public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello World.");
}
}我问他:“这段代码干嘛用的?”
他答道:“它会在屏幕上打印‘Hello World’。”
“public 是什么?class 是什么?static 是什么?……”
“先不要在意这些,它们都只是模板代码。”
但这些所谓的模板代码让我感到很疑惑,于是我开始了解这些关键字的意思。事实证明,这些复杂而无聊的东西给我年轻的编程梦想蒙上了一层阴影。
现在学习软件开发比我上高中时要容易得多,这要感谢像 codecademy.com 这样的网站,它们提供了基本的开发环境,倾向于教授解释型编程语言,比如 Python 和 Javascript。你可以在几分钟内从对编程一无所知变成能够写出第一条可以在浏览器上执行的条件语句。没有繁琐的环境设置、安装、编译器或样板代码——你直接进入编程最有趣的部分。
这是人类最好的学习方式。首先,我们被灌输高层次的核心概念,然后开始理解具体细节。我们先学习 Python,然后是 C 语言,然后是汇编,而不是反过来。
不幸的是,现在很多学习 ML 的人跟我第一次接触 Java 时的情况完全一样。他们最先被灌输所有的底层细节——分层架构、反向传播、dropout 等,然后会觉得 ML 很复杂,认为需要先掌握线性代数,最后就想着要放弃。
这个有点遗憾,因为在不久的将来,大多数 ML 开发人员将不再需要考虑或了解任何底层的东西,就像我们通常不需要编写汇编代码或自己实现 TCP 协议栈或加密库一样,ML 将成为我们的工具,工具的实现细节交给一小部分专家就可以了。到了这个时候——也就是在 ML 被“大众化”之后——开发人员需要了解的不是实现细节,而是如何部署这些智能算法。
ML 发展到了什么程度
现在,如果你想要开发一个神经网络来识别照片中的猫或者预测你的下一条推文是否会被疯传,可以学一下 TensorFlow 或 PyTorch。这些基于 Python 的深度学习库是目前最流行的设计神经网络的工具,它们都不到 5 岁。
在它短暂的生命周期中,TensorFlow 已经变得比 5 年前友好得多。在早期,要成为一个高效的 TensorFlow 程序员,你不仅要了解 ML,还要了解分布式计算和图架构。即使是写一个简单的打印语句也很费劲。
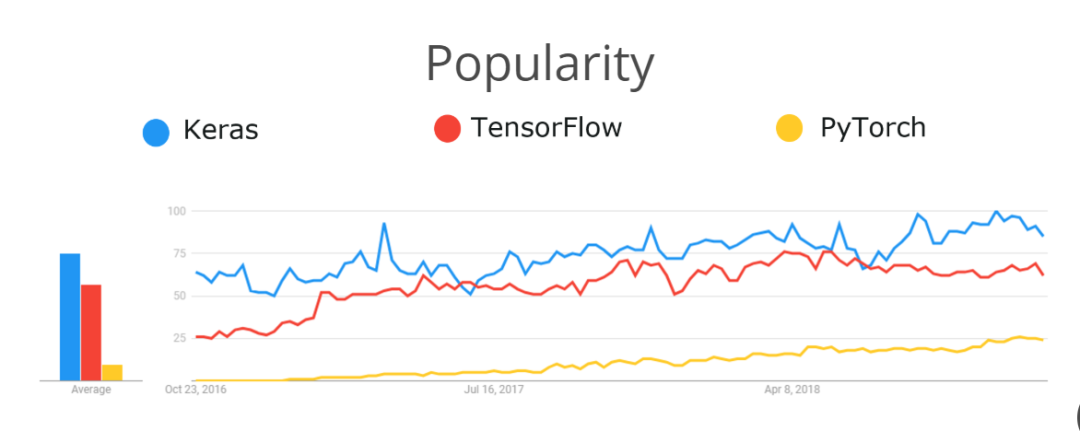
今年秋季,TensorFlow 2.0 正式发布,它对开发人员更加友好。下面是使用 TensorFlow 2.0 构建一个“Hello World”模型的代码:
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(1, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy'),
metrics=['accuracy']))
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)如果你以前设计过神经网络,就很容易看懂上面这段代码。但如果之前没学过,或者正在学习,可能就会有一些问题。比如,dropout 是什么意思?这些密集的层是什么东西?你需要多少层,应该把它们放在哪里?sparse_categorical_crossentropy 又是什么?TensorFlow 2.0 确实简化了构建模型时的一些繁文缛节,但并没有将模型的实际架构设计抽离出去。
未来会怎样
那么,ML 工具的未来会是什么样子呢?谷歌、亚马逊、微软和苹果公司的人都在花时间研究这个问题。另外,作为谷歌的一名工程师,我也花了很多时间思考这个问题。
首先,我们将会看到越来越多的开发人员使用预先训练好的模型来完成常见的任务。也就是说,我们将不再自己收集数据和训练神经网络,而是使用谷歌、亚马逊和微软提供的模型。很多云厂商已经在做类似的事情了。例如,你可以通过调用谷歌云的 REST 端点来使用预先训练好的神经网络,用它们来:
- 抽取图像中的文本;
- 标记照片中的物体;
- 把语音转成文本;
- 翻译不同的语言;
- 识别文本的情感色彩;
其他
你也可以使用谷歌的 ML Kit 或苹果的 Core ML 等工具在移动设备上运行预先训练好的模型。
坦率地说,与自己使用 TensorFlow 构建的模型相比,预先训练好的模型更加准确,因为它们是由谷歌研究人员基于整个互联网的数据训练出来的,他们使用了大量的 GPU 和 TPU。
预训练模型的缺点是,它们解决的是一般性问题,比如识别图像中的猫和狗,而不是特定领域的问题,比如识别装配线上某个部件的缺陷。
但即使是为特定领域的任务训练特定的模型,ML 工具对我们也很友好。
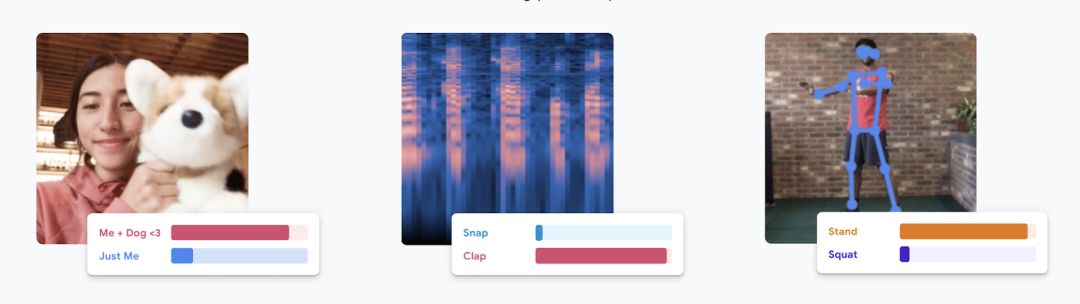 Teachable Machine——一个在浏览器中构建视觉、手势和语音模型的工具
Teachable Machine——一个在浏览器中构建视觉、手势和语音模型的工具
谷歌的 Teachable Machine 为用户提供了拖放式界面,可以直接在浏览器中收集数据和训练模型。今年早些时候,麻省理工学院发布了一个类似的无代码界面,用来构建在触摸屏设备上运行的模型,这个界面是为医生等非编程人员设计的。微软和一些初创公司(lobe.ai)也提供了类似的解决方案。Google Cloud AutoML 是一个企业级的自动化模型训练框架。
现在要学些什么
随着 ML 工具变得越来越容易使用,(不需要成为专家的)开发人员的技能也将发生变化。所以,你现在应该学些什么?
要知道什么时候该用 ML 并不容易
ML 算法与其他软件的不同之处在于它们具有概率性。即使是一个高度精确的模型有时也会出错,这意味着它并不是很多问题的正确解决方案。以基于 ML 的语音到文本转换算法为例:有时候,你想让 Alexa“关掉音乐”,它却帮你把闹钟调到凌晨 4 点。如果医学版的 Alexa 把医生说的 Adderall(一种治疗多动症的药)误解成 Enulose(一种缓泻药),那就糟糕了。
知道何时以及如何在生产环境中使用 ML 模型始终是一个难题,在这些情况下尤为如此:
- 风险很高;
- 人力资源有限;
人类有偏见,预测不准确。
以医学成像为例。现在全球范围内都很缺医生,而 ML 模型在诊断疾病方面往往比训练有素的医生更准确,但你会希望让一个算法来决定你是否患有癌症吗?用于帮助法官判决刑期的 ML 模型也类似。模型是有偏见的,人也是。
知道什么时候可以使用 ML 以及如何正确地部署 ML 模型并不是一件容易的事情,而这个问题不会很快得到解决。
可解释性
众所周知,ML 模型是不透明的,所以它们有时候也被叫作“黑匣子”。如果你只是把“这是我的神经网络告诉我的”作为唯一的证据,就不太可能说服你的副总裁做出重大的商业决策。另外,如果你不明白为什么你的模型会做出这样的预测,也可能就意识不到它会做出有偏见的决定(例如,拒绝贷款给特定年龄层或属于某个邮政编码区域的人)。
正因为如此,ML 领域的很多参与者都专注于构建“可解释的 AI”特征工具——可以让用户检查模型使用了什么特征进行预测。但从整个行业的角度来看,我们还没有完全解决这个问题,不过我们正在取得进展。11 月份,谷歌发布了一套可解释性工具和 Model Cards——一种帮助用户理解 ML 模型局限性的可视化指南。
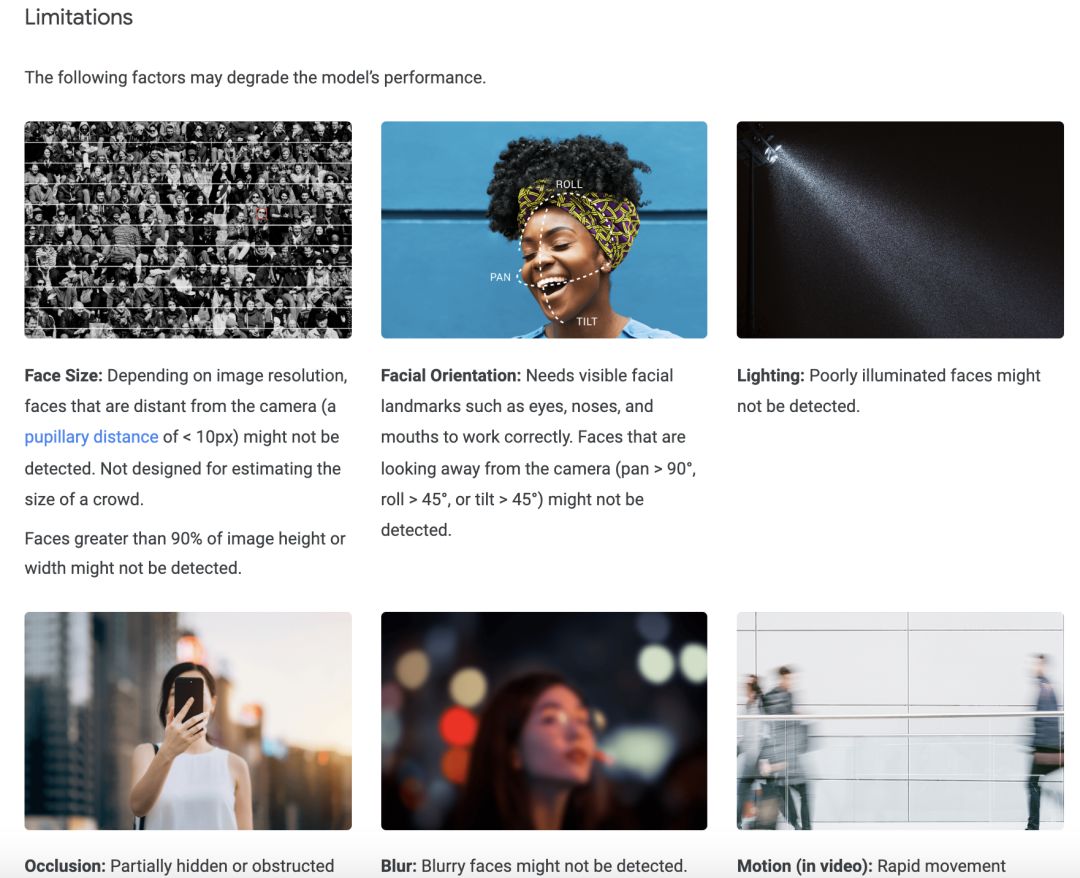 谷歌的脸部识别 Model Card 显示了该模型的局限
谷歌的脸部识别 Model Card 显示了该模型的局限
创造性的应用
有些开发人员擅长机器学习,有些研究人员擅长神经科学,但很少有人同时精通这两个领域。这个问题几乎在任何复杂的领域中都存在。未来几年,ML 的主要进步可能不是数学方法方面的改进,而是来自不同专业领域的人学会了足够多的机器学习知识,并将其应用到他们的领域中。例如,医学成像领域最令人感到兴奋的突破——通过扫描就能发现有害疾病——并不是因为应用了新的神经网络架构,而是因为将标准模型应用在了新奇的问题上。因此,如果你是一名软件开发人员,并且掌握了额外的专业知识,那你就已经走在了别人的前面。
如果我现在从头开始学习 AI,至少会关注这些问题。我发现自己花在从头构建模型上的时间越来越少,而是越来越多地使用高级工具,如 AutoML 和 AI API,并将注意力集中在应用程序开发上。