文章目录

1.导论
没有介绍什么高深的内容,仅仅是优化的一点点废话。
- 不能过早的优化
2.性能测试方法
-
测试真实应用
-
微基准测试

这段代码在智能Jvm优化成
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5pm8P2bT-1616337041274)(images/image-20210316215815535.png)]](https://img-blog.csdnimg.cn/20210321223148645.png)
本章主要讲解了性能测试方法,这个适用于测试人员。
3, Java性能调优工具
vmstat命令 查看CPU使用绿
iostat查看磁盘使用率
nicstat 可以此案时每个网络接口的流量概要,包括网络接口的使用度
简单的介绍了java监控工具,不详细,案例太少不值得看。基本jvm信息,线程信息,类信息,GC分析,时候堆转储。
性能分析工具的介绍。飞行器的介绍。
3.2 java 监控工具
-
jcmd 用来打印java进程所涉及的基本类。线程和jvm信息,适用于脚本
jcmd process_id command optional_arguments -
jconsole 提供jvm活动的图形化视图,包括线程的使用,类的使用和GC活动
-
jhat读取内存堆转储,并有助于分析
-
jmap提供堆转储,并且有助于分析
-
jinfo 查看Jvm系统信息,可以动态的设置一些系统属性
-
jstat 提供GC和类活动的信息
-
jvisualvm 监视jvm的GUI工具,可以用来跑鞋运行的程序分析jvm堆转储
3.2.1 基本信息
查看 JVM 运行的时长
% jcmd process_id VM.uptime
[lcc@lcc ~/Downloads]$ jcmd 67970 VM.uptime
67970:
65.996 s
显示 System.getProperties() 的各个条目。
% jcmd process_id VM.system_properties
或者
% jinfo -sysprops process_id
命令行 -D 标志设置的所有属性,应用动态添加的所有属性和 JVM 的默认
属性
获取 JVM 版本:
% jcmd process_id VM.version
jconsole 的“VM 摘要”页可以显示程序所用的命令行
% jcmd process_id VM.command_line
获得对应用生效的 JVM 调优标志:
% jcmd process_id VM.flags [-all]
获取进程中所有标志的值
% jinfo -flags process_id
jinfo 带有 -flags 时可以提供所有标志的信息,否则只打印命令行所指定的标志。这两种数据都不像 -XX:+Printflagsfinal 那样易读,但 jinfo 有其他值得注意的特性。
jinfo 可以检查单个标志的值:
% jinfo -flag PrintGCDetails process_id -XX:+PrintGCDetails
3.3 性能分析工具
3.3.1 采样分析器
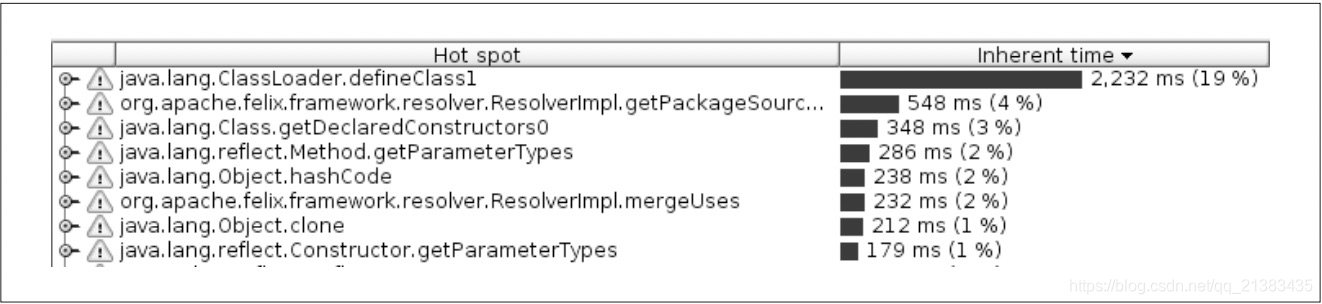
- 采样分析器是最常用的分析器。
- 因为采样分析器的采样频率相对较低,所以引入的测量失真也较小。
- 不同的采样分析器各有千秋,针对不同应用各有所长
3.3.2 探查分析器

- 探查分析器可以给出更多的应用信息,但相对采样分析器,它对应用的影响更大。
- 探查分析器应该仅在小代码区域——一些类和包——中设置使用,以限制对应用性能的影响
3.3.3 阻塞方法和线程时间线
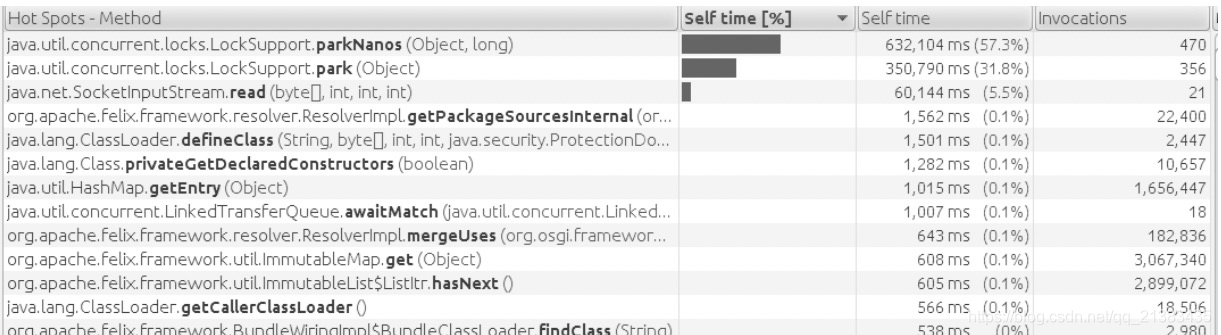
- 线程被阻塞可能是性能问题,也可能不是,有必要进一步调查它们为何被阻塞。
- 通过正被阻塞的方法调用,或者分析线程的时间线,可以辨认出被阻塞的线程
3.3.4 本地分析器
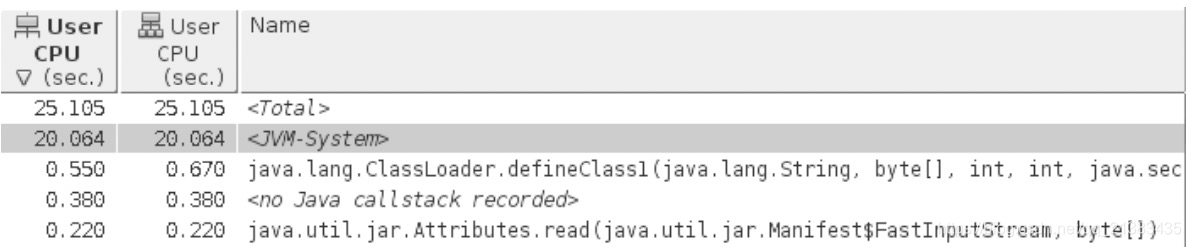
- 本地性能分析器可以提供 JVM 和应用代码内部的信息。
- 如果本地性能分析器显示 GC 占用了主要的 CPU 使用时间,优化垃圾收集器就是正确的做法。然而,如果显示编译线程占用了明显的时间,则说明通常对应用性能没什么影响。
3.4 Java任务控制
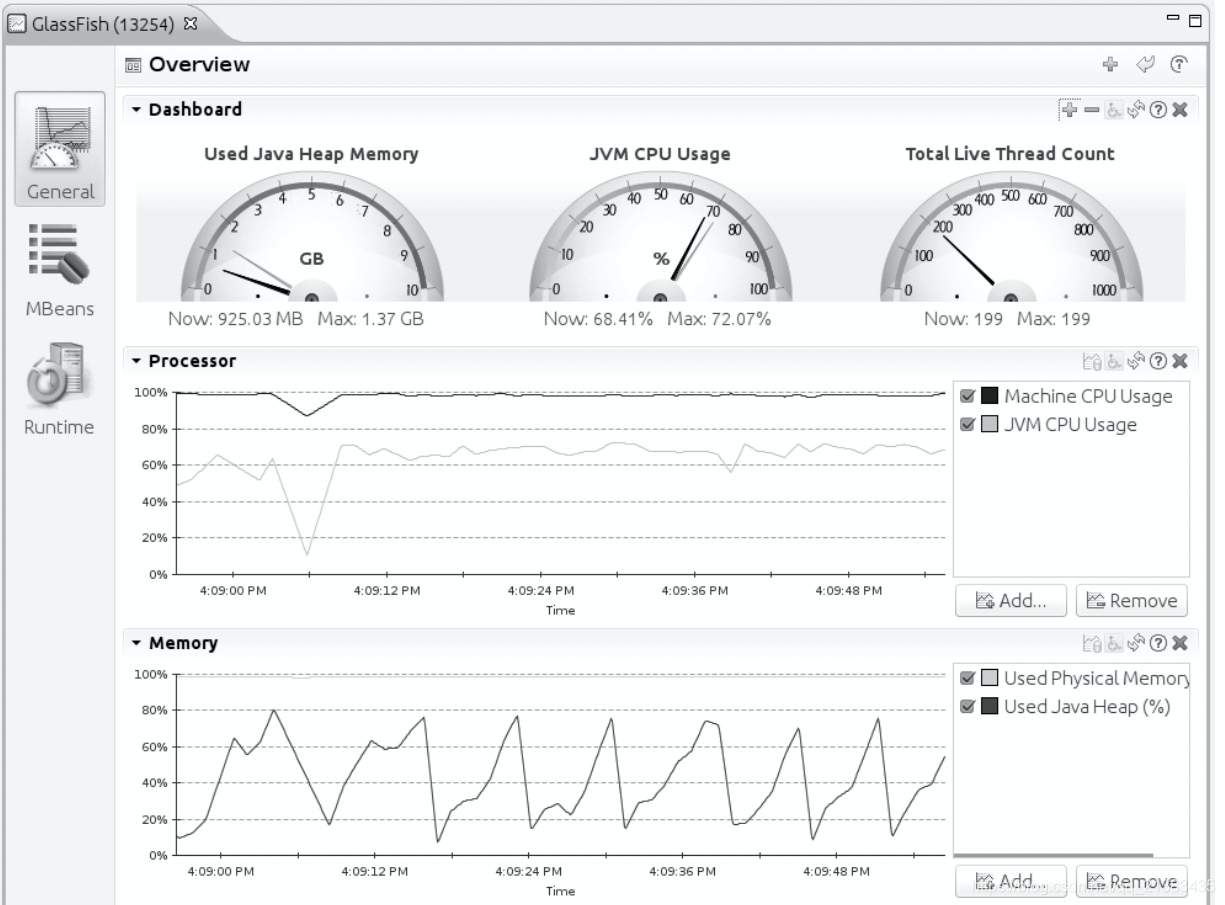
3.4.1 Java飞行记录器
这个讲了大半个篇幅,但是我没看
4. JIT编译器
- 主要讲解了 sever 和client模式下的热点代码编译
- 分层编译的问题
- 64 位jvm server模式下,代码缓存的默认大小是240M(不好估算,1-3倍)
- -XX:ReservedCodeCacheSize=N 设置代码缓存的最大值
- 编译是基于两种 JVM 计数器的:方法调用计数器和方法中的循环回边计数器。回边实际上可看作是循环完成执行的次数,所谓循环完成执行,包括达到循环自身的末尾,也包括执行了像 continue 这样的分支语句。
- 标准编译由 -XX:CompileThreshold=N 标志触发。使用 client 编译器时, N 的默认值是 1500,使用 server 编译器时为 10 000。
- 热点代码计数器会随着方法和循环的执行而增加,但是也会随着时间周期性的减少。
- jstat可以检测编译
4.1 编译器介绍
- Java 的设计结合了脚本语言的平台独立性和编译型语言的本地性能。
- Java 文件被编译成中间语言(Java 字节码),然后在运行时被 JVM 进一步编译成汇编语言。
- 字节码编译成汇编语言的过程中有大量的优化,极大地改善了性能
4.2 调优入门: 选择编译器类型
- 为分层编译。代码先由 client编译器编译,随着代码变热,由 server 编译器重新编译。
4.2.1 优化启动
- 如果应用的启动时间是首要的性能考量,那 client 编译器就是最有用的。
- 分层编译的启动时间可以非常接近于 client 编译器所获得的启动时间。
4.2.2 优化批处理
- 对于计算量固定的任务来说,应该选择实际执行任务最快的编译器。
- 分层编译是批处理任务合理的默认选择。
4.2.3 优化长时间运行的应用
- 对于长时间运行的应用来说,应该一直使用 server 编译器,最好配合分层编译。
4.3 Java和JIT编译器版本
- 如果堆小于 3 GB, 32 位的 Java 会更快一些,并且内存占用也更少。这是因为 JVM 内部的指针只有 32 位,操作 32 位指针的代价要少于 64 位指针的(即便你使用的是 64位 CPU)。而且 32 位指针所占的内存也少。
- 压缩的普通对象指针(ordinary object pointers, oops),这是一种在 64 位JVM 中使用 32 位寻址的方法。不过,即便有这种优化, 64 位 JVM 的内存占用仍然大于 32 位 JVM,这是因为它所用的本地代码依然是 64 位寻址。
- 32 位 JVM 无法使用 CPU 的64 位寄存器,所以大量使用 long 或 double 变量的程序在 32 位 JVM 上就会比较慢。
- 在 32 位 JVM 上运行的程序,只要与 32 位寻址空间吻合,无论机器是 32 位还是 64位,都要比在类似配置的 64 位 JVM 上运行时快 5% 到 20%。
4.4 编译器中级调优
4.4.1 调优代码缓存
JVM 编译代码时,会在代码缓存中保留编译之后的汇编语言指令集。代码缓存的大小固定,所以一旦填满, JVM 就不能编译更多代码了。
代码缓存填满时, JVM(通常)会发出以下警告:
Java HotSpot(TM) 64-Bit Server VM warning: CodeCache is full.Compiler has been disabled.
Java HotSpot(TM) 64-Bit Server VM warning: Try increasing the code cache size using -XX:ReservedCodeCacheSize=
各种平台上代码缓存的默认大小
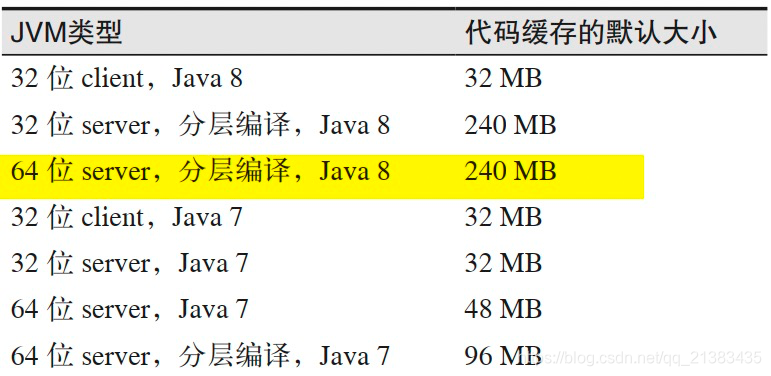
没有什么好的机制可以算出程序所需要的代码缓存。所以,通常的做法是简单地增加 1 倍或 3 倍。
-XX:ReservedCodeCacheSize=N( 对 特 定 编 译 器 来 说, N 为 默 认 的 值 ) 标 志 可 以 设置 代 码 缓 存 的 最 大 值。
4.4.2 编译阈值
编译是基于两种 JVM 计数器的:方法调用计数器和方法中的循环回边计数器。回边实际上可看作是循环完成执行的次数,所谓循环完成执行,包括达到循环自身的末尾,也包括执行了像 continue 这样的分支语句。
标准编译由 -XX:CompileThreshold=N 标志触发。使用 client 编译器时, N 的默认值是 1500,使用 server 编译器时为 10 000。
虽然计数器随着方法和循环的执行而增加,但它们也会随时间而减少。每种计数器的值都会周期性减少(特别是当 JVM 达到安全点时)。
4.4.3 检测编译过程
- 如果开启 PrintCompilation,每次编译一个方法(或循环)时, JVM 就会打印一行被编译的内容信息。
- 观察代码如何被编译的最好方法是开启 PrintCompilation。
- PrintCompilation 开启后所输出的信息可用来确认编译是否和预期一样。
4.5 高级编译器优化
4.5.1 编译线程
- 编译队列并不严格准守先进先出的原则,调用计算次数多的方法有更高的优先级。
- 当使用 client 编译器时, JVM 会开启一个编译线程;使用 server 编译器时,则会开启两个这样的线程。当启用分层编译时, JVM 默认开启多个 client 和 server 线程,线程数依据一个略复杂的等式而定,包括目标平台 CPU 数取双对数之后的数值。
4.5.2 内联
- 方法内联。内联是默认开启的,-XX:-Inline
Point p = getPoint();
p.setX(p.getX() * 2);
而编译后的代码本质上执行的是:
Point p = getPoint();
p.x = p.x * 2;
- 基本上没法看到 JVM 是如何内联代码的。(如果你从源代码编译 JVM,那可以用 -XX:+PrintInlining 生成带调试信息的版本
- 方法是否内联取决于它有多热以及它的大小。
- JVM 依据内部计算来判定方法是否是热点(譬如,调用很频繁);是否是热点并不直接与任何调优参数相关。如果方法因调用频繁而可以内联,那只有在它的字节码小于 325 字节时(或 -XX:MaxFreqInlineSize=N 所设定的任意值)才会内联。否则,只有方法很小时,即小于 35 字节(或 -XX:MaxInlineSize=N 所设定的任意值)时才会内联
4.5.3 逃逸分析
- 开启逃逸分析( -XX:+DoEscapeAnalysis,默认为 true)
- 逃逸分析是编译器能做得最复杂的优化。此类优化常常会导致微基准测试失败。
- 逃逸分析常常会给不正确的同步代码引入“bug
4.6 逆优化
有两种逆优化的情形:代码状态分别为“made not entrant”(代码被丢弃)和“made zombie”(产生僵尸代码)时。
4.6.1 代码被丢弃
4.6.2 逆优化僵尸代码
- 逆优化使得编译器可以回到之前版本的编译代码。
- 先前的优化不再有效时(例如,所涉及的对象类型发生了更改),才会发生代码逆优化。
- 代码逆优化时,会对性能产生一些小而短暂的影响,不过新编译的代码会尽快地再次热身。
- 分层编译时,如果代码之前由 client 编译器编译而现在由 server 编译器优化,就会发生逆优化。
4.7 分层编译级别
client 编译器有 3 种级别,所以总共有 5 种执行级别。因此,编译级别有:
• 0:解释代码
• 1:简单 C1 编译代码
• 2:受限的 C1 编译代码
• 3:完全 C1 编译代码
• 4: C2 编译代码
4.8 小结
- 不用担心小方法——特别是 getter 和 setter,因为它们很容易内联。
- 需要编译的代码在编译队列中。队列中代码越多,程序达到最佳性能的时间越久。
- (3) 虽然代码缓存的大小可以(也应该)调整,但它仍然是有限的资源。
- 代码越简单,优化越多。分析反馈和逃逸分析可以使代码更快,但复杂的循环结构和大方法限制了它的有效性
5. 垃圾回收器入门
- 几乎所有的垃圾收集算法中基本的垃圾回收线程数都依据机器上的 CPU数目计算得出。
- 多个 JVM 运行于同一台物理机上时,依据公式计算出的线程数可能过高,必须进行优化(减少)。
- JVM 在堆的内部如何调整新生代及老年代的百分比是由自适应调整机制控制的。
- 可以设置
-XX:+PrintAdaptiveSizePolicy标志。开启该标志后,一旦发生垃圾回收, GC 的日志中会包含垃圾回收时不同的代进行空间调整的细节信息.
5.1 垃圾收集概述
6. 垃圾回收器算法
6.1 理解Throughput收集器
这个垃圾回收器,很少见,直接没看。
7. 堆内存最佳实践
7.1 堆分析
7.1.1 堆直方图
% jcmd 8998 GC.class_histogram
8898:
num #instances #bytes class name
---------------------------------------------
1: 789087 31563480 java.math.BigDecimal
2: 237997 22617192 [C
3: 137371 20696640 <constMethodKlass>
4: 137371 18695208 <methodKlass>
5: 13456 15654944 <constantPoolKlass>
6: 13456 10331560 <instanceKlassKlass>
7: 37059 9238848 [B
8: 10621 8363392 <constantPoolCacheKlass>
7.1.2 堆转储
从命令行生成转储文件往往更容易,可以在下面两条命令中选择一个:
% jcmd process_id GC.heap_dump /path/to/heap_dump.hprof
或:
% jmap -dump:live,file=/path/to/heap_dump.hprof process_id
浅对象
一个对象的浅大小,指的是该对象本身的大小。如果该对象包含一个指向另一个对象的引用, 4 字节或
8 字节的引用会计算在内,但是目标对象的大小不会包含进来。
深对象
深大小则包含那些对象的大小。深大小与保留大小的区别在于那些存在共享的对象。
7.1.3 内存溢出错误
在下列情况下, JVM 会抛出内存溢出错误( OutOfMemoryError) :
• JVM 没有原生内存可用;
• 永久代(在 Java 7 和更早的版本中)或元空间(在 Java 8 中)内存不足;
• Java 堆本身内存不足——对于给定的堆空间而言,应用中活跃对象太多;
• JVM 执行 GC 耗时太多
-XX:+HeapDumpOnOutOfMemoryError
该标志默认为 false,打开该标志, JVM 会在抛出 OutOfMemoryError 时创建堆转储。
-XX:HeapDumpPath=<path>
该标志指定了堆转储将被写入的位置;默认会在应用的当前工作目录下生成java_ pid<pid>.hprof文件。这里的路径可以指定目录(这种情况下会使用默认的文件
名),也可以指定要生成的实际文件的名字。
-XX:+HeapDumpAfterFullGC
这会在运行一次 Full GC 后生成一个堆转储文件。
-XX:+HeapDumpBeforeFullGC
这会在运行一次 Full GC 之前生成一个堆转储文件。
达到GC的开销限制
JVM 抛出 OutOfMemoryError 的最后一种情况是 JVM 认为在执行 GC 上花费了太多时间:
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded
当满足下列所有条件时就会抛出该错误。
- 花在 Full GC 上的时间超出了 -XX:GCTimeLimit=N 标志指定的值。其默认值是 98(也就
是,如果 98% 的时间花在了 GC 上,则该条件满足)。 - 一次 Full GC 回收的内存量少于
-XX:GCHeapFreeLimit=N标志指定的值。其默认值是 2,
这意味着如果 Full GC 期间释放的内存不足堆的 2%,则该条件满足。 - 上面两个条件连续 5 次 Full GC 都成立(这个数值是无法调整的)。
-XX:+UseGCOverhead-Limit标志的值为 true(默认如此)。
请注意,所有四个条件必须都满足。一般来说,应用中连续执行了 5 次以上的 Full GC,不一定会抛出 OutOfMemoryError。其原因是,即便应用将 98% 的时间花费在执行 Full GC 上,但是每次 GC 期间释放的堆空间可能会超过 2%。这种情况下可以考虑增加 GCHeapFreeLimit 的值。
7.2 减少内存使用
堆内存用的越少,堆被填满的几率就越低,需要的 GC 周期也越少。而且有倍乘效应:新生代回收的次数更少,对象的晋升年龄也就不会很频繁地增加,这意味着对象被提升到老年代的可能性也降低了。
7.2.1 减少对象大小
-
减少对象大小有两种方式:减少实例变量的个数(效果很明显),或者减少实例变量的大小(效果没那么明星)。
-
对象大小未必总能很明显地看出来:对象会被填充到 8 字节的边界,对象引用的大小在 32 位和 64 位 JVM 上也有所不同。
-
对象内部即使为 null 的实例变量也会占用空间
7.2.2 延迟初始化
- 要延迟初始化其字段,在计算性能上会有一点小小的损失,代码每次执行时都必须测试变量的状态:
- 如果问题中的这个操作使用不太频繁,那延迟初始化最适合:如果操作很常用,实际上没有节省内存(总是会分配这些实例),而常用操作又有轻微的性能损失。
- 检查要进行延迟初始化的变量是不是已经被初始化了,未必总会有性能损失
尽早清理
- 只有当常用的代码路径不会初始化某个变量时,才去考虑延迟初始化该变量。
- 一般不会在线程安全的代码上引入延迟初始化,否则会加重现有的同步成本。
- 对于使用了线程安全对象的代码,如果要采用延迟初始化,应该使用双重检查锁。
7.2.3 不可变对象和标准化对象
- 不可变对象为标准化(canonicalization)这种特殊的生命周期管理提供了可能性。
- 通过标准化去掉不可变对象的冗余副本,可以极大减少应用消耗的堆内存
7.2.4 字符串的保留
- 表的大小可以在 JVM 启动时使用 -XX:StringTableSize=N(如前面所介绍的,默认值为 1009 或 60 013) 。如果某个应用会保留大量字符串,就应该增加这个值。如果这个值是个素数,字符串保留表的效率最高。
- 注意,如果字符串保留表的大小设置不当,性能损失会相当严重。一旦根据预期数据设置了该表的大小,性能会极大改善。
如果想看看字符串表的执行过程,可以使用 -XX:+PrintStringTableStatistics 参数(这个标志要求 JDK 7u6 或更新版本,默认为 false)运行应用。当 JVM 退出时,它会打印一个这样的列表:
StringTable statistics:
Number of buckets : 1009
Average bucket size : 3008
Variance of bucket size : 2870
Std. dev. of bucket size: 54
Maximum bucket size : 3186
7.3 对象生命周期管理
7.3.1 对象重用
- 对象重用通常有两种实现方式:对象池和线程局部变量。
- 对象在堆中 存留的时间越长, GC 的效率越差。
下面是 JDK 和 Java EE 中重用对象的一些例子,以及重用的原因:
线程池
线程初始化的成本很高。
JDBC 池
数据库连接初始化的成本很高。
EJB 池
EJB 初始化的成本很高(参见第 10 章)。
大数组
Java 要求,一个数组在分配的时候,其中的每个元素都必须初始化为某个默认值( null、 0 或者 false,根据具体情况而定)。对于很大的数组,这是非常耗时的。
原生 NIO 缓冲区
不管缓冲区多大,分配一个直接的 java.nio.Buffer(即调用 allocateDirect() 方法返回的缓冲区),这个操作都非常昂贵。最好是创建一个很大的缓冲区,然后通过按需切堆内存最佳实践 割的方式来管理,以便将其重用于以后的操作。
安全相关类
MessageDigest、 Signature 以及其他安全算法的实例,初始化的成本都很高。基于Apache 的 XML 代码就是使用线程局部变量保存这些实例的。
字符串编解码器对象
JDK 中的很多类都会创建和重用这些对象。在大多数情况下,这些还是软引用
StringBuilder 协助者
BigDecimal 类在计算中间结果时会重用一个 StringBuilder 对象。
随机数生成器
Random 类和(特别是) SecureRandom 类,生成它们的实例的代价是很高的。
从 DNS 查询到的名字
网络查询代价很高。
ZIP 编解码器
有一种有趣的变化,初始化的开销不是特别高,但是释放的成本很高,因为这些对象要依赖对象终结操作(finalization)来确保释放掉所用的原生内存。
7.3.2 弱引用、 软引用与其他引用
引用(Reference)
引用(或者说对象引用)可以是任何类型的引用:强引用、弱引用、软引用等。指向一个对象的普通引用实例变量就是一个强引用。
非确定引用(Indefinite reference)
本书使用这个术语来区分强引用和其他特殊引用(比如软引用或弱引用)。一个非确定应用其实是一个对象实例(比如, SoftReference 类的一个实例)。
所引对象(Referent)
非确定引用的工作方式是,在非确定引用类的实例内,嵌入另一个引用(几乎总是嵌入一个强引用)。被封装的对象称作“所引对象”。
- 非确定引用会导致应用使用更多内存。对垃圾收集器的更大的影响体现为,垃圾收集器要回收非确定引用,至少需要两个 GC 周期。
- 当运行一个使用了大量非确定引用的对象时,可以考虑添加 -XX:+PrintReferenceGC 标志(默认为 false)。这样就能看到处理这些引用花了多少时间
1. 软引用
- 如果问题中的对象以后有很大的机会重用,可以使用软引用,但是如果该对象近期一直没有使用到(计算时也会考虑堆还有多少内存可用),垃圾收集器会回收它。软引用本质上是一个比较大的、最近最久未用(LRU)的对象池。获得较好性能的关键是确保它们会被及时清理。
一个软引用何时会被释放呢?
首先,所引对象一定不能有其他的强引用。如果软引用是指向其所引对象的唯一引用,而且该软引用最近没有被访问过,则所引对象会在下一次 GC 周期释放。
对 于 长 期 运 行 的 应 用, 如 果 满 足 如 下 两 个 条 件, 可 以 考 虑 增 大SoftReflRUPolicyMSPerMB 的值:
- 有很多空闲堆可用;
- 软引用会频繁访问。
2.弱引用
- 当问题中的所引对象会同时被几个线程使用时,应该考虑弱引用。否则,弱引用很可能会被垃圾收集器回收:只有弱引用的对象在每个 GC 周期都可以回收。
3. 终结器(Finalizer) 和最终引用(Final Reference)
- 每个 Java 类都有一个从 Object 类继承而来的 finalize() 方法;在对象可以被垃圾收集器回收时,可以用这个方法来清理数据。
- 在非确定应用对象释放之前,至少需要两个 GC 周期。然而,这里的性能损失要比其他非确定引用类型大得多。
- finalize() 方法可能会不小心又创建了一个指向所引对象的新的强引用。
8.原生内存最佳实践
8.1 内存占用
- JVM 使用的原生内存和堆内存的总量,就是一个应用总的内存占用( Footprint)。
8.1.1 测量内存占用
8.1.2 内存占用最小化
堆
堆是最大的一块内存,尽管有些出人意料,它可能只占总内存占用的 50% 到 60%。可以将堆的最大值设置为一个较小的值(或者设置 GC 调优参数,比如控制堆不会被完全占满),以此限制程序的内存占用。
线程栈
线程栈非常大,特别是对 64 位 JVM 而言。
代码缓存
代码缓存使用原生内存来保存编译后的代码。
直接字节缓冲区
8.1.3 原生NIO缓冲区
- 原生字节缓冲区非常重要,因为它们支持原生代码和 Java 代码在不复制的情况下共享数据。最常见的例子是用于文件系统和套接字(socket)操作的缓冲区。把数据写入一个原生 NIO 缓冲区,然后再发送给通道(channel,比如文件或套接字),不需要在 JVM 和用于传输数据的 C 库之间复制数据。如果使用的是堆字节缓冲区, JVM 则必须复制该缓冲区的内容。
- 应用可以分配一个非常大的直接字节缓冲区,然后每个请求使用 ByteBuffer 类的 slice() 方法从中分配一部分。如果不能保证每次分配相同的大小,这种方案就很难处理:就像在分配和释放不同大小的对象时堆会呈现出碎片化一样,最初分配的这个字节缓冲区也会变得碎片化。然而与堆不同的是,字节缓冲区的不同片段是无法压缩的,所以只有当所有片段大小都相同时,这种解决方案才好用。
8.1.4 原生内存跟踪
-XX:NativeMemoryTracking=off|summary|detail这个选项, JVM 支持我们一窥它是如何分配原生内存的。原生内存跟踪( Native Memory Tracking, NMT)默认是关闭的( off 模式)。如果开启了概要模式( summary)或详情模式( detail),可以随时通过 jcmd 命令获得原生内存的信息:
% jcmd process_id VM.native_memory summary
8.2 针对不同操作系统优化JVM
8.2.1 大页
参考:https://blog.csdn.net/qq_21383435/article/details/115015062
8.2.2 压缩的oop
- 压缩的 oop 会在最有用的时候默认开启。
- 使用了压缩 oop 的 31 GB 的堆,与稍微大一些、但因为堆太大而无法使用压缩 oop 的堆相比,性能通常要好一些。
9.线程与同步的性能
9.1 线程池与ThreadPoolExecutor
这个有过详细了解,这里可看可不看
9.2 ForkJoinPool
ForkJoinPool 在内部会使用一个无界任务列表,供构造器中所指定数目(如果所选的是无参构造器,则为该机器上的 CPU 数)的线程来运行。
ForkJoinPool 类是为配合分治算法的使用而设计的:任务可以递归地分解为子集。这些子集可以并行处理,然后每个子集的结果被归并到一个结果中。一个经典的例子就是快速排序算法。
9.3 线程同步
9.3.1 同步的代价
同步代码对性能有两个方面的影响。其一,应用在同步块上所花的时间会影响该应用的可伸缩性。其二, 获取同步锁需要一些 CPU 周期,所以也会影响性能。
1. 同步与可伸缩性

2. 锁定对象的开销
首先是获取同步锁的成本。如果某个锁没有被争用(即两个线程没有同时尝试访问这个锁),那这方面的开销会相当小。 synchronized 关键字和 CAS 指令之间有轻微的差别。非竞争的 synchronized 锁被称为非膨胀( uninflated)锁, 获取非膨胀锁的开销在几百纳秒的数量级。非竞争的 CAS 代码损失会更小。
- 线程同步有两个性能方面的代价:限制了应用的可伸缩性,以及获取锁是有开销的。
- 同步的内存语义、基于 CAS 的设施和 volatile 关键字对性能可能会有很大的影响,特别是在有很多寄存器的大型机上
9.3.2 避免同步
在通常情况下,在比较基于 CAS 的设施和传统的同步时,可以使用如下指导原则。
- 如果访问的是不存在竞争的资源,那么基于 CAS 的保护要稍快于传统的同步(虽然完全不使用保护会更快)。
- 如果访问的资源存在轻度或适度的竞争,那么基于 CAS 的保护要快于传统的同步(而且往往是快得多)。
- 随着所访问资源的竞争越来越剧烈,在某一时刻,传统的同步就会成为更高效的选择。在实践中,这只会出现在运行着大量线程的非常大型的机器上。
- 当被保护的值有多个读取,但不会被写入时,基于 CAS 的保护不会受竞争的影响。
9.3.3 伪共享
大多数情况下,像这样加载邻接的值是有意义的:如果程序访问了对象中的某个特定实例变量,则很有可能会访问邻接的实例变量。如果这些实例变量被加载到当前核的高速缓存中,内存访问就非常快,这是很大的性能优势。
这种模式的缺点是,当程序更新本地缓存中的某个值时,当前的核必须通知其他所有核:这个内存被修改了。其他核必须作废其缓存行,并重新从内存中加载。
不论何时, CPU 缓存中有任何数据被写入了,其他保存了同样范围数据的缓存都必须作废。
- 对于会频繁地修改 volatile 变量或退出同步块的代码,伪共享对性能影响很大。
- 伪共享很难检测。如果某个循环看上去非常耗时,可以检查该代码,看看是否与伪共享出现时的模式相匹配。
- 最好通过将数据移到局部变量中、稍后再保存来避免伪共享。作为一种替代方案,有时可以使用填充将冲突的变量移到不同的缓存行中
9.4 JVM线程调优
9.4.1 调节线程栈大小
每个线程都有一个原生栈,操作系统用它来保存该线程的调用栈信息(比如, main() 方法调用了 calculate() 方法,而 calculate()方法又调用了 add() 方法,栈会把这些信息记录下来)。
几种JVM的默认栈大小
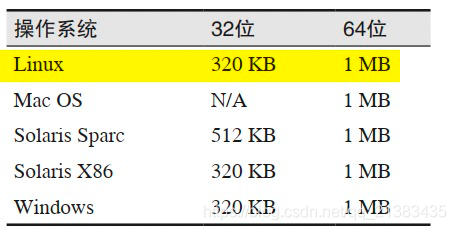
- 在内存比较稀缺的机器上,可以减少线程栈大小。
- 在 32 位的 JVM 上,可以减少线程栈大小,以便在 4 GB 进程空间限制的条件下,稍稍增加堆可以使用的内存
9.4.2 偏向锁
偏向锁即锁可以偏向于对它访问最为频繁的线程。
偏向锁背后的理论依据是,如果一个线程最近用到了某个锁,那么线程下一次执行由同一把锁保护的代码所需的数据可能仍然保存在处理器的缓存中。如果给这个线程优先获得这把锁的权利,缓存命中率可能就会增加。如果实现了这点,性能会有所改进。但是因为偏向锁也需要一些簿记信息,故有时性能可能会更糟。
9.4.3 自旋锁
对于想要获得锁而陷入阻塞的线程,可以让它进入忙循环,执行一些指令,然后再次检查这个锁。也可以把这个线程放入一个队列,在锁可用时通知它(使得 CPU 可供其他线程使用)
如果多个线程竞争的锁的被持有时间较短,那忙循环(所谓的线程自旋)就比另一个方案快得多。如果被持有时间较长,则让第二个线程等待通知会更好,而且这样第三个线程也有机会使用 CPU。
-XX:+UseSpinning标志,该标志可以开启或关闭自旋锁。从 Java 7u40(以及 Java 8 中)开始, Java 不再支持该标志,使用这个标志会报错。
9.4.4 线程优先级
每个 Java 线程都有一个开发者定义的优先级,这是应用提供给操作系统的一个线索,用以说明特定线程在其眼中的重要程度。如果有不同线程处理不同任务,你可能会认为,可以以让其他任务在优先级较低的线程上运行为代价,使用线程优先级来改进特定任务的性能。遗憾的是,实际不会这么有用。
操作系统会为机器上运行的每个线程计算一个“当前”(current)优先级。当前优先级会考虑 Java 指派的优先级,但是还会考虑很多其他的因素,其中最重要的一个是:自线程上次运行到现在所持续的时间。这可以确保所有的线程都有机会在某个时间点运行。不管优先级高低,没有线程会一直处于“饥饿”状态,等待访问 CPU
9.5 监控线程与锁
总的线程数(既不能太大,也不能太小)和线程花在等待锁或其他资源上的时间。
9.5.1 查看线程
9.5.2 查看阻塞线程
- 利用系统提供的线程基本信息,可以对正在运行的线程的数目有个大致了解。
- 就性能分析而言,当线程阻塞在某个资源或 I/O 上时,能够看到线程的相关细节就显得比较重要。
- JFR 使得我们可以很方便地检查引发线程阻塞的事件。4 利用 jstack,一定程度上可以检查线程是阻塞在什么资源上。
10.Java EE性能调优
这一章,一堆烂七八糟的东西,可看可不看。
11. 数据库性能的最佳实践
本章主要介绍了jdbc ,预处理语句,以及连接池,事务,结果集的处理等。
11.1.5 结果集的处理
SELECT * FROM stockprice WHERE symbol = 'TPKS' AND
pricedate >= '2013-01-01' AND pricedate <= '2013-12-31';
这条语句会返回 261 条数据记录。如果还需要对应股票的股价,可以采用类似的查询得到五倍数量的记录。获取样本数据库中所有数据(128 支股票一年的数据)的 SQL 语句会返回 200 448 条数据记录。
SELECT * FROM stockprice s, stockoptionprice o WHERE
o.symbol = s.symbol AND s.pricedate >= '2013-01-01'
AND s.pricedate <= '2013-12-31';
为了使用这些数据,代码需要遍历结果集:
PreparedStatement ps = c.prepareStatement(...);
ResultSet rs = ps.executeQuery();
while (rs.next()) {
……读取当前的行……
}
这里就有一个问题,即这 200 448 条记录保存在什么地方。如果整个结果集的数据都在执行 executeQuery()调用时返回,应用程序就会在它的堆内保存大量的活跃数据,而这可能会导致 GC 或者其他的问题。与此相反,如果只返回调用 next() 方法时的一行数据,在处理结果集时,应用和数据库之间就会有大量的往返流量。
与之前一样,这个问题也没有所谓的正确答案;在有的情况下,在数据库中保持大多数的数据,需要时进行提取是更高效的方法;而在另一些场景里,查询时一次性地将所有的数据返回可能会更高效。通过 PreparedStatement 对象的setFetchSize()方法可以控制这些行为,它能通知 JDBC 驱动程序一次返回多少行数据。
这个参数的默认值随 JDBC 驱动程序的不同而异;譬如对 Oracle 的 JDBC 驱动程序,该默认值是 10。在上面展示的循环语句中调用executeQuery()方法, Oracle 数据库会返回 10行数据,返回的数据会由 JDBC 驱动程序在内部缓存。头 10 次 next() 方法的调用都直接从缓存行中读取,返回其中的一条记录。第 11 次调用该方法时, JDBC 驱动程序会向数据库发出请求,取得另 10 行数据,如此周而复始。
11.2 JPA
下面是jpa相关的,这章,我不用Jpa也不想了解,直接过去。
12.Java SE API技巧
12.1 缓冲式I/O
InputStream.read() 和 OutputStream.write()方法操作的是一个字符。由于所访问资源不同,这些方法有可能非常慢。而在fileInputStream上调用 read()方法,更是慢得难以形容:每次调用该方法,都要进入内核,去取一个字节的数据。在大多数操作系统上,内核都会缓冲 I/O,因此,很幸运,该场景不会在每次调用 read() 方法时触发一次磁盘读取操作。但是这种缓冲保存在内核中,而非应用中,这就意味着每次读取一个字节时,每个方法调用还是会涉及一次代价高昂的系统调用。
写数据也是如此:使用 write()方法向fileOutputStream发送一个字节,也需要一次系统调用,将该字节存储到内核缓冲区中。最后(当文件关闭或刷新时),内核会把缓冲区中的内容写入磁盘。
对于使用二进制数据的文件 I/O,记得使用一个BufferedInputStream或 BufferedOutputStream来 包 装 底 层 的 文 件 流。 对 于 使 用 字 符( 字 符 串 ) 数 据 的 文 件 I/O, 记 得 使 用 一 个BufferedReader 或 BufferedWriter来包装底层的流。
12.2 类加载
- 在存在多个类加载器的复杂应用(特别是应用服务器)中 ,让这些类加载器支持并行,可以解决系统类加载器或者启动类加载器上的瓶颈问题。
- 如果应用是在单线程内,则通过一个类加载器加载很多类,关掉 Java 7支持并行的特性可能会有好处。
12.3 随机数
参考:https://blog.csdn.net/qq_21383435/article/details/115027415
12.4 Java原生接口
- 如果想编写尽可能快的代码,要避免使用 JNI。
- 从 Java 调用 C 比 。从 C 调用 Java 开销更大:从 Java 调用 C,会隐式地把问题中的对象( this)传递给 C 函
数,从 C 调用 Java 则无需传递任何对象。
12.5 异常
- 现代 JVM 生成的代码可以非常高效地处理异常。
- (大部分)异常会涉及获取该异常发生时的栈轨迹信息。这一操作代价可能会很高,特别是在栈的轨迹很深时
- 代码显式地创建异常,或者是当 JVM 解析到空指针时创建异常(见表中的前两行)。目前的情况是,在某一个时刻,编译器会优化掉系统生成的异常; JVM 开始重用同一个异常对象,而不是每次需要时创建一个新的。不管调用栈是什么样的,相关的代码每次执行时都会重用这个对象; 而且这个异常实际上没有包含调用栈(也就是说, printStackTrace() 没有输出)。这种优化在完整的栈异常信息抛出很长一段时间之后才会出现,所以如果测试用例中没有包含足够长的热身周期,是不会看到这种效果的。
12.6 字符串的性能
- 一行的字符串连接代码性能很不错。
- 对于多行的连接操作,一定要确保使用 StringBuilder。
12.7 日志
- 为帮助用户找出问题,代码应该包含大量日志,但是这些日志默认都应该是关闭的。
- 如果 Logger 实例的参数需要调用方法或者分配对象,那么在调用该实例之前,不要忘了测试日志级别。
12.8 Java集合类API
12.8.1 同步还是非同步
12.8.2 设定集合的大小
12.8.3 集合与内存使用效率
- 仔细考虑如何访问集合,并为其选择恰当的同步类型。不过,在不存在竞争的条件下访问使用了内存保护的集合(特别是使用了基于 CAS 的保护的集合),性能损失会极小;有时候,保证安全性才是上策。
- 设定集合的大小对性能影响很大:集合太大,会使得垃圾收集器变慢;集合太小,又会导致大量的大小调整与复制。
12.9 AggressiveOpts标志
12.10 Lambda表达式和匿名类
- 如果要在 Lambda 表达式和匿名类之间做出选择,则应该从方便编程的角度出发,因为性能上没什么差别。
- Lambda 表达式并没有实现为类,所以有个例外情况,即当类加载行为对性能影响很大时, Lambda 表达式略胜一筹。
12.11 流和过滤器的性能
- 过滤器因为支持在迭代过程中结束处理,所以有很大的性能优势。
- 即使都要处理整个数据集,一个过滤器还是要比一个迭代器稍微快些。
- 多个过滤器有些开销,所以要确保编写好用的过滤器。