1. 项目技术的变更(RabbitMQ—>Kafka)
以前我们公司用到的MQ是RabbitMQ,后来随着项目的功能需求,我们替换成Kafka会更加的适合;
项目的功能:每辆车每5s中发送GPS数据到服务器,当车辆数够多的时候,RabbitMQ已经明显不如Kafka;所以我们MQ改用Kafka;
2. RabbitM与Kafka的区别(区别一)
Kafka的体量比RabbitMQ的体量更大
什么意思呢?
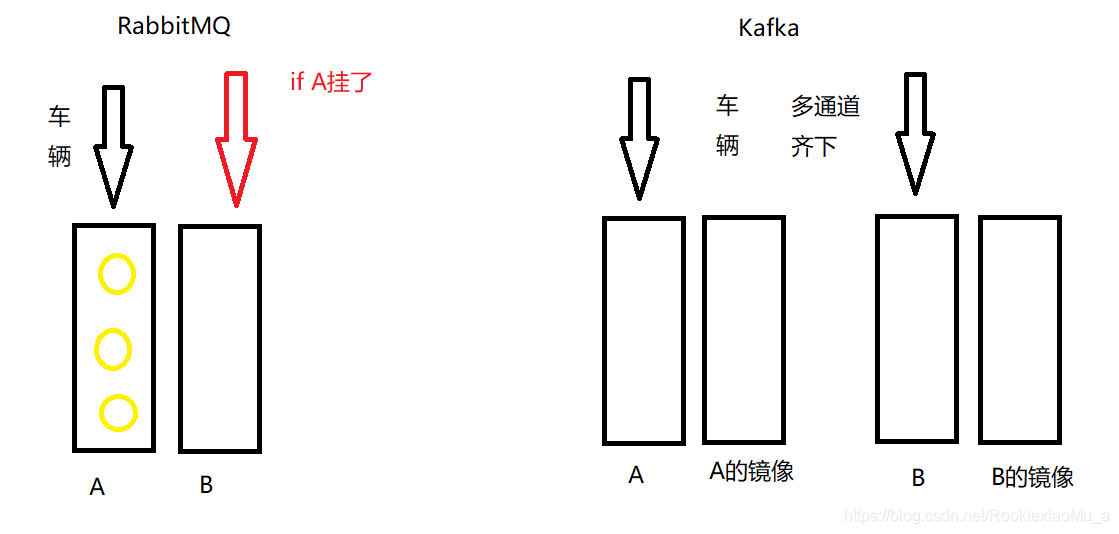
打个比方:比如我们高速路口有n个收费口A、B、C…(收费口=队列,车辆=消息)
如果是RabbitMQ那么车辆是先从A收费口进去,其他收费口空闲状态,如果这个时候A收费口挂了,这个时候车辆才会去B收费口,同时A收费口的车辆合并到B收费口…
如果换成Kafka那么车辆是从各个收费口进去,如果这个时候A收费口挂了,那么这时候会有A的 镜像 顶替上来,同时A的车辆合并到镜像…
这也是Kafka吞吐量大的原因…
3. JS的setInterval结合HTTP和WebSocket
需求:前端浏览器需要从后台获取数据,但是后台不一定有数据(此数据从终端使用Kafka异步发送过来),所以我们要定时从后台获取数据。
解决方法一:JS的setInterval结合HTTP
之前我们是使用JS的定时器:setInterval定时发送HTTP请求从后台获取数据的,但是这种方法low,太low…
后来我们想到了另一个解决方法:使用WebSocket
解决方法二:WebSocket
WebSocket:WebSocket 是 HTML5 开始提供的一种在单个 TCP 连接上进行全双工通讯的协议。
WebSocket 使得客户端和服务器之间的数据交换变得更加简单,允许服务端主动向客户端推送数据。在 WebSocket API 中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接,并进行双向数据传输。
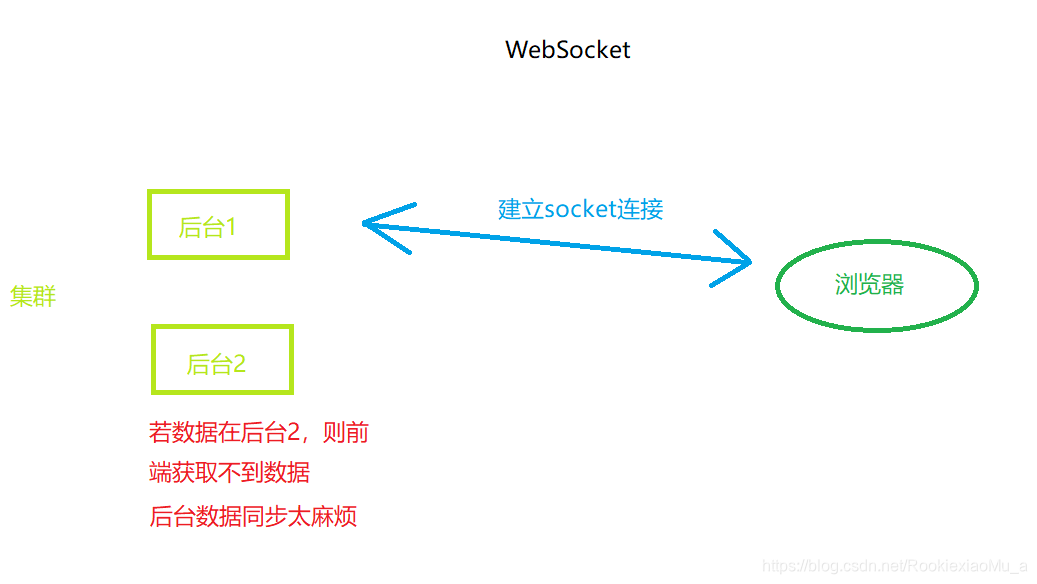
听起来似乎问题已经完美的解决了,不!!!这样会有一个问题,结合实际环境,我们并不知道后台有多少台服务器,如果我们使用了集群,每个服务有多台服务器,假设有A、B两台,那么这个时候前端浏览器只和A建立了连接,那如果你的请求到了B服务器怎么办?那浏览器就获取不到数据了,如果后台要做数据同步的话太麻烦,low…

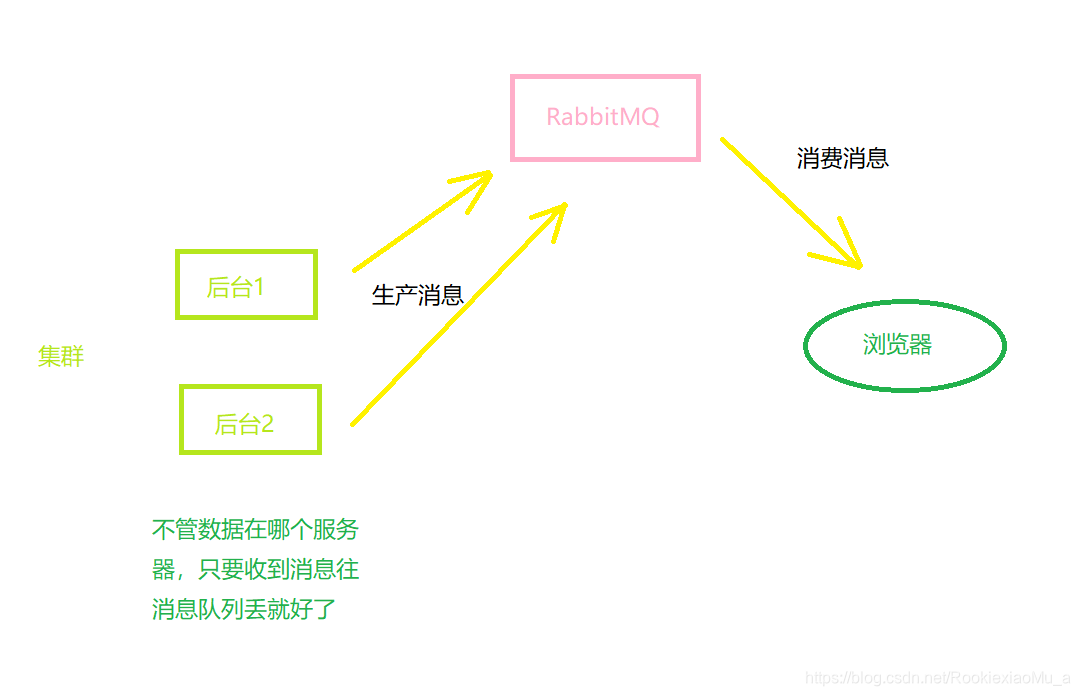
解决方法三:RabbitMQ
后台接收(消费)到终端的数据,这个时候将数据发送的RabbitMQ队列中,然后前端消费消息,这也是我们要说的RabbitMQ与Kafka的第二的区别:RabbitMQ封装了WebSocket,我们在前端可以写js代码消费RabbitMQ的消息,这样就完美达到了我们的目的。
PS:RabbitMQ不仅提供了JS的连接,还提供了Android的连接。