一、通过Callable的方式创建线程
1.1区别
class Thread1 implements Runnable{
@Override
public void run() {
}
}
class Thread2 implements Callable<String>{
@Override
public String call() throws Exception {
return null;
}
}
- 实现Runnable接口创建线程重写的是run方法,实现Callable接口重写的call方法
- 实现Callable接口创建进程,可以抛出异常
- 实现Callable接口创建进程,有返回值,返回值要和泛型一致
1.2 启动一个线程
那么该如何创建一个实现了Callable的线程呢?查看官方文档可以发现,使用Callable创建的线程和Runnable相似,那么可以在Therad中启动

Thread中是没有直接可以传入Callable接口的参数的,
要想在Thread中使用Callable,我们可以试想一下这种即实现了Runnable,又实现了Callable的接口或者类呢?而FutureTask正是这种类,首先是实现了Runnable接口,然后构造方法允许传入Callable接口的实现类

FutureTask(Callable<V> callable)
那么启动Callable线程就好办了
class Thread2 implements Callable<String>{
@Override
public String call() throws Exception {
System.out.println("线程启动了");
return null;
}
}
public class CallableTest {
public static void main(String[] args) throws InterruptedException {
FutureTask<String> task = new FutureTask<>(new Thread2());
new Thread(task,"A").start();
}
}
1.3 获取返回值
调用get方法即可获得返回值
FutureTask<String> task = new FutureTask<>(new Thread2());
new Thread(task,"A").start();
task.get();
1.4 原理
调用get方法线程会堵塞直到线程执行结束,返回返回值。在主线程中需要执行比较耗时的操作时,但又不想阻塞主线程时,可以把这些作业交给Future对象在后台完成,当主线程将来需要时,就可以通过Future对象获得后台作业的计算结果或者执行状态。
FutureTask<Integer> futureTask = new FutureTask(()->{
System.out.println(Thread.currentThread().getName()+" come in callable");
TimeUnit.SECONDS.sleep(4);
return 1024;
});
new Thread(futureTask,"A").start();
while(!futureTask.isDone()){
System.out.println("***wait");
}
System.out.println(futureTask.get());
System.out.println(Thread.currentThread().getName()+" come over");
上面启动了一个线程,模拟计算较耗时的任务然后将最终结果放回,在主线程中,isDone方法判断是否执行结束,执行结束(完成/取消/异常)返回true,以上程序可以证明调用get方法是堵塞的,只有A线程将结果返回,才会继续执行
 还需要注意的是一个task任务只计算一次,看如下代码
还需要注意的是一个task任务只计算一次,看如下代码
FutureTask<Integer> futureTask = new FutureTask(()->{
System.out.println(Thread.currentThread().getName()+" come in callable");
TimeUnit.SECONDS.sleep(4);
return 1024;
});
new Thread(futureTask,"A").start();
while(!futureTask.isDone()){
System.out.println("***wait");
}
System.out.println(futureTask.get());
System.out.println("--------");
System.out.println(futureTask.get());
System.out.println(Thread.currentThread().getName()+" come over");

第二次get时,线程并没有休眠4秒。可见是直接返回的,所以每个task任务只会计算一次。
总结:
一般FutureTask多用于耗时的计算,主线程可以在完成自己的任务后,再去获取结果。仅在计算完成时才能检索结果;如果计算尚未完成,则阻塞 get 方法。一旦计算完成,就不能再重新开始或取消计算。get方法而获取结果只有在计算完成时获取,否则会一直阻塞直到任务转入完成状态,然后会返回结果或者抛出异常。 一个task任务只计算一次,所以一般将get方法放到最后。
二、线程池
2.1 线程池的好处
说到线程池,很容易想起来数据库连接池c3p0等等数据库连接池技术,数据库连接池和线程池的好处都是一样的:
- 降低资源消耗:通过重复利用已创建的线程降低线程创建和销毁造成的消耗
- 提高响应速度:当任务到达时,任务可以不需要等到线程创建就能立即执行
- 提高线程的可管理性:线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池技术可以进行统一分配、调优和监控
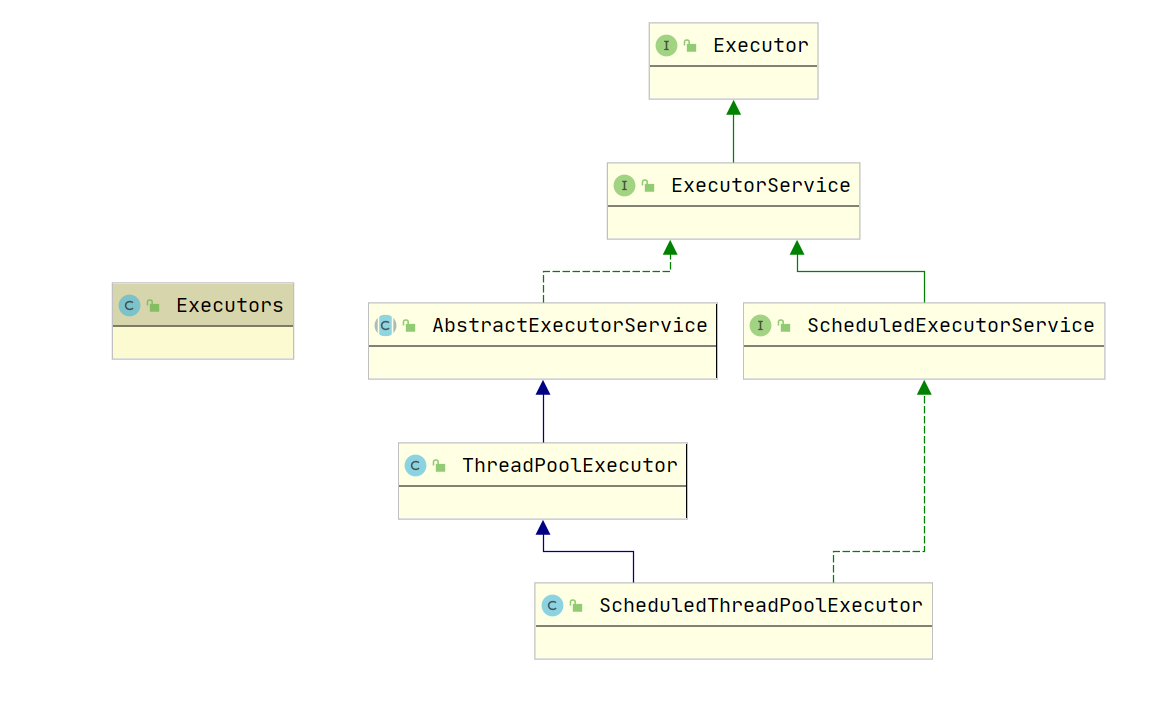
2.2 Executor简介
Executor框架主要由3部分组成:
- 任务:包括被执行任务需要实现的接口:Runnable接口和Callable接口
- 任务的执行:包括任务执行机制的核心接口Executor,以及继承至Executor接口的ExecutorService接口,其中有两个关键类实现了ExecutorService接口:ThreadPoolExecutor,ScheduledThreadPoolExecutor
- 异步计算的结果:包括Future接口和实现Future接口的FutrueTask类
2.3 使用线程池
通过Executors这个工具类,可以创建3种类型的ThreadPoolExecutor:
- FixedThreadPool
- SingleThreadExecutor
- CachedThreadPool
2.3.1 FixedThreadPool
FixedThreadPool被称为可重用固定线程数的线程池,里面传入一个参数表示线程池里最多有多少个线程
public class MyThreadPoolDemo1 {
public static void main(String[] args) {
//创建固定数量的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(4);
for (int i = 1; i <= 10; i++) {
//执行每个线程里的方法
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "\t进来了");
try {
//暂停1秒
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
//关闭线程池
threadPool.shutdown();
}
}

2.3.2 SingleThreadExecutor
SingleThreadExecutor是使用单个worker线程的Executor,使用方法和FixedThreadPool一样
ExecutorService threadPool = Executors.newSingleThreadExecutor();
for (int i = 1; i <= 10; i++) {
//执行每个线程里的方法
threadPool.execute(() -> {
System.out.println(Thread.currentThread().getName() + "\t进来了");
try {
//暂停1秒
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
//关闭线程池
threadPool.shutdown();
2.3.3 CachedThreadPool
CachedThreadPool是一个会根据需要创建新线程的线程池,使用方法和上面两个一样
2.4 线程池七大参数
虽然Executors工具类提供了3个可用的线程池,分别有单个线程的,指定线程数的,可根据需要扩展的,下面来看看其中的源码
//固定线程数的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
//单个work工作的线程
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
//可根据需要扩展的线程池
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
看到上面源码,可发现共同之处,调用的都是ThreadPoolExecutor方法,也就是说Executors提供的3个线程池只不过帮我们向ThreadPoolExecutor传递了一些参数而已,下面是ThreadPoolExecutor的源码
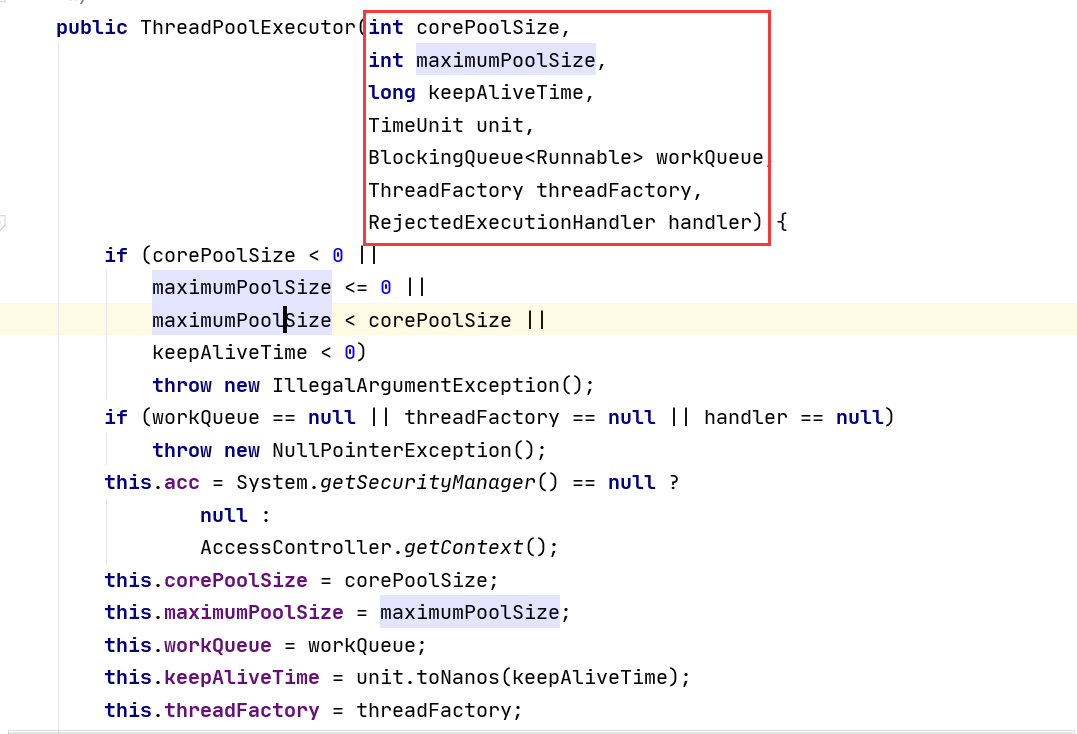
ThreadPoolExecutor一共有七大参数,下面一一介绍
2.4.1 corePoolSize
corePoolSize 是线程池的基本大小,线程池中的常驻核心线程数
当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有基本线程。
2.4.2 maximumPoolSize
maximumPoolSize是线程池的最大数量,线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是,如果使用了无界的任务队列这个参数就没什么效果。 此值必须大于等于1
2.4.3 keepAliveTime和unit
keepAliveTime是线程活动的保持时间,多余的空闲线程的存活时间,当前池中线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁直到只剩下corePoolSize个线程为止
unit是keepAliveTime的单位
2.4.4 workQueue
workQueue:任务队列,被提交但尚未被执行的任务,可以选择的有以下几个:
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原
则对元素进行排序。 - LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通
常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。 - SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用
移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于Linked-BlockingQueue,静态工
厂方法Executors.newCachedThreadPool使用了这个队列。 - PriorityBlockingQueue:一个具有优先级的无限阻塞队列。
这些队列其实就是前面的堵塞队列
2.4.5 threadFactory
表示生成线程池中工作线程的线程工厂,用于创建线程,一般默认的即可
2.4.6 handler
handler饱和策略,当队列和线程池都满了,说明线程池处于饱和状态,那么必须采取一种策略处理提交的新任务。这个策略默认情况下是AbortPolicy,表示无法处理新任务时抛出异常。在JDK 1.5中Java线程池框架提供了以下4种策略。
- AbortPolicy:直接抛出异常。
- CallerRunsPolicy:只用调用者所在线程来运行任务。
- DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。
- DiscardPolicy:不处理,丢弃掉。
当然,也可以根据应用场景需要来实现RejectedExecutionHandler接口自定义策略。如记录日志或持久化存储不能处理的任务。
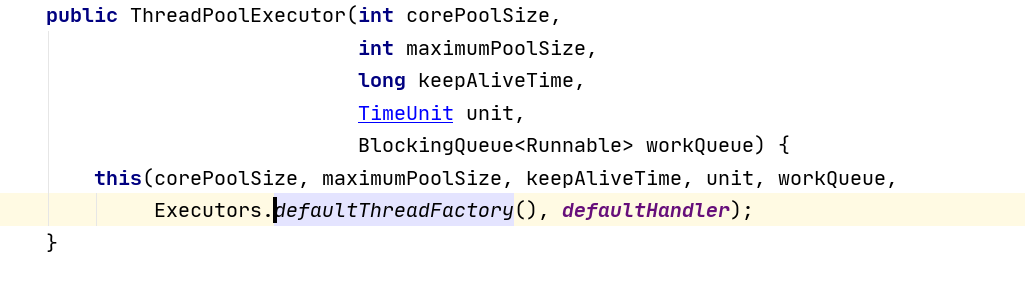

可见,饱和策略默认使用的是AbortPolicy
2.5 线程池的底层工作原理
在上面使用线程池的时候都是调用execute方法,这个方法对理解线程池的工作原理非常重要:
public void execute(Runnable command) {
//如果任务为null,则直接抛出异常
if (command == null)
throw new NullPointerException();
//The main pool control state, ctl, is an atomic integer packing
//ct1保存线程的运行状态
int c = ctl.get();
//首先判断当前线程池执行的任务数是否小于corePoolSize 如果小于新建一个线程,并将任务添加到该线程中 然后启动线程
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果当前线程数大于corePoolSize,那么就来到下面的逻辑
//通过isRunning判断线程的状态只有运行的线程,并且队列不满时才能加入到工作队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//再次获取线程的状态,如果不是Running就从队列里移除
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//如果addWorker失败 则直接启动拒绝策略
else if (!addWorker(command, false))
reject(command);
}
-
在创建了线程池后,开始等待请求。
-
当调用execute()方法添加一个请求任务时,线程池会做出如下判断:
- 如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务;
- 如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列;
- 如果这个时候队列满了且正在运行的线程数量还小于maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
- 如果队列满了且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略来执行。
-
当一个线程完成任务时,它会从队列中取下一个任务来执行。
-
当一个线程无事可做超过一定的时间(keepAliveTime)时,线程会判断:
-
如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉。
-
所有线程池的所有任务完成后,它最终会收缩到corePoolSize的大小。
-
下面通过图再次加深理解
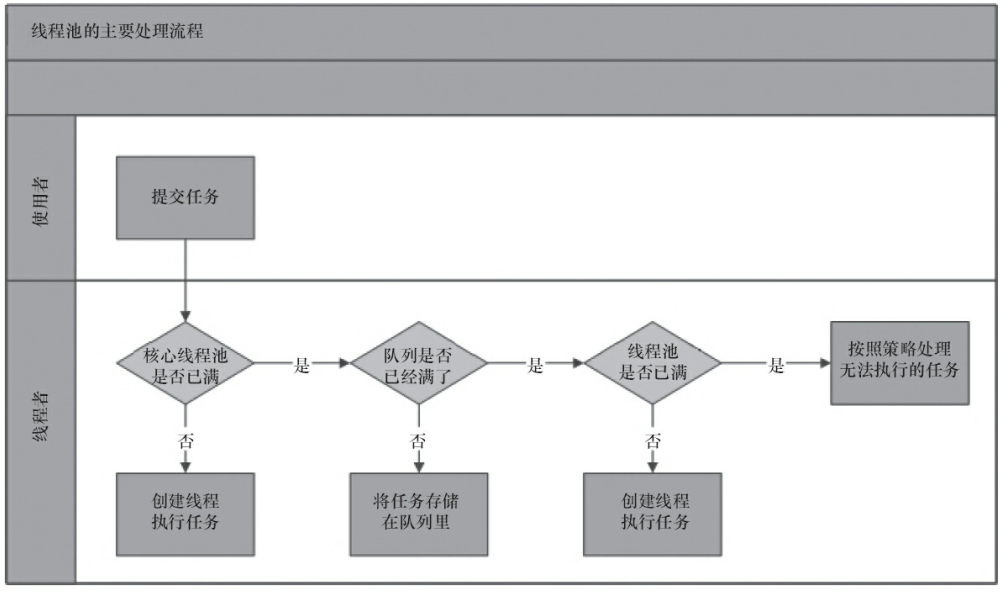
- 线程池判断核心线程池里的线程是否都在执行任务。如果不是,则创建一个新的工作线程来执行任务。如果核心线程池里的线程都在执行任务,则进入下个流程。
- 线程池判断工作队列是否已经满。如果工作队列没有满,则将新提交的任务存储在这个工作队列里。如果工作队列满了,则进入下个流程。
- 线程池判断线程池的线程是否都处于工作状态。如果没有,则创建一个新的工作线程来执行任务。如果已经满了,则交给饱和策略来处理这个任务。
也就是说,线程池的工作流程要检查3个地方,当线程数越来越多的时候,检查corePoolSize,workQueue堵塞队列是否已满,maxmumPoolSize最大线程数是否已经达到,如果再增加线程,那么启动饱和策略,这和线程池的七大参数都是相关的
2.6 合理的配置线程池
虽然Executors向我们提供了3中创建线程的方式,而且CachedThreadPool还可以根据需要创建线程,但是在真正的工作中还是需要自己定义线程池的参数的,具体原因可以看看CachedThreadPool的源码
public static ExecutorService newCachedThreadPool () {
//可以看到最大容量为Integer.MAX_VALUE
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
那么其他两个呢?FixedThreadPool和SingleThreadExecutor使用的是无界的LinkedBlockingQueue(虽然叫做有界的,但是最大容量是Integer.MAX_VALUE,所以这里也叫无界的,我强行解释,因为《Java并发艺术编程》里说这个是无界的),CachedThreadPool使用的是SynchronousQueue。
所以说,FixedThreadPool、SingleThreadExecutor和CachedThreadPool都有可能会撑爆内存,造成oom,所以一般使用自定义参数的线程池
要想合理的配置线程池,首先要分析其任务特性,可以从以下几个角度来分析:任务的性质、任务的优先级、任务的执行时间、任务的依赖性