥远主机之间的点对点的通讯。
不过这种传输是不可靠,于是可靠性就由传输层的 TCP 协议来保证, TCP 通过慢开始,乘法减小等手段来进行流量控制和拥塞避免,同时提供了两台遥远主机上进程到进程的通信,最终保证了 HTTP 的请求头能够被远方的服务器上正在监听的 HTTP 服务器进程收到。
终于,数据包在跳与跳之间被拆了又封装,在子网与子网之间被转发了又转发,最后进入了服务器的操作系统的缓冲区,服务器的操作系统由此给正在被阻塞住的 accept 函数一个返回,将他唤醒。
7. 服务器接收数据
接收端的服务器在链路层接收到数据包,再层层向上直到应用层。这过程中包括在传输层通过 TCP 协议将分段的数据包重新组成原来的 HTTP 请求报文。
服务器在收到浏览器发送的 HTTP 请求之后,会将收到的 HTTP 报文封装成 HTTP 的 Request 对象,并通过不同的 Web 服务器进行处理,处理完的结果以 HTTP 的 Response 对象返回,主要包括状态码,响应头,响应报文三个部分。
状态码主要包括以下部分
- 1xx:指示信息–表示请求已接收,继续处理。
- 2xx:成功–表示请求已被成功接收、理解、接受。
- 3xx:重定向–要完成请求必须进行更进一步的操作。
- 4xx:客户端错误–请求有语法错误或请求无法实现。
- 5xx:服务器端错误–服务器未能实现合法的请求。
响应头主要由 Cache-Control、 Connection、Date、Pragma 等组成。响应体为服务器返回给浏览器的信息,主要由 HTML,css,js ,图片文件组成。
常用的响应头部(部分):
Access-Control-Allow-Headers: 服务器端允许的请求Headers
Access-Control-Allow-Methods: 服务器端允许的请求方法
Access-Control-Allow-Origin: 服务器端允许的请求Origin头部(譬如为*)
Content-Type:服务端返回的实体内容的类型
Date:数据从服务器发送的时间
Cache-Control:告诉浏览器或其他客户,什么环境可以安全的缓存文档
Last-Modified:请求资源的最后修改时间
Expires:应该在什么时候认为文档已经过期,从而不再缓存它
Max-age:客户端的本地资源应该缓存多少秒,开启了Cache-Control后有效
ETag:请求变量的实体标签的当前值
Set-Cookie:设置和页面关联的cookie,服务器通过这个头部把cookie传给客户端
Keep-Alive:如果客户端有keep-alive,服务端也会有响应(如timeout=38)
Server:服务器的一些相关信息
8. 服务器响应请求并返回相应文件
服务接收到客户端发送的 HTTP 请求后,服务器上的的 HTTP 监听进程会得到这个请求,然后一般情况下会启动一个新的子进程去处理这个请求,同时父进程继续监听。
HTTP 服务器首先会查看重写规则,然后如果请求的文件是真实存在,例如一些图片,或 html、css、js 等静态文件,则会直接把这个文件返回,如果是一个动态的请求,那么会根据 url 重写模块的规则,把这个请求重写到一个 rest 风格的 url 上,然后根据动态语言的脚本,来决定调用什么类型的动态文件脚本解释器来处理这个请求。
我们以 php 语言为例来说的话,请求到达一个 php 的 mvc 框架之后,框架首先应该会初始化一些环境的参数,例如远端 ip ,请求参数等等。
然后根据请求的 url 送到一个路由器类里面去匹配路由,路由由上到下逐条匹配,一旦遇到 url 能够匹配的上,而且请求的方法也能够命中的话,那么请求就会由这个路由所定义的处理方法去处理。
请求进入处理函数之后,如果客户端所请求需要浏览的内容是一个动态的内容,那么处理函数会相应的从数据源里面取出数据。
这个地方一般会有一个缓存,例如 memcached 来减小 db 的压力,如果引入了 orm 框架的话,那么处理函数直接向 orm 框架索要数据就可以了,由 orm 框架来决定是使用内存里面的缓存还是从 db 去取数据,一般缓存都会有一个过期的时间,而 orm 框架也会在取到数据回来之后,把数据存一份在内存缓存中的。
orm 框架负责把面向对象的请求翻译成标准的 sql 语句,然后送到后端的 db 去执行。
db 这里以 mysql 为例的话,那么一条 sql 进来之后, db 本身也是有缓存的,不过 db 的缓存一般是用 sql 语言 hash 来存取的。
也就是说,想要缓存能够命中,除了查询的字段和方法要一样以外,查询的参数也要完全一模一样才能够使用 db 本身的查询缓存。
sql 经过查询缓存器,然后就会到达查询分析器,在这里, db 会根据被搜索的数据表的索引建立情况和 sql 语言本身的特点,来决定使用哪一个字段的索引。
值得一提的是,即使一个数据表同时在多个字段建立了索引,但是对于一条 sql 语句来说,还是只能使用一个索引,所以这里就需要分析使用哪个索引效率最高了,一般来说, sql 优化在这个点上也是很重要的一个方面。
sql 由 db 返回结果集后,再由 orm 框架把结果转换成模型对象,然后由 orm 框架进行一些逻辑处理,把准备好的数据,送到视图层的渲染引擎去渲染,渲染引擎负责模板的管理,字段的友好显示,也包括负责一些多国语言之类的任务。
在视图层把页面准备好后,再从动态脚本解释器送回到 http 服务器,由 http 服务器把这些正文加上一个响应头,封装成一个标准的 http 响应包,再通过 tcp ip 协议,送回到客户机浏览器。
9.浏览器开始处理数据信息并渲染页面
历经千辛万苦,我们请求的响应终于成功到达了客户端的浏览器,响应到达浏览器之后,浏览器首先会根据返回的响应报文里的一个重要信息——状态码,来做个判断。
如果是 200 开头的就好办,表示请求成功,直接进入渲染流程,如果是 300 开头的就要去相应头里面找 location 域,根据这个 location 的指引,进行跳转,这里跳转需要开启一个跳转计数器,是为了避免两个或者多个页面之间形成的循环的跳转,当跳转次数过多之后,浏览器会报错,同时停止。
比如: 301 表示永久重定向,即请求的资源已经永久转移到新的位置。在返回 301 状态码的同时,响应报文也会附带重定向的 url ,客户端接收到后将 http 请求的 url 做相应的改变再重新发送。
如果是 400 开头或者 500 开头的状态码,浏览器也会给出一个错误页面。比如:404 not found 就表示客户端请求的资源找不到。
当浏览得到一个正确的 200 响应之后,接下来面临的一个问题就是多国语言的编码解析了,响应头是一个 ASCII 的标准字符集的文本,这个还好办,但是响应的正文本质上就是一个字节流,对于这一坨字节流,浏览器要怎么去处理呢?
浏览器会去看响应头里面指定的 encoding 域,按照指定的 encoding 去解析字符。
接下来就是构建 dom 树了,在 html 语言嵌套正常而且规范的情况下,这种 xml 标记的语言是比较容易的能够构建出一棵 dom 树出来的,当然,对于互联网上大量的不规范的页面,不同的浏览器应该有自己不同的容错去处理。
构建出来的 dom 本质上还是一棵抽象的逻辑树,构建 dom 树的过程中,如果遇到了由 script 标签包起来的 js 动态脚本代码,那么会把代码送到 js 引擎里面去跑。
如果遇到了 style 标签包围起来的 css 代码,也会保存下来,用于稍后的渲染。如果遇到了 img 或 css 和 js 等引用外部文件的标签,那么浏览器会根据指定的 url 再次发起一个新的 http 请求,去把这个文件拉取回来。
值得一提的是,对于同一个域名下的下载过程来说,浏览器一般允许的并发请求是有限的,通常控制在两个左右,所以如果有很多的图片的话,一般出于优化的目的,都会把这些图片使用一台静态文件的服务器来保存起来,负责响应,从而减少主服务器的压力。
dom 树构造好了之后,就是根据 dom 树和 css 样式表来构造 render 树了,这个才是真正的用于渲染到页面上的一个一个的矩形框的树,网页渲染是浏览器最复杂、最核心的功能。
对于 render 树上每一个框,需要确定他的 x y 坐标,尺寸,边框,字体,形态,等等诸多方面的东西, render 树一旦构建完成,整个页面也就准备好了,可以上菜了。
需要说明的是,下载页面,构建 dom 树,构建 render 树这三个步骤,实际上并不是严格的先后顺序的,为了加快速度,提高效率,让用户不要等那么久,现在一般都并行的往前推进的,现代的浏览器都是一边下载,下载到了一点数据就开始构建 dom 树,也一边开始构建 render 树,构建了一点就显示一点出来,这样用户看起来就不用等待那么久了。
整个过程需要多个模块写作才能最终展示出来的,对于前端来说,我们可以只关注浏览器的相关操作。