第三章:JDK并发包
3.1 多线程的团队协作:同步控制
3.1.1 synchronized的功能扩展: 重入锁
重入锁完全可以代替synchronized关键字。
例子:
public class ReenterLock implements Runnanble{
public static ReentrantLock Lock = new ReentrantLock();
public static int Count = 0;
public static class MyThread extends Thread{
@Override
public void run(){
for(int i=0;i<10000;i++){
Lock.lock();
try {
Count++;
}finally {
Lock.unlock();
}
}
}
}
public static void main(String args[]) throws InterruptedException{
MyThread t1 = new MyThread();
MyThread t2 = new MyThread();
t1.start();t2.start();
t1.join();t2.join();
System.out.println(Count);
}
}
运行结果:20000
如上,可看到重入锁对逻辑控制的灵活性要远远优于关键字synchronized,因为开发人员必须手动指定何时加锁、何时释放锁。
一个线程还能被允许连续获得多次同一把锁,但是获得了多少次就要释放多少次。
重入锁的高级功能:
1、中断响应请
lockInterruptibly()方法:这是一个可以对中断进行响应的锁申请动作,即在等待锁的过程中,可以响应中断。(即 获得锁,但优先响应中断)
重入锁可以响应中断,从而能够解决死锁问题,即当多个线程陷入死锁状态时,线程都在互相等待对方的资源,此时中断其中几个,那么被中断的线程就会放弃等待、释放资源,并停止执行,从而解决死锁问题。
2、锁申请等待时限
为了避免死锁,还可以用tryLock()方法进行限时等待。
tryLock(参数1,参数2):参数1表示等待时长,参数2表示计时单位。
例:lock.try(5,TimeUnit.SECONDS); //等待5秒后还为获得锁就返回请求锁失败
tryLock()还可以不带参数直接运行。在这种情况下,当前线程会尝试获得锁,如果锁并未被其他线程占用,则申请成功,立即返回true。如果锁被其他线程占用,会立即返回false。这种模式不会引起线程的等待,因此也不会产生死锁。
3、公平锁
在大多数情况下,锁的申请都是非公平的。当多个线程申请锁时,系统只会从这个锁的等待队列中随机挑取一个(而不是先申请先得)。因此不能保证公平性。
公平锁:按照时间的先后顺序,保证先到者先得,后到者后得。 因此公平锁的一大特点是它不会产生饥饿现象。
设置重入锁的公平性:(其构造函数)
public ReentrantLock(boolean fair)
当参数fair为true时,表示锁是公平的。要实现公平锁,就需要系统维护一个有序队列,因此公平锁的实现成本比较高,性能却非常低下,因此,在默认情况下,锁是非公平的。如果没有什么特别的需求,尽量别用公平锁。
3.1.2 重入锁的好搭档:Condition
就类似操作系统里学的条件变量。
Condition接口提供的基本方法:
Void await() throws InterrupteException;
Void awaitUninterruptibly();
Long awaitNanos(long nanosTimeout) throws InterrupteException;
Boolean await(long time, TimeUnit unit) throws InterrupteException;
Boolean awaitUntil(Data deadline) throws InterrupteException;
Void signal();
Void signalAll();
以上方法的含义:
- await()方法会使当前线程等待,同时释放当前锁,当其他线程使用signal()或signalAll()方法时,线程会重新获得锁并继续执行。或者当线程被中断时,也能跳出等待。这和object.wait()方法很相似。
- awaitUninterruptibly()方法与wait()方法基本相同,但它不会在等待的过程中响应中断。
- signal()方法用于唤醒一个在等待中的线程。signalAll()会唤醒所有正在等待的线程。这和object.notify()方法很相似。
3.1.3 允许多个线程同时访问:信号量(Semaphore)
信号量的构造函数:
Public Semaphore(int permits);//permits表示许可证的张数
Public Semaphore(int permits, boolean fair); //第二个参数可以指定是否公平
信号量的方法:
Public void acquire();
Public void acquireUninterruptibly();
Public boolean tryAcquire();
Public boolean tryAcquire(long timeout, TimeUnit unit);
Public void release();
- acquire()方法尝试获得一个准入的许可。若无法获得,则线程会等待,直到申请到许可或者当前线程被中断。
- acquireUninterruptibly()方法与acquire()方法类似,但不响应中断。
- tryAcquire()尝试获得一个许可,成功返回true失败返回false,它不会进行阻塞等待,立即返回。
- release()用于在线程访问资源结束后,释放一个许可,以使其他等待许可的线程可以进行资源访问。
3.1.4 ReadWriteLock 读写锁
读写锁的访问约束情况:
- 读-读不互斥:读读之间不阻塞。
- 读-写互斥:读阻塞写,写也会阻塞读。
- 写-写互斥:写写阻塞。
3.1.5 倒计数器:CountDownLatch
CountDownLatch 是一个非常实用的多线程控制工具类。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
例如在火箭发射前,为了保证万无一失,往往还要进行各项设备、仪器的检查。只有等所有的检查完毕后,引擎才能点火。这种场景就非常适合使用 CountDownLatch。它可以使得点火线程等待所有检查线程全部完工后,再执行。
CountDownLatch 的构造函数接收一个整数作为参数,即当前这个计数器的计数个数:
public CountDownLatch(int count)
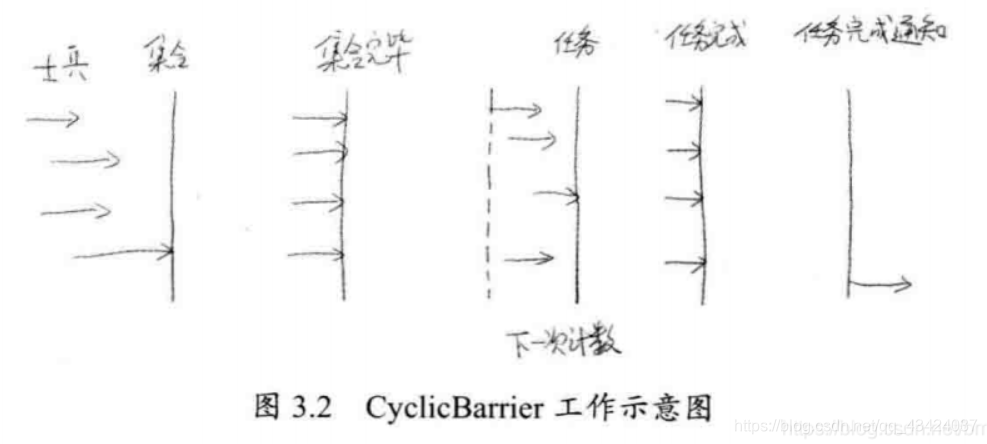
3.1.6 循环栅栏:CyclicBarrier
CyclicBarrier 是另外一种多线程并发控制实用工具。和 CountDownLatch 非常类似,它也可以实现线程间的计数等待,但它的功能比 CountDownLatch 更加复杂且强大。
CyclicBarrier 可以理解为循环栅栏。用来阻止线程继续执行,要求线程在栅栏处等待。 Cyclic 意为循环,也就是说这个计数器可以反复使用。比如,将计数器设置为 10,那么凑齐第一批 10 个线程后,计数器就会归零,然后接着凑齐下一批 10 个线程。
CyclicBarrier的构造函数:
public CyclicBarrier(int parties,Runnable barrierAction)
- parties 表示计数总数,也就是参与的线程总数。
- barrierAction 表示当计数器一次计数完成后,系统会执行的动作。
例子:
public class CyclicBarrierDemo {
public static class Soldier implements Runnable{
private String soldierName;
private final CyclicBarrier cyclic;
Soldier(CyclicBarrier cyclic,String soldierName){
this.cyclic = cyclic;
this.soldierName = soldierName;
}
@Override
public void run() {
try{
//等待其他士兵到齐
cyclic.await();
doWork();
//等待所有士兵完成工作
cyclic.await();
}catch (InterruptedException e){
e.printStackTrace();
}catch (BrokenBarrierException e){
e.printStackTrace();
}
}
void doWork(){
try {
Thread.sleep(1000);
}catch (InterruptedException e){
e.printStackTrace();
}
System.out.println(soldierName+" :任务完成");
}
}
public static class BarrierRun implements Runnable{
boolean flag;
int N;
public BarrierRun(boolean flag,int N){
this.flag = flag;
this.N = N;
}
@Override
public void run() {
if(flag){
System.out.println("司令:[士兵"+N+"个,任务完成!]");
}else{
System.out.println("司令:[士兵"+N+"个,集合完毕!]");
flag = true;
}
}
}
public static void main(String[] args) {
final int N = 10;
Thread[] allSoldier = new Thread[N];
boolean flag = false;
CyclicBarrier cyclic = new CyclicBarrier(N,new BarrierRun(flag,N));
//设置屏障点,主要是为了执行这个方法
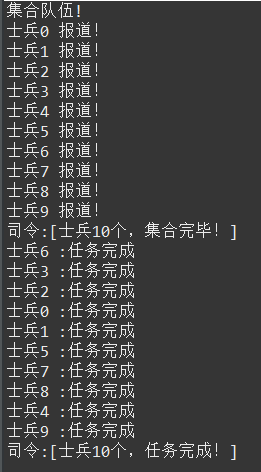
System.out.println("集合队伍!");
for(int i = 0;i < N;i++){
System.out.println("士兵"+i+" 报道!");
allSoldier[i] =new Thread(new Soldier(cyclic,"士兵"+i));
allSoldier[i].start();
}
}
}
执行结果:
CyclicBarrier.await() 方法可能会抛出两个异常:
- InterruptedException:在等待过程中,线程被中断。大部分迫使线程等待的方法都可能会抛出这个异常,使得线程在等待时依然可以响应外部紧急事件。
- CyclicBarrier 特有的 BrokenBarrierException:一旦遇到这个异常,则表示当前的CyclicBarrier已经破损了,可能系统已经没有办法等待所有线程到齐了。如果继续等待,可能就是徒劳无功的,因此,还是就地散货,打道回府吧!
3.1.7 线程阻塞工具类:LockSupport3
LockSupport 是一个非常方便实用的线程阻塞工具,它可以在线程内任意位置让线程阻塞。 和 Thread.suspend() 相比,它弥补了由于 resume() 在前发生,导致线程无法继续执行的情况。和 Object.wait() 相比,它不需要先获得某个对象的锁,也不会抛出 InterruptedException 异常。
LockSupport的方法:
- park() 可以阻塞当前线程,类似的还有 parkNanos() 、parkUntil() 等方法。它们实现了一个限时的等待。
- unpark() 取消阻塞,使得一个许可变为可用。
3.1.8 Guava和RateLimiter限流
Guava是Goole下的一个核心库,提供了一大批设计精良、使用方便的工具类。许多Java项目都是用Guava作为其基础工具类来提升开发效率,我们可以认为Guava是JDK标准库的重要补充。 RateLimiter是Guava中的一款限流工具。
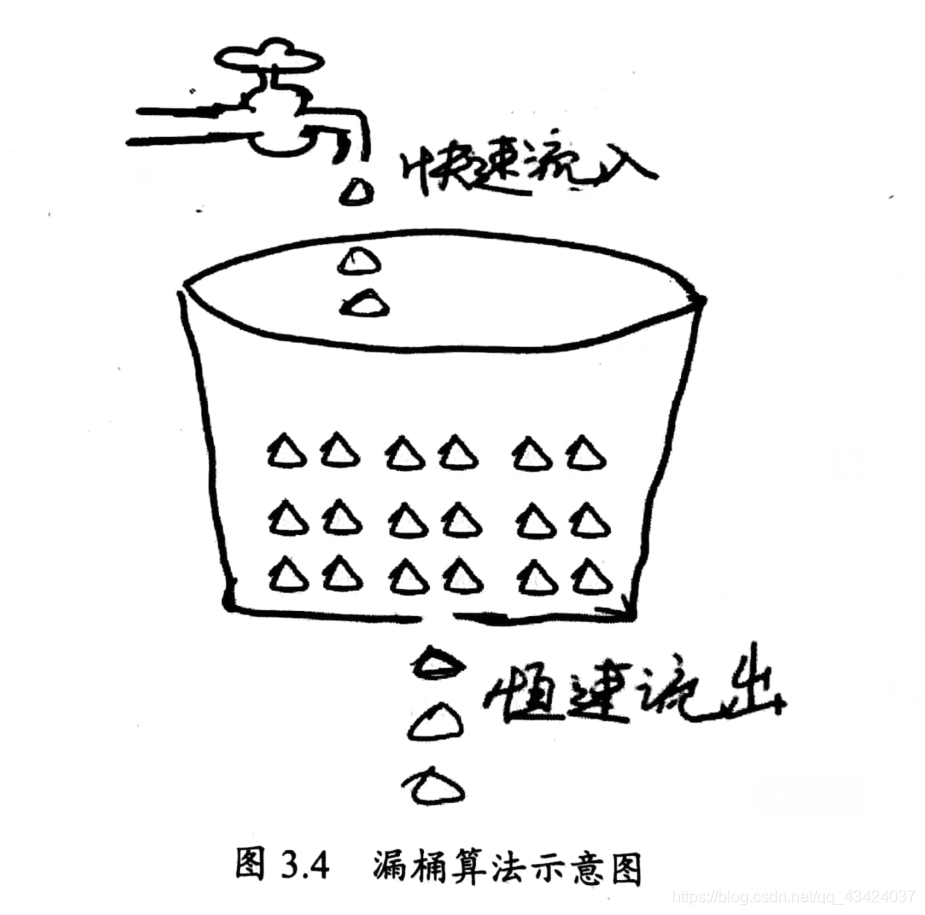
一般化的限流算法:漏桶算法和令牌桶算法
- 漏桶算法:利用一个缓存区,当有请求进入系统时,无论请求的速率如何,都先在缓存区保存,然后以固定的流速流出缓存区进行处理。
- 令牌桶算法:该算法是一种反向的漏桶算法。在令牌桶算法中,桶中存放的不再是请求,而是令牌。处理程序只有拿到令牌后才能对请求进行处理。如果没有令牌,那么处理程序要么丢弃请求,要么等待可用的令牌。为了限制流速,该算法在每个单位产生一定量的令牌存入桶中。
RateLimiter正是采用了令牌桶算法。
3.2 线程复用:线程池
3.2.1 什么是线程池
为了避免系统频繁地创建和销毁线程,从而引入线程池的概念。线程池就是已经创建好的线程的集合。 当需要使用线程时,可以从线程池里随便拿一个空闲线程,当完成工作时,并不着急关闭线程,而是将这个线程退回到线程池中,方便其他人使用。(即创建线程变成从线程池获取空闲线程,关闭线程变成向线程池归还线程)
3.2.2 不要重复发明轮子:JDK对线程池的支持
为了能够更好地控制多线程,JDK 提供了一套 Executor 框架,帮助开发人员有效地进行线程控制,其本质就是一个线程池。
Executor 框架提供了各种类型的线程池,主要有以下工厂方法:
public static ExecutorService newFixedThreadPool(int nThreads)
public static ExecutorService newSingleThreadExecutor()
public static ExecutorService newCachedThreadPool()
public static ScheduledExecutorService newSingleThreadScheduledExecutor()
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
- newFixedThreadPool() 方法:该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
- newSingleThreadExecutor() 方法:该方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
- newCachedThreadPool() 方法:该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
- newSingleThreadScheduledExecutor() 方法:该方法返回一个 ScheduledExecutorService 对象,线程池大小为 1。ScheduledExecutorService 接口在 ExecutorService 接口之上扩展了在给定时间执行某任务的功能,如在某个固定的延时之后执行,或者周期性执行某个任务。
- newScheduledThreadPool() 方法:该方法也返回一个 ScheduledExecutorService 对象,但该线程池可以指定线程数量。
ScheduledExecutorService并不一定会立即安排执行任务。它其实是起到了计划任务的作用。它会在指定的时间,对任务进行调度。
线程池的使用:(以newFixedThreadPool() 方法为例)
public class ThreadPoolDemo {
public static class MyTask implements Runnable {
@Override
public void run() {
System.out.println(System.currentTimeMillis() + ":Thread ID:" + Thread.currentThread().getId());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
MyTask task = new MyTask();
//创建了固定大小的线程池,内有5个线程。
ExecutorService es = Executors.newFixedThreadPool(5);
for (int i = 0; i < 0; i++) {
//依次向线程池提交了10个任务。
es.submit(task);
}
}
}
cheduledExecutorService 对象的主要方法:
在这里插入代码片public ScheduledFuture<?> scheduled(Runnable command,
long delay,
TimeUnit unit);
public ScheduledFuture<?> scheduledAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit);
public ScheduledFuture<?> scheduledWithFixedDelay(Runnable command,
long initialDelay,
long delay,
TimeUnit unit)
- schedule():会在给定时间,对任务进行一次调度。
- scheduleAtFixedRate():创建一个周期性任务。任务开始于给定的初始延时。后续的任务按照给定的周期进行:后续第一个任务将会在 initialDelay+period 时执行,后续第二个任务将在initialDelay+2*period时进行,依此类推。
- scheduleWithFixedDelay():创建并执行一个周期性任务。任务开始于初始延时时间,后续任务将会按照给定的延时进行,即上一个任务的结束时间到下一个任务的开始时间的时间差。
scheduleAtFixedRate()使用示例:
public class ScheduledExecutorServiceDemo {
public static void main(String[] args) {
ScheduledExceptorService ses = Executors.newScheduledThreadPool(10);
//如果当前的任务没有完成,则调度也不会启动
ses.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(1000);
System.out.println(System.currentTimeMillis() / 1000);
} catch (InterruptedExcepiton e) {
e.printStackTrace();
}
}
}, 0, 2, TimeUnit.SECONDS);
}
}
注意 :如果任务遇到异常,那么后续的所有子任务都会停止调度,因此,必须保证异常被及时处理,为周期性任务的稳定调度提供条件。
3.2.3 刨根究底:核心线程池的内部实现
newFixedThreadPool() 、newSingleThreadExecutor()、 newCachedThreadPool() 的实现方式:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L,TimeUnit.MILLISECONDS,new LinkedBolockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService(new ThreadPoolExecutor(1, 1,0L,TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS,new SynchronousQueue<Runnable>());
}
由以上线程池的实现代码可以看到,它们都只是 ThreadPoolExecutor 类的封装。
ThreadPoolExecutor 最重要的构造函数:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
- corePoolSize:指定了线程池中的线程数量。
- maximumPoolSize:指定了线程池中的最大线程数量。
- keepAliveTime:当线程池线程数量超过 corePoolSize 时,多余的空闲线程的存活时间。即,超过 corePoolSize 的空闲线程,在多长时间内,会被销毁。
- unit:keepAliveTime 的单位。
- workQueue:任务队列,被提交但尚未被执行的任务。
- threadFactory:线程工厂,用于创建线程,一般用默认的即可。
- handler:拒绝策略。当任务太多来不及处理,如何拒绝任务。
workQueue的说明:
参数 workQueue 指被提交但未执行的任务队列,它是一个 BlockingQueue 接口的对象,仅用于存放 Runnable 对象。
根据队列功能分类,在 ThreadPoolExecutor 的构造函数中可使用以下几种 BlockingQueue:
-
直接提交的队列:该功能由 SynchronousQueue 对象提供。SynchronousQueue 是一个特殊的 BlockingQueue。SynchronousQueue 没有容量,每一个插入操作都要等待一个相应的删除操作,反之,每一个删除操作都要等待对应的插入操作。如果使用 SynchronousQueue,提交的任务不会被真实的保存,而总是将新任务提交给线程执行,如果没有空闲的进程,则尝试创建新的进程,如果进程数量已经达到最大值,则执行拒绝策略。 因此,使用 SynchronousQueue 队列,通常要设置很大的 maximumPoolSize 值,否则很容易执行拒绝策略。
-
有界的任务队列:有界的任务队列可以使用 ArrayBlockingQueue 实现。ArrayBlockingQueue 的构造函数必须带一个容量参数,表示该队列的最大容量。当使用有界的任务队列时,若有新的任务需要执行,如果线程池的实际线程数小于 corePoolSize,则会优先创建新的线程,若大于 corePoolSize,则会将新任务加入等待队列。若等待队列已满,无法加入,则在总线程数不大于 maximumPoolSize 的前提下,创建新的进程执行任务。若大于 maximumPoolSize,则执行拒绝策略。 可见,有界队列仅当在任务队列装满时,才可能将线程数提升到 corePoolSize 以上,换言之,除非系统非常繁忙,否则确保核心线程数维持在在 corePoolSize。
-
无界的任务队列:无界任务队列可以通过 LinkedBlockingQueue 类实现。与有界队列相比,除非系统资源耗尽,否则无界的任务队列不存在任务入队失败的情况。当有新的任务到来,系统的线程数小于 corePoolSize时,线程池会生成新的线程执行任务,但当系统的线程数达到 corePoolSize 后,就不会继续增加。若后续仍有新的任务加入,而又没有空闲的线程资源,则任务直接进入队列等待。 若任务创建和处理的速度差异很大,无界队列会保持快速增长,直到耗尽系统内存。
-
优先任务队列:优先任务队列是带有执行优先级的队列。它通过 PriorityBlockingQueue 实现,可以控制任务的执行先后顺序。它是一个特殊的无界队列。 无论是有界队列 ArrayBlockingQueue,还是未指定大小的无界队列 LinkedBlockingQueue 都是按照先进先出算法处理任务的。而 PriorityBlockingQueue 则可以根据任务自身的优先级顺序先后执行,在确保系统性能的同时,也能有很好的质量保证(总是确保高优先级的任务先执行)。
3.2.4 超负载了怎么办:拒绝策略
JDK内置的四种拒绝策略:
- AbortPolicy 策略:该策略会直接抛出异常,阻止系统正常工作。
- CallerRunsPolicy 策略:只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。显然这样做不会真的丢弃任务,但是,任务提交线程的性能极有可能会急剧下降。
- DiscardOledestPolicy 策略:该策略将丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试再次提交当前任务。
- DiscardPolicy 策略:该策略默默地丢弃无法处理的任务,不予任何处理。
以上内置的策略均实现了 RejectedExecutionHandler 接口,若以上策略仍无法满足实际应用需要,完全可以自己扩展 RejectedExecutionHandler 接口。RejectedExecutionHandler 的定义如下:
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
- r 为请求执行的任务
- executor 为当前的线程池
3.2.5 自定义线程创建:ThreadFactory
ThreadFactory 是一个接口,它只有一个方法,用来创建线程:
Thread newThread(Runnable r);
当线程池需要新建线程时,就会调用这个方法。
自定义线程示例:
public static void main(String[] args) throws InterruptedException {
MyTask task = new MyTask();
ExecutorService es = new ThreadPoolExecutor(5, 5, 0L, TimeUnit.MILLISECONDS,
new SynchronousQueue<Runnable>(),
new ThreadFactory(){
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setDaemon(true);
System.out.println("create " + t);
return t;
}
});
for (int i = 0; i < 5; i++) {
es.submit(task);
}
Thread.sleep(2000);
}
如上,这个案例使用自定义的 ThreadFactory,一方面记录了线程的创建,另一方面将所有的线程都设置为守护线程,这样,当主线程退出后,将会强制销毁线程池。
3.2.6 我的应用我做主:扩展线程池
ThreadPoolExecutor 也是一个可以扩展的线程池。它提供了 beforeExecute() 、afterExecute() 和 terminated() 三个接口对线程池进行控制。
3.2.7 合理的选择:优化线程池线程数量
线程池的大小对系统的性能有一定的影响。一般来说,确定线程池的大小需要考虑CPU数量、内存大小等因素。

在Java中,可以通过如下代码取得可用的CPU数量:
Runtime.getRuntime().availableProcessors()
3.2.8 堆栈去哪里了:在线程池中寻找堆栈
在线程池讨回异常堆栈的方法:
- 将submit()方法改用为execute()方法
pools.execute(new DivTask(100,i));
- 改造submit()
Future re = pools.submit(new DivTask(100, i));
re.get();
以上两种方法都可以得到部分堆栈信息。(即在这两个异常堆栈中我们只能知道异常是在哪里抛出的,但并不知道这个任务是在哪里提交的。)
为了将堆栈的信息全部挖掘出来,我们需要扩展ThreadPoolExecutor线程池,让它在调度任务之前,先保存一下提交任务线程的堆栈信息:
public class TraceThreadPoolExecutor extends ThreadPoolExecutor{
public TraceThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
@Override
public void execute(Runnable task) {
super.execute(wrap(task, clientTrace(Thread.currentThread().getName()), Thread.currentThread().getName()));
}
@Override
public Future<?> submit(Runnable task){
return super.submit(wrap(task,clientTrace(),Thread.currentThread().getName()));
}
private Exception clientTrace() {
return new Exception("Client stack trace");
}
private Runnable wrap(final Runnable task, final Exception clientTrace, final String name) {
return new Runnable() {
public void run() {
try {
task.run();
} catch (Exception e) {
clientTrace.printStackTrace();
try {
throw e;
} catch (Exception e1) {
e1.printStackTrace();
}
}
}
};
}
}
在第 23 行代码中,wrap() 方法的第 2 个参数为一个异常,里面保存着提交任务的线程的堆栈信息。该方法将我们传入的 Runnable 任务进行一层包装,使之能处理异常信息。当任务发生异常时,这个异常会被打印。
使用扩展后的线程池来执行代码就可以打印出我们需要的异常啦,例:

3.2.9 分而治之:Fork/Join 框架
fork():创建线程
join():等待
在实际使用中,如果毫无顾忌地使用 fork() 开启线程进行处理,那么很有可能导致系统开启过多的线程而严重影响性能。所以,在 JDK 中,给出了一个 ForkJoinPool 线程池,对于 fork() 方法并不急着开启线程,而是提交给 ForkJoinPool 线程池进行处理,以节省系统资源。
在绝大多数情况下,一个物理线程实际上是需要处理多个逻辑任务的。因此,每个线程必然需要拥有一个任务队列。因此,在实际执行过程中,可能遇到这么一种情况:线程 A 已经把自己的任务都执行完成了,而线程 B 还有一堆任务等着处理,此时,线程 A 就会 “帮助” 线程 B,从线程 B 的任务队列中拿一个任务过来处理, 尽可能地达到平衡。 一个值得注意的地方是,当线程试图帮助别人时,总是从任务队列的底部开始拿数据,而线程试图执行自己的任务时,则是从相反的顶部开始拿。
ForkJoinPool 的一个重要的接口:
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task)
你可以向 ForkJoinPool 线程池提交一个 ForkJoinTask 任务。所谓 ForkJoinTask 任务就是支持 fork() 分解以及 join() 等待的任务。ForkJoinTask 有两个重要的子类,RecursiveAction 和 RecursiveTask。它们分别表示没有返回值的任务和可以携带返回值的任务。