数组定义方法
方法一:
数组名=(value0 value1 value2 …)

方法二:
数组名=([0]=value [1]=value [2]=value …)

方法三:
列表名=“value0 value1 value2…”
数组名=($列表名)

方法四:
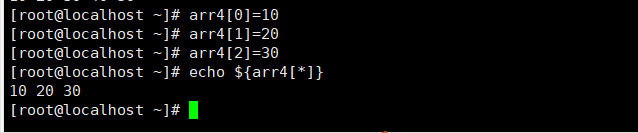
数组名[0]=“value”
数组名[1]=“value”
数组名[2]=“value”
数组包含的数据类型
数值类型
字符类型(使用" "或’ '定义)
获取数组长度


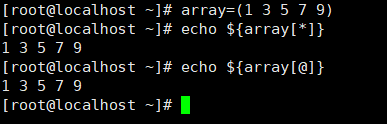
获取数据列表
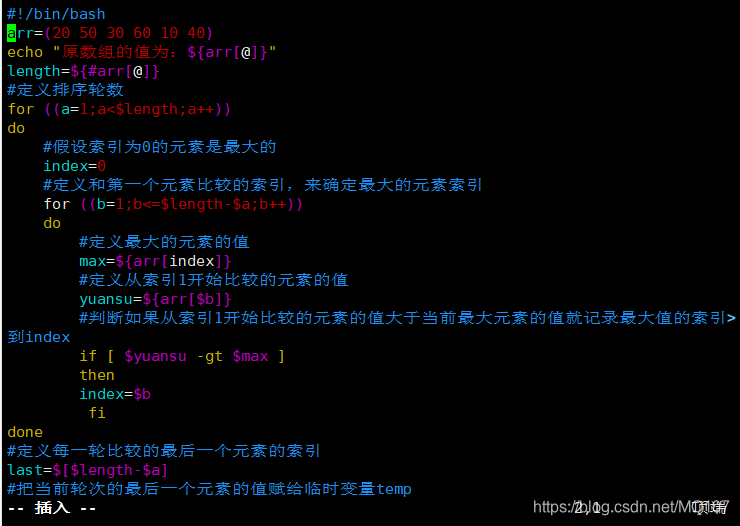
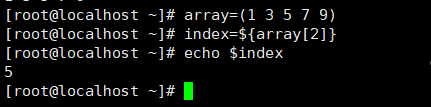
读取某下标赋值
数组遍历

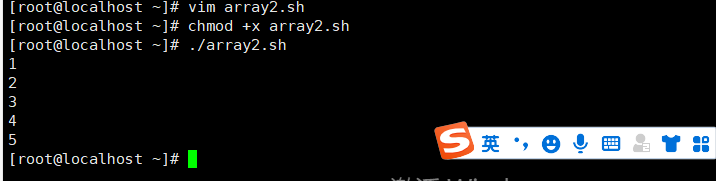
数组切片
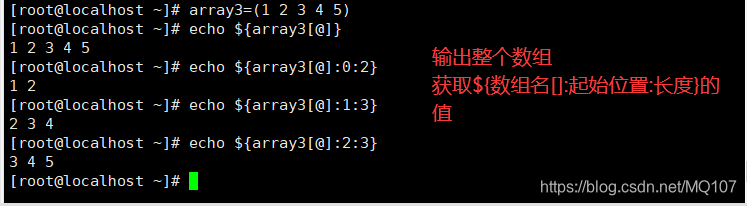
数组替换



数组删除


数组追加元素
方法一:

方法二:
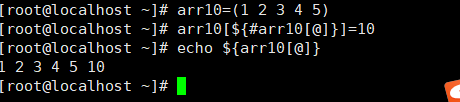
方法三:

双引号不能省略,否则,当数组array_name中存在包含空格的元素时会按空格将元素拆分成多个
不能将“@”替换为“”,如果替换为“”,不加双引号时与“@”的表现一致,加双引号时,会将数组array_name中的所有元素作为一个元素添加到数组中
方法四:
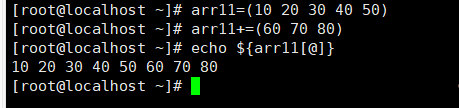
待添加元素必须用“()”包围起来,并且多个元素用空格分隔
向函数传数组参数
如果将数组变量作为函数参数,函数只会取数组变量的第一个值。
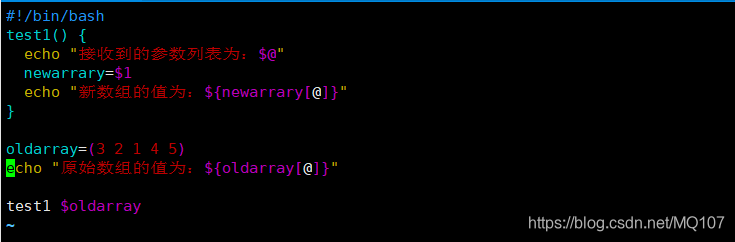
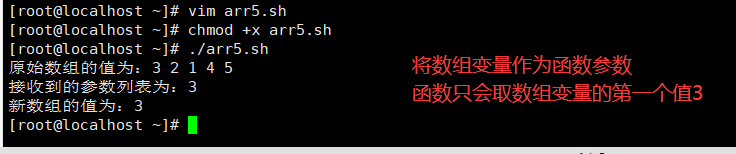
解决这个问题则需要将数组变量的值分解成单个的值,然后将这些值作为函数参数使用。在函数内部,再将所有的参数重新组合成一个新的数组变量。
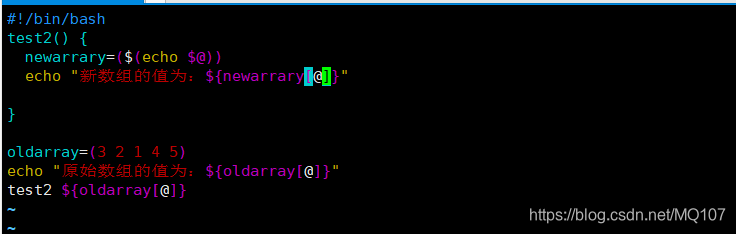

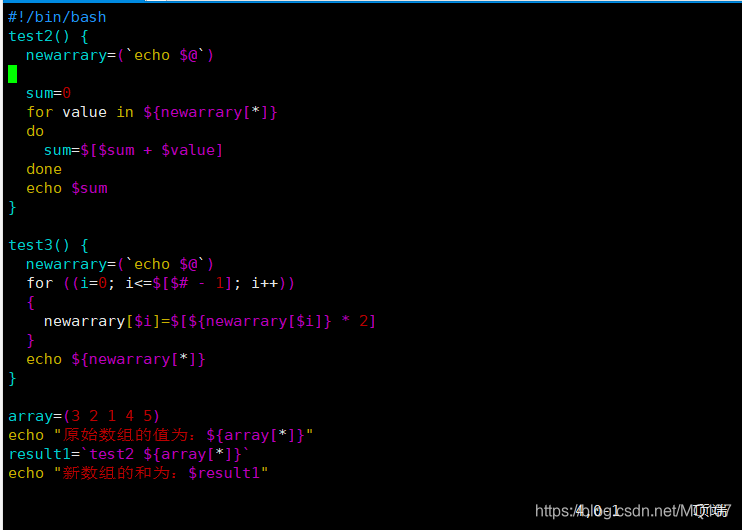
从函数返回数组

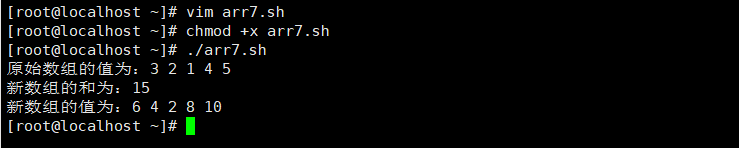
冒泡排序
类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动。
基本思想:
冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部。
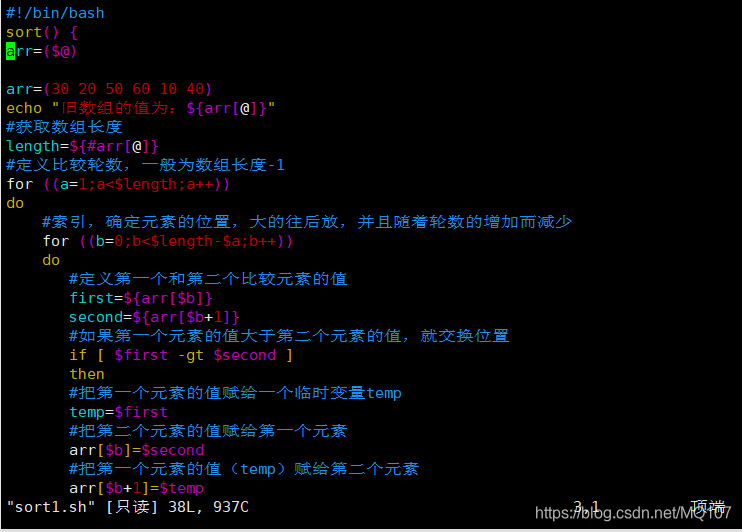
算法思路
冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少。
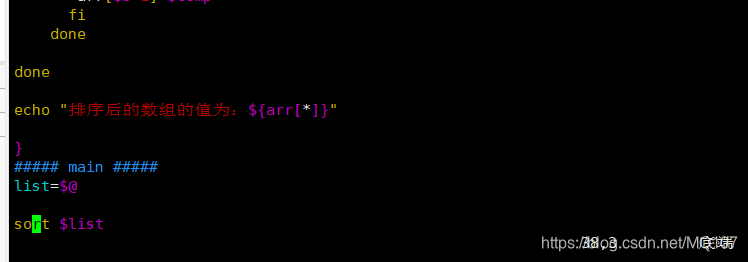

直接选择排序
与冒泡排序相比,直接选择排序的交换次数更少,所以速度更快
基本思想:
将指定排序位置与其它数组元素分别对比,如果满足条件就交换元素值,注意这里区别冒泡排序,不是交换相邻元素,而是把满足条件的元素与指定的排序位置交换(如从最后一个元素开始排序),这样排序好的位置逐渐扩大,最后整个数组都成为已排序好的格式。