1. 冒泡排序
比较相邻的元素,如果前一个大于后一个,就交换二者;对每一对相邻元素做同样的工作,每一轮把当前未排序部分的最大数字移到最后。
void bubbleSort(int[] array){
int length = array.length;
for(int i=0; i < length-1; i++){
for(int j=0; j < length-i-1; j++){
if(array[j] > array[j+1]){
int temp = array[j];
array[j] = array[j+1];
array[j+1] = temp;
}
}
}
}
2. 选择排序
每一轮在未排序的部分找到最小值的index,然后将index对应的值交换到已排序部分的末尾,以此类推,直至排完所有元素。
void selectSort(int[] array){
int length = array.length;
for(int i=0; i < length-1; i++){
int minIndex = i;
for(int j=i+1; j < length; j++){
if(array[j] < array[minIndex]){
minIndex = j;
}
}
int temp = array[i];
array[i] = array[minIndex];
array[minIndex] = temp;
}
}
3. 插入排序
从第一个元素开始,取出下一个元素,在已排序的部分中从后往前扫描,如果该元素(已排序)大于当前取出的新元素,就将其往后移一位,直到找到已排序的元素小于等于新元素的位置,将新元素插入到该位置,重复进行直至排完所有。
void insertSort(int[] array){
int length = array.length;
for(int i=1; i < length; i++){
int cur = array[i];
int preIndex = i-1;
while (preIndex>=0 && array[preIndex]>cur){
array[preIndex+1] = array[preIndex];
preIndex--;
}
array[preIndex+1] = cur;
}
}
4. Shell排序
分组插入排序,先将整个待排元素序列分割成若干个子序列(由相隔某个“增量gap”的元素组成的),对每个子序列进行插入排序,然后逐渐缩减增量gap再进行插入排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次插入排序。
void insertSort(int[] array){
int length = array.length;
for(int i = 1; i < length; i++){
int cur = array[i];
int preIndex = i-1;
while (preIndex>=0 && array[preIndex]>cur){
array[preIndex+1] = array[preIndex];
preIndex--;
}
array[preIndex+1] = cur;
}
}
5. 归并排序
分治的思想,先将序列递归拆半分成多个子序列,再将各个子序列排序后归并。
void merge(int[] A,int l,int m,int r){
int[] L = new int[m-l+1];
int[] R = new int[r-m];
for(int i = 0; i < m-l+1; i++){
L[i] = A[l+i];
}
for(int i = 0; i < (r-m); i++){
R[i] = A[m+i+1];
}
int i = 0;
int j = 0;
for(int k = l; k <= r; k++){
if(i >= L.length){
A[k] = R[j++];
}else if(j >= R.length){
A[k] = L[i++];
}else if(L[i] < R[j]){
A[k] = L[i++];
}else {
A[k] = R[j++];
}
}
}
void mergesort(int[] A,int l,int r){
if(l<r){
int m = (l+r)/2;
mergesort(A,l,m);
mergesort(A,m+1,r);
merge(A,l,m,r);
}
}
6. 快速排序
快速排序从数组中找一个pivot,将小于piovt的放到左边,大于pivot的放到右边
快速排序vs归并排序
前者基于数值大小划分,后者基于index划分。
快速排序不需要额外的存储空间,这一点使得它优于归并排序,因为归并排序需要额外一倍存储空间存储排序数组。
void swap(int[]A,int s,int r){
if(s!=r){
A[s] += A[r];
A[r] = A[s] - A[r];
A[s] = A[s] - A[r];
}
}
int findpivot(int[] A,int l,int r){
return (l+r)/2;
}
int partition(int[] A,int l,int r,int p){
do{
while(A[l]<p) {
l++; }
while((l<r) && A[r]>=p) {
r--; }
swap(A,l,r);
}while (l<r);
return l;
}
void quicksort(int[] A,int l,int r){
if(l<r) {
int p = findpivot(A, l, r);
swap(A, p, r);
int k = partition(A, l, r - 1, A[r]);
swap(A, k, r);
quicksort(A, l, k - 1);
quicksort(A, k + 1, r);
}
}
7. 堆排序
先建立大顶堆,每次将堆顶元素与末尾元素交换,再调整堆结构,这样循环到排序完成。
void swap(int[]A,int s,int r){
if(s!=r){
A[s] += A[r];
A[r] = A[s] - A[r];
A[s] = A[s] - A[r];
}
}
void modifyHeap(int[] heap, int index,int len){
// 计算左右节点index
int left = 2*index + 1, right = 2*index +2, maxIndex = index;
// 找到最大值
if(left < len && heap[left] > heap[maxIndex]){
maxIndex = left;
}
if(right < len && heap[right] > heap[maxIndex]){
maxIndex = right;
}
//调整位置
if(maxIndex != index){
swap(heap,maxIndex,index);
modifyHeap(heap,maxIndex,len);
}
}
void buildHeap(int[] heap){
int len = heap.length;
for(int i = len/2-1; i >= 0; i--){
modifyHeap(heap,i,len);
}
}
void heapSort(int[] array){
// 建立大顶堆
buildHeap(array);
// 取堆顶,然后调整堆结构
for(int i = array.length-1; i > 0; i--){
swap(array,0,i);
modifyHeap(array,0,i);
}
}
8. 计数排序
计数排序不是基于比较的排序算法,其核心在于将序列中元素出现的次数的统计结果存到一个count数组,然后按count数组中的统计结果对原数组赋值。
其排序速度快于任何比较排序算法。当range不是很大并且序列比较集中时,计数排序是一个很有效的排序算法。
void countSort(int[] array){
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for(int i = 0; i < array.length; i++){
max = Math.max(max,array[i]);
min = Math.min(min,array[i]);
}
int range = max - min + 1;
int[] count = new int[range];
for(int i = 0; i < array.length; i++){
count[array[i]-min]++;
}
int index = 0;
for(int i = 0; i < count.length; i++){
while (count[i]>0){
array[index++] = i + min;
count[i]--;
}
}
}
9. 桶排序
桶排序的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排),最后从不是空的桶里把排好序的数据拼接起来。
void bucketSort(int[] array){
// 计算最大值和最小值
int max = Integer.MIN_VALUE;
int min = Integer.MAX_VALUE;
for(int i = 0; i < array.length; i++){
max = Math.max(max,array[i]);
min = Math.min(min,array[i]);
}
// 计算桶的数量,然后创建
int bucketNum = (max - min)/array.length + 1;
ArrayList<ArrayList<Integer>> bucketArr = new ArrayList<>(bucketNum);
for(int i = 0 ; i < bucketNum; i++){
bucketArr.add(new ArrayList<Integer>());
}
// 将每个元素放进桶
for(int i = 0; i < array.length; i++){
int num = (array[i] - min)/array.length;
bucketArr.get(num).add(array[i]);
}
// 对每个桶排序
for(int i = 0; i < bucketArr.size(); i++){
Collections.sort(bucketArr.get(i));
}
// 将桶中元素赋值到原数组
int index = 0;
for(int i = 0; i < bucketArr.size(); i++){
for(int j = 0; j < bucketArr.get(i).size(); j++){
array[index++] = bucketArr.get(i).get(j);
}
}
}
10. 基数排序
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。
基数排序基于分别排序,分别收集,所以是稳定的。但基数排序的性能比桶排序要略差,每一次关键字的桶分配都需要O(n)的时间复杂度,而且分配之后得到新的关键字序列又需要O(n)的时间复杂度。假如待排数据可以分为d个关键字,则基数排序的时间复杂度将是O(d*2n) ,当然d要远远小于n,因此基本上还是线性级别的。
// 计算最大位数
static int maxbits(int[] array){
int max = Integer.MIN_VALUE;
for(int i = 0; i < array.length; i++){
max = Math.max(max,array[i]);
}
int res = 0;
while (max !=0){
max /= 10;
res++;
}
return res;
}
// 获取位数数值
static int getDigit(int num, int digit){
return (num/(int) Math.pow(10, digit-1)) % 10;
}
// 基数排序
static void radixSort(int[] array, int start, int end, int digit){
final int radix = 10;
int[] count = new int[radix];
int[] bucket = new int[end-start+1];
for(int d=1; d <= digit; d++){
// 清空old数据
for(int i = 0; i < radix; i++){
count[i] = 0;
}
// 统计数量
for(int i = start; i <= end; i++){
count[getDigit(array[i],d)]++;
}
// 计算位置
for(int i = 1; i < radix; i++){
count[i] = count[i] + count[i-1];
}
// 按桶位置排序
for(int i = end; i >= start; i--){
int j = getDigit(array[i],d);
count[j]--;
bucket[count[j]] = array[i];
}
for(int i = start,j = 0; i <= end; i++,j++){
array[i] = bucket[j];
}
}
}
static void radixSort(int[] array){
if(array == null || array.length<2){
return;
}
radixSort(array,0,array.length-1,maxbits(array));
}
排序算法梳理
1. 复杂度分析
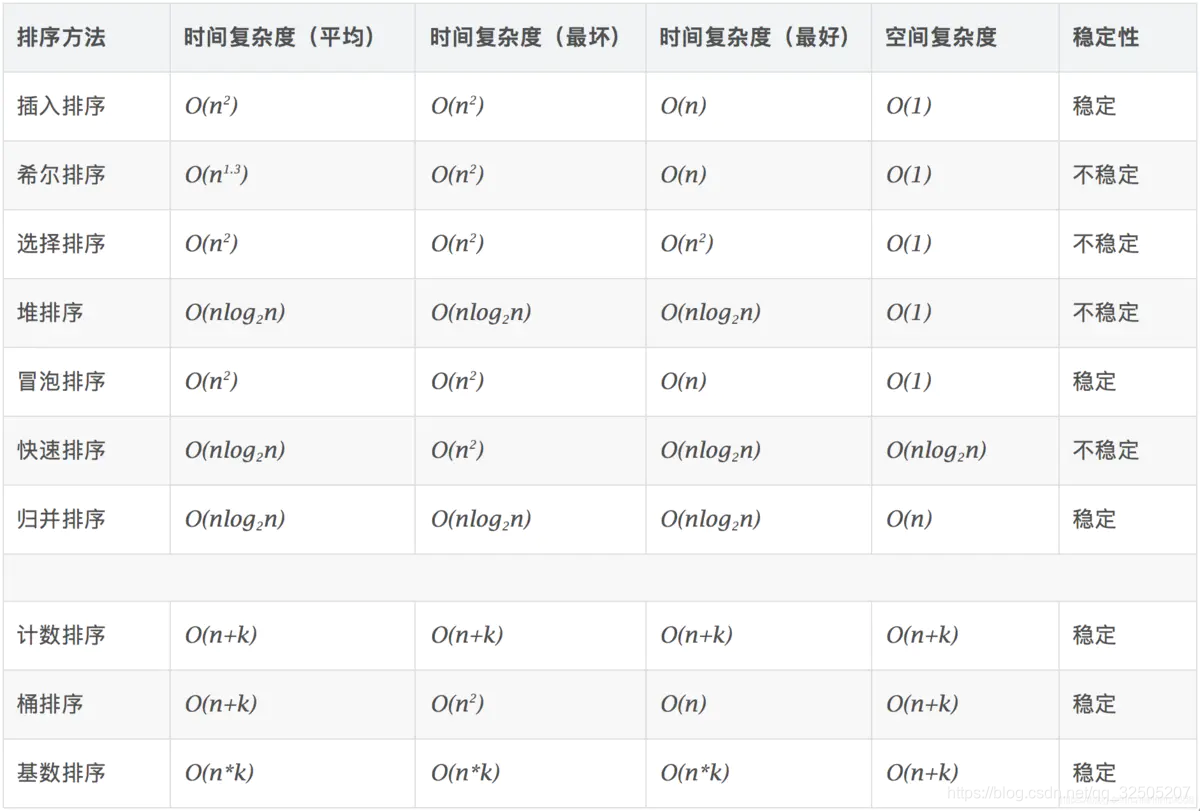
稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
2. 算法分类
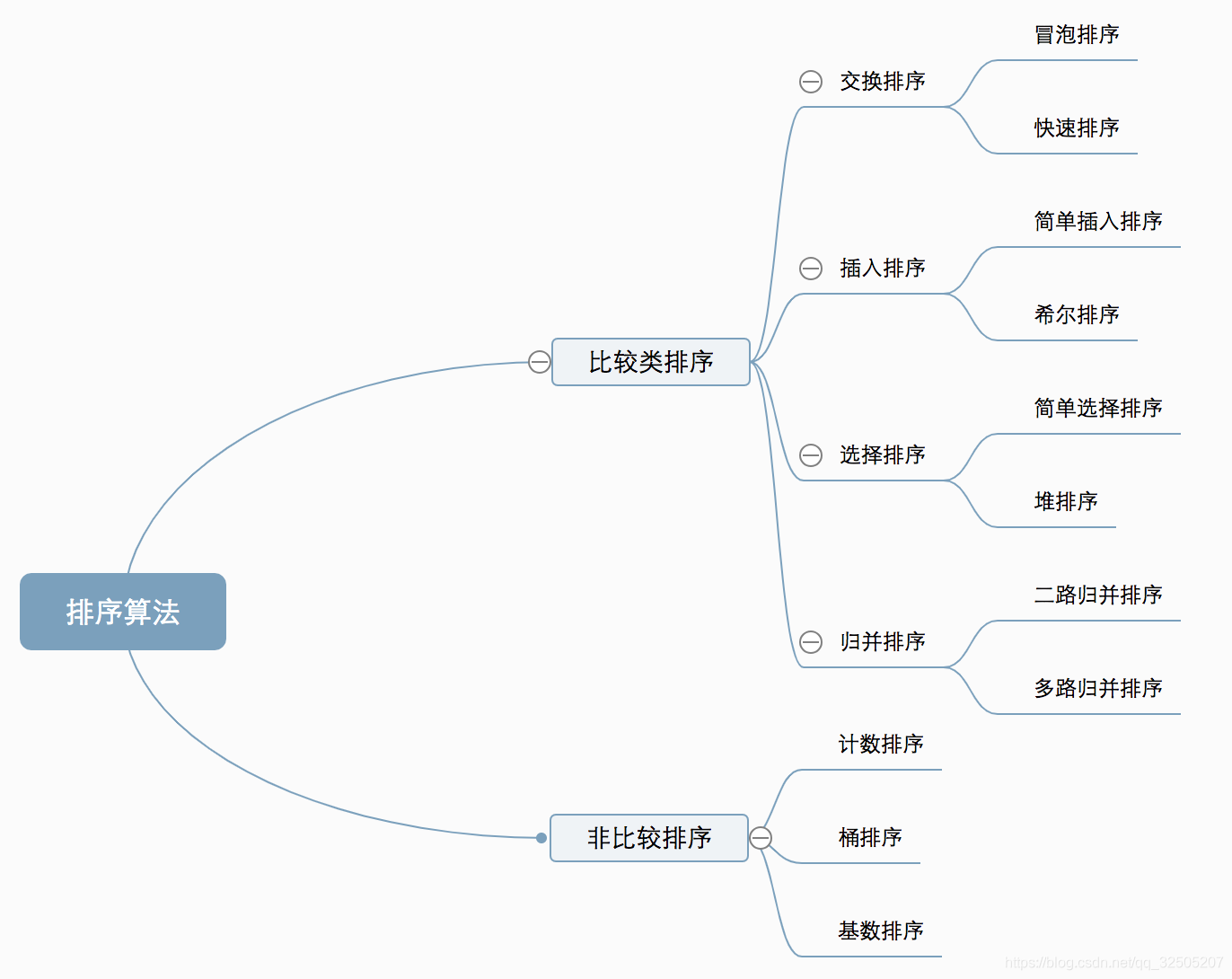
十种常见排序算法可以分为两大类:
- 比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此也称为非线性时间比较类排序。
- 非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,空间换时间,以线性时间运行,因此也称为线性时间非比较类排序。