Kafka 整体架构

Kafka是大数据领域无处不在的消息中间件,目前广泛使用在企业内部的实时数据管道,并帮助企业构建自己的流计算应用程序。
Kafka虽然是基于磁盘做的数据存储,但却具有高性能、高吞吐、低延时的特点,其吞吐量动辄几万、几十上百万。
Kafka为什么速度快、吞吐量大?
Kafka是将消息记录持久化到本地磁盘中的,一般人会认为磁盘读写性能差,可能会对Kafka性能如何保证提出质疑。实际上不管是内存还是磁盘,快或慢关键在于寻址的方式,磁盘分为顺序读写与随机读写,内存也一样分为顺序读写与随机读写。基于磁盘的随机读写确实很慢,但磁盘的顺序读写性能却很高,一般而言要高出磁盘随机读写三个数量级,一些情况下磁盘顺序读写性能甚至要高于内存随机读写。
这里给出著名学术期刊 ACM Queue 上的性能对比图: queue.acm.org/detail.cf

磁盘的顺序读写是磁盘使用模式中最有规律的,并且操作系统也对这种模式做了大量优化,Kafka就是使用了磁盘顺序读写来提升的性能。Kafka的message是不断追加到本地磁盘文件末尾的,而不是随机的写入,这使得Kafka写入吞吐量得到了显著提升 。


上图就展示了Kafka是如何写入数据的, 每一个Partition其实都是一个文件 ,收到消息后Kafka会把数据插入到文件末尾(虚框部分)。
这种方法有一个缺陷—— 没有办法删除数据 ,所以Kafka是不会删除数据的,它会把所有的数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示 读取到了第几条数据 。
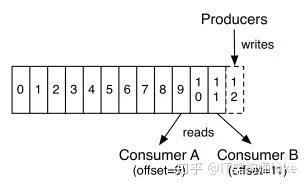
两个消费者,Consumer1有两个offset分别对应Partition0、Partition1(假设每一个Topic一个Partition);Consumer2有一个offset对应Partition2。这个offset是由客户端SDK负责保存的,Kafka的Broker完全无视这个东西的存在;一般情况下SDK会把它保存到zookeeper里面。(所以需要给Consumer提供zookeeper的地址)。
如果不删除硬盘肯定会被撑满,所以Kakfa提供了两种策略来删除数据。一是基于时间,二是基于partition文件大小。具体配置可以参看它的配置文档:http://kafka.apache.org/08/documentation/#configuration。
在kafka/config/目录下面有3个配置文件:
producer.properties
consumer.properties
server.properties
详细配置文件参考:https://www.jianshu.com/p/c5618df93b43。
Page Cache 是什么?
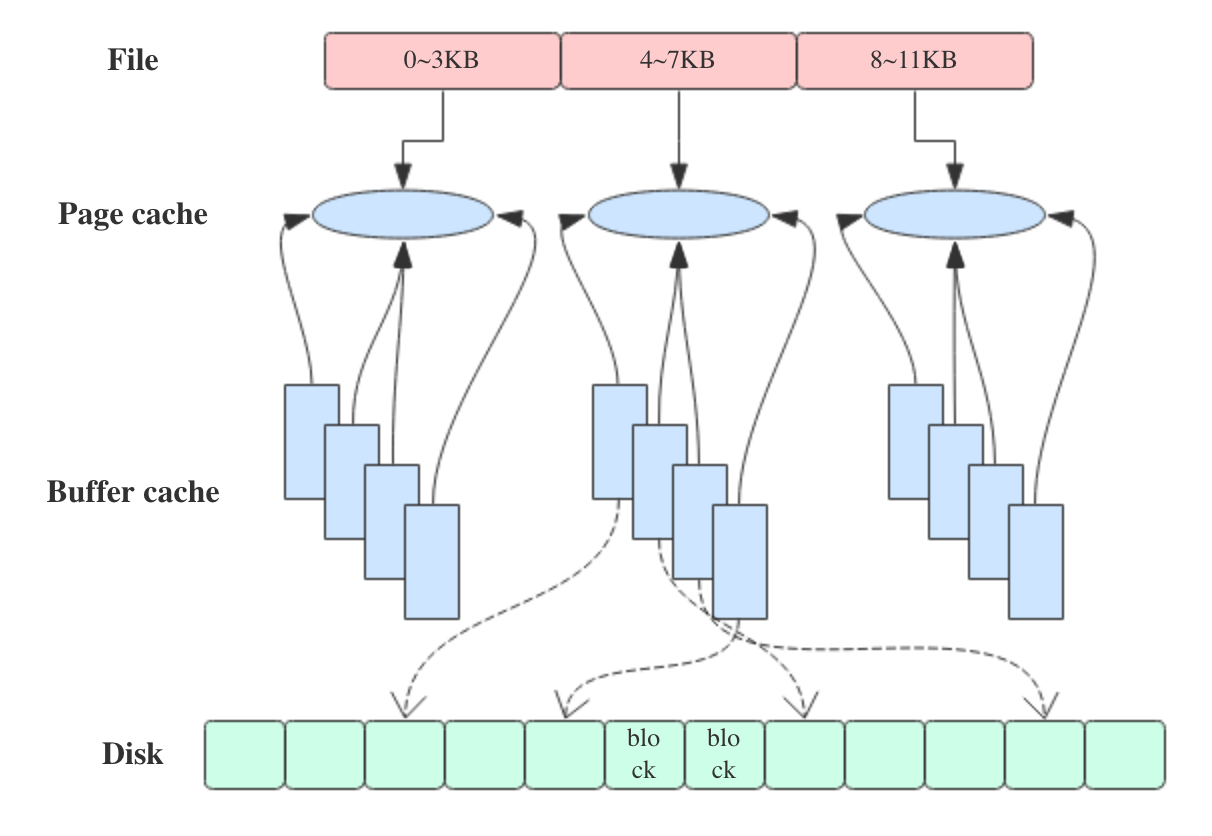
PageCache是OS对文件的缓存,用于加速对文件的读写。一般来说,程序对文件进行顺序读写的速度几乎接近于内存的读写访问,这里的主要原因就是在于OS使用PageCache机制对读写访问操作进行了性能优化,将一部分的内存用作PageCache。
对于数据文件的读取,如果一次读取文件时出现未命中(cache miss)PageCache的情况,OS从物理磁盘上访问读取文件的同时,会顺序对其他相邻块的数据文件进行预读取(顺序读入紧随其后的少数几个页面)。这样,只要下次访问的文件已经被加载至PageCache时,读取操作的速度基本等于访问内存。
Page Cache是针对文件系统的缓存,通过将磁盘中的文件数据缓存到内存中,从而减少磁盘I/O操作提高性能。
对磁盘的数据进行缓存从而提高性能主要是基于两个因素:
- 磁盘访问的速度比内存慢好几个数量级(毫秒和纳秒的差距);
- 被访问过的数据,有很大概率会被再次访问。
文件 IO 读写流程
读流程
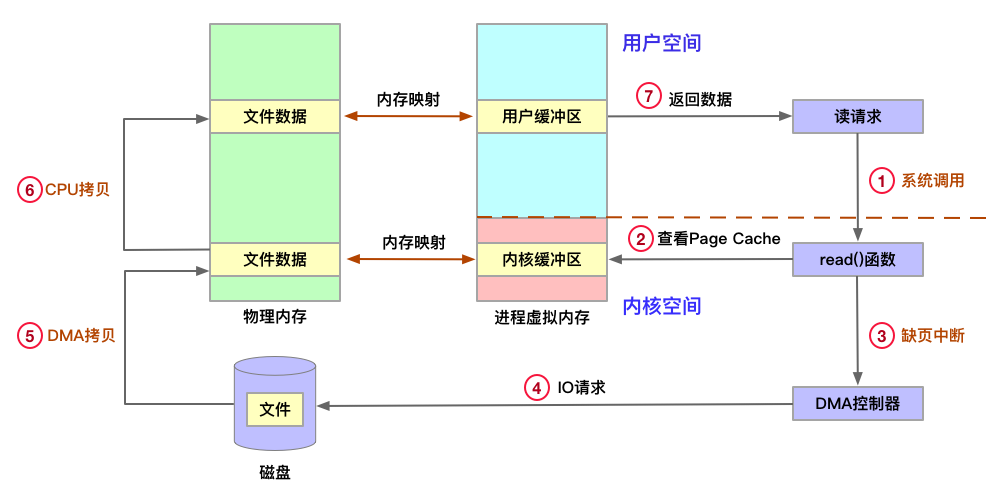
1、应用程序发起读请求,触发系统调用read()函数,用户态切换为内核态;
2、文件系统通过目录项→inode→address_space→页缓存树,查询Page Cache是否存在;
3、Page Cache不存在产生缺页中断,CPU向DMA发出控制指令;
DMA 控制器将数据从主存或硬盘拷贝到内核空间(kernel space)的缓冲区(read buffer);
4、DMA 磁盘控制器向 CPU 发出数据读完的信号,由 CPU 负责将数据从内核缓冲区拷贝到用户缓冲区;
5、用户进程由内核态切换回用户态,获得文件数据;

写流程

1、应用程序发起写请求,触发系统调用write()函数,用户态切换为内核态;
2、文件系统通过目录项→inode→address_space→页缓存树,查询 Page Cache是否存在,如果不存在则需要创建;
3、Page Cache 存在后,CPU将数据从用户缓冲区拷贝到内核缓冲区,Page Cache 变为脏页(Dirty Page,内存数据页跟磁盘数据页内容不一致),写流程返回;
4、用户主动触发刷盘或者达到特定条件内核触发刷盘,唤醒 pdflush 线程,pdflush 将内核缓冲区的数据刷入磁盘;
脏页: 当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为“脏页”。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”。
pdflush回写时机
定时方式执行;
内存不足时;
用户主动触发;
DMA传输
DMA 的全称叫直接内存存取(Direct Memory Access),是一种允许外围设备(硬件子系统)直接访问系统主内存的机制。基于 DMA 访问方式,硬件与内核缓冲区的数据传输由DMA控制器控制,CPU只需在数据传输开始和结束时做一点处理外(开始和结束时候要做中断处理),释放了CPU。目前大多数的硬件设备,包括磁盘控制器、网卡、显卡以及声卡等都支持 DMA 技术。
https://blog.csdn.net/yangguosb/article/details/77886826
2、读Cache
当内核发起一个读请求时(例如进程发起read()请求),首先会检查请求的数据是否缓存到了Page Cache中。
如果有,那么直接从内存中读取,不需要访问磁盘,这被称为cache命中(cache hit);
如果cache中没有请求的数据,即cache未命中(cache miss),就必须从磁盘中读取数据。然后内核将读取的数据缓存到cache中,这样后续的读请求就可以命中cache了。
page可以只缓存一个文件部分的内容,不需要把整个文件都缓存进来。
3、写Cache
当内核发起一个写请求时(例如进程发起write()请求),同样是直接往cache中写入,后备存储中的内容不会直接更新(当服务器出现断电关机时,存在数据丢失风险)。
内核会将被写入的page标记为dirty,并将其加入dirty list中。内核会周期性地将dirty list中的page写回到磁盘上,从而使磁盘上的数据和内存中缓存的数据一致。
当满足以下两个条件之一将触发脏数据刷新到磁盘操作:
- 数据存在的时间超过了dirty_expire_centisecs(默认300厘秒,即30秒)时间;
- 脏数据所占内存 > dirty_background_ratio,也就是说当脏数据所占用的内存占总内存的比例超过dirty_background_ratio(默认10,即系统内存的10%)的时候会触发pdflush [note]刷新脏数据。
Kafka 对 page cache 的利用
Kafka为什么不自己管理缓存,而非要用page cache?原因有如下三点:
1.JVM中一切皆对象,数据的对象存储会带来所谓object overhead,浪费空间;
2.如果由JVM来管理缓存,会受到GC的影响,并且过大的堆也会拖累GC的效率,降低吞吐量;
3.一旦程序崩溃,自己管理的缓存数据会全部丢失。
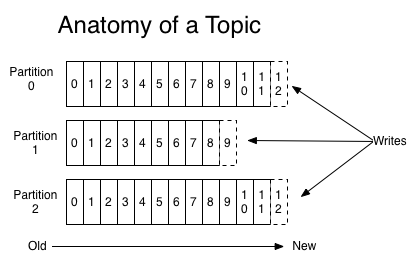
Kafka三大件(broker、producer、consumer)与page cache的关系可以用下面的简图来表示。

producer生产消息时,会使用pwrite()系统调用【对应到Java NIO中是FileChannel.write() API】按偏移量写入数据,并且都会先写入page cache里。consumer消费消息时,会使用sendfile()系统调用【对应FileChannel.transferTo() API】,零拷贝地将数据从page cache传输到broker的Socket buffer,再通过网络传输。
图中没有画出来的还有leader与follower之间的同步,这与consumer是同理的:只要follower处在ISR中,就也能够通过零拷贝机制将数据从leader所在的broker page cache传输到follower所在的broker。
同时,page cache中的数据会随着内核中flusher线程的调度以及对sync()/fsync()的调用写回到磁盘,就算进程崩溃,也不用担心数据丢失。另外,如果consumer要消费的消息不在page cache里,才会去磁盘读取,并且会顺便预读出一些相邻的块放入page cache,以方便下一次读取。
由此我们可以得出重要的结论:如果Kafka producer的生产速率与consumer的消费速率相差不大,那么就能几乎只靠对broker page cache的读写完成整个生产-消费过程,磁盘访问非常少。这个结论俗称为“读写空中接力”。并且Kafka持久化消息到各个topic的partition文件时,是只追加的顺序写,充分利用了磁盘顺序访问快的特性,效率高。
关于 Linux 文件 IO 读写,参考:https://www.jianshu.com/p/d81f51e58b83
Java 的 IO 读写
Java的 IO读写大致分为三种:
1、普通IO(java.io)
例如FileWriter、FileReader等,普通IO是传统字节传输方式,读写慢阻塞,单向一个Read对应一个Write 。
2、文件通道 FileChannel(java.nio)
FileChannel fileChannel = new RandomAccessFile(new File("data.txt"), "rw").getChannel()全双工通道,采用内存缓冲区ByteBuffer且是线程安全的
使用FileChannel为什么会比普通IO快?
一般情况FileChannel在一次写入4kb的整数倍数时,才能发挥出实际的性能,益于FileChannel采用了ByteBuffer这样的内存缓冲区。这样可以精准控制写入磁盘的大小,这是普通IO无法实现FileChannel是直接把ByteBuffer的数据直接写入磁盘?
ByteBuffer 中的数据和磁盘中的数据还隔了一层,这一层便是 PageCache,是用户内存和磁盘之间的一层缓存。我们都知道磁盘 IO 和内存 IO 的速度可是相差了好几个数量级。我们可以认为 filechannel.write 写入 PageCache 便是完成了落盘操作,但实际上,操作系统最终帮我们完成了 PageCache 到磁盘的最终写入,理解了这个概念,你就应该能够理解 FileChannel 为什么提供了一个 force() 方法,用于通知操作系统进行及时的刷盘,同理使用FileChannel时同样经历:
磁盘->PageCache->用户内存
这三个阶段。
3、内存映射MMAP(java.nio)
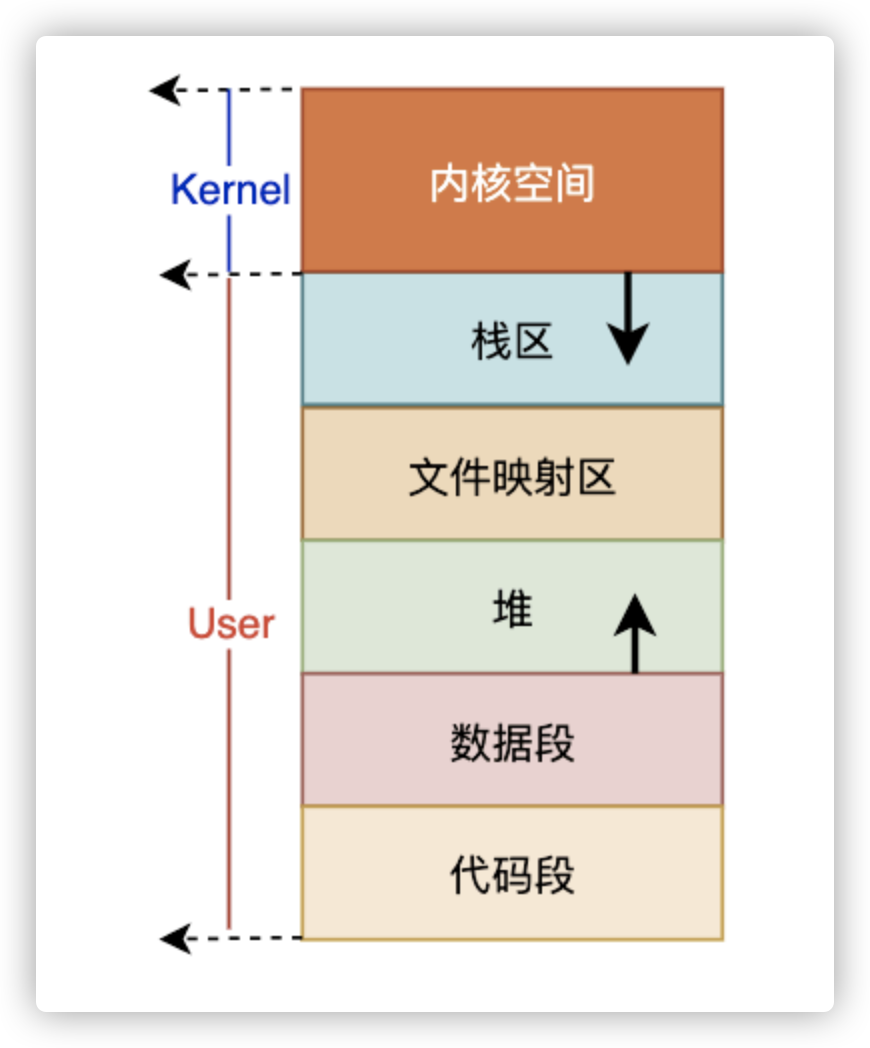
mmap的工作原理:当你发起这个 mmap 文件读写调用的时候,它只是在你的虚拟空间中分配了一段空间,连真实的物理地址都不会分配的。在你访问这段空间的时刻,CPU触发了 OS内核缺页异常[note],执行 PageFault 异常处理,然后异常处理会在这个时间分配物理内存,并用文件的内容填充这片内存,然后才返回你进程的上下文,这时你的程序才会感知到这片内存里有数据。Linux 是直到,实在实在是不行的时候,才会分配物理页。https://www.zhihu.com/question/48161206/answer/110418693
note:关于缺页异常,参考:https://www.jianshu.com/p/5ff9b1b3c95e
Java 中的 mmap 实现类: MappedByteBuffer
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, position, fileSize)
mmap 把文件映射到用户空间里的虚拟内存,省去了从内核缓冲区复制到用户空间的过程,文件中的位置在虚拟内存中有了对应的地址,可以像操作内存一样操作这个文件,相当于已经把整个文件放入内存,但在真正使用到这些数据前却不会消耗物理内存,也不会有读写磁盘的操作,只有真正使用这些数据时,也就是图像准备渲染在屏幕上时,虚拟内存管理系统 VMS
MMAP 并非是文件 IO 的银弹,它只有在一次写入很小量数据的场景下才能表现出比 FileChannel 稍微优异的性能。紧接着我还要告诉你一些令你沮丧的事,至少在 JAVA 中使用 MappedByteBuffer 是一件非常麻烦并且痛苦的事,主要表现为三点:
MMAP 使用时必须实现指定好内存映射的大小,并且一次 map 的大小限制在 1.5G 左右,重复 map 又会带来虚拟内存的回收、重新分配的问题,对于文件不确定大小的情形实在是太不友好了。
MMAP 使用的是虚拟内存,和 PageCache 一样是由操作系统来控制刷盘的,虽然可以通过 force() 来手动控制,但这个时间把握不好,在小内存场景下会很令人头疼。
MMAP 的回收问题,当 MappedByteBuffer 不再需要时,可以手动释放占用的虚拟内存。
参考资料
https://www.jianshu.com/p/958f82922e4bhttps://blog.csdn.net/yancychas/article/details/88561291https://blog.csdn.net/gx11251143/article/details/107620259https://zhuanlan.zhihu.com/p/22604682https://www.sohu.com/a/406019130_115128https://blog.csdn.net/yangguosb/article/details/77886826