HBase数据迁移
通常我们的数据来自logs以及RDBMS中,在有些时候,我们需要进行数据迁移,比如,将RDBMS中数据进行备份迁移到HBase中存储或者将一些文件迁移到HBase中,常见的HBase的数据迁移有以上几种方式:
- 使用Put API来插入数据
- 使用Bulk Load方式迁移海量数据(下面会详解以及演示)
- 编写MapReduce程序进行数据迁移
- 使用Sqoop等工具从RDBMS中抽取数据到HBase中
- 使用JDBC从RDBMS中提取数据存储到HBase中
本文将主要讲解如何继承mapreduce程序来迁移数据、使用maprudce的导入工具importtsv来迁移数据、使用Bulk Load方式来迁移数据。
使用MapReduce
HBase如何继承mapreduce程序呢?首先我们会想到将hbase所需jar包加入到lib目录下运行mapreduce程序,这是行的通的。不过,这里不会这样做。实际上HBase的lib目录下有一个hbase-server-0.98.6-hadoop2.jar包含了我们要运行的mapreduce程序,可以使用这个jar来运行mapreduce程序。如何继承mapreduce程序,下面,首先讲解如何使用hbase中自带的mapreduce程序,然后会编写mapreduce程序进行表与表之间的数据迁移。
1.运行mapreduce程序
在hbase的安装目录下写入命令可以看到两个重要的命令,这两个命令正是我们运行mapreduce程序必需的。
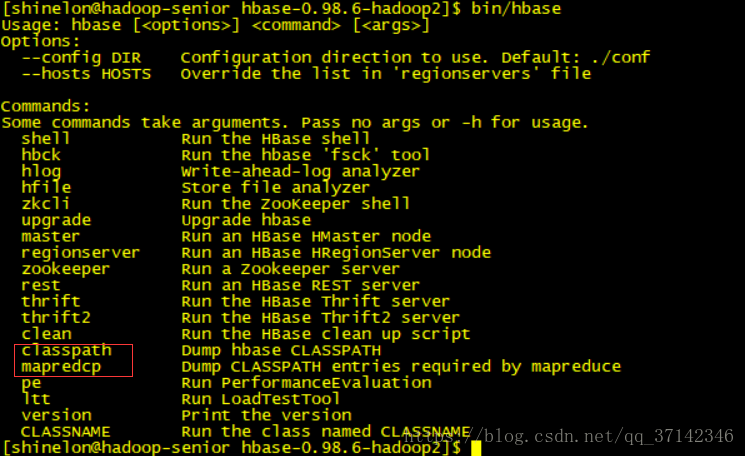
要运行mapreduce程序,需要在配置文件中添加hadoop的安装目录以及hbase安装目录的环境变量(可参考官网文档http://hbase.apache.org/book.html#hbase.mapreduce.classpath),下面直接使用export命令导入环境变量。
export HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2
export HADOOP_HOME=/opt/modules/hadoop-2.5.0
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \
${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-server-0.98.6-hadoop2.jar敲入上面命令可以看到重要的mapreduce程序案例
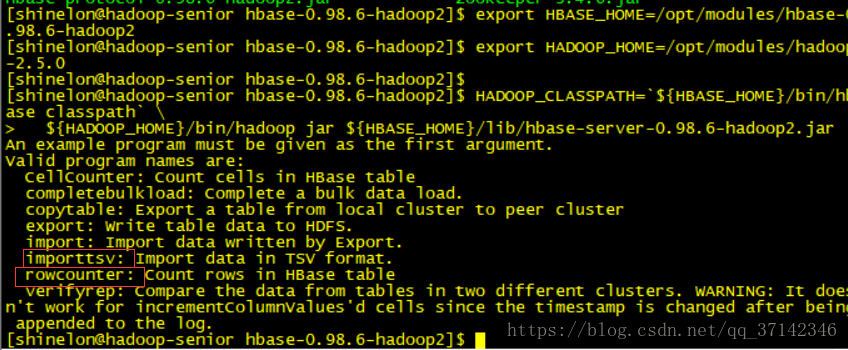
下面,运行rowcounter案例来计算一张表的记录数:
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` ${HADOOP_HOME}/bin/hadoop jar ${HBASE_HOME}/lib/hbase-server-0.98.6-hadoop2.jar rowcounter 'user'运行结果如下,user表中有三条记录:

其他案例读者可以自行测试,比如import,export等案例。
2.编写mapreduce程序进行数据迁移
应用 场景:下面要编程程序将user表中的每条记录的name,age列
迁移到basic表中。
首先要创建一张basic表:
create 'basic','info'编写mapreduce程序不难,只要熟悉mapreduce程序的编写,然后参考官方文档即可完成,鉴于程序中笔者加了注释,并且官方文档给出了详解的案例,这里不赘述,直接给出编写的代码:
package cn.just.hbase.mapreduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class UserToBasicMapreduce extends Configured implements Tool{
//Mapper class
public static class UserMapper extends TableMapper<Text, Put>{
public Text mapOutPutKey=new Text();
//key:rowKey value:cell
@Override
public void map(ImmutableBytesWritable key, Result value,
Mapper<ImmutableBytesWritable, Result, Text, Put>.Context context)
throws IOException, InterruptedException {
//set rowkey
String rowkey=Bytes.toString(key.get());
mapOutPutKey.set(rowkey);
Put put=new Put(key.get());
for(Cell cell:value.rawCells()) {
//add cf
if("info".equals(Bytes.toString(CellUtil.cloneFamily(cell)))) {
//add name column
if("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {
put.add(cell);
}
//add age column
if("age".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {
put.add(cell);
}
}
}
context.write(mapOutPutKey, put);
}
}
//Reducer class
public static class BasicReducer extends TableReducer<Text, Put, ImmutableBytesWritable>{
@Override
public void reduce(Text key, Iterable<Put> values,
Reducer<Text, Put, ImmutableBytesWritable, Mutation>.Context context)
throws IOException, InterruptedException {
for(Put put:values) {
context.write(null, put);
}
}
}
//Driver class
public int run(String[] arg0) throws Exception {
//create job
Job job=Job.getInstance(this.getConf(), this.getClass().getSimpleName());
//set job jar
job.setJarByClass(this.getClass());
//set job
Scan scan = new Scan();
scan.setCaching(500); // 1 is the default in Scan, which will be bad for MapReduce jobs
scan.setCacheBlocks(false); // don't set to true for MR jobs
// set other scan attrs
TableMapReduceUtil.initTableMapperJob(
"user", // input table
scan, // Scan instance to control CF and attribute selection
UserMapper.class, // mapper class
Text.class, // mapper output key
Put.class, // mapper output value
job);
TableMapReduceUtil.initTableReducerJob(
"basic", // output table
BasicReducer.class, // reducer class
job);
job.setNumReduceTasks(1); // at least one, adjust as required
boolean b = job.waitForCompletion(true);
if(!b) {
throw new IOException("error with job!");
}
return b?1:0;
}
public static void main(String[] args) throws Exception{
//set configration
Configuration configuration=HBaseConfiguration.create();
//submit job
int status=ToolRunner.run(configuration, new UserToBasicMapreduce(), args);
//exit program
System.exit(status);
}
}
编写好程序后,将jar包导出,输入下面命令即可完成迁移:
#userToBasicMR.jar是上面程序导出的jar包
export HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2
export HADOOP_HOME=/opt/modules/hadoop-2.5.0
HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase classpath` \
${HADOOP_HOME}/bin/hadoop jar \
/opt/modules/hadoop-2.5.0/jars/userToBasicMR.jar查看basic表中数据,发现迁移成功:
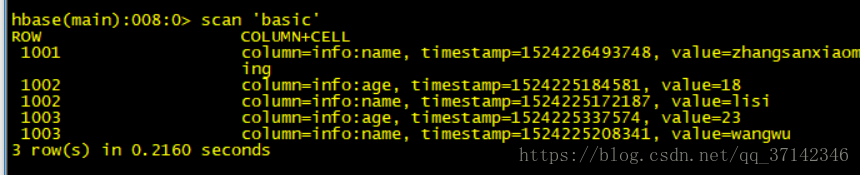
使用importtsv工具导入TSV文件
首先,说一下什么是TSV文件,知道CSV文件的读者都知道,其文件格式是用逗号隔开的,而TSV文件是用制表符‘\t’隔开的。
首先创建一个student.tsv文件输入下面几行数据(在哪个目录创建下面的命令就写在哪个目录下):
1001 zhangsan 23 male beijing 12457996
1002 wangwu 25 male hangzhou 12458796
1003 wangjun 20 male lanzhou 021547996
1004 zhaoliu 19 female jinan 1200246
1005 shinelon 19 male nanjing 03457996创建完student.tsv文件后将其上传至hdfs文件系统上:
bin/hdfs dfs -mkdir -p /user/shinelon/hbase/importtsv
bin/hdfs dfs -put /opt/datas/student.tsv /user/shinelon/hbase/importtsv/然后创建一张表student:
create 'student','info'接着就是使用importtsv工具将HDFS文件系统中的文件导入到hbase中(下面中列的数目与上面创建student.tsv文件中列的数目相等,要对应上):
export HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2
export HADOOP_HOME=/opt/modules/hadoop-2.5.0
sudo HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf \
${HADOOP_HOME}/bin/yarn jar \
${HBASE_HOME}/lib/hbase-server-0.98.6-hadoop2.jar importtsv \
-Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:age,info:sex,info:address,info:phone \
student \
hdfs://hadoop-senior.shinelon.com:8020/user/shinelon/hbase/importtsvmapreduce程序运行完毕后就可以查看student表中已经插入了数据:
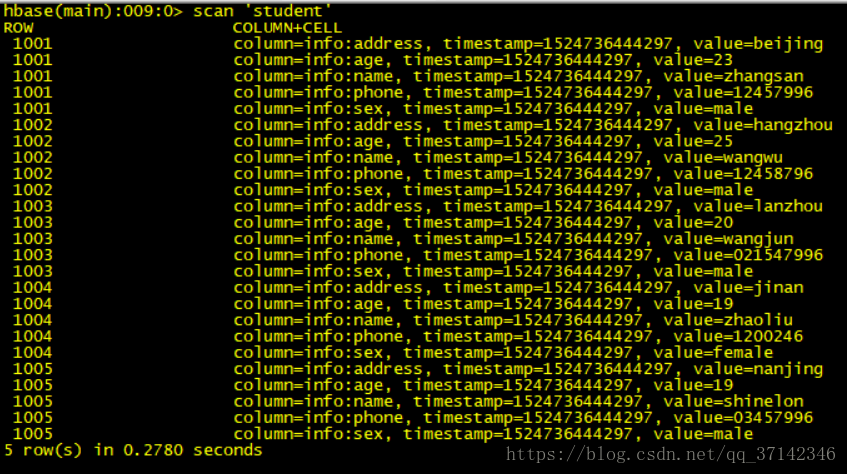
使用Bulk Load来进行海量数据的迁移
通过上面标题可以看到使用Bulk Load可以对海量数据进行快速的迁移,而且效率很高,对于集群的负载很小。
通常使用mapreduce程序向hbase中插入数据时使用的是TableOutPutFormat方式,reduce中直接生成put对象写入hbase,这种方式在大量数据插入的时候效率低下,因为hbase会频繁的访问节点写入数据,对集群的性能造成很大的影响(比如GC过长,响应变慢,节点超时退出等一系列连锁反应)。
使用Bulk Load方式可以达到快速入库海量数据的效果,并且集群负载很小,因为它利用了hbase数据存储在hdfs,以HFile文件的格式存储的原理,直接将数据生成HFile存储在hdfs,然后加载(移动,加载后hdfs上的HFile文件将会不见)到hbase中。并且配合mapreduce完成,高效便捷,不占用region资源,添加负载。使用Bulk Load方式主要有下面两个好处:
- 消除hbase集群的插入压力
- 提高job的运行速度,降低job的执行时间
下面我们来将上面创建的student.tsv文件使用bulk load方式加载到student2表中。
首先,创建student2表:
create 'student2','info'使用下面命令将tsv文件中的数据上传到hdfs文件系统中存储在HFile文件中:
export HBASE_HOME=/opt/modules/hbase-0.98.6-hadoop2
export HADOOP_HOME=/opt/modules/hadoop-2.5.0
sudo HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf \
${HADOOP_HOME}/bin/yarn jar \
${HBASE_HOME}/lib/hbase-server-0.98.6-hadoop2.jar importtsv \
-Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:age,info:sex,info:address,info:phone \
-Dimporttsv.bulk.output=/user/shinelon/hbase/hfileInput \
student2 \
hdfs://hadoop-senior.shinelon.com:8020/user/shinelon/hbase/importtsv然后就是将HFile文件加载到hbase中:
sudo HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp`:${HBASE_HOME}/conf \
${HADOOP_HOME}/bin/yarn jar \
${HBASE_HOME}/lib/hbase-server-0.98.6-hadoop2.jar \
completebulkload \
hdfs://hadoop-senior.shinelon.com:8020/user/shinelon/hbase/hfileInput \
student2查看student2中表可以看到数据成功插入:
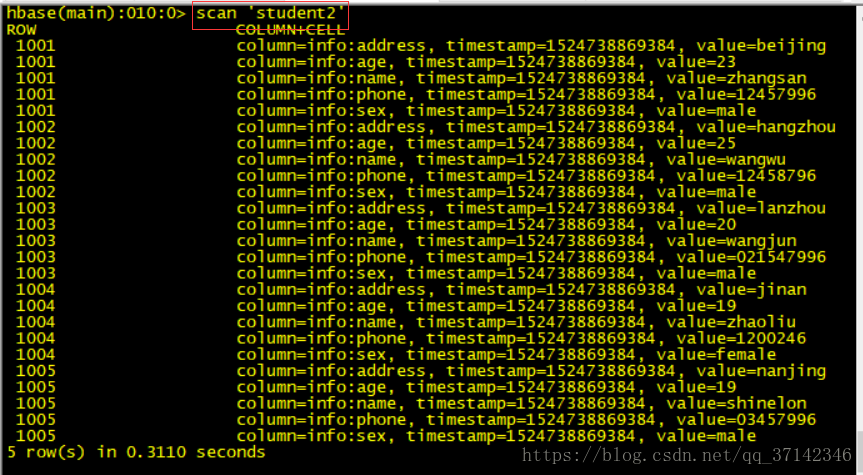
至此,本文介绍了如何继承mapreduce程序以及使用工具来进行数据迁移,如有不足之处欢迎留言讨论,请尊重劳动成果,转发请标明转发链接,谢谢!