前提条件:
- 已经安装了win10 的desktop 版本的docker和kubernetes
- kubernetes上已经装了ingress
以下步骤参考自:
https://testdriven.io/blog/deploying-spark-on-kubernetes/
- spark docker image:
Dockerfile:
FROM java:openjdk-8-jdk
# define spark and hadoop versions
ENV SPARK_VERSION=3.0.0
ENV HADOOP_VERSION=3.3.0
# download and install hadoop
RUN mkdir -p /opt && \
cd /opt && \
curl http://archive.apache.org/dist/hadoop/common/hadoop-${HADOOP_VERSION}/hadoop-${HADOOP_VERSION}.tar.gz | \
tar -zx hadoop-${HADOOP_VERSION}/lib/native && \
ln -s hadoop-${HADOOP_VERSION} hadoop && \
echo Hadoop ${HADOOP_VERSION} native libraries installed in /opt/hadoop/lib/native
# download and install spark
RUN mkdir -p /opt && \
cd /opt && \
curl http://archive.apache.org/dist/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop2.7.tgz | \
tar -zx && \
ln -s spark-${SPARK_VERSION}-bin-hadoop2.7 spark && \
echo Spark ${SPARK_VERSION} installed in /opt
# add scripts and update spark default config
ADD common.sh spark-master spark-worker /
ADD spark-defaults.conf /opt/spark/conf/spark-defaults.conf
ENV PATH $PATH:/opt/spark/bin
你可以在这在github的这个仓库里面找到对应的Dockerfile文件
仓库地址:https://github.com/testdrivenio/spark-kubernetes
编译image:
docker build -f docker/Dockerfile -t spark-hadoop:3.0.0 ./docker
如果不想要本地编译image的话,可以直接使用已经编译好的docker image,dockerhub上面image的名字是mjhea0/spark-hadoop:3.0.0
docker pull 下来使用docker tag命令rename成spark-hadoop:3.0.0 就行了
docker image ls spark-hadoop
REPOSITORY TAG IMAGE ID CREATED SIZE
spark-hadoop 3.0.0 8f3ccdadd795 11 minutes ago 911MB
Spark Master
spark-master-deployment.yaml:
kind: Deployment
apiVersion: apps/v1
metadata:
name: spark-master
spec:
replicas: 1
selector:
matchLabels:
component: spark-master
template:
metadata:
labels:
component: spark-master
spec:
containers:
- name: spark-master
image: spark-hadoop:3.0.0
command: ["/spark-master"]
ports:
- containerPort: 7077
- containerPort: 8080
resources:
requests:
cpu: 100m
spark-master-service.yaml:
kind: Service
apiVersion: v1
metadata:
name: spark-master
spec:
ports:
- name: webui
port: 8080
targetPort: 8080
- name: spark
port: 7077
targetPort: 7077
selector:
component: spark-master
部署spark master并且启动服务:
kubectl create -f ./kubernetes/spark-master-deployment.yaml
kubectl create -f ./kubernetes/spark-master-service.yaml
验证:
$ kubectl get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
spark-master 1/1 1 1 12s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
spark-master-6c4469fdb6-rs642 1/1 Running 0 6s
Spark Workers
spark-worker-deployment.yaml:
kind: Deployment
apiVersion: apps/v1
metadata:
name: spark-worker
spec:
replicas: 2
selector:
matchLabels:
component: spark-worker
template:
metadata:
labels:
component: spark-worker
spec:
containers:
- name: spark-worker
image: spark-hadoop:3.0.0
command: ["/spark-worker"]
ports:
- containerPort: 8081
resources:
requests:
cpu: 100m
部署
$ kubectl create -f ./kubernetes/spark-worker-deployment.yaml
验证:
NAME READY UP-TO-DATE AVAILABLE AGE
spark-master 1/1 1 1 92s
spark-worker 2/2 2 2 6s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
spark-master-6c4469fdb6-rs642 1/1 Running 0 114s
spark-worker-5d4bdd44db-p2q8v 1/1 Running 0 28s
spark-worker-5d4bdd44db-v4d84 1/1 Running 0 28s
Ingress
ingress 是用来设定了访问spark master的web界面的(github 仓库里面的代码是用来设定minikube的, 这边有所不同,ingress的版本要更新一点)
minikube-ingress.yaml(原始版):
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: minikube-ingress
annotations:
spec:
rules:
- host: spark-kubernetes
http:
paths:
- path: /
backend:
serviceName: spark-master
servicePort: 8080
minikube-ingress.yaml(修改版,适用于kubernetes 1.19 版本以后, ingress-controller 需要自己提前安装):
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: minimal-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: spark-master
port:
number: 8080
创建ingress对象:
$ kubectl apply -f ./kubernetes/minikube-ingress.yaml
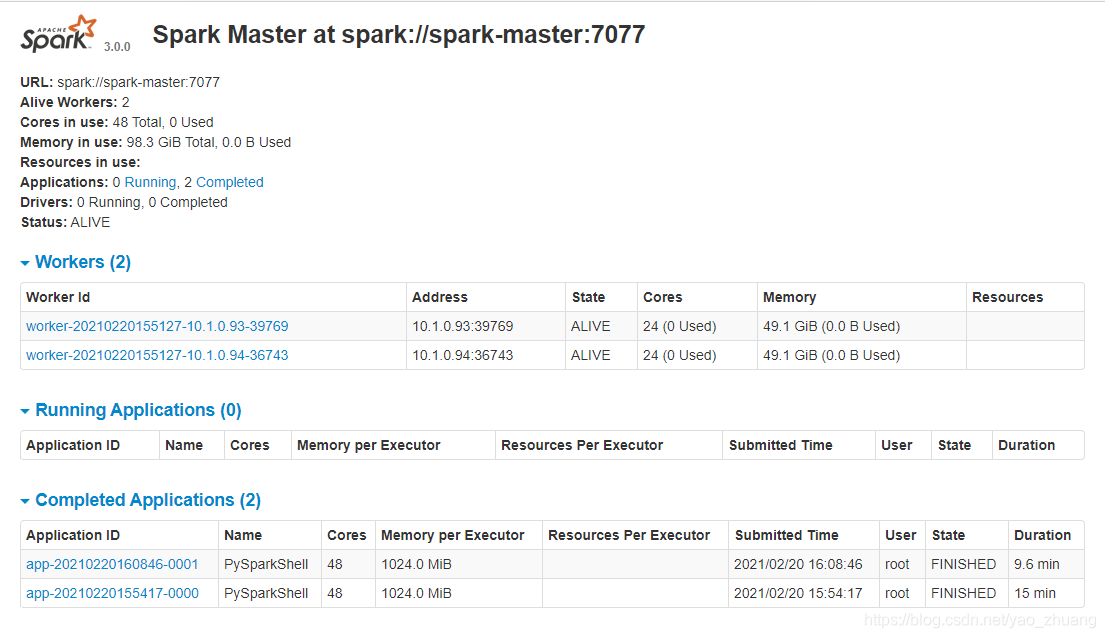
访问http://127.0.0.1就能看到spark master的管理界面了, 如下
测试
启动spark-master中的pyspark
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
spark-master-6c4469fdb6-rs642 1/1 Running 0 10m
spark-worker-5d4bdd44db-p2q8v 1/1 Running 0 8m42s
spark-worker-5d4bdd44db-v4d84 1/1 Running 0 8m42s
$ kubectl exec spark-master-6c4469fdb6-rs642 -it -- pyspark
words = 'the quick brown fox jumps over the\
lazy dog the quick brown fox jumps over the lazy dog'
seq = words.split()
data = spark.sparkContext.parallelize(seq)
counts = data.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b).collect()
dict(counts)
之后你可以看到下面的结果:
{'brown': 2, 'lazy': 2, 'over': 2, 'fox': 2, 'dog': 2, 'quick': 2, 'the': 4, 'jumps': 2}