在现代系统多核的时代,使用多线程明显了地提高了系统的性能,但是在高并发的环境中,激烈的锁竞争对系统的性能带来的严重的影响,因为对于多线程来说,它不仅要维持每一个线程本身的元数据,还要负责线程之间的切换,不断的挂起,唤醒,浪费了大量的时间,因此,有必要探讨一下如何将多线程中锁的优化做到极致,给系统带来更大的好处。
对于“锁”性能的优化
本文将围绕“锁”优化来讲解,其中会涉及到部分JDK的源码解读,希望通过一些JDK内部的例子来说明锁的优化带来的好处。
在应用层面锁的优化主要有以下几种:
- 减小锁的持有时间
- 减小锁的颗粒度
- 读写锁分离来替换独占锁
- 锁分离
- 锁的粗化
(也许在网上读者可能会看到不同的说法,但其原理上是差不多的,本文是基于JDK1.8的)。
一、减小锁的持有时间
对于使用锁的应用程序而言,在多线程中,只要有一个线程占用了该锁,其他的锁就会等待当前线程释放锁,如果每一个线程持有锁的时间非常长,那么整个系统的性能会大大的降低。以下面一段代码为例:
private synchronized void sync() {
method1();
mutexMethod();
method2();
}明明在并发环境下只需要mutexMethod()方法实现同步,而你对整个方法加锁,而这个方法要调用三个方法,如果method1方法和method2方法是重量级方法,那么不是会浪费大量的时间吗?因此,我们有必要将上面的代码改为下面的代码,减小锁的持有时间来优化系统:
private void sync() {
method1();
synchronized (mutex) {
mutextMethod();
}
method2();
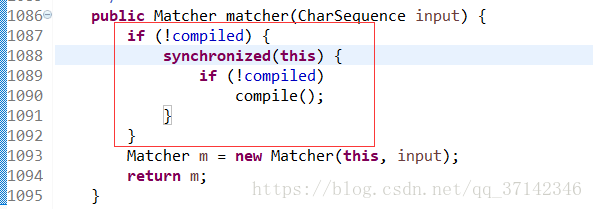
}实际上,在JDK内部也大量的使用该方法来优化锁,比如处理正则表达式的Pattern类的内部的matcher方法只有在表达式没有编译的时候才会局部加锁,这样大大提高了matcher方法的执行效率。
二、减小锁的颗粒度
减小锁的颗粒度也是一种优化锁的方案,最典型的就是JDK内部ConcurrentHashMap的实现原理,我们都知道它与HashMap的不同之处在与它是线程安全的,那么有没有想过是怎么实现线程安全的呢?在HashMap的内部,有两个重要的方法put和get方法,可能大多数人会想到在这两个方法上加锁,但是这两个方法内部实现很复杂,如果在这两个方法上加上方法锁就会导致锁的颗粒度太大,所以,这个方法肯定不行。不妨,来看看ConcurrentHashMap是怎样实现线程安全的,我想,它肯定不会想上面一样加上又重又笨的锁吧。


下面来简单看看ConcurrentHashMap的源码,在JDK1.7和JDK1.8之间,ConcurrentHashMap做了很大的改变,在JDK1.7中有一个段(Segment)的概念,也就是说在ConcurrentHashMap内部将HashMap细分为若干个HashMap,称之为段(Segment),默认情况下,ConcurrentHashMap分为16个段。当需要Put一个表项的时候,ConcurrentHashMap并不会对整个HashMap加锁,它首先会通过hashcode得到该表项放到哪个段,然后对该段加锁,因此,如果有多个线程同时进行put操作,它们也不一定会放入到一个段中,这样给不同的段加锁就可能做到真正的并行。先来看看JDK1.7下局部变量和put方法源码:
public class ConcurrentHashMap<K, V> extends AbstractMap<K, V>
implements ConcurrentMap<K, V>, Serializable {
// 将整个hashmap分成几个小的map,每个segment都是一个锁;与hashtable相比,这么设计的目的是对于put, remove等操作,可以减少并发冲突,对
// 不属于同一个片段的节点可以并发操作,大大提高了性能
final Segment<K,V>[] segments;
// 本质上Segment类就是一个小的hashmap,里面table数组存储了各个节点的数据,继承了ReentrantLock, 可以作为互拆锁使用
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
transient int count;
}
// 基本节点,存储Key, Value值
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
}
}
public V put(K key,V value){
Segment<K,V> s;
if(value==null){
throw new NullPointException();
int hash=hash(key);
int j=(hash>>>segmentShift)&segmentMask;
if((s=(Segment<K,V>)UNSAFE.getObject
(segments,(j<<SSHIFT)+SBASE))==NULL)
s=ensureSegment(j);
return s.put(key,hash,value,false);
)可以看出,它会先根据key找到hash值,然后定位到该段进行操作。这里顺便提一下,在JDK1.7中该类的size()方法中,如果要获取其size大小,先会尝试以无锁的方式来求和,如果失败,就会在每一段中先加锁,然后再每一段求和,然后汇总,最后释放锁,这样可以看出使用size方法性能不是很高,但是大多数情况下,我们使用ConcurrentHashMap很少使用size方法,因此是值得的。
而在JDK1.8中,取消了段的概念,采用table保存数据,对每一行数据进行加锁,减小了锁的颗粒度。下面是JDK1.8中put方法的部分源码:
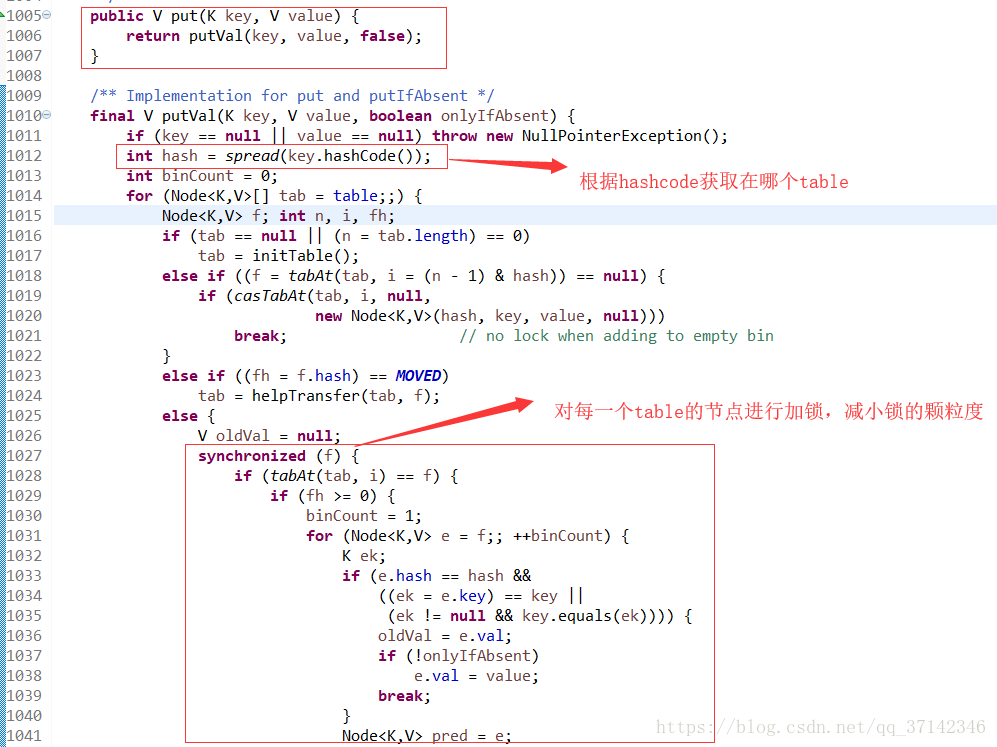
这里由于本文探讨的主题不是ConcurrentHashMap,因此对于它的源码以及不同JDK版本的区别进行探讨,读者如果想深究可以参考这篇博客(https://blog.csdn.net/mawming/article/details/52302448)
三、读写分离锁来替换独占锁
在读多写少的场合,我们可以使用读写锁ReadWriteLock,它是一个借口,对于读写操作分别用了不同的锁。

因此,对数据的读操作并不需要相互等待,你先读和它先读都是一样的,不想写操作一样产生脏数据,因此,我们可以总结出,对于读写锁的访问约束表如下:
| 读 | 写 | |
|---|---|---|
| 读 | 非阻塞 | 阻塞 |
| 写 | 阻塞 | 阻塞 |
可以看一个简单的例子来看看读写锁的性能。
package cn.just.thread.concurrent;
import java.util.Random;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
/**
* 测试读写锁
* 使用读写锁时:读读操作是并行的,所以耗费时间短
* 使用普通锁时:读读操作是串行的,所以要耗费很多时间
* @author Shinelon
*
*/
public class ReaddWriteLockDemo {
private static Lock lock=new ReentrantLock();
private static ReentrantReadWriteLock readWriteLock=new ReentrantReadWriteLock(); //读写锁
private static Lock readLock=readWriteLock.readLock(); //读锁
private static Lock writeLock=readWriteLock.writeLock(); //写锁
private int value;
/**
* 读操作
* @param lock
* @return
* @throws InterruptedException
*/
public Object handRead(Lock lock) throws InterruptedException{
try{
lock.lock();
Thread.sleep(1000);
return value;
}finally{
lock.unlock();
}
}
/**
* 写操作
* @param lock
* @param index
* @throws InterruptedException
*/
public void handWrite(Lock lock,int index) throws InterruptedException{
try{
lock.lock();
Thread.sleep(1000);
value=index;
System.out.println(value);
}finally{
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
final ReaddWriteLockDemo demo=new ReaddWriteLockDemo();
Runnable readRunnable=new Runnable() {
@Override
public void run() {
try{
// demo.handRead(readLock); //使用读锁
demo.handRead(lock); //使用普通重入锁
}catch (InterruptedException e) {
e.printStackTrace();
}
}
};
Runnable writeRunnable=new Runnable() {
@Override
public void run() {
try{
// demo.handWrite(writeLock, new Random().nextInt());
demo.handWrite(lock, new Random().nextInt());
}catch (InterruptedException e) {
e.printStackTrace();
}
}
};
/**
* 启动20个读线程
*/
for(int i=0;i<20;i++){
new Thread(readRunnable).start();
}
/**
* 启动2个写线程
*/
for(int i=18;i<20;i++){
new Thread(writeRunnable).start();
}
}
}
上面的代码分别使用了普通重入锁和读写锁来开启18个读线程和2个写的线程来测试,当使用普通重入锁,读操作之间也需要相互等待,因此整个程序运行完毕需要20秒左右,很长的一段时间,而使用了读写锁,读操作之间不需要进行等待,因此读与读之间真正的并行,只有两个写的线程之间需要等待,因此,需要很少的时间就可以完成,大概2秒左右。因此,在读多写少的情况采用读写锁对于系统的性能有更大的提升。
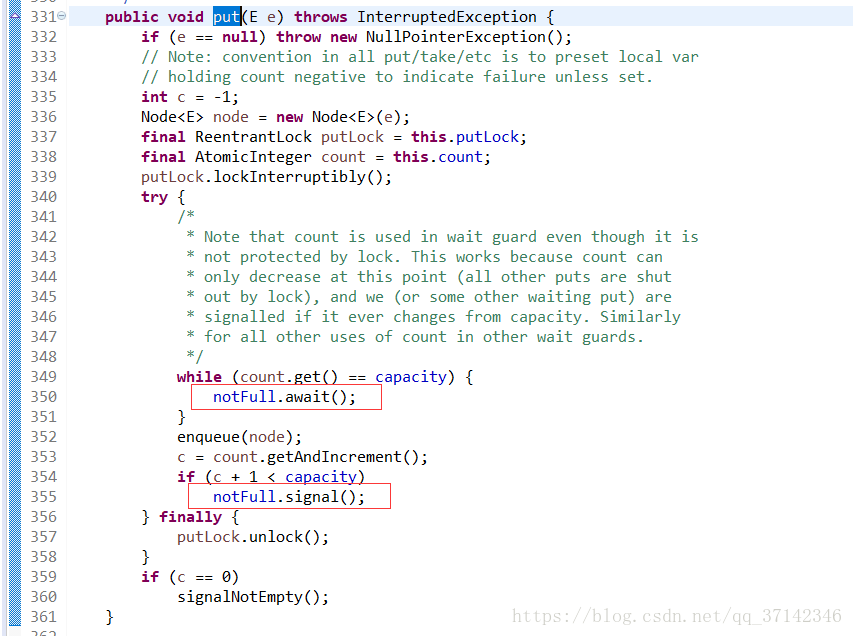
四、锁分离
有的人可能认为锁分离和读写锁差不多,其实读写锁是根据操作的不同分为不同的种类,而锁分离是读写锁的扩展,它根据应用功能的特点,采用分离的思想,这样讲可能有点搞不清,我们可以看看BlockingQueue接口的两个实现类的源码就可以更好地理解独占锁了。(之前的文章简单探究过BlockingQueue的源码 生产者-消费者模式案例以及数据共享队列【BlockingQueue】源码分析)
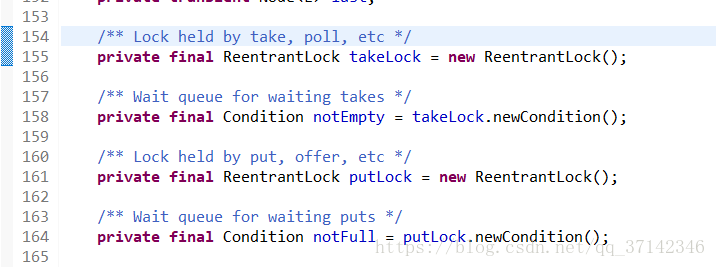
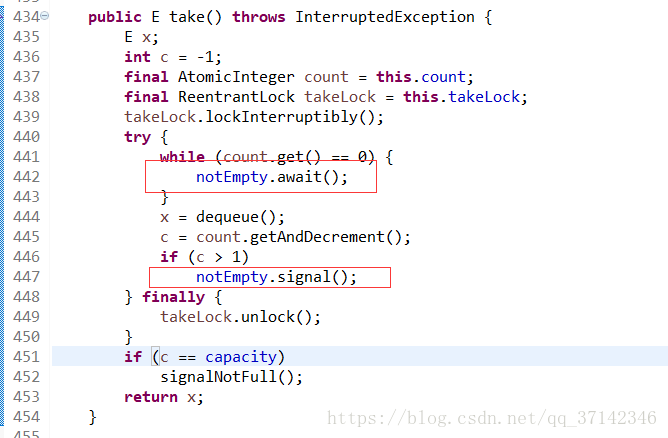
在LinkedBlockingQueue(BlockingQueue的一个实现类,链表的数据结构)的源码中对它的take()和put()方法进行加锁处理,因为这两个操作分别是从链表的头部和尾部开始操作,因此相互并不影响,因此完全可以使用两把不同的锁来提高并发性。
五、锁的粗化
可能有的读者感到奇怪,上面不是说到减小锁的颗粒度吗?这里为什么又要粗化锁,确实,在有的情况下需要粗化锁的大小来避免不必要的损耗来提高性能。如果在一系列的操作中,都需要加锁进行同步处理,但是你对每一个操作都加锁,这样,频繁的加锁释放锁严重的耗损了系统的性能,还不如加上一把大的锁,避免锁的不断请求。以下面代码为例可以看看如何粗化锁:
public void test1(){
synchronized(lock){
//do something
}
//中间是耗时很小的操作
synchronized(lock){
//do something
}对于上面的情况我们可以使用下面的方式来优化锁:
public void test1(){
synchronized(lock){
//do something
}还有一种就是for循环加锁:
for(int i=0;i<size;i++){
synchronized(lock){
//.....
}应优化为下面的代码:
synchronized(lock){
for(int i=0;i<size;i++){
//.....
}
}以上就是对锁的优化方案的几种不同方式,对于不同的场合,我们可以采用不同的优化的方案,当然,你也可以有自己独特的优化方式,总之,我们在实际开发中一定要考虑系统的性能。