
文章作者:携程技术团队
编辑整理:Hoh
内容来源:《携程架构实践》
出品平台:DataFunTalk
注:转载请在后台留言“转载”。
导读:飞机有两个发动机,用于实现高可用。如果一个发动机出现故障,另一个发动机还能够持续工作,数据库运维也是如此。我们需要多个副本,一旦某个节点发生故障,另外一个节点可以继续提供服务。我们还需要考虑到机房发生故障的场景,需要有快速切换到异地容灾机房的能力。
我们推荐使用数据库三副本,一主一从一异地容灾。如果想要节省成本,也可以只保留两副本,但是一旦其中一台服务器发生故障,服务器维修时间会比较长,那么在维修期间,数据库服务会处于单点状态,使得风险急剧上升。
本文主要介绍以下内容:
SQL Server 高可用
MySQL 高可用
Redis 高可用
01SQL Server 高可用
携程的 SQL Server 高可用架构经过了多次演进。最初使用的是镜像技术,如果服务器出现故障,在切换时,需要人工进行干预以切换到镜像节点。同时镜像节点不提供读服务,可扩展性比较差。后来引入了 SAN 存储,将计算和存储进行分离,可以实现自动切换,但 SAN 存储技术过于复杂,并且价格昂贵。2013年,我们开始将其逐步改造为 AlwaysOn 架构,这是 SQL Server 2012 以后的版本所具有的功能。
图1显示了三副本的 SQL Server 数据库服务架构。主副本提供读写访问;一个辅助副本是同步模式,即和主副本数据保持一致;另一个辅助副本是异步模式,存放在异地机房。同步模式可以保证主从数据一致,在切换时不会丢失数据。但同步节点的性能可能会对主副本造成影响,每一个事务都需要在同步节点确认后,才算完成。所以,将同步节点和主节点放在同一网段内,可以减少网络开销,提升整体的响应速度。
SQL Server 可以在主副本服务器发生故障时,自动切换到同步节点。在切换期间,数据库不可用,所以通常在1分钟之内完成。而切换到异步节点是手动触发的,因为是异步模式,可能会丢失数据,所以尽量不切换到异步节点。
SQL Server 高可用在很大程度上依赖于底层操作系统。因为 AlwaysOn 架构依赖底层的 Windows 群集服务。一个 Windows 群集可以有多套 AlwaysOn 组。Windows 群集服务可以这样设计:
尽量增加群集节点数量,一般保持在9个以上的奇数节点,避免一台或两台服务器故障导致整个群集不可用;
因为群集节点多,所以增加 regroup 的超时时间,避免重组超时导致整个群集异常;
增加文件共享仲裁,文件共享可以存放在第三机房,避免机房故障导致群集失去多数仲裁,同时在失去多数仲裁时,可以使用 ForceQuorum 模式强制启动 Windows 群集服务,尽快恢复业务。
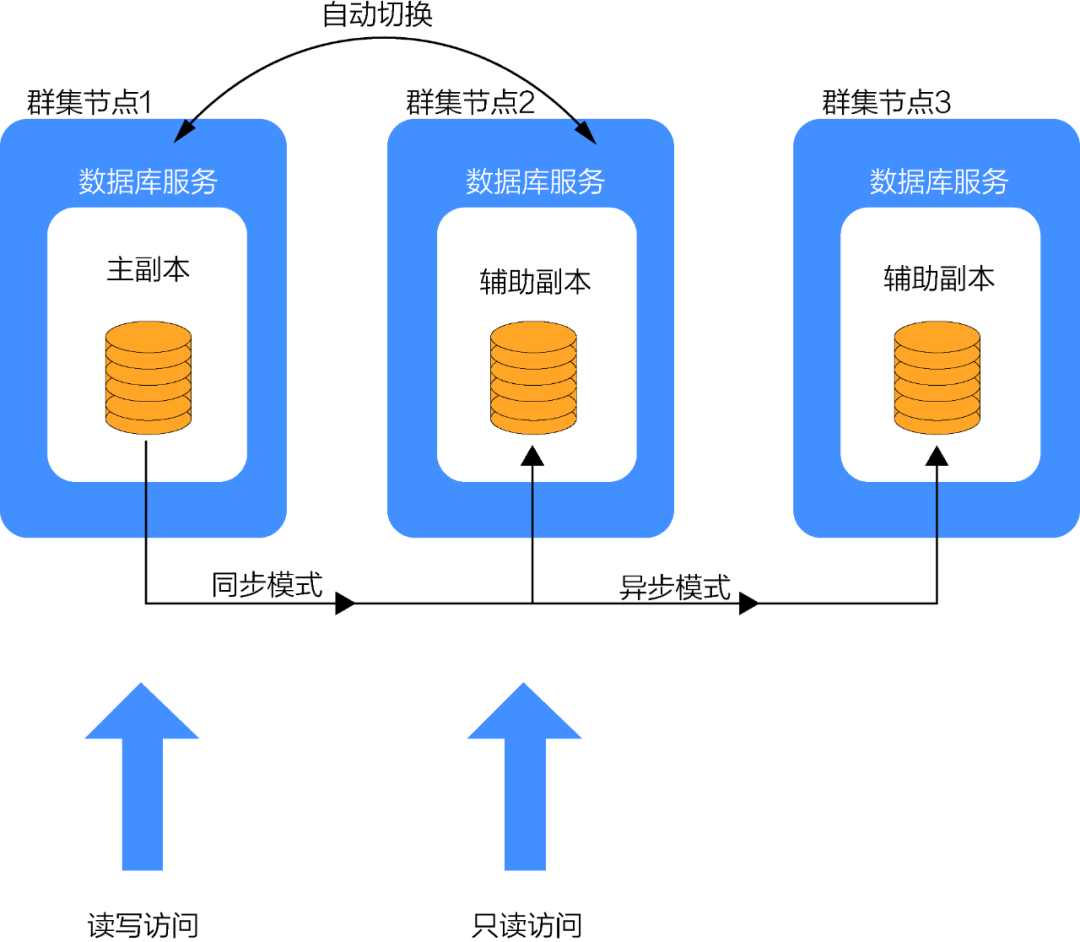 图1 三副本的 SQL Server 数据库服务架构
图1 三副本的 SQL Server 数据库服务架构
使用 AlwaysOn 架构可以极大减轻主节点的负载。数据库的全量备份或日志备份可以调整到异步节点上进行,无须担心数据库备份会对业务造成性能影响。我们会比较关注 AlwaysOn 的主从延迟,并采用插值法进行监控,对每一个业务数据库设计了一张监控表,定期插入时间戳。在经过 AlwaysOn 传递到辅助副本后,我们把时间戳取出来,和当前时间进行比较,就能精确地获得延迟时间。延迟通常是只读副本上的查询语句 IO 开销大导致的。根据延迟时间,以及前文提到的全量语句性能数据采集,我们可以定位导致延迟的异常语句。
02MySQL 高可用
相对于成熟的商业数据库软件,开源版本的 MySQL 高可用方案更多地需要使用者自己进行设计和研发,好在 MySQL 本身已经为我们提供了一些必要的功能:MySQL 复制技术。MySQL 复制技术包含传统的基于日志传输的复制技术,以及在 MySQL 5.7 之后的版本引入的组复制技术。在携程,大部分 MySQL 集群采用传统的基于日志传输的复制技术。携程的 MySQL 高可用架构经历了3个阶段的演进。
第一阶段:采用传统的 MHA 管理方式,架构如图2所示。
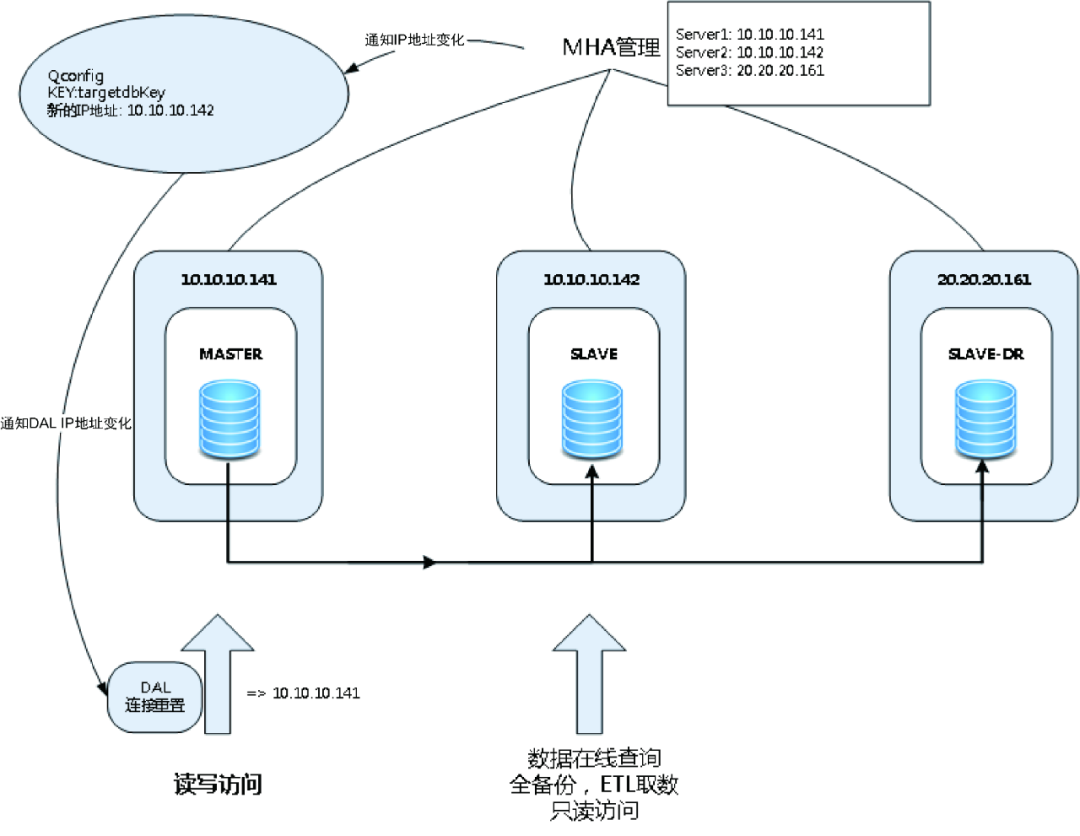 图2 传统的 MHA 架构
图2 传统的 MHA 架构
从本质上来说,MHA 是一个管理 MySQL 主从复制架构的工具集。我们可以通过其官方网站下载最新的版本。应用可以通过虚拟 IP 地址10.10.10.59进行访问,虚拟 IP 地址挂载在主节点上。MHA 管理节点会每隔10秒探测并连接主机,如果连续3次连接不上,则判定主机故障,触发切换。在发生切换时,MHA 会结合半同步复制,补全未同步的日志,这种切换可以保证数据完整。另外,切换会尝试连接旧主机,把挂载在主节点上的虚拟 IP 地址删除,然后在 Slave 节点重新挂载虚拟 IP 地址,完成切换。
传统的 MHA 架构比较成熟,使用广泛,但存在风险。如果由于交换机故障,MHA 管理节点连接不上主机,但主机本身运行正常,MHA 管理工具无法判断是网络故障还是服务器故障,就会进行切换,并且把虚拟 IP 地址挂载到 Slave 节点,但 MHA 管理节点连接不上旧主机,无法删除虚拟 IP 地址。此时两个节点都有虚拟 IP 地址存在,数据会发生"双写",也就是发生"脑裂"。这种情况很少发生,但一旦发生,就难以处理,起因就在于虚拟 IP 地址。解决的方法是把虚拟 IP 地址删除,使用物理 IP 地址进行直连。这就需要使用数据库访问 DAL 模块和统一配置中心。在切换时,需要通知应用程序 IP 地址发生变化,并对所有的连接进行重置。
第二阶段:使用 IP 直连,如图3所示。
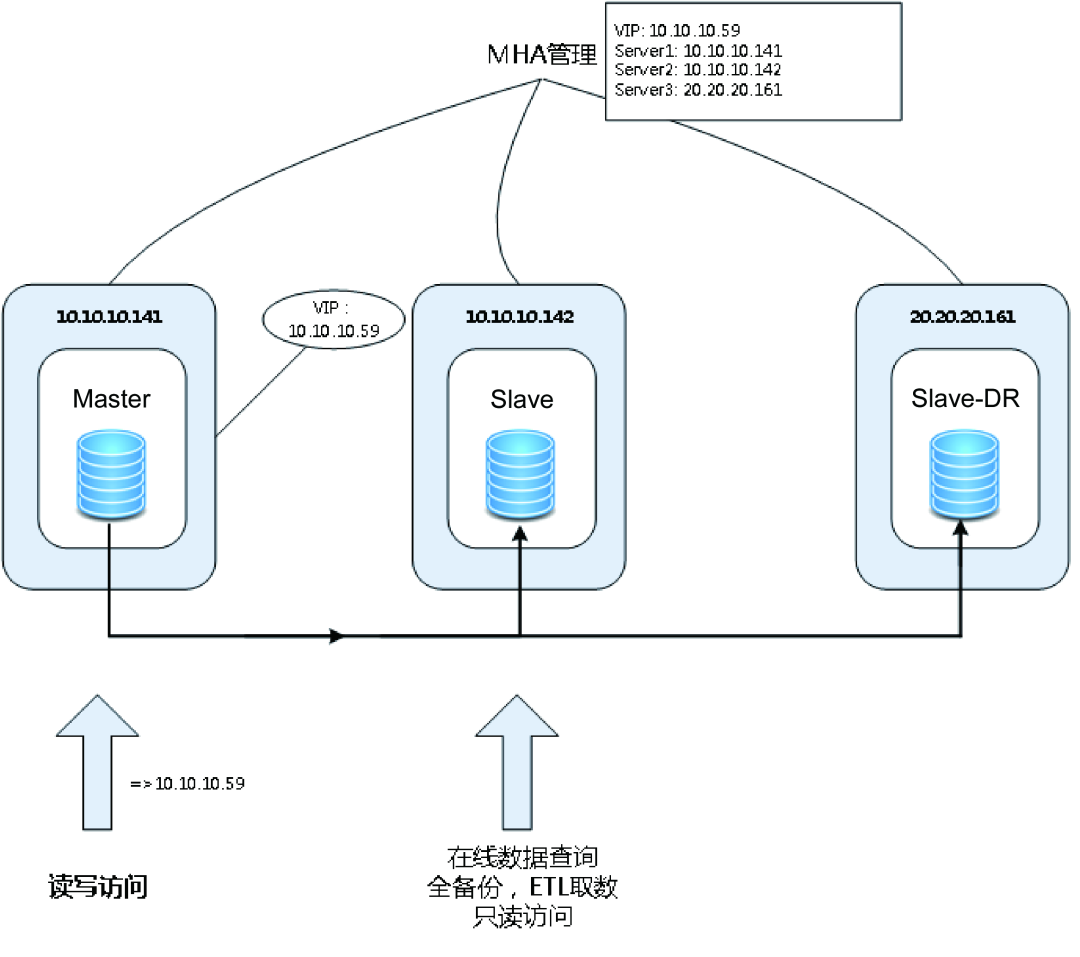 图3 IP 直连
图3 IP 直连
初始的时候,应用程序使用物理 IP 地址10.10.10.141访问数据库。MHA 管理节点探测到主节点发生了故障,预备切换到10.10.10.142,并将 IP 地址变化通知统一配置中心 QConfig。统一配置中心在收到这个变化后,会把这个变化推送到应用服务器的数据库访问中间件 DAL。DAL 会重置对数据库的连接,使用新的 IP 地址10.10.10.142。此处的统一配置中心要确保高可用,即使机房发生故障,也不能影响统一配置中心的正常运转。
经过改造,我们去除了数据"双写"的隐患。但在极端场景下,还是会存在风险。如果机房整体发生故障,MHA 管理节点和主机/从机同时无法运行了,MHA 就无法自动切换到 DR 节点。这是由于 MHA 单管理节点本身成了系统瓶颈,解决的方法是引入多 MHA 管理节点进行协同管理。
第三阶段:引入多 MHA 管理节点,如图4所示。
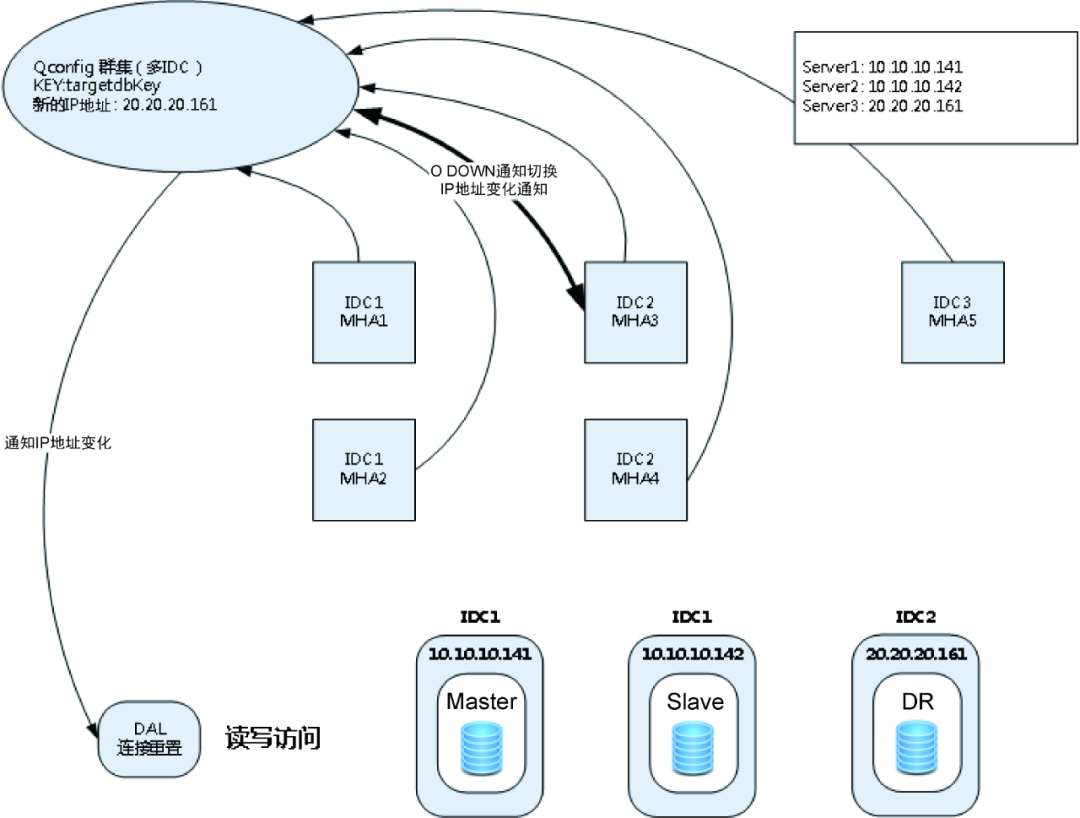 图4 IP 直连 + 多 MHA 管理节点
图4 IP 直连 + 多 MHA 管理节点
应用使用物理 IP 地址10.10.10.141访问数据库。每一个数据库实例都由5个 MHA 管理节点进行同时监听。这5个 MHA 管理节点分布在3个机房。一旦某个 MHA 管理节点探测到主机发生了异常,则标记为 SDOWN。但一个 MHA 管理节点无法决定主机是否真的发生了故障,该 MHA 管理节点需要发起协商流程,和其他4个 MHA 管理节点一同判断,如果多数 MHA 管理节点认为发生了故障,则标记为 ODOWN,也就是确定主机真的发生了故障。MHA 会检测并决定可以成为备选主节点的节点,并由5个 MHA 管理节点再次协商,推选一个管理节点,用来向统一配置中心 QConfig 汇报 IP 地址变化。如果机房发生故障,并且另一个节点10.10.10.142不可用,则可选择主节点为20.20.20.161。统一配置中心会把这个变化推送到 DAL 组件,并重置连接,使用新的 IP 地址。
五节点模式的 MHA 管理是稳定的。其中一个管理节点处于第三机房,能抵御单机房故障。MHA 管理节点之间的协商比较复杂,我们可以借助成熟的 Redis 哨兵管理机制,在 Redis 哨兵管理机制上进行改造,适配对 MySQL 的监控。
03Redis 高可用架构
Redis 的高可用架构有两种通用的做法:一种是基于复制的主从模型,另一种是群集模型。携程使用的是第一种模型,即主从复制,其运行机制如图5所示。
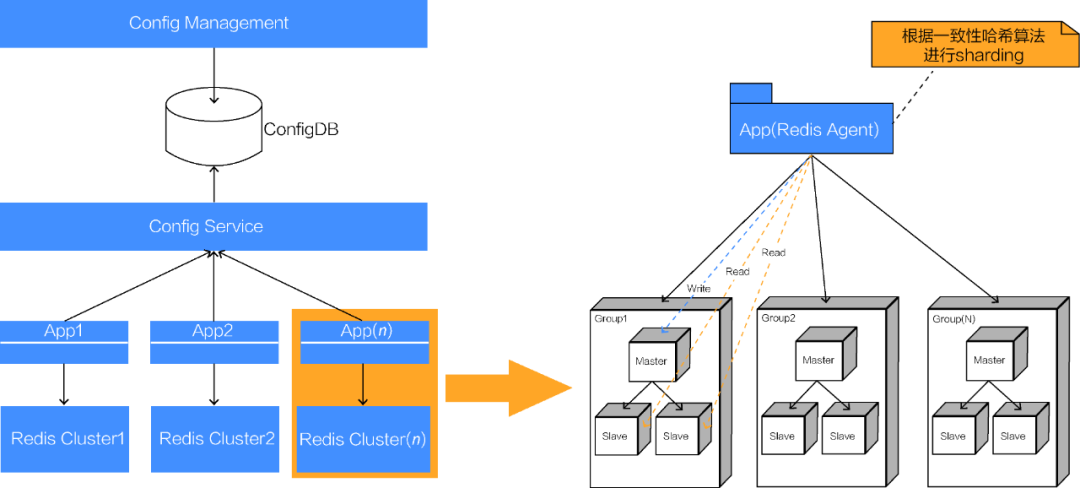 图5 Redis 运行机制
图5 Redis 运行机制
Redis 的元数据被存放在 ConfigDB 中。元数据包括 Redis 实例的状态信息,以及对应的 IP 地址和端口信息等。前端可以通过页面对元数据进行调整,如设置某个实例不可用或不可读等。服务是通过 Config Service 实现的。服务会从 ConfigDB 中拉取配置,应用会定期调用 Config Service 服务,获得实例元数据信息,实现对 Redis 群集的实际访问。
我们通过一致性哈希算法对 Redis 进行分片。每一个分片都被称为组。在每一个组中,有读写实例和只读实例,它们会通过复制关系来传递数据。在部署时,我们尽量把实例分散到不同的服务器上。一旦服务器发生故障,则只会影响部分分片,不会严重影响后端数据库。我们应当尽量控制 Redis 缓存的每一个实例为 10GB 左右。如果超过 10GB,则可能需要确定是否可以进行拆分。若需要重新进行分组,则多拆分出几个组。
Redis 由哨兵来监控 Redis 实例的运行状态。我们启用了5个哨兵来同时监听。哨兵的主要功能为:
监控所有实例是否在正常运行;
当 Slave 出现故障时,通过消息通知机制把该 Slave 拉出,并将其设置为不可用,同时把 Master 设置为可读、可写;
当 Master 出现故障时,通过自动投票机制从 Slave 节点中选举新的 Master,实现 Redis 的自动切换。
哨兵实际上是一个运行在特殊模式下的 Redis 服务,我们可以通过在启动命令参数中指定 sentinel 选项,来标识该 Redis 服务是哨兵。每一个哨兵会向其他哨兵,即 Master 和 Slave 定时发送消息,以确认对方是否正常运行,如果发现对方在指定时间内未回应,则暂时认为对方主观挂机 ( Subjective Down,简称 SDOWN )。如果哨兵群中的多数哨兵都报告某个 Master 没响应,系统就会认为该 Master 客观挂机 ( Objective Down,简称 ODOWN )。
通过 Redis 的运行机制可以看出,Config Service 的状态信息需要和 Redis 实例的实际状态信息保持一致,否则在访问应用时会发生异常,比如,当只读实例发生故障,在重新向 Master 节点全量同步数据期间,如果该实例还是配置可读,在访问应用时就会报错。当有故障发生时,Redis 需要具备快速自动恢复的能力,减少人工干预。我们应当尽量从哨兵处获得信息,如果超过半数的哨兵发生故障,则直连 Redis 实例来获得物理状态。
对于 Redis 异地机房容灾而言,我们需要考虑跨机房全量同步为网络带来的开销,以及可能存在的网络不稳定因素。因此,我们采用了一个中间层,即 Keeper 来对数据进行缓冲。在本质上,Keeper 是伪 Slave,即实现 Redis 协议,伪装成 Slave,让 Master 推送数据到 Keeper 中。受限于篇幅,对于 Redis 异地机房容灾及切换,这里就不介绍了,谢谢大家。
以上内容选自携程技术团队新作《携程架构实践》
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~

关于我们:
DataFunTalk专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号DataFunTalk累计生产原创文章400+,百万+阅读,5万+精准粉丝。
