我们从SEER数据库下载到数据库后,一个很重要的步骤就是把数据库随机分为建模组和验证组,一般来说的话是用70%的数据建模,30%的数据进行验证。因为我们很难找到和SEER数据库类似的数据进行外部验证,因此只能对数据进行拆分来验证。下图这个范文,作者就是使用了数据7:3的拆分


今天我们来说说怎么通过R语言来对SEER数据库按比例拆分为建模集和验证集,还是使用我们常用的既往乳腺癌的数据,
先把数据导入
tr1<- sample(nrow(bc),0.7*nrow(bc))##随机无放抽取
bc_train <- bc[tr1,]#70%数据集
bc_test<- bc[-tr1,]#30%数据集

OK,数据已经随机抽取好了,把它写成文件就好了
write.csv(bc_train,file = "bc_train.csv")
write.csv(bc_test,file = "bc_test.csv")
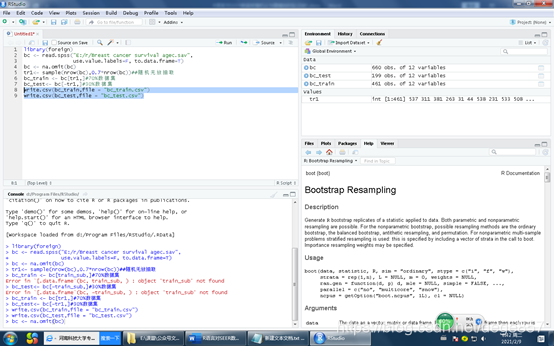
OK,完成,虽然很简单,也是很实用的。
本公众号提供了SPSS、Stata对seer数据库整套挖掘课程,零基础,简单上手,欢迎订阅。
更多精彩文章请关注公众号:零基础说科研
