天津大学《数据分析与数据挖掘》公开课--学习笔记
- 1.1 数据分析与数据挖掘
- 1.2 分析和挖掘的数据类型
- 1.3 数据分析与数据挖掘方法
- 1.4 数据分析与数据挖掘使用技术
- 1.5 应用场景及存在的问题
- 2.1 数据的属性
- 2.2 数据的基本统计描述
- 2.3 数据的相似性和相异性
- 3.1 数据存在的问题
- 3.2 数据清理
- 3.3 数据集成
- 3.4 数据规约
- 3.5 数据变换与数据离散化
- 4.1 数据仓库的基本概念
- 4.2 数据仓库设计
- 4.3 数据仓库实现
- 4.4 联机分析处理
- 4.5 元数据模型
- 5.1 回归分析
- 5.2 一元线性回归
- 5.3 多元线性回归
- 5.4 多项式回归
- 6.1 频繁模式概述
- 6.2 Apriori算法
- 6.3 FP-growth算法
- 6.4 压缩频繁项集
- 6.5 关联模式评估
- 7.1 分类概述
- 7.2 决策树
- 7.3 朴素贝叶斯分类
- 7.4 惰性学习法
- 7.5 神经网络
- 7.6 分类模型的评估
- 8.1 聚类概述
- 8.2 基于划分的聚类
- 8.3 基于层次的聚类
- 8.4 基于网格的聚类
- 9.1 离群点定义和类型
- 9.2 离群点检测
网址:《数据分析与数据挖掘》–天津大学公开课
链接: https://b23.tv/PJkU28
1.1 数据分析与数据挖掘
数据分析是指采用适当的统计分析方法对收集到的数据进行分析、概括和总结,对数据进行恰当的描述,提取出有用的信息的过程。对决策进行辅助,提供数据的根据,利用表格和列表进行展示。
数据挖掘是指在大量的数据中进行挖掘知识。
1.1.3 知识发现(KDD)的过程
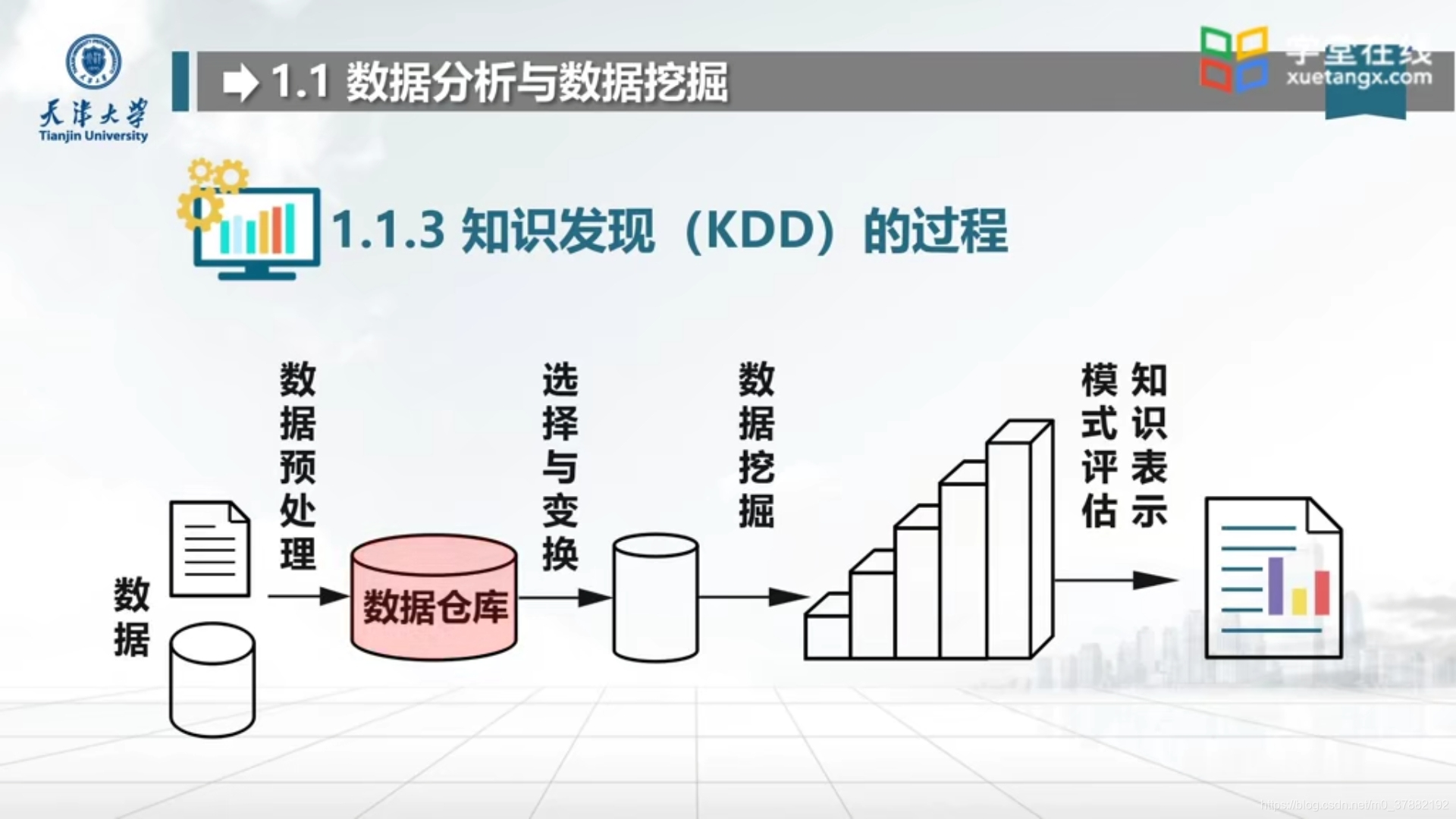
1.1.4 区别

1.1.5 联系

1.2 分析和挖掘的数据类型
1.2.1 数据库数据
关系数据库
SQL
数据库 比较流行的有:MySQL, Oracle, SqlServer
1.2.2 数据仓库数据
数据仓库是一个面向主题的、集成的、随时间变化的、但信息本身相对稳定的数据集合,用于对管理决策过程的支持。
数据仓库 比较流行的有:AWS Redshift, Greenplum, Hive等

1.2.3 事务数据
数据库事务(简称:事务)是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
一个数据库事务通常包含了一个序列的对数据库的读/写操作。它的存在包含有以下两个目的:
为数据库操作序列提供了一个从失败中恢复到正常状态的方法,同时提供了数据库即使在异常状态下仍能保持一致性的方法。
当多个应用程序在并发访问数据库时,可以在这些应用程序之间提供一个隔离方法,以防止彼此的操作互相干扰。
当事务被提交给了DBMS(数据库管理系统),则DBMS(数据库管理系统)需要确保该事务中的所有操作都成功完成且其结果被永久保存在数据库中,如果事务中有的操作没有成功完成,则事务中的所有操作都需要被回滚,回到事务执行前的状态;同时,该事务对数据库或者其他事务的执行无影响,所有的事务都好像在独立的运行。
但在现实情况下,失败的风险很高。在一个数据库事务的执行过程中,有可能会遇上事务操作失败、数据库系统/操作系统失败,甚至是存储介质失败等情况。这便需要DBMS对一个执行失败的事务执行恢复操作,将其数据库状态恢复到一致状态(数据的一致性得到保证的状态)。为了实现将数据库状态恢复到一致状态的功能,DBMS通常需要维护事务日志以追踪事务中所有影响数据库数据的操作。
1.2.4 数据矩阵
1.2.5 图和网状结构数据
例如社交数据,电商数据,搜索引擎
网页排名算法PageRank
1.3 数据分析与数据挖掘方法
1.3.1 频繁模式
关联与相关性
信用卡分析、购物车分析
1.3.2 分类与回归
1.3.3 聚类分析
聚类:
1.3.4 离群点分析
离群点:
信用卡异常消费
1.4 数据分析与数据挖掘使用技术

1.4.1 统计学方法
1.4.2 机器学习
监督学习
无监督学习
半监督学习
1.4.3 数据库与数据仓库
1.5 应用场景及存在的问题
商务智能、信息识别、搜索引擎
2.1 数据的属性
2.1.1 数据对象
2.1.2 属性

2.1.3 属性类型
2.2 数据的基本统计描述

2.2.1 中心趋势度量
截尾均指:
加权算数平均数:
2.2.2 数据的分散度量
极差:
方差:
2.2.3 数据的图形显示
1、箱图
用来描述最大值、最小值、下四位数、中位数和上四位数的五数概括
2.饼图
3、频率直方图
4、散点图
2.3 数据的相似性和相异性
2.3.1 数据矩阵和相异矩阵
近邻性度量
2.3.2 数值属性的相异性
1、欧几里得距离
2、曼哈顿距离
2.3.3 序数属性的近邻性度量
2.3.4 余弦相似性
余弦相似度
3.1 数据存在的问题
数据不一致
数据缺失
噪声数据
缺失值
3.2 数据清理
3.2.1 空缺值处理
3.2.2 噪声处理
3.3 数据集成
1、实体识别问题
2、冗余问题
数值数据:相关系数及协方差
相关性分析
卡方检验
3.4 数据规约
数据标准化
数据立方体
3.5 数据变换与数据离散化
数据变换:将数据变换成适合数据挖掘的形式
3.5.1 数据泛化
3.5.2 数据规范化
3.5.3 数据变换:属性构造
3.5.4 离散化
分箱法
4.1 数据仓库的基本概念
4.1.1 数据仓库定义和特征
定义:数据仓库,英文名称为Data Warehouse,可简写为DW或DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
特征:集成的、时变性、非易失的、
4.1.2 数据仓库体系结构

4.1.3 数据模型
4.1.4 粒度
4.2 数据仓库设计
面向主题的、集成的、不可更新的
自顶向下,逐步细化
4.2.1 概念模型设计
多维数据模型、
星型模型
雪花模型

事实星座模型
4.2.2 逻辑模型设计
核心基础

4.3 数据仓库实现
SQL实现工具
实例
4.4 联机分析处理
4.4.1 OLAP简介
联机分析处理(OLAP)系统是数据仓库系统最主要的应用,专门设计用于支持复杂的分析操作,侧重对决策人员和高层管理人员的决策支持,可以根据分析人员的要求快速、灵活地进行大数据量的复杂查询处理,并且以一种直观而易懂的形式将查询结果提供给决策人员,以便他们准确掌握企业(公司)的经营状况,了解对象的需求,制定正确的方案。
数据层。实现对企业操作数据的抽取、转换、清洗和汇总,形成信息数据,并存储在企业级的中心信息数据库中。
应用层。通过联机分析处理,甚至是数据挖掘等应用处理,实现对信息数据的分析。
表现层。通过前台分析工具,将查询报表、统计分析、多维联机分析和数据发掘的结论展现在用户面前。
ROLAP、MOLAP、HOLAP
4.4.2 OLAP与OLTP区别
OLTP与OLAP的介绍
数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
OLAP 系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。

4.4.3 典型OLAP操作
切片
切块
上卷
下钻
旋转
4.5 元数据模型
4.5.1 元数据内容
元数据库
4.5.2 元数据类型
静态元数据
动态元数据
4.5.3 元数据的作用
元数据

5.1 回归分析
回归分析:
一元线性回归
多元线性回归
多项式回归
5.1.1 回归分析的步骤
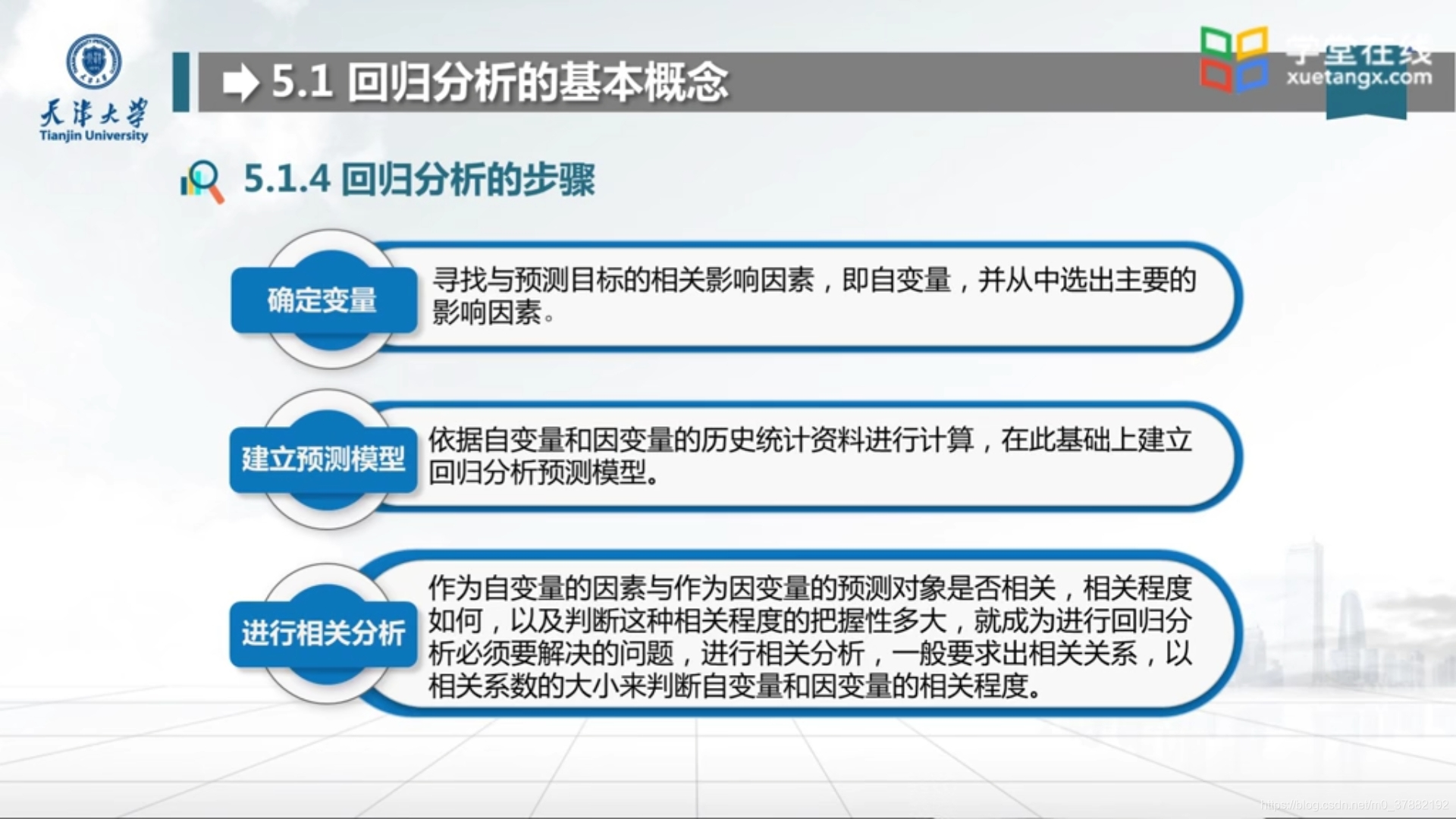
5.2 一元线性回归
5.2.1 回归方程

5.2.2 求解及模型检验
最小二乘法
拟合优度检验
显著性检验
5.3 多元线性回归
5.3.1 回归方程
方程

5.4 多项式回归
5.4.1 回归方程
方程

5.4.2 最小二乘法
5.4.3 拟合优度检验
5.4.4 显著性检验
6.1 频繁模式概述
6.1.1 相关概念
购物车分析、牛奶面包组合
频繁相集
6.1.2 关联规则
关联规则公式
最小支持度
置信度
最小置信度
强关联规则
6.1.3 先验原理
6.2 Apriori算法
6.2.1 关联规则挖掘的方法
穷举法
6.2.2 Apriori算法
Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策。比如在常见的超市购物数据集,或者电商的网购数据集中,如果我们找到了频繁出现的数据集,那么对于超市,我们可以优化产品的位置摆放,对于电商,我们可以优化商品所在的仓库位置,达到节约成本,增加经济效益的目的。

第一步:连接
第二步:剪枝
第三步:计算支持度
本文基于该样例的数据编写Python代码实现Apriori算法。代码需要注意如下两点:
由于Apriori算法假定项集中的项是按字典序排序的,而集合本身是无序的,所以我们在必要时需要进行set和list的转换;
由于要使用字典(support_data)记录项集的支持度,需要用项集作为key,而可变集合无法作为字典的key,因此在合适时机应将项集转为固定集合frozenset。
// An highlighted block
"""
# Python 2.7
# Filename: apriori.py
# Author: llhthinker
# Email: hangliu56[AT]gmail[DOT]com
# Blog: http://www.cnblogs.com/llhthinker/p/6719779.html
# Date: 2017-04-16
"""
def load_data_set():
"""
Load a sample data set (From Data Mining: Concepts and Techniques, 3th Edition)
Returns:
A data set: A list of transactions. Each transaction contains several items.
"""
data_set = [['l1', 'l2', 'l5'], ['l2', 'l4'], ['l2', 'l3'],
['l1', 'l2', 'l4'], ['l1', 'l3'], ['l2', 'l3'],
['l1', 'l3'], ['l1', 'l2', 'l3', 'l5'], ['l1', 'l2', 'l3']]
return data_set
def create_C1(data_set):
"""
Create frequent candidate 1-itemset C1 by scaning data set.
Args:
data_set: A list of transactions. Each transaction contains several items.
Returns:
C1: A set which contains all frequent candidate 1-itemsets
"""
C1 = set()
for t in data_set:
for item in t:
item_set = frozenset([item])
C1.add(item_set)
return C1
def is_apriori(Ck_item, Lksub1):
"""
Judge whether a frequent candidate k-itemset satisfy Apriori property.
Args:
Ck_item: a frequent candidate k-itemset in Ck which contains all frequent
candidate k-itemsets.
Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.
Returns:
True: satisfying Apriori property.
False: Not satisfying Apriori property.
"""
for item in Ck_item:
sub_Ck = Ck_item - frozenset([item])
if sub_Ck not in Lksub1:
return False
return True
def create_Ck(Lksub1, k):
"""
Create Ck, a set which contains all all frequent candidate k-itemsets
by Lk-1's own connection operation.
Args:
Lksub1: Lk-1, a set which contains all frequent candidate (k-1)-itemsets.
k: the item number of a frequent itemset.
Return:
Ck: a set which contains all all frequent candidate k-itemsets.
"""
Ck = set()
len_Lksub1 = len(Lksub1)
list_Lksub1 = list(Lksub1)
for i in range(len_Lksub1):
for j in range(1, len_Lksub1):
l1 = list(list_Lksub1[i])
l2 = list(list_Lksub1[j])
l1.sort()
l2.sort()
if l1[0:k-2] == l2[0:k-2]:
Ck_item = list_Lksub1[i] | list_Lksub1[j]
# pruning
if is_apriori(Ck_item, Lksub1):
Ck.add(Ck_item)
return Ck
def generate_Lk_by_Ck(data_set, Ck, min_support, support_data):
"""
Generate Lk by executing a delete policy from Ck.
Args:
data_set: A list of transactions. Each transaction contains several items.
Ck: A set which contains all all frequent candidate k-itemsets.
min_support: The minimum support.
support_data: A dictionary. The key is frequent itemset and the value is support.
Returns:
Lk: A set which contains all all frequent k-itemsets.
"""
Lk = set()
item_count = {
}
for t in data_set:
for item in Ck:
if item.issubset(t):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
t_num = float(len(data_set))
for item in item_count:
if (item_count[item] / t_num) >= min_support:
Lk.add(item)
support_data[item] = item_count[item] / t_num
return Lk
def generate_L(data_set, k, min_support):
"""
Generate all frequent itemsets.
Args:
data_set: A list of transactions. Each transaction contains several items.
k: Maximum number of items for all frequent itemsets.
min_support: The minimum support.
Returns:
L: The list of Lk.
support_data: A dictionary. The key is frequent itemset and the value is support.
"""
support_data = {
}
C1 = create_C1(data_set)
L1 = generate_Lk_by_Ck(data_set, C1, min_support, support_data)
Lksub1 = L1.copy()
L = []
L.append(Lksub1)
for i in range(2, k+1):
Ci = create_Ck(Lksub1, i)
Li = generate_Lk_by_Ck(data_set, Ci, min_support, support_data)
Lksub1 = Li.copy()
L.append(Lksub1)
return L, support_data
def generate_big_rules(L, support_data, min_conf):
"""
Generate big rules from frequent itemsets.
Args:
L: The list of Lk.
support_data: A dictionary. The key is frequent itemset and the value is support.
min_conf: Minimal confidence.
Returns:
big_rule_list: A list which contains all big rules. Each big rule is represented
as a 3-tuple.
"""
big_rule_list = []
sub_set_list = []
for i in range(0, len(L)):
for freq_set in L[i]:
for sub_set in sub_set_list:
if sub_set.issubset(freq_set):
conf = support_data[freq_set] / support_data[freq_set - sub_set]
big_rule = (freq_set - sub_set, sub_set, conf)
if conf >= min_conf and big_rule not in big_rule_list:
# print freq_set-sub_set, " => ", sub_set, "conf: ", conf
big_rule_list.append(big_rule)
sub_set_list.append(freq_set)
return big_rule_list
if __name__ == "__main__":
"""
Test
"""
data_set = load_data_set()
L, support_data = generate_L(data_set, k=3, min_support=0.2)
big_rules_list = generate_big_rules(L, support_data, min_conf=0.7)
for Lk in L:
print "="*50
print "frequent " + str(len(list(Lk)[0])) + "-itemsets\t\tsupport"
print "="*50
for freq_set in Lk:
print freq_set, support_data[freq_set]
print
print "Big Rules"
for item in big_rules_list:
print item[0], "=>", item[1], "conf: ", item[2]
6.3 FP-growth算法
FP-growth(Frequent Pattern Tree, 频繁模式树),是韩家炜老师提出的挖掘频繁项集的方法,是将数据集存储在一个特定的称作FP树的结构之后发现频繁项集或频繁项对,即常在一块出现的元素项的集合FP树。
FP-growth算法比Apriori算法效率更高,在整个算法执行过程中,只需遍历数据集2次,就能够完成频繁模式发现,其发现频繁项集的基本过程如下:
(1)构建FP树
(2)从FP树中挖掘频繁项集
6.3.1 FP-growth算法步骤

FP-growth的一般流程如下:
1:先扫描一遍数据集,得到频繁项为1的项目集,定义最小支持度(项目出现最少次数),删除那些小于最小支持度的项目,然后将原始数据集中的条目按项目集中降序进行排列。
2:第二次扫描,创建项头表(从上往下降序),以及FP树。
3:对于每个项目(可以按照从下往上的顺序)找到其条件模式基(CPB,conditional patten base),递归调用树结构,删除小于最小支持度的项。如果最终呈现单一路径的树结构,则直接列举所有组合;非单一路径的则继续调用树结构,直到形成单一路径即可。
6.3.2 FP-growth算法代码
- FP树的类定义
// An highlighted block
class treeNode:
def __init__(self, nameValue, numOccur, parentNode):
self.name = nameValue #节点名字
self.count = numOccur #节点计数值
self.nodeLink = None #用于链接相似的元素项
self.parent = parentNode #needs to be updated
self.children = {
} #子节点
def inc(self, numOccur):
'''
对count变量增加给定值
'''
self.count += numOccur
def disp(self, ind=1):
'''
将树以文本形式展示
'''
print (' '*ind, self.name, ' ', self.count)
for child in self.children.values():
child.disp(ind+1)
2、FP树构建函数
// An highlighted block
def createTree(dataSet, minSup=1):
'''
创建FP树
'''
headerTable = {
}
#第一次扫描数据集
for trans in dataSet:#计算item出现频数
for item in trans:
headerTable[item] = headerTable.get(item, 0) + dataSet[trans]
headerTable = {
k:v for k,v in headerTable.items() if v >= minSup}
freqItemSet = set(headerTable.keys())
#print ('freqItemSet: ',freqItemSet)
if len(freqItemSet) == 0: return None, None #如果没有元素项满足要求,则退出
for k in headerTable:
headerTable[k] = [headerTable[k], None] #初始化headerTable
#print ('headerTable: ',headerTable)
#第二次扫描数据集
retTree = treeNode('Null Set', 1, None) #创建树
for tranSet, count in dataSet.items():
localD = {
}
for item in tranSet: #put transaction items in order
if item in freqItemSet:
localD[item] = headerTable[item][0]
if len(localD) > 0:
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)]
updateTree(orderedItems, retTree, headerTable, count)#将排序后的item集合填充的树中
return retTree, headerTable #返回树型结构和头指针表
def updateTree(items, inTree, headerTable, count):
if items[0] in inTree.children:#检查第一个元素项是否作为子节点存在
inTree.children[items[0]].inc(count) #存在,更新计数
else: #不存在,创建一个新的treeNode,将其作为一个新的子节点加入其中
inTree.children[items[0]] = treeNode(items[0], count, inTree)
if headerTable[items[0]][1] == None: #更新头指针表
headerTable[items[0]][1] = inTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1:#不断迭代调用自身,每次调用都会删掉列表中的第一个元素
updateTree(items[1::], inTree.children[items[0]], headerTable, count)
def updateHeader(nodeToTest, targetNode):
'''
this version does not use recursion
Do not use recursion to traverse a linked list!
更新头指针表,确保节点链接指向树中该元素项的每一个实例
'''
while (nodeToTest.nodeLink != None):
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
3、抽取条件模式基
// An highlighted block
def ascendTree(leafNode, prefixPath): #迭代上溯整棵树
if leafNode.parent != None:
prefixPath.append(leafNode.name)
ascendTree(leafNode.parent, prefixPath)
def findPrefixPath(basePat, treeNode): #treeNode comes from header table
condPats = {
}
while treeNode != None:
prefixPath = []
ascendTree(treeNode, prefixPath)
if len(prefixPath) > 1:
condPats[frozenset(prefixPath[1:])] = treeNode.count
treeNode = treeNode.nodeLink
return condPats
4、递归查找频繁项集
// An highlighted block
def mineTree(inTree, headerTable, minSup, preFix, freqItemList):
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1][0])]# 1.排序头指针表
for basePat in bigL: #从头指针表的底端开始
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
print ('finalFrequent Item: ',newFreqSet) #添加的频繁项列表
freqItemList.append(newFreqSet)
condPattBases = findPrefixPath(basePat, headerTable[basePat][1])
print ('condPattBases :',basePat, condPattBases)
# 2.从条件模式基创建条件FP树
myCondTree, myHead = createTree(condPattBases, minSup)
# print ('head from conditional tree: ', myHead)
if myHead != None: # 3.挖掘条件FP树
print ('conditional tree for: ',newFreqSet)
myCondTree.disp(1)
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
链接: https://blog.csdn.net/baixiangxue/article/details/80335469
6.4 压缩频繁项集
6.4.1 挖掘闭模式
6.4.2 枝剪的策略
6.5 关联模式评估
6.5.1 支持度与置信度框架
6.5.2 相关性分析
1、提升度
2、杠杆度
3、皮尔森相关系数
4、IS度量
5、确信度
6.5.3 模式评估度量
1、全置信度
2、极大置信度
3、Kulczynski度量
7.1 分类概述
分类:
分类与预测:
7.2 决策树
决策树是一种常见的机器学习算法,它的思想十分朴素,类似于我们平时利用选择做决策的过程。 父节点和子节点是相对的,说白了子节点由父节点根据某一规则分裂而来,然后子节点作为新的父亲节点继续分裂,直至不能分裂为止。而根节点是没有父节点的节点,即初始分裂节点,叶子节点是没有子节点的节点,如下图所示:

链接: https://blog.csdn.net/jiaoyangwm/article/details/79525237
7.2.1 决策树上
结构
显然,决策树在逻辑上以树的形式存在,包含根节点、内部结点和叶节点。
- 根节点:包含数据集中的所有数据的集合
- 内部节点:每个内部节点为一个判断条件,并且包含数据集中满足从根节点到该节点所有条件的数据的集合。根据内部结点的判断条件测试结果,内部节点对应的数据的集合别分到两个或多个子节点中。
- 叶节点:叶节点为最终的类别,被包含在该叶节点的数据属于该类别。
简而言之,决策树是一个利用树的模型进行决策的多分类模型,简单有效,易于理解。
伪代码
决策树算法的伪代码(参照了python语法)如下图所示:
// An highlighted block
# D = {
(x1,y1)、(x2,y2)......(xm,yn)} 是数据集
# A = {
a1、a2、a3.} 是划分节点的属性集
# 节点node有两个主要属性:content代表该节点需要分类的训练集,type代表叶节点的决策类型
def generateTree(D,A):
newNode = 空 #生成新的节点
# 如果当前数据集都为一个种类,则设为一个叶节点并返回
if D 中数据皆属于类别 C:
newNode.content = D
newNode.type = C
return
# 如果已经没有属性了或者数据集在剩余属性中表现相同(属性无法区分)
if A = 空集 or D中数据在A中取值相同:
newNode.content = D
newNode.type = D中最多的类
return
#从A中选取最优的属性a
a=selectBestPorperty(A)
#为a的每一个取值生成一个节点,递归进行处理
for a的每一个取值 res[i]:
生成新的分支节点 node[i]
D[i] = D中取值为res[i]的数据
node[i].content = D[i]
if node[i].content == null:
node[i].type = D中最多的类
else:
generateTree(D[i],A - {
a})
return
7.2.2 决策树中
ID3算法
7.2.3 决策树下
C4.5算法
7.3 朴素贝叶斯分类
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
链接: https://blog.csdn.net/qq_17073497/article/details/81076250
7.4 惰性学习法
惰性学习方法也叫消极学习方法,这种学习方法在最开始的时候不会根据已有的样本创建目标函数,只是简单的把训练用的样本储存好,后期需要对新进入的样本进行判断的时候才开始分析新进入样本与已存在的训练样本之间的关系,并据此确定新实例(新进入样本)的目标函数值.
7.4.1 惰性学习法的概念
消极学习的典型算法KNN,KNN不会根据训练集主动学习或者拟合出一个函数来对新进入的样本进行判断,而是单纯的记住训练集中所有的样本,并没有像上边决策树那样先对训练集数据进行训练得出一套规则,所以它实际上没有所谓的"训练"过程,而是在需要进行预测的时候从自己的训练集样本中查找与新进入样本最相似的样本,即寻找最近邻来获得预测结果
7.4.2 K近邻算法
KNN是通过测量不同特征值之间的距离进行分类。它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
K近邻算法详解: https://blog.csdn.net/wangmumu321/article/details/78576916
k-近邻算法梳理(从原理到示例): https://blog.csdn.net/kun_csdn/article/details/88919091
7.5 神经网络
深度学习500问: https://github.com/runningreader/DeepLearning-500-questions
7.5.1 神经网络基本概念
神经网络是一门重要的机器学习技术。它是目前最为火热的研究方向–深度学习的基础。学习神经网络不仅可以让你掌握一门强大的机器学习方法,同时也可以更好地帮助你理解深度学习技术。
本文以一种简单的,循序的方式讲解神经网络。适合对神经网络了解不多的同学。本文对阅读没有一定的前提要求,但是懂一些机器学习基础会更好地帮助理解本文。
神经网络是一种模拟人脑的神经网络以期能够实现类人工智能的机器学习技术。人脑中的神经网络是一个非常复杂的组织。成人的大脑中估计有1000亿个神经元之多。
神经网络——最易懂最清晰的一篇文章: https://blog.csdn.net/illikang/article/details/82019945
7.5.2 BP神经网络算法
1、后向传播
2、算法步骤
神经网络之BP算法(图说神经网络+BP算法理论推导+例子运用+代码): https://blog.csdn.net/weixin_39441762/article/details/80446692.
7.6 分类模型的评估
评估分类是判断预测值时否很好的与实际标记值相匹配。正确的鉴别出正样本(True Positives)或者负样本(True Negatives)都是True。同理,错误的判断正样本(False Positive,即一类错误)或者负样本(False Negative,即二类错误)。
注意:True和False是对于评价预测结果而言,也就是评价预测结果是正确的(True)还是错误的(False)。而Positive和Negative则是样本分类的标记。
分类模型评估: https://www.jianshu.com/p/e8b688f796d8
7.6.1 准确率

7.6.2 召回率

7.6.3 灵敏度、特效率

7.6.4 F值

7.6.5 交叉验证
8.1 聚类概述
1、聚类是一种机器学习技术,它涉及到数据点的分组。给定一组数据点,我们可以使用聚类算法将每个数据点划分为一个特定的组。理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征。聚类是一种无监督学习的方法,是许多领域中常用的统计数据分析技术。
在数据科学中,我们可以使用聚类分析从我们的数据中获得一些有价值的见解。
2、聚类的目标
使同一类对象的相似度尽可能地大;不同类对象之间的相似度尽可能地小。
3、聚类和分类的区别
聚类技术通常又被称为无监督学习,因为与监督学习不同,在聚类中那些表示数据类别的分类或者分组信息是没有的。
Clustering (聚类),简单地说就是把相似的东西分到一组,聚类的时候,我们并不关心某一类是什么,我们需要实现的目标只是把相似的东西聚到一起。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了,因此 clustering 通常并不需要使用训练数据进行学习,这在Machine Learning中被称作unsupervised learning (无监督学习)。
Classification (分类),对于一个classifier,通常需要你告诉它“这个东西被分为某某类”这样一些例子,理想情况下,一个 classifier 会从它得到的训练集中进行“学习”,从而具备对未知数据进行分类的能力,这种提供训练数据的过程通常叫做supervised learning (监督学习)。
8.2 基于划分的聚类
8.2.1 K均值算法

8.2.2 K-中心点(PAM)算法

8.3 基于层次的聚类
层次聚类(Hierarchical Clustering)是聚类算法的一种,通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。创建聚类树有自下而上合并和自上而下分裂两种方法。

// An highlighted block
import numpy as np
import matplotlib.pyplot as plt
'''
AGNES层次聚类,采用自底向上聚合策略的算法。先将数据集的每个样本看做一个初始的聚类簇,然后算法运行的每一步中找出距离最近的两个
类簇进行合并,该过程不断重复,直至达到预设的聚类簇的个数。
'''
#计算两个向量之间的欧式距离
def calDist(X1 , X2 ):
sum = 0
for x1 , x2 in zip(X1 , X2):
sum += (x1 - x2) ** 2
return sum ** 0.5
def updateClusterDis(dataset,distance,sets,cluster_i):
i=0
while i<len(sets):
dis = []
for e in sets[i]:
for ele in sets[cluster_i]:
dis.append(calDist(dataset[e],dataset[ele]))
distance[i,cluster_i]=max(dis)
distance[cluster_i,i]=max(dis)
i+=1
#将每个簇和自身距离设为无穷大
distance[np.diag_indices_from(distance)] = float('inf')
return distance
def agens(dataset,k):
#初始化聚类簇:让每一个点都代表,一个类簇
sets=[]
for i in range(0,len(dataset)):
sets.append({
i})
#初始化类簇间距离的矩阵
delta = np.array(dataset[0] - dataset)
for e in dataset[1:, :]:
delta = np.vstack((delta, (e - dataset)))
distance = np.sqrt(np.sum(np.square(delta), axis=1))
distance = np.reshape(distance, (len(dataset), len(dataset)))
distance[np.diag_indices_from(distance)]=float('inf')
####################################################
while len(sets)>k:
locations=np.argwhere(distance==np.min(distance))
#将集合合并,删除被合并的集合
locations=locations[locations[:,0]<locations[:,1]]
cluster_i=locations[0,0]
cluster_j=locations[0,1]
for e in sets[cluster_j]:
sets[cluster_i].add(e)
del sets[cluster_j]
#删除被合并的簇,distance矩阵对应的行和列,并更新距离矩阵
distance=np.delete(distance,cluster_j,axis=0)#删除对应列
distance=np.delete(distance,cluster_j,axis=1)#删除对应行
distance=updateClusterDis(dataset,distance,sets,cluster_i)
print(sets)
return sets
8.4 基于网格的聚类
将数据空间划分成为有限个单元(cell)的网格结构,所有的处理都是以单个的单元为对象的。
特点:处理速度很快,通常这是与目标数据库中记录的个数无关的,只与把数据空间分为多少个单元有关。
算法:STING算法、CLIQUE算法、WAVE-CLUSTER算法
1) STING:统计信息网格
STING是一种基于网格的多分辨率的聚类技术,它将输入对象的空间区域划分成矩形单元,空间可以用分层和递归方法进行划分。这种多层矩形单元对应不同的分辨率,并且形成了一个层次结构:每个高层单元被划分成低一层的单元。关于每个网格单元的属性的统计信息(如均值,最大值和最小值)被作为统计参数预先计算和存储。对于查询处理和其他数据分析任务,这些统计参数是有效的。
STING算法:
(1) 针对不同的分辨率,通常有多个级别的矩形单元。
(2) 这些单元形成了一个层次结构,高层的每个单元被划分成多个底一层的单元。
(3) 关于每个网格单元属性的统计信息(例如平均值,max,min)被预先计算和存储,这些统计信息用于回答查询。(统计信息是进行查询使用的)
网格中常用的参数:
(1) count 网格中对象数目
(2) mean网格中所有值的平均值
(3) stdev网格中属性值的标准偏差
(4) min 网格中属性值的最小值
(5) max 网格中属性值的最大值
(6) distribution 网格中属性值符合的分布类型。如正态分布,均匀分布
STING聚类的层次结构:
注意:当数据加载到数据库时。最底层的单元参数直接由数据计算,若分布类型知道,可以用户直接指定。而较高层的单元的分布类型可以基于它对应的低层单元多数的分布类型,用一个阈值过滤过程的合取来计算,若底层分布类型彼此不同,那么高层分布类型为none
STING查询算法步骤:
(1) 从一个层次开始
(2) 对于这一个层次的每个单元格,我们计算查询相关的属性值。
(3) 从计算的属性值以及约束条件下,我们将每一个单元格标记成相关或者不想关。(不相关的单元格不再考虑,下一个较低层的处理就只检查剩余的相关单元)
(4) 如果这一层是底层,那么转(6),否则转(5)
(5) 我们由层次结构转到下一层,依照步骤2进行
(6) 查询结果得到满足,转到步骤8,否则(7)
(7) 恢复数据到相关的单元格进一步处理以得到满意的结果,转到步骤(8)
(8) 停止
到这儿,STING算法应该基本就差不多了,其核心思想就是:根据属性的相关统计信息进行划分网格,而且网格是分层次的,下一层是上一层的继续划分。在一个网格内的数据点即为一个簇。
同时,STING聚类算法有一个性质:如果粒度趋向于0(即朝向非常底层的数据),则聚类结果趋向于DBSCAN聚类结果。即使用计数count和大小信息,使用STING可以近似的识别稠密的簇。
STING算法的优点:
(1) 基于网格的计算是独立于查询的,因为存储在每个单元的统计信息提供了单元中数据汇总信息,不依赖于查询。
(2) 网格结构有利于增量更新和并行处理。
(3) 效率高。STING扫描数据库一次开计算单元的统计信息,因此产生聚类的时间复杂度为O(n),在层次结构建立之后,查询处理时间为)O(g),其中g为最底层网格单元的数目,通常远远小于n。
缺点:
(1) 由于STING采用了一种多分辨率的方法来进行聚类分析,因此STING的聚类质量取决于网格结构的最底层的粒度。如果最底层的粒度很细,则处理的代价会显著增加。然而如果粒度太粗,聚类质量难以得到保证。
(2) STING在构建一个父亲单元时没有考虑到子女单元和其他相邻单元之间的联系。所有的簇边界不是水平的,就是竖直的,没有斜的分界线。降低了聚类质量。
9.1 离群点定义和类型
离群点:离群点是指一个时间序列中,远离序列的一般水平的极端大值和极端小值。
链接: https://blog.csdn.net/qq_19446965/article/details/89395190.
离群点是一个数据对象,它显著不同于其他数据对象,好像它是被不同的机制产生的一样。有时也称非离群点为“正常数据”,离群点为“异常数据”。
离群点不同于噪声数据。噪声是被观测变量的随机误差或方差。一般而言,噪声在数据分析(包括离群点分析)中不是令人感兴趣的。如在信用卡欺诈检测,顾客的购买行为可以用一个随机变量建模。一位顾客可能会产生某些看上去像“随机误差”或“方差”的噪声交易,如买一份较丰盛的午餐,或比通常多要了一杯咖啡。这种交易不应该视为离群点,否则信用卡公司将因验证太多的交易而付出沉重代价。因此,与许多其他数据分析和数据挖掘任务一样,应该在离群点检测前就删除噪声。
离群点检测是有趣的,因为怀疑产生它们的机制不同于产生其他数据的机制。因此,在离群点检测时,重要的是搞清楚为什么检测到的离群点被某种其他机制产生。通常,在其余数据上做各种假设,并且证明检测到的离群点显著违反了这些假设。
9.2 离群点检测
9.2.1 离群点的类型
一般而言,离群点可以分成三类:全局离群点、情境(或条件)离群点和集体离群点。
全局离群点
在给定的数据集中,一个数据对象是全局离群点,如果它显著的偏离数据集中的其他对象。全局离群点是最简单的一类离群点,大部分的离群点检测方法都旨在找出全局离群点。
情境离群点
在给定的数据集中,一个数据对象是情境离群点,如果关于对象的特定情境,它显著的偏离其他对象。情境离群点又称为条件离群点,因为它们条件的依赖于选定的情境。一般地,在情境离群点检测中,所考虑数据对象的属性划分成两组:
Ÿ 情境属性:数据对象的情境属性定义对象的情境。一般为静态属性变量,如信用卡欺诈检测中,不同年龄、不同地区的人消费情况是不同的,先按照静态属性将人群大致分类,再检测每一类的离群点,会得到更好的结果。
Ÿ 行为属性:定义对象的特征,并用来评估对象关于它所处的情境是否为离群点。在上述例子中,行为属性可以是消费金额,消费频率等
情境离群点分析为用户提供了灵活性,因为用户可以在不同情境下考察离群点,这在许多应用中都是非常期望的。
集体离群点
给定一个数据集,数据对象的一个子集形成集体离群点,如果这些对象作为整体显著的偏离整个数据集。如一家供应链公司,每天处理数以千计的订单和出货。如果一个订单的出货延误,则可能不是离群点,因为统计表明延误时常发生。然而,如果有一天有100个订单延误,则必须注意。这100个订单整体来看,形成一个离群点,尽管如果单个考虑,它们每个或许都不是离群点。你可能需要更详细地整个考察这些订单,搞清楚出货问题。
与全局和情境离群点检测不同,在集体离群点检测中,不仅必须考虑个体对象的行为,而且还要考虑对象组群的行为。因此,为了检测集体离群点,需要关于对象之间联系的背景知识,如对象之间的距离或相似性测量方法。
9.2.2 离群点检测方法
统计学方法
离群点检测的统计学方法对数据的正常性做假定。假定数据集中的正常对象由一个随机过程(生成模型)产生。因此,正常对象出现在该随机模型的高概率区域中,而低概率区域中的对象是离群点。
离群点检测的统计学方法的一般思想是:学习一个拟合给定数据集的生成模型,然后识别该模型低概率区域中的对象,把它们作为离群点。有许多不同方法来学习生成模型,一般而言,根据如何指定和如何学习模型,离群点检测的统计学方法可以划分成两个主要类型:参数方法和非参数方法。
参数方法假定正常的数据对象被一个以为参数的参数分布产生。该参数分布的概率密度函数给出对象被该分布产生的概率。该值越小,越可能是离群点。
非参数方法并不假定先验统计模型,而是试图从输入数据确定模型。非参数方法的例子包括直方图和核密度估计。
参数方法
1、基于正态分布的一元离群点检测
假定数据集由一个正态分布产生,然后,可以由输入数据学习正态分布的参数,并把低概率的点识别为离群点。
在正态分布的假定下,区域包含99.7%的数据,包含95.4%的数据,包含68.3%的数据。视具体情况而定,将其区域外的数据视为离群点。
这种直截了当的统计学离群点检测方法也可以用于可视化。例如盒图方法使用五数概况绘制一元输入数据:最小的非离群点值(Min)、第一个四分位数(Q1)、中位数(Q2)、第三个四分位数(Q3)和最大的非离群点值(Max)。
四分位数极差(IQR)定义为Q3-Q1。比Q1小1.5倍的IQR或者比Q3大1.5倍的IQR的任何对象都视为离群点,因为Q1-1.5IQR和Q3+1.5IQR之间的区域包含了99.3%的对象。
2、多元离群点检测
(1)使用马哈拉诺比斯距离检测多元离群点。
对于一个多元数据集,设为均值向量。对于数据集中的对象,从到的马哈拉诺比斯(Mahalanobis)距离为
其中S是协方差矩阵。
是一元数据,可以对它进行离群点检测。如果被确定为离群点,则也被视为离群点。
(2)使用统计量的多元离群点检测。
在正态分布的假设下,统计量可以用来捕获多元离群点。对于对象,统计量是
其中,是在第维上的值,是所有对象在第维上的均值,而是维度。如果对象的统计量很大,则该对象是离群点。
(3)使用混合参数分布
在许多情况下,数据是由正态分布产生的假定很有效。然而,当实际数据很复杂时,这种假定过于简单。在这种情况下,假定数据是被混合参数分布产生的。
混合参数分布中用期望最大化(EM)算法来估计参数。具体情况比较复杂,可以参考韩家炜的《数据挖掘:概念与技术》一书。
非参数方法
在离群点检测的非参数方法中,“正常数据”的模型从输入数据学习,而不是假定一个先验。通常,非参数方法对数据做较少假定,因而在更多情况下都可以使用。
使用直方图检测离群点
包括如下两步:
步骤1:构造直方图。尽管非参数方法并不假定任何先验统计模型,但是通常确实要求用户提供参数,以便由数据学习。如指定直方图的类型(等宽或等深的)和其他参数(如直方图中的箱数或每个箱的大小)。与参数方法不同,这些参数并不指定数据分布的类型(如高斯分布)。
步骤2:检测离群点。为了确定一个对象是否是离群点,可以对照直方图检验它。在最简单的方法中,如果该对象落入直方图的一个箱中,则该对象被看做是正常的,否则被认为是离群点。
对于更复杂的方法,可以使用直方图赋予每个对象一个离群点得分。一般可以令对象的离群点得分为该对象落入的箱的容积的倒数。得分越高,表明是离群点的概率越大。
使用直方图作为离群点检测的非参数模型的一个缺点是,很难选择一个合适的箱尺寸。一方面,如箱尺寸太小,则由很多正常对象都会落入空的或稀疏箱,因而被误识别为离群点。这将导致很高的假正例率或低精度。相反,如果箱尺寸太大,则离群点对象可能渗入某些频繁的箱中,这将导致很高的假负例率或召回率。为了解决这些问题,使用核密度估计来估计数据的概率密度分布。具体参考韩家炜的《数据挖掘:概念与技术》。
基于邻近性的方法
给定特征空间中的对象集,可以使用距离度量来量化对象间的相似性。基于邻近性的方法假定:离群点对象与它最近邻的邻近性显著偏离数据集中其他对象与它们近邻之间的邻近性。
基于聚类的方法
基于聚类的方法通过考察对象与簇之间的关系检测离群点。直观地,离群点是一个对象,它属于小的偏远簇,或不属于任何簇。
这导致三种基于聚类的离群点检测的一般方法。考虑一个对象。
l 该对象属于某个簇吗?如果不,则它被识别为离群点。
l 该对象与最近的簇之间的距离很远吗?如果是,则它是离群点。
l 该对象是小簇或稀疏簇的一部分吗?如果是,则该簇中的所有对象都是离群点。