(这一个章节将讲到Java里面比较重要的一个章节,这里说一句抱歉,因为最近换工作的原因,一直没有时间继续书写教程,不过接下来我会一直坚持写下去的哈,希望大家能够支持。这个章节主要涉及到常用的文件读写,包括高级的文件IO内容——java.nio,因为这些内容在如今的一些项目里面也属于相当常见的一部分,如果有什么遗漏或者笔误的话,希望读者来Email告知:[email protected],谢谢!这一部分篇幅可能比前边章节长很多,也是为了保证能够将Java里面IO和文件操作部分内能写的都写入,如果有遗漏希望读者来Email,概念上有混淆的地方请告知,里面有些内容参考了一些原文数据进行了翻译以及思考注解。)
本章目录:
1.IO类相关内容
2.文件和目录
3.文件高级操作
【Jar文档的读写(.jar)】
JAR文件介绍:
JAR文件格式是以流行的ZIP文件格式为基础,用于将许多文件聚集压缩到一个文件里面,与ZIP文件不同的是,JAR文件不仅用于压缩和发布,而且还用于部署和封装库、组件和插件程序,并可被像编译器和JVM这样的工具直接使用。在JAR文件中包含特殊的文件,如manifests和部署描述符,用来只是工具如何处理特定的JAR文件。
JAR文件的作用如下:
- 用于发布和使用类库
- 作为应用程序和扩展的构建单元
- 作为组件、applet或者插件程序的部署单位
- 用于打包与组件相关联的辅助资源
JAR文件格式提供了许多优势和功能,其中很多是传统的压缩格式如ZIP或者TAR所没有提供的,包括:
- 安全性:可以对JAR文件内容加上数字化签名,这样,能够识别签名的工具就可以有选择地为您授予软件安全特权,这是其他文件做不到的,它还可以检测代码是否被篡改过
- 减少下载时间:如果一个Applet捆绑到一个JAR文件中,那么浏览器就可以在一个HTTP事务中下载这个Applet的类文件和相关资源,而不是对每一个文件打开一个新连接
- 压缩:JAR格式允许您压缩文件以提高存储效率
- 传输平台扩展:Java扩展框架(Java Extensions Framework)提供向Java核心平台添加功能的方法,这些扩展是用JAR文件打包的(Java 3D和JavaMail就是扩展的例子)
- 包密封:存储在JAR文件中的包可以选择进行密封,以增强版本一致性和安全性,密封一个包意味着包中的所有类都必须在同一个JAR文件中找到
- 包版本控制:一个JAR文件可以包含有关它所包含的文件的数据,如厂商和版本信息
- 可移植性:处理JAR文件的机制就是Java核心平台API的标准部分
META-INF目录:
大多数JAR文件包含一个META-INF目录,它用于存储包和扩展的配置数据,如安全性和版本信息,Java 2平台识别并解释META-INF目录中的下述文件和目录,以便配置应用程序、扩展应用和类装载器:
- MANIFEST.MF:这个manifest文件定义了与扩展和包相关的数据源
- INDEX.LIST:这个文件由jar工具的新选项-i生成,它包含在应用程序或者扩展中定义的包的位置信息,它是JarIndex实现的一部分,并且由类装载器装载过程。
- XXX.SF:这个是JAR文件的签名文件。占位符XXX表示了签名者
- XXX.DSA:与签名文件相关联的签名程序块文件,它存储了用于签名JAR文件的公共签名
Pack200类:
Pack200类的全名为:java.util.jar.Pack200,这个类是JDK 1.5过后才有的类,该类主要作用是针对JAR文件进行高效压缩,该类的实现是根据Java类特有的结构——合并常量池、去掉误用信息、保存内联数据结构、使用变量长度编码、选择优化的代码类型进行二次压缩来实现高效压缩。但是该类是针对Java类进行压缩的,所以对普通文件的压缩和普通压缩软件没有什么两样,但是对于Jar文件却能轻易达到10-40%的压缩率,这在Java应用部署中很有用,尤其针对Java移动应用程序的压缩和解压是尤其不错的做法。其使用主要用于class文件比较多的情况,当jar中包含的非Java类的资源文件比较多的时候,如JPEG或者GIF,使用gzip格式是最好的选择,但是如果Jar包中绝大部分都是class内容的话,使用pack200绝对是首选,因为pack200会针对class的java类进行优化设计,Pack200的压缩和解压缩的速度是很快的,而且压缩率也是惊人的,试试就知道了。Java命令行也提供了相关的命令工具:pack200
先提供简单的代码段,再示例其操作:
压缩:
Pack200.Packer packer = Pack200.newPacker();
OutputStream output = new BufferedOutputStream(new FileOutputStream(outfileName));
packer.pack(new JarFile(jarFile),output);
output.close();
解压:
Pack200.Unpacker unpacker = Pack200.newUnpacker();
OutputStream output = new JarOutputStream(new FileOutputStream(jarFile));
unpacker.unpack(pack200File,output);
output.close();
——[$]Pack200类例子——
package org.susan.java.io;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.util.jar.JarFile;
import java.util.jar.Pack200;
public class Pack200Tester {
public static void main(String args[]) throws Exception{
JarFile file = new JarFile("D:/work/study.jar");
Pack200.Packer packer = Pack200.newPacker();
OutputStream out = new FileOutputStream("D:/work/study.pack");
packer.pack(file, out);
out.close();
File inputFile = new File("D:/work/study.jar");
File outputFile = new File("D:/work/study.pack");
System.out.println("Before Pack Size: " + inputFile.length());
System.out.println("After Pack Size: " + outputFile.length());
}
}
这段程序运行后我这里有这样的输出:
Before Pack Size: 293695
After Pack Size: 130423
【需要说明的就是:如果JAR本身是一个可执行的JAR,当被Pack200压缩过后,如果要执行的话必须解压才能执行,否则这个JAR文件会直接抛出错误告诉你不能执行,也就是说Pack200针对Jar文件不是单纯的压缩,是进行了高效率的优化,主要目的是为了使得这个Jar在压缩过后体积减小,但是里面的类照样可以引用的,也就是如果是一个java库的话使用这样的方式未尝是一个提供网络jar的比较不错的方式。】
——[$]Jar文件列表——
package org.susan.java.io;
import java.io.IOException;
import java.sql.Date;
import java.util.Enumeration;
import java.util.jar.Attributes;
import java.util.jar.JarEntry;
import java.util.jar.JarFile;
public class JarListReader {
public static void main(String args[]) throws IOException {
JarFile file = new JarFile("D:/work/study.jar");
Enumeration<JarEntry> e = file.entries();
while (e.hasMoreElements()) {
JarEntry entry = e.nextElement();
System.out.println(entry.getName());
long uncompressedSize = entry.getSize();
long compressedSize = entry.getCompressedSize();
long crc = entry.getCrc();
int method = entry.getMethod();
String comment = entry.getComment();
System.out.println(new Date(entry.getTime()));
System.out.println("From " + uncompressedSize + " bytes to " + compressedSize);
if (method == ZipEntry.STORED) {
System.out.println("ZipEntry.STORED");
} else if (method == ZipEntry.DEFLATED) {
System.out.println(ZipEntry.DEFLATED);
}
System.out.println("Its CRC is " + crc);
System.out.println(comment);
System.out.println(entry.isDirectory());
Attributes a = entry.getAttributes();
if (a != null) {
Object[] nameValuePairs = a.entrySet().toArray();
for (int j = 0; j < nameValuePairs.length; j++) {
System.out.println(nameValuePairs[j]);
}
}
System.out.println();
}
}
}
上边这个类会读取Jar文件的清单,这里输出我不一一列举主要是这个文件里面太多内容,仅仅列举其中一部分:
META-INF/MANIFEST.MF
2009-12-19
From 74 bytes to 75
8
Its CRC is 3423671674
null
false
org/susan/java/basic/BreakContinueMain.class
2009-12-18
From 924 bytes to 538
8
Its CRC is 1903539533
null
false
但是这样并没有解压,只是一个读取过程,这一点希望读者谨记,如果要解压,直接使用ZIP解压的方式也可以操作。
——[$]从一个URL地址获取Jar文件——
package org.susan.java.io;
import java.net.JarURLConnection;
import java.net.URL;
import java.util.jar.JarFile;
public class JarMainEntry {
public static void main(String args[]) throws Exception{
//在线地址“ jar:http://hostname/study.jar!/”
URL url = new URL("jar:file:/D://work//study.jar!/");
JarURLConnection con = (JarURLConnection)url.openConnection();
System.out.println(con.getEntryName());
JarFile jarFile = con.getJarFile();
//JarEntry entry = con.getJarEntry();
System.out.println(jarFile.getName());
//System.out.println(entry.getName());
}
}
这段代码可以直接从一个在线的URL地址获取jar文件,其输出为:
null
D:/work/study.jar
在线地址的方式在上边也有说明,这里就不多讲,读者在这里可以举一反三学会使用jar文件的加载,在线读取一个jar文件过后进行jar文件的加载,以及读取jar文件的内容过后找到入口进行程序的运行等!
【这里做个简单的小结*:从这里可以知道Jar文件实际上就是一种特殊的Zip文件,里面的内容存在一定的规范而已,而Jar文件和Zip不一样的就在于不仅仅有特殊工具进行二次压缩,而且还可以直接从一个在线地址加载过来进行运行或者载入,而且在线地址的格式是很特殊的,其地址代码里面已经有说明,这里不多讲。】
[3]Scanner和Print类
Print*类:
Java语言里面的输出具有一些特殊的类型:PrintStream和PrintWriter,这里先提供几个简单的例子演示Print*类的用法:【*:Print*类只有Java的输出类里面有,输入类里面不存在这个类型。】
PrintStream类是过滤器类中一个不可忽视的成员,最基本的标准输出就要借助于它——我们常用的System.out变量就是PrintStream实例。与之对应的字符流类是PrintWriter类。
PrintStream有两个构造函数(在新版API中已标记为过时):
public PrintStream(OutputStream out)
public PrintStream(OutputStream out,boolean autoFlush)
其中,autoFlush置为true时,每当输出遇到换行符,缓冲区的内容就被强制全部输出,如同调用了一次flush()。但要注意,如果没遇到换行符,还是会有数据“憋”在缓冲区里。
方法(已熟悉的就不解释):
public void write(int b)
public void write(byte b,int offset,int length)
public void flush()
public void close()
public void print(Object obj)
这个方法功能是 非常强大的,它可以输出任何对象,而不必另加说明。此外print()方法有许多重载形式,即有多种参数。它们是字符串(String)、字符数组 (char[])、字符(char)、整数(int)、长整数(long)、浮点数(float)、双精度浮点数(double)、布尔值 (boolean)。其中,输出多个数单位的print()方法(也就是指参数为String和char[]的)是同步(synchronized)方 法。
public void println()输出一个换行符。
public synchronized void println(Object obj)
println()方法有9个重载形式,几乎就是print()方法的翻版。唯一的区别在于println()方法都是同步的。
public boolean checkError()
检查输出过程中有什么错误,如有,返回true值。只要输出流中出现一次错误,则出错后的任意对checkError()的调用均会返回真值。
——[$]创建PrintWriter和使用——
package org.susan.java.io;
import java.io.PrintWriter;
public class PrintWriterDemo {
public static void main(String args[]) throws Exception{
// System.out是一个特殊的OutputStream
PrintWriter writer = new PrintWriter(System.out);
// 一些方法举例
writer.println(true);
writer.println('A');
writer.println(500);
writer.println(40000L);
writer.println(45.67f);
writer.println(45.67);
writer.println("Hello");
writer.println(new Integer("99"));
// 关闭PrintWriter
writer.close();
}
}
这段程序的输出为:
true
A
500
40000
45.67
45.67
Hello
99
另外一种创建方式可以通过下边这段代码来实现:
// 从BufferedWriter创建PrintWriter
FileWriter fileWriter = new FileWriter(args[0]);
BufferedWriter bWriter = new BufferedWriter(fileWriter);
PrintWriter pWriter = new PrintWriter(bWriter);
PrintStream使用的三个弊端:
第一个问题是println的输出是与平台有关的,所以写入控制台不会产生任何的问题。但是对于网络客户端和服务器而言就会出现大的问题!大多数网络协议,如Http和Gnutela,指明换行应当为。所以使用println能编写出能正常工作的windows下的程序但是不能工作在Unix和Mac下,在加上readLine()中本身的bug,如果让带有prinln()的程序会使得服务器和客户端都挂起。
第二个问题是,如果PrintSteam使用的是所在平台使用的默认编码方式。但是,乐中编码方式并不是服务期或客户端所期望的。例如一个接收XML文件的WEB希望以UTF-8或UTF16编码,但是一个使用PrintStream的WEB服务器可能在中国——本地化环境系统上发送GBK或GB2312的编码的文件,而不管客户端是否期望或理解这些方式。那么出现可能出现编码失败或者挂起。
第三个问题是PrintStraem吞掉所有的异常。这就是得PrintStream很适合作为教科书程序,如HelloWorld为了讲受简单的控制台输出,不让学生去理解复杂的异常处理。但是在WEB程序中往往会出现连接中断、带宽提供商的错误、远程系统崩溃和其他不可预知得原因而断开。所以网络程序必须具备处理数据流中意料之外的中断。完成这一点的方法是处理异常。但是PrintStream捕获了低层输出流抛出的所有异常。并且在PrintStream中5个标准的方法并没有throws IOException()的声明:
public abstract void write();
public void write(byte[] data);
public void write(byte[] data,int offset,int length);
public void flush();
public void close();
作为替代PrintStream要依靠一个过时标志。如果在底层出现异常,就会设置这个标志,并且程序员要通过checkError()方法检查此标志的值:public boolean checkError();简单地说printStream提供的错误通知对于不可靠的网络连接而言,是不完全的。
Scanner类的使用:
Scanner类是JDK 1.5才出来的一个新的类,以前编程的时候,学过C++的人很多人都说Java里面缺乏像C++一样直接从控制台录入的cin类似的操作,而Scanner的改进就可以使得Java也可以完成了,不过Scanner的最初设计目的铁定不仅仅只是为了这么简单的原因的!这个类是Java 5的新特性,主要是简化文本扫描,这个类最实用的地方表现在获取控制台输入,其他的功能相对使用范围比较少,尽管Java API里面针对这个类有大量的方法,但是都不怎么常用。Scanner里面比较实用的几个方法:
public Pattern delimiter():
返回该Scanner当前正在用于匹配分隔符的Pattern
public Scanner useDelimiter(Pattern pattern):
将此扫描器的分隔模式设置为指定模式
public Scanner useDelimiter(String pattern):
将此扫描器的分隔模式设置为从指定 String 构造的模式
public boolean hasNext() throws IllegalStateException:
如果此扫描器的输入中有另一个标记,则返回 true。在等待要扫描的输入时,此方法可能阻塞。扫描器将不执行任何输入。
public boolean hasNextLine() throws IllegalStateException:
如果在此扫描器的输入中存在另一行,则返回 true。在等待输入信息时,此方法可能阻塞。扫描器不执行任何输入。
public String nextLine() throws NoSuchElementException,IllegalStateException:
此扫描器执行当前行,并返回跳过的输入信息。 此方法返回当前行的其余部分,不包括结尾处的行分隔符。当前位置移至下一行的行首。因为此方法会继续在输入信息中查找行分隔符,所以如果没有行分隔符,它可能会缓冲所有输入信息,并查找要跳过的行。
public String next() throws NoSuchElementException:
查找并返回来自此扫描器的下一个完整标记。完整标记的前后是与分隔模式匹配的输入信息。即使以前调用 hasNext() 返回了 true,在等待要扫描的输入时此方法也可能阻塞。
——[$]扫描控制台输入——
package org.susan.java.io;
import java.util.Scanner;
public class ScannerDemo {
public static void main(String args[]){
Scanner scanner = new Scanner(System.in);
System.out.println("Please input the string:");
while(true){
String line = scanner.nextLine();
if(line.equals("exit"))
break;
System.out.println(">>>" + line);
}
}
}
上边这段代码的输出为【可交互的控制台】:
Please input the string:
LangYu
>>>LangYu
HelloWorld
>>>HelloWorld
exit
*:这里的LangYu、HelloWorld和exit都是用户从控制台输入的字符串,这里就演示了用户从控制台和应用程序交互的过程。
——[$]使用Scanner分隔——
package org.susan.java.io;
import java.util.Scanner;
public class ScannerDevide {
public static void main(String args[]){
Scanner scanner = new Scanner("123 asdf sd 45 789 sdf asdfl,sdf.sdf,asdf ....asdf las");
scanner.useDelimiter(" ");
while(scanner.hasNext()){
System.out.println(scanner.next());
}
}
}
该程序的输出为:
123
asdf
sd
45
789
sdf
asdfl,sdf.sdf,asdf
....asdf
las
*:上边这段程序注意useDelimiter方法的传入参数,这里的参数应该是一个正则表达式,正则表达式的内容这里不再说明,没有看过前边章节的读者可以参考一下前边正则表达式一章节的内容以参考,这里传入的匹配模式是一个空白符号,所以以空白作为分隔符直接把传入Scanner的字符串进行了分隔并且分开输出。
——[$]逐行读取——
package org.susan.java.io;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.util.Scanner;
public class SingleLineScanner {
public static void main(String args[]) throws FileNotFoundException{
InputStream in = new FileInputStream("D:/work/AutoSubmit.java");
Scanner scanner = new Scanner(in);
int number = 1;
while(scanner.hasNextLine()){
System.out.print(number + ". ");
System.out.println(scanner.nextLine());
number++;
}
}
}
这段代码的输出为:
1. package org.susan.java.io;
2.
3. import java.io.BufferedReader;
4. import java.io.FileReader;
5. import java.io.FileWriter;
6.
7. public class AutoSubmit{
8. public static void main(String args[]) throws Exception{
9. FileReader inReader = new FileReader("D:/read.txt");
10. FileWriter outWriter = new FileWriter("D:/write.txt");
11. BufferedReader in = new BufferedReader(inReader);
12. //BufferedWriter out = new BufferedWriter(outWriter);
13. int c = 0;
14. while((c = in.read()) != -1){
15. outWriter.write(c);
16. }
17. in.close();
18. outWriter.close();
19. }
20. }
这里可以看出这段代码给这段代码每一行添加了行号的输出,主要在于下边这两句话:
System.out.print(number + ". ");
System.out.println(scanner.nextLine());
而且这里可以看出这些代码就是逐行读取的内容。【*:到这里关于Scanner的内容就大致讲解到这个地方,】
[4]花1K内存实现高效IO的RandomAccessFile类【摘录自IBM开发中心,这里引入这篇文章是激发读者去思考,因为这篇文章很古老,是02年的文章,实际上JDK 1.4过后完全可以使用下边将会讲到的高级操作。】:
这里再谈谈Java的文件随机存取类,RandomAccessFile类的IO效率本身比较低下,这里提供一种解决方案展示如何创建具备缓存读写能力的文件随机存取类,并且进行了优化。一般情况下当开发人员需要文件随机存取的时候,就需要使用RandomAccessFile类,其IO性能较之其他常用开发语言的同类性能差距甚远,严重影响程序的运行效率,这里提供一个测试结果:逐字节拷贝一个12M的文件(这里涉及读写两个操作)。
| 读 | 写 | 时间(秒) |
| RandomAccessFile | RandomAccessFile | 95.829 |
| BufferedInputStream + DataInputStream | BufferedOutputStream + DataOutputStream | 2.935 |
根据上边的结论,针对RandomAccessFile的类加上缓冲读写机制,随机访问类与顺序类不同,前者是通过实现DataInput/DataOutput接口创建的,而后者是扩展FilterInputStream/FilterOutputStream创建的,不能直接照搬。
其步骤如下:
——开辟缓冲区BUF,默认1024字节,用作读写的公用缓冲区
——先实现读缓冲
读缓冲逻辑的基本原理:A欲读文件POS位置的一个字节;B查BUF中是否存在?若有,直接从BUF中读取,并返回该字符byte;C若没有,则BUF重新定位到该POS所在的位置并把该位置附近的BUFSIZE的字节的文件内容填充BUFFER,返回B操作。
——[$]实现代码——
package org.susan.java.io;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.RandomAccessFile;
public class BufferedRandomAccessFile extends RandomAccessFile{
// BUF映射在当前文件首的偏移地址
private long bufstartpos;
// BUF映射在当前文件尾的偏移地址
private long bufendpos;
// 当前类文件指针的便宜地址
private long curpos = 0;
// 当改值为真的时候,把buf[]中尚未写入磁盘的数据写入磁盘
private boolean bufdirty;
// 已经使用的字节
private int bufusedsize;
// 指示当前文件的尾偏移地址,主要考虑到追加因素
private long fileendpos;
// 缓冲区字节长度
private long bufbitlen;
// 缓冲区字节大小
private long bufsize;
// 设置的需要的缓冲区
private byte[] buf;
public BufferedRandomAccessFile(String name,String mode) throws FileNotFoundException{
super(name, mode);
}
/**
* 读取当前文件POS位置所在的字节
* @param pos
* @return
* @throws IOException
*/
public byte read(long pos) throws IOException{
if( pos < this.bufstartpos || pos > this.bufendpos){
this.flushbuf();
this.seek(pos);
if(( pos < this.bufstartpos) || (pos > this.bufendpos))
throw new IOException();
}
this.curpos = pos;
return this.buf[(int)(pos - this.bufstartpos)];
}
/**
* 刷新缓冲区
* @throws IOException
*/
private void flushbuf() throws IOException{
if( this.bufdirty == true){
if( super.getFilePointer() != this.bufstartpos){
super.seek(this.bufstartpos);
}
super.write(this.buf,0,this.bufusedsize);
this.bufdirty = false;
}
}
/**
* 移动指针到pos位置,并且把buf[]映射填充到POS所在的文件块
*/
public void seek(long pos) throws IOException{
if((pos < this.bufstartpos) || ( pos > this.bufendpos)){
this.flushbuf();
if((pos >= 0 ) && (pos <= this.fileendpos) && (this.fileendpos != 0)){
this.bufstartpos = pos * this.bufbitlen / this.bufbitlen;
this.bufusedsize = this.fillbuf();
}else if(( pos == 0 ) && ( this.fileendpos == 0) || (pos == this.fileendpos + 1)){
this.bufstartpos = pos;
this.bufusedsize = 0;
}
this.bufendpos = this.bufstartpos + this.bufsize -1;
}
this.curpos = pos;
}
/**
* 根据bufstartpos,填充buf[]
* @return
* @throws IOException
*/
private int fillbuf() throws IOException{
super.seek(this.bufstartpos);
this.bufdirty = false;
return super.read(this.buf);
}
}
这样缓冲读取就已经实现了,用这种方式测试一下读写速度,就可以发现【这里同样读取12M的文件】:
| 读 | 写 | 时间(秒) |
| BufferedRandomAccessFile | BufferedOutputStream + DataOutputStream | 2.833 |
——接下来实现缓冲写
缓冲写的基本原理:A欲写文件POS位置的一个字节;B查BUF中是否有该映射?若有,直接向BUF中写入,并返回true;C若没有,则BUF重新定位到POS所在的位置,并把该位置附近的BUFSIZE字节的文件内容填充到BUFFER,返回B步骤
这里提供关键代码,在上边类里面添加下边的方法来实现:
/**
* 根据POS的不同以及BUF的位置:存在修改、追加、BUF中、BUF外等情况。
* 在逻辑判断时,把最可能出现的情况,最先判断可以提高速度
* @param bw
* @param pos
* @return
* @throws IOException
*/
public boolean write(byte bw, long pos) throws IOException {
if ((pos >= this.bufstartpos) && (pos <= this.bufendpos)) {
this.buf[(int) (pos - this.bufstartpos)] = bw;
this.bufdirty = true;
if (pos == this.fileendpos + 1) {
this.fileendpos++;
this.bufusedsize++;
}
} else {
this.seek(pos);
if ((pos >= 0) && (pos <= this.fileendpos) && (this.fileendpos != 0)) {
this.buf[(int) (pos - this.bufstartpos)] = bw;
} else if (((pos == 0) && (this.fileendpos == 0)) || (pos == this.fileendpos + 1)) {
this.buf[0] = bw;
this.fileendpos++;
this.bufusedsize = 1;
} else {
throw new IndexOutOfBoundsException();
}
this.bufdirty = true;
}
this.curpos = pos;
return true;
}
上边这个方法就实现了缓冲写操作,再测试一下:
| 读 | 写 | 时间(秒) |
| BufferedRandomAccessFile | BufferedRandomAccessFile | 2.453 |
——优化BufferedRandomAccessFile
优化原理:A调用频繁的语句最需要优化,且优化效果比较明显;B多重嵌套逻辑判断时,最可能出现的判断应放在最外层;C减少不必要的NEW操作,比如seek方法。
优化过后再测试可以看到测试结果:
| 读 | 写 | 时间(秒) |
| BufferedRandomAccessFile优 | BufferedRandomAccessFile优 | 2.197 |
——整体完善:
提供文件追加功能,添加方法:
public boolean append(byte bw) throws IOException{
return this.write(bw, this.fileendpos + 1);
}
提供文件当前位置修改功能:
public boolean write(byte bw) throws IOException{
return this.write(bw,this.curpos);
}
返回文件长度,因为提供了BUF读写的原因,与原来的类有所不同:
public long length() throws IOException{
return this.max(this.fileendpos + 1, this.initfilelen);
}
返回当前指针:
public long getFilePointer() throws IOException{
return this.curpos;
}
完善过程中这里还有两个重要方法就是缓冲读写方法的改写:
提供对当前位置的多个字节的缓冲写功能:
public void write(byte b[], int off, int len) throws IOException {
long writeendpos = this.curpos + len - 1;
if (writeendpos <= this.bufendpos) {
System.arraycopy(b, off, this.buf,
(int) (this.curpos - this.bufstartpos), len);
this.bufdirty = true;
this.bufusedsize = (int) (writeendpos - this.bufstartpos + 1);
} else {
super.seek(this.curpos);
super.write(b, off, len);
}
if (writeendpos > this.fileendpos)
this.fileendpos = writeendpos;
this.seek(writeendpos + 1);
}
提供对当前位置的多个字节的缓冲读功能:
public int read(byte b[], int off, int len) throws IOException {
long readendpos = this.curpos + len - 1;
if (readendpos <= this.bufendpos && readendpos <= this.fileendpos) {
System.arraycopy(this.buf, (int) (this.curpos - this.bufstartpos),b, off, len);
} else {
if (readendpos > this.fileendpos) {
len = (int) (this.length() - this.curpos + 1);
}
super.seek(this.curpos);
len = super.read(b, off, len);
readendpos = this.curpos + len - 1;
}
this.seek(readendpos + 1);
return len;
}
public int read(byte b[]) throws IOException {
return this.read(b, 0, b.length);
}
public void setLength(long newLength) throws IOException {
if (newLength > 0) {
this.fileendpos = newLength - 1;
} else {
this.fileendpos = 0;
}
super.setLength(newLength);
}
public void close() throws IOException {
this.flushbuf();
super.close();
}
最后提供一个测试的总表来完成几种不同方法之间的对比:
| 读 | 写 | 时间(秒) |
| RandomAccessFile | RandomAccessFile | 95.829 |
| BufferedInputStream + DataInputStream | BufferedOutputStream + DataOutputStream | 2.935 |
| BufferedRandomAccessFile | BufferedOutputStream + DataOutputStream | 2.833 |
| BufferedRandomAccessFile | BufferedRandomAccessFile | 2.453 |
| BufferedRandomAccessFile优 | BufferedRandomAccessFile优 | 2.197 |
| BufferedRandomAccessFile完 | BufferedRandomAccessFile完 | 0.401 |
3.文件高级操作
JDK 1.4介绍了许多提高IO性能的过程,这里有一种IO称为“新的IO”,主要是使用了java.nio包,这个包提供了下边几种功能:
- 设置字符编码的编码器(encoder)和解码器(decoder)
- 非阻塞IO
- 内存映射文件
- 文件锁
使用java.nio的功能的性能优势在于:
- 能够直接从硬盘上、而不需要一字节一字节地读写数据块,当你在非阅读期间将数据从缓冲器中提出时,它处理低字节优先问题。
- 可以进行非阻塞异步输入/输出
- 你能够锁定整个或部分文件
那么NIO的原理是什么呢?Java NIO的一些应用通常适用在IO读写方面,我们知道系统运行的性能瓶颈通常在IO读写,包括对端口和文件的操作,过去打开一个IO通道过后,通过读取一直等待在一个端口读取一个字节内容,如果没有字节内容进来,则应用程序的读取操作也是傻傻等待,这样就影响了程序继续做其他的事情,而改进方法就是开设线程让线程来等待,实际上通过实践可以知道这样的方法同样也是非常耗时的。Java NIO非堵塞技术实际是采取Reactor模式,或者说是Observer模式为我们监察I/O端口,如果有内容进来,会自动通知我们,这样,我们就不必开启多个线程死等,从外界看,实现了流畅的I/O读写,不堵塞了。Java NIO出现不只是一个技术性能的提高,你会发现网络上到处在介绍它,因为它具有里程碑意义,从JDK1.4开始,Java开始提高性能相关的功能,从而使得Java在底层或者并行分布式计算等操作上已经可以和C或Perl等语言并驾齐驱。如果你至今还是在怀疑Java的性能,说明你的思想和观念已经完全落伍了,Java一两年就应该用新的名词来定义。从JDK1.5开始又要提供关于线程、并发等新性能的支持,Java应用在游戏等适时领域方面的机会已经成熟,Java在稳定自己中间件地位后,开始蚕食传统C的领域。【*:此段摘录自
http://www.jdon.com/concurrent/nio%D4%AD%C0%ED%D3%A6%D3%C3.htm
】
Java的NIO包里面引入了四个关键的抽象数据类型,它们相互配合共同解决了传统的IO中一些问题。
- Buffer:它是包含数据并且用于读写的线性表结构,其中提供了一些特殊类用的内存映射文件的IO操作
- Charset:它提供了Unicode字符串影射到字节序列以及逆影射的操作
- Channels:包含了socket、file和pipe三种通道,实际上是双向交流的通道。
- Selector:它将多元异步IO操作几种到一个或者多个线程中
Java的NIO包里面引入了一种称为通道的新型原始输入输出提取方法,通道表示实体(硬件设备、文件、网络套接字或者可以执行一个或者多个独特的注入读和写之类的输入输出操作的程序组件)的开放连接,操作的一个线程可以被阻止,而另外一个线程能够关闭通道,这是通道的一个突出的特点,当通道关闭的时候,被阻止的线程用一个异常激活,表明通道是被关闭的。
i.基本术语:
内存映射文件:
内存映射文件的IO市一中读写数据的方法,它可以比常规的基于流或者基于通道的IO高效很多,内存映射文件IO的读写方式是通过使用文件中的数据组合成为内存数组的内容来完成的,咋一听貌似这种方式是将整个文件读取到整个内存中,实际上不是的,在读写过程中只有真正在读写的部分才会进入内存,这种方式称为映射。现在很多操作系统一般都会根据需要将文件或者文件中的某些部分映射为内存的一部分内容,从而实现文件系统,Java内存映射机制不过使用的是针对底层操作系统的该机制的一种使用。
缓冲区结构:
当我们在使用内存映射的时候,需要将让一个内存里面单独的缓冲区和一个实体文件或者一个实体文件的域进行交互,在这样的情况下就需要提供一个缓冲区的简单的数据结构。缓冲区的结构如下:
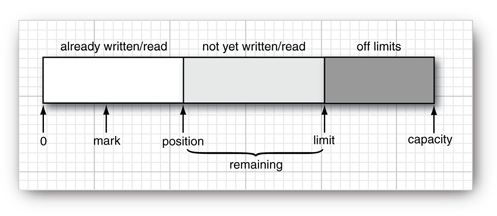
从上边的图可以知道,一个缓冲区包含下边几个部分:
- 一个绝对不会改变的缓冲区的容量capacity
- 下一个值的读写位置position
- 无意义读写的一个限制空间limit
- 额外的还有一个用来重复读写的标记mark
文件锁(File Locking):
ii.NIO初探【诱导初学者教程】:
Java NIO里面一个主要的类是Selector,这个类似一个观察者,只要在写程序过程把需要探知的socketchannel告诉Selector,我们就可以直接做其他的事情,当有事件发生的时候,他会通知我们,传回一个SelectionKey,读取这些Key就可以获取刚刚注册过的SocketChannel,然后就可以从这个Channel中读取锁需要的数据,它保证我们在读写过程能够读取到这些数据,接着还可以针对这些数据进行处理。Selector内部原理其实很简单,就是针对一个注册过的Channel进行轮询访问,不断的轮询一旦轮询到一个Channel有所注册的事情发生,比如数据来了等就会发送报告,交出一个Key,让程序通过该Key直接读取这个Channel的内容。
【*:关于Java NIO我们在编程过程可以这样理解,实际上Java NIO的大部分内容都不是Java语言本身实现的,它之所以效率比较高是因为它本身使用的就是操作系统底层的IO部分的API而不是基于JVM级别的,而它的实现语言使用的是C,所以它在读写过程和操作系统紧密相关,而利用上边讲解的原理就可以完整实现Java的高效读取,这种方式和我们前边遇到的Java IO的方式有本质上的区别,而如何使用Java书写接口而换用C语言书写实现读者可以参考JNI的有关文档。】
接下来提供几个例子来说明Java NIO的API的相关用法:
——[$]使用映射文件来读取文本文件——
package org.susan.java.io;
import java.io.FileInputStream;
import java.io.IOException;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class NativeMapFile {
public static void main(String args[]){
FileInputStream fileInputStream;
FileChannel fileChannel;
long fileSize;
MappedByteBuffer mBuffer;
try{
fileInputStream = new FileInputStream("D:/work/test.txt");
fileChannel = fileInputStream.getChannel();
fileSize = fileChannel.size();
mBuffer = fileChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileSize);
for( int i = 0; i < fileSize; i++ ){
System.out.print((char)mBuffer.get());
}
fileChannel.close();
fileInputStream.close();
}catch(IOException ex){
ex.printStackTrace();
}
}
}
上边这段代码会使用本地映射文件读取某个文件里面的内容,test.txt里面的内容为:
你好么?你好啊!
HelloWorld!
以下是该程序的输出结果:
ᄏ¦ᄑᅠ¥ᆬᄑ¦ᄍネᄐ゚¦ᄑᅠ¥ᆬᄑ¥ユハᄐチ
HelloWorld!
可以知道一点就是直接使用这种方式读取文件,有可能会出现中文的乱码问题,不过这个问题稍候想办法解决,这里先介绍几个NIO里面的几个重要知识点:FileChannel.MapMode是文件影射模型的安全的枚举,主要有几个值:
FileChannel.MapMode.PRIVATE:专用(写入时拷贝)映射模式
FileChannel.MapMode.READ_ONLY:只读映射模式
FileChannel.MapMode.READ_WRITE:读取、写入映射模式
其实java.nio里面的一个核心类就是上边使用到的FileChannel,该类的介绍如下:
定义:
public abstract class FileChannel extends AbstractInterruptibleChannel implements ByteChannel, GatheringByteChannel, ScatteringByteChannel
该类是用于读取、写入、映射和操作文件的通道,文件通道在文件内部有一个当前的position,可以对其进行查询和修改,该文件本身包含一个可读写的长度的可变字节序列,并且可以通过查询该文件的当前大小,写入字节超出文件的当前大小时,则增加文件的大小;截取该文件的时候,则减小文件的大小,文件可能还有某个相关联的元数据,如访问权限、内容类型和最后的修改时间,该类却没有定义元数据的方法。除了字节通道中常见的读取、写入和关闭操作,此类还定义了下列特定于文件的操作:
- 以不影响通道当前位置的方式,对文件中绝对位置的字节进行读取和写入
- 将文件中的某个区域直接映射到内容中,对于较大的文件,这通常比调用普通的read或write方式更加高效
- 强制对底层存储设备进行文件更新,以确保在系统崩溃的时候不丢失数据
- 以一种可以被很多操作系统优化为直接向文件系统缓存发送或从中读取的高速传输方法,将字节从文件传输到某个其他通道中,反之亦然
- 可以锁定某个文件区域,以阻止其他程序进行访问
多个并发线程可安全地使用文件通道,可随时调用关闭方法,正如Channel接口中所指定,对于涉及通道位置或者可以更改文件大小的操作,在任意给定时间只能进行一个这样的操作,如果尝试在第一操作仍在进行时发起第二个操作,则会导致在第一个操作完成之前阻塞第二个操作。可以并发处理其他操作,特别是采用显示位置的操作,但是否并发处理则取决于系统,因此是未指定的。确保此类的实例所提供的文件视图与同一程序中其他实例所提供的相同文件视图是一致的。但是,此类的实例所提供的视图不一定与其他并发运行的程序所看到的视图一致,这取决于底层操作系统所执行的缓冲策略和各种网络文件系统协议所引入的延迟。不管其他程序是以何种语言编写的,而且也不管是运行在相同机器还是不同机器上都是如此。此种不一致的确切性质取决于系统,因此是未指定的。此类没有定义打开现有文件或创建新文件的方法,以后的版本中可能添加这些方法。在此版本中,可从现有的 FileInputStream、FileOutputStream 或 RandomAccessFile 对象获得文件通道,方法是调用该对象的 getChannel 方法,这会返回一个连接到相同底层文件的文件通道。文件通道的状态与其 getChannel 返回该通道的对象密切相关。显式或者通过读取或写入字节来更改通道的位置将更改发起对象的文件位置,反之亦然。通过文件通道更改此文件的长度将更改通过发起对象看到的长度,反之亦然。通过写入字节更改此文件的内容将更改发起对象所看到的内容,反之亦然。
此类在各种情况下指定要求“允许读取操作”、“允许写入操作”或“允许读取和写入操作”的某个实例。通过
FileInputStream 实例的 getChannel 方法所获得的通道将允许进行读取操作。通过 FileOutputStream 实例的 getChannel 方法所获得的通道将允许进行写入操作。最后,如果使用模式 "r" 创建 RandomAccessFile 实例,则通过该实例的 getChannel 方法所获得的通道将允许进行读取操作,如果使用模式 "rw" 创建实例,则获得的通道将允许进行读取和写入操作。
如果从文件输出流中获得了允许进行写入操作的文件通道,并且该输出流是通过调用
FileOutputStream(File,boolean) 构造方法且为第二个参数传入 true 来创建的,则该文件通道可能处于添加模式。在此模式中,每次调用相关的写入操作都会首先将位置移到文件的末尾,然后再写入请求的数据。在单个原子操作中是否移动位置和写入数据是与系统相关的,因此是未指定的。
【思考*:使用FileChannel的时候主要是针对字节序列进行操作,那么和前面提及到的Java普通IO交互的部分大部分都是字节流读写器,参考字节流读写器中间可以发现一部分Stream类型的读写器可以通过getChannel方法获取文件通道。】
下边再引入一个FileChannel的例子:
——[$]写入文件,使用新的IO——
package org.susan.java.io;
import java.io.FileOutputStream;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class NativeFileWrite {
public static void main(String args[]){
FileOutputStream fileOutputStream;
FileChannel fileChannel;
ByteBuffer byteBuffer;
try{
fileOutputStream = new FileOutputStream("D:/work/test.txt");
fileChannel = fileOutputStream.getChannel();
byteBuffer = ByteBuffer.allocateDirect(26);
for( int i = 0; i < 26; i++ )
byteBuffer.put((byte)('A' + i));
byteBuffer.rewind();
fileChannel.write(byteBuffer);
fileChannel.close();
fileOutputStream.close();
}catch(IOException ex){
ex.printStackTrace();
}
}
}
该例子演示了向一个文件内写入英文字母A到Z的全过程,下边是写入过后test.txt里面的文件内容:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
这里再介绍一个类:ByteBuffer类,该类针对字节进行了六种操作:
- 读写单个字节的绝对和相对get和put方法
- 将此缓冲区的连续字节列传输到数组中的相对批量get方法
- 将byte数组或其他字节缓冲区中的连续字节序列传输到此缓冲区的相对批量put方法
- 读写其他基本类型值,并按照特定的字节序列在字节序列之间转换这些值的get和put方法
- 创建视图缓冲区的方法,这些方法允许将字节缓冲区视为包含其他基本类型值的缓冲区
- 对字节缓冲区进行compacting、duplicating和slicing的方法
直接与非直接缓冲区:
ByteBuffer有两个创建缓冲区的方法:
static ByteBuffer allocate(int capacity)
static ByteBuffer allocateDirect(int capacity)
这两个方法都是创建缓冲区的方法,使用直接缓冲区的时候,JVM虚拟机会直接在此缓冲区上执行本机IO操作,也就是说,在每次调用基础操作系统的一个本机IO之前或者之后,虚拟机都会避免将缓冲区的内容复制到中间缓冲区(或者从中间缓冲区复制内容)。直接字节缓冲区使用上边方法中的allocateDirect工厂方法创建,此方法返回的缓冲区进行分配和取消分配所需要的成本往往比间接缓冲区要高,直接缓冲区的内容可以驻留在常规的垃圾回收堆之外,因此,它们对应用程序的内容需求量造成的影响可能并不明显,所以建议将直接缓冲区主要分配给那些容易受基础系统的本机IO操作影响的大型、持久的缓冲区。一般情况下,最好仅在直接缓冲区能在程序性能方面带来明显好处的时候分配它们。
直接缓冲区还可以使用mapping将文件区域直接映射到内存中来创建,Java平台的实现有助于通过JNI从本机代码直接创建字节缓冲区,如果以上这些缓冲区中的某个缓冲区实例指的是不可访问的内存区域,则视图访问该区域不会更改该缓冲区的内容,并且会在访问期间或稍候的某个时间导致抛出不确定的异常。
字节缓冲区是直接缓冲区还是非直接缓冲区可以通过ByteBuffer的isDirect方法来确定,提供该方法是为了能够在性能关键型代码中执行显示缓冲区管理。
访问二进制数据:
此类定义除了boolean之外,读写所有其他基本类型值的方法,这些基本值可以根据缓冲区的当前字节顺序与字节序列相互进行转换,并可以通过order方法获取和修改。特定的字节顺序由ByteOrder类的实例进行表示,字节缓冲区的初始顺序是BIG_ENDIAN(该顺序可以参考《Java内存模型》
http://blog.csdn.net/silentbalanceyh/archive/2009/10/13/4661230.aspx
)的。为了访问异类二进制数据,此类还针对每种类型定义了一系列绝对和相对的put和get方法,并针对float、char、short、int、long和double等类型定义了相对方法,该方法可以自行参考API内容。绝对get和put方法的index参数是根据字节定义的,而不是根据所读写的类型定义的。
为了访问同类二进制数据(即相同类型的值序列),此类还定义了可以为指定类型的缓冲区创建视图的方法,视图缓冲区只是其内容受该字节缓冲区支持的另一种缓冲区,字节缓冲区内容的更改在视图缓冲区中是可见的,反之亦然;这两种缓冲区的位置、限制和标记值都是独立的。使用视图缓冲区有三大优势:
- 视图缓冲区不是根据字节进行索引,而是根据其特定于类型的值的大小进行索引
- 视图缓冲区提供了相对批量put和get方法,这些方法可在缓冲区和数组或相同类型的其他缓冲区之间传输值的连续序列
- 视图缓冲区可能更高效,这是因为,当且仅当其支持的字节缓冲区为直接缓冲区时它才是直接缓冲区。
实际上ByteBuffer是继承于Buffer类,里面存放的是字节,如果要将它们转换成字符串则需要使用Charset,Charset是字符编码,它提供了把字节流转换成为字符流(解码)和将字符串转换成字节流(编码)的方法。该类有一下三个重要的属性:
- 容量(capacity):表示该缓冲区可以存放多少数据
- 极限(limit):表示读写缓存的位置,不能对超过位置进行数据的读或写操作
- 位置(position):表示下一个缓冲区的读写单元,每读写一次缓存区,位置都会变化,位置是一个非负整数
——[$]快速复制文件——
package org.susan.java.io;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.nio.ByteBuffer;
import java.nio.channels.FileChannel;
public class QuickCopy {
public static void main(String args[]) throws Exception{
FileInputStream fin = new FileInputStream("D:/work/test.txt");
FileOutputStream fout = new FileOutputStream("D:/work/output.txt");
FileChannel inChannel = fin.getChannel();
FileChannel outChannel = fout.getChannel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
while(true){
int ret = inChannel.read(buffer);
if( ret == -1)
break;
buffer.flip(); //该方法为父类Buffer的方法
outChannel.write(buffer);
buffer.clear(); //该方法为父类Buffer的方法
}
}
}
上边的代码分配了1024个字节的直接缓冲区,然后使用本地拷贝的方式进行文件拷贝,应该是比普通的文件拷贝更高效,这里解释几个比较常用的ByteBuffer类里面的方法【这里不介绍分配缓冲区的方法了】:
public abstract ByteBuffer compact() throws ReadOnlyBufferException:
——该方法压缩此缓冲区(可选的),将缓冲区的当前位置和界限之间的字节复制到缓冲区的开始处,即将索引p = position()处的字节复制到索引0处,将索引n+1处的字节复制到索引1的位置,依次类推直到索引limit() - 1处的字节复制到索引 n = limit() - 1 - p处,然后将缓冲区的位置设置为n + 1,并将其界限设置为其容量,如果已定义了标记,则丢弃。将缓冲区的位置设置为复制的字节数,而不是零,以便调用此方法后可以紧接着调用另一个相对put方法。
public abstract ByteBuffer duplicate():
——创建共享此缓冲区内容的新的字节缓冲区,新缓冲区的内容将为此缓冲区的内容,此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。新缓冲区的容量、界限、位置和标记值将与此缓冲区相同。当且仅当此缓冲区为直接时,新缓冲区才是直接的,当切仅当此缓冲区是只读时,新缓冲区才是只读的。
public abstract ByteBuffer slice():
——创建新的字节缓冲区,其内容是此缓冲区的共享子序列,新缓冲区的内容将从此缓冲区的当前位置开始,此缓冲区内容的更改在新缓冲区中是可见的,反之亦然;这两个缓冲区的位置、界限和标记值是相互独立的。
public abstract ByteBuffer wrap(byte[] array):
——将byte数组包装到缓冲区中,新的缓冲区将由给定的byte数组支持,也就是说,缓冲区修改将导致数组修改,反之亦然。新缓冲区的容量和界限将为array.length,其位置将为零,其标记是不确定的,其底层实现数据将为给定数组,并且其数组偏移量将为零。
这里再提供几个基本操作的例子:
——[$]基本类型和ByteBuffer——
package org.susan.java.io;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
public class BasicType {
public static void main(String args[]) throws Exception{
// 使用字节数组创建ByteBuffer
byte[] bytes = new byte[10];
ByteBuffer buffer = ByteBuffer.wrap(bytes);
// 创建字符ByteBuffer
ByteBuffer charBuffer = ByteBuffer.allocate(15);
CharBuffer charBuffer2 = buffer.asCharBuffer();
// 设置获取字符类型的Buffer
ByteBuffer charBuffer3 = ByteBuffer.allocate(100);
charBuffer3.putChar((char)123);
charBuffer3.flip();
char c = charBuffer3.getChar();
}
}
上边是针对基本类型的操作,查阅API可以看到基本操作相关的类里面提供的方法
——[$]String和ByteBuffer——
package org.susan.java.io;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
public class StringByteBuffer {
public static void main(String args[]) throws Exception{
// 使用ByteBuffer存储字符串
ByteBuffer buffer = ByteBuffer.allocate(100);
CharBuffer cBuffer = buffer.asCharBuffer();
cBuffer.put("Hello World");
cBuffer.flip();
String result = cBuffer.toString();
}
}