
作者 | Corby Rosset译者 | 王强策划 | 钰莹
Turing Natural LanguageGeneration(T-NLG,图灵自然语言生成)是微软开发的一款 170 亿参数语言模型,它在许多下游 NLP 任务上的表现均超过了现有的顶尖水平。我们向学术界展示了这个模型的一个 demo,其中包括了它的自由格式生成、问题回答和摘要功能,以供反馈和研究之用。<|本段结束|>
上述文字(的英文原文)是由 Turing-NLG 语言模型自己生成的。
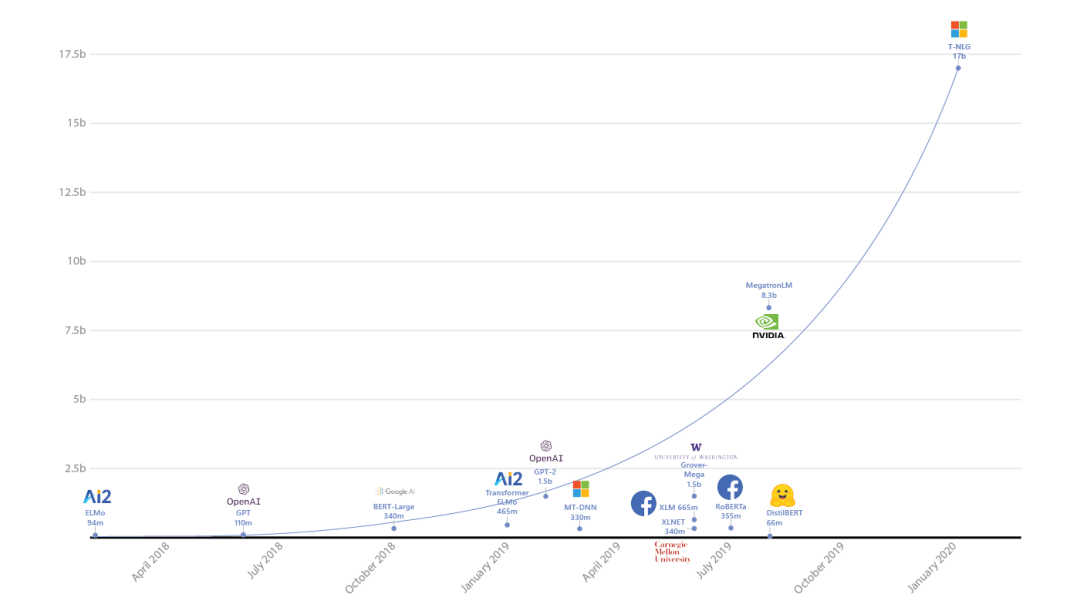
诸如 BERT 和 GPT-2 之类的大规模深度学习语言模型(LM)从互联网上发布的几乎所有文本中学习到了数以十亿计的参数,并提升了几乎所有下游自然语言处理(NLP)任务(包括问题解答、会话代理和文档理解等)的发展水平。
先进的自然语言生成技术可以转化为多种现实应用,例如协助作者撰写内容,帮助人们汇总一长段文本来节省时间,或改善数字助理的客户体验。当下的趋势是自然语言模型规模越大,产生的结果就越好,在这样的背景下 微软图灵项目 就推出了图灵自然语言生成(T-NLG)技术,这是有史以来发布的规模最大的模型,拥有 170 亿个参数,在各种语言建模基准测试上的成绩均优于之前最顶尖的水平,并且在许多实际任务(包括摘要和问题解答等)上的表现也很出色。这一成果背后的最大功臣就是 DeepSpeed 库(与 PyTorch 兼容)和 ZeRO 优化器 带来的突破性进展,相关内容可参阅这一篇 博客文章)。
我们向学术界的一小批用户发布了一个 T-NLG 的私有 demo,其中包括自由格式生成、问题回答和摘要功能,以供初步测试和反馈之用。
T-NLG:大型语言生成模型的好处
T-NLG 是一款基于 Transformer 的语言生成模型,这意味着它可以生成词汇来完成开放式文本任务。除了补足未完成的句子外,它还可以直接对输入的问题生成答案,或对输入的文档生成摘要。

T-NLG 之类的生成模型对于 NLP 任务来说是很重要的,因为我们的目标是在任何情况下都尽可能像人类那样直接、准确和流畅地响应。以前,问题解答和摘要系统需要从文档中提取现有内容,这些内容可以用作备用答案或摘要,但它们往往看起来不那么自然和连贯。借助 T-NLG,我们就可以针对个人文档或电子邮件主题自然地给出摘要或回答问题。
我们观察到了这样的事实:只要模型更大,预训练数据更加多样化,更为全面,那么即使所用的训练实例数量较少,模型在推广到多个下游任务时也能表现得更好。因此,我们认为训练一个大型中心化多任务模型,并在众多任务中共享其能力,比为每个任务单独训练新模型的做法更有效率。
预训练 T-NLG:硬件和软件突破
任何具有超过 13 亿个参数的模型都无法装入单个 GPU(甚至有 32GB 内存的 GPU 都不行),因此这个模型本身必须在多个 GPU 之间并行化,或分解成多个片段。我们利用了几项硬件和软件突破性成果来训练 T-NLG:
我们利用 NVIDIA DGX-2 硬件配置和 InfiniBand 连接,加快了 GPU 之间的通信。
我们使用张量切片,在 NVIDIA Megatron-LM 框架中将模型分片到四个 NVIDIA V100 GPU 上。
DeepSpeed with ZeRO 使我们可以降低模型并行度(从 16 减到 4),并将每个节点的批大小增加到 4 倍,还将训练时间减少到了三分之一。有了 DeepSpeed,我们就能用较少的 GPU 训练非常大的模型,从而提高了效率;它仅用 256 个 NVIDIA GPU 就能以 512 的批大小进行训练,而单独使用 Megatron-LM 则需要 1024 个 NVIDIA GPU。DeepSpeed 还兼容 PyTorch。
生成的 T-NLG 模型具有 78 个 Transformer 层,其隐藏层节点大小为 4256,有 28 个 attention head。为了和 Megatron-LM 的结果对比,我们使用了与 Megatron-LM 相同的超参数和学习计划来对模型进行预训练,使用了自回归生成损失函数,1024 长度的 Token 序列,训练了 30 万步,批大小为 512。学习计划遵循 3200 个线性预热步骤,最大学习速率为 1.5×10-4,余弦衰减超过 500,000 个步骤,精度为 FP16。我们使用与 Megatron-LM 模型相同的数据类型来训练模型。
我们还对比了预训练的 T-NLG 模型在标准语言任务,例如 WikiText-103 和 LAMBADA 在下一个单词的预测准确度(越高越好)上的性能。下表显示,我们在 LAMBADA 和 WikiText-103 上都打破了已有的最好纪录。其中 Megatron-LM 是 NVIDIA Megatron 模型公开发布的结果数据。
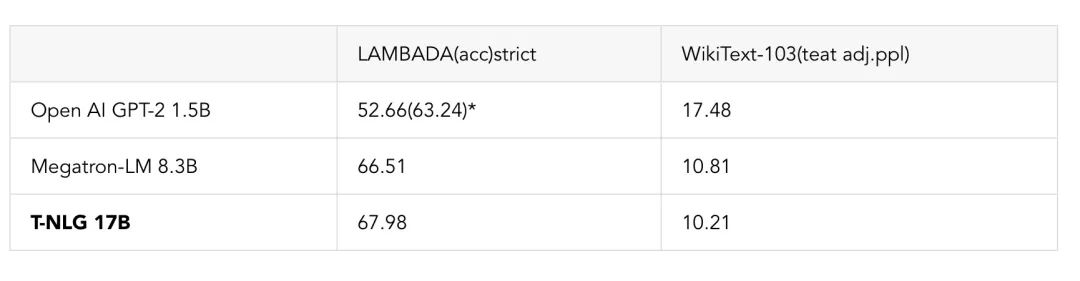
*OpenAI 使用了额外的处理技术(停用词过滤)来获得比独立模型更好的成绩。Megatron 和 T-NLG 都不使用这种停用词过滤技术。
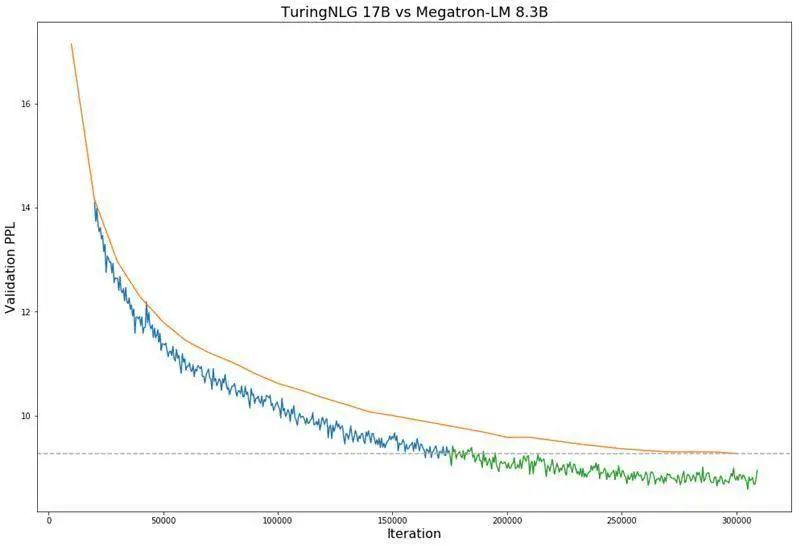
下面的图 1 显示了与 Megatron-LM 相比,T-NLG 在验证困惑度方面的表现。
直接回答问题和零次回答能力
许多 Web 搜索用户希望在问问题时,能看到结果页面的顶部显示一个直接回答问题的卡片。这些卡片往往会从某段上下文中找出一句话来做答案。我们的目标是直接回答用户的问题,从而更明确地满足他们信息需求。例如,大多数搜索引擎解答下面这个问题时会展示一段文字,并高亮显示其中的“Tristan Prettyman”(参见下面的示例)。
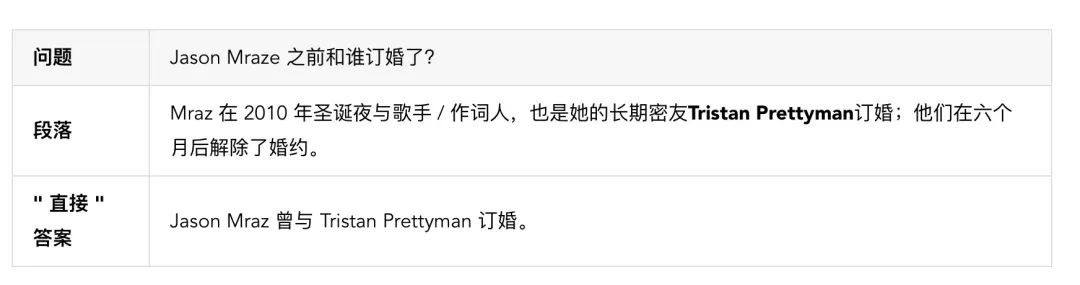
相比之下,T-NLG 会直接用完整的句子回答问题。这种能力在 Web 搜索以外的场景中用途更大——例如,当用户向 AI 助手询问有关自己个人数据的问题(例如电子邮件或 Word 文档)时,这种能力能让助手更智能地给出答案。
这一模型还能够实现“零次”(zero shot)问题解答,意味着无需上下文即可回答问题。下面的示例中模型没有什么段落可用,只有问题。在这类情况下,模型通过在预训练过程中获得的知识来生成答案。

由于 ROUGE 评分) 取决于真值(ground-truth)答案,其无法反映其他质量指标,例如事实正确性和语法正确性等,因此我们请人工注释者来评估我们之前的基准系统(一个类似于 CopyNet 的 LSTM 模型)和当前的 T-NLG 模型。要实现对事实正确性的自动评估还有很多工作要做。
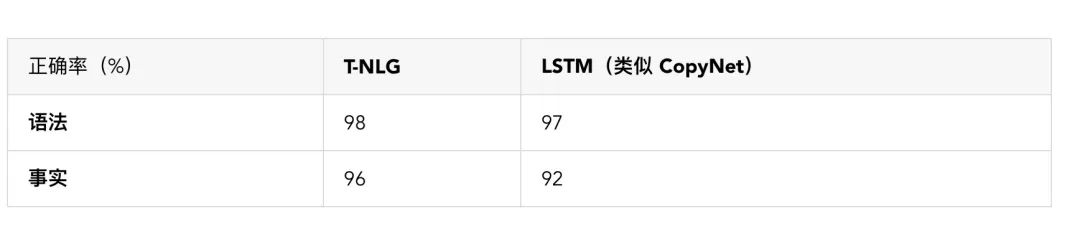
我们还注意到,较大的预训练模型要达到较好的学习成果时所需的下游任务实例更少。我们最多只有 100,000 个“直接”回答问题 - 段落 - 答案三元组的实例,但就算只进行了几千次训练,我们的模型仍比 LSTM 基准模型在同一份数据上训练多个 epoch 的表现还更出色。由于收集带注释的监督数据是非常昂贵的,所以这种结果会带来实际的业务收益。
无需太多监督的抽象摘要
NLP 领域中的摘要技术有两种类型:提取——从文档中获取少量句子作为摘要;抽象——用 NLG 模型像人类一样生成摘要。T-NLG 的目标不是复制现有内容,而是为各种文本文档(如电子邮件、博客文章、Word 文档甚至 Excel 工作表和 PowerPoint 演示文稿)像人类那样编写抽象摘要。这里的一大挑战是,在所有这些情况下都缺乏监督训练数据:人类并不会每次都明确地总结每种文档类型。T-NLG 的强大在于,它已经非常理解文本,因此无需太多的监督即可胜过我们之前使用的所有技术。
为了使 T-NLG 尽可能通用,从而为各种类型的文本生成摘要,我们在几乎所有公开可用的摘要数据集中以多任务方式调整了 T-NLG 模型,总计约有 400 万个训练实例。我们使用 ROUGE 分数(代表所生成的摘要与参考摘要中的单字组和双字组的匹配程度)与另一种最新的基于 Transformer 的语言模型(称为 PEGASUS,https://arxiv.org/abs/1912.08777),和之前表现最佳的模型进行了对比。
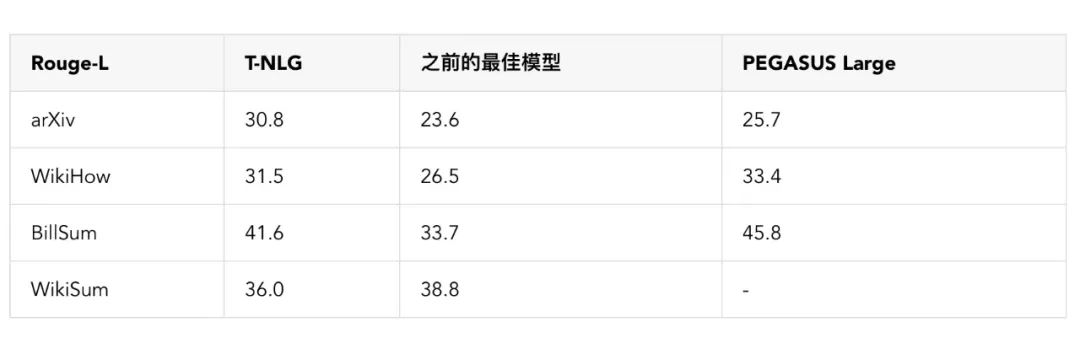
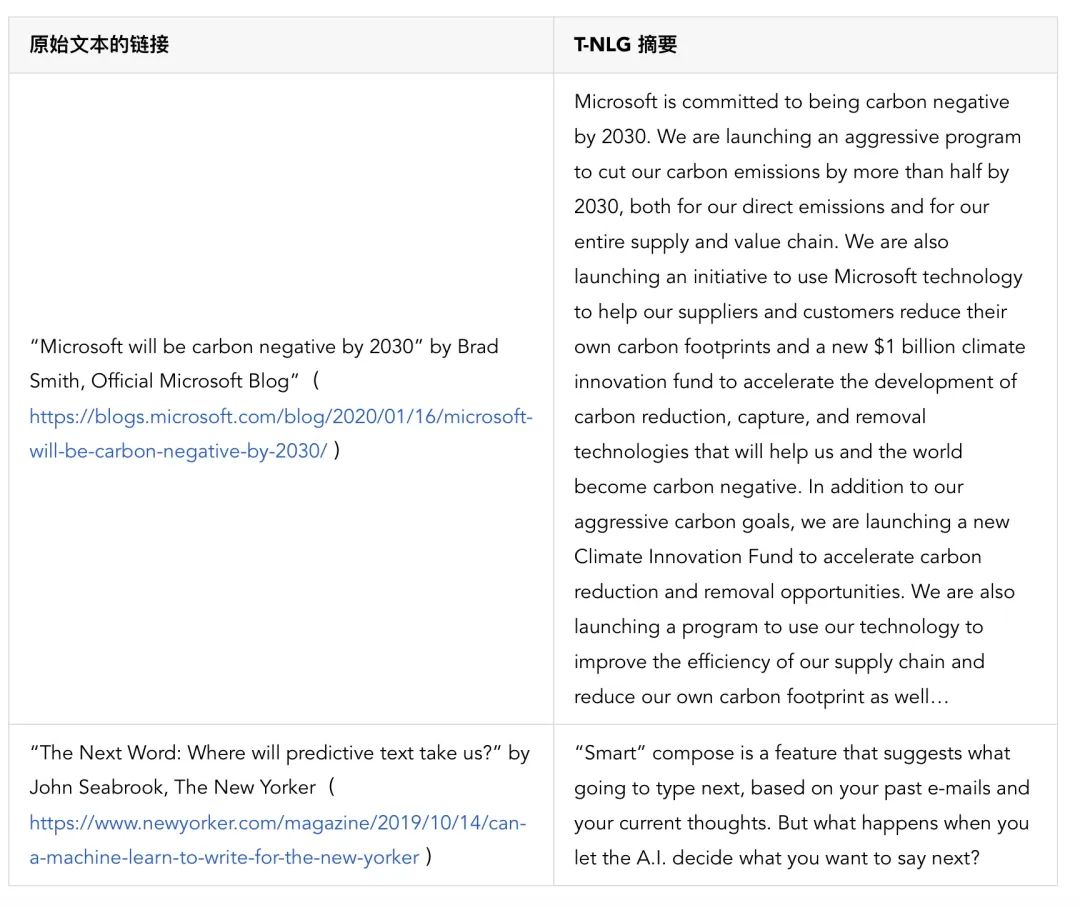
请注意,T-NLG 是以多任务方式,同时在所有数据集上进行训练的。众所周知,ROUGE 评分在摘要任务方面存在缺陷(可以通过多种方式编写很好的抽象摘要),因此我们在下面提供了一些公开发表的文章的输出摘要,以供比较。
T-NLG 的未来应用
T-NLG 在自然语言生成方面已经取得了突破,为微软和我们的客户提供了新的机遇。除了通过文档和电子邮件摘要来节省用户时间之外,T-NLG 还可以为作者提供写作辅助,并回答读者可能对文档提出的问题来增强微软 Office 套件的体验。此外,它为对话更流畅的 聊天机器人 和 数字助理)铺平了道路,这样自然语言生成技术就可以与客户对话,从而帮助企业改善客户关系管理和销售工作。随着我们进一步提高语言模型的质量,我们也对新的可能性兴奋不已。
关于图灵项目:
T-NLG 是一个名为图灵项目的更大计划的一部分,该计划是一个应用研究小组,致力于在文本和图像处理方面采用深度学习技术来开发微软产品。我们的工作正在主动集成到多个微软产品中,包括 Bing、Office 和 Xbox 等。