1.解决问题
通过形如:com.xxx.yyy.zzz形式的包名,加载包下所有的类
2.代码:
package com.chuyutech.rssp.openservice.service.data;
import java.io.File;
import java.io.FileFilter;
import java.io.IOException;
import java.net.URL;
import java.net.URLDecoder;
import java.util.Enumeration;
import java.util.LinkedHashSet;
import java.util.Set;
/**
* @description: 简单的文件操作类,包含一些文件的基本操作
*
* @author cwh
*
*/
public class FileOpreation {
/**
* 根据包名访问磁盘文件
*
* @param packageName:形如com.xxx.yyy.zzz以点号分割
*/
public static Set<Class<?>> getClazz(String packageName) {
// 是否递归
boolean isRecursion = true;
// 定义变量,保存class文件
Set<Class<?>> clazz = new LinkedHashSet<Class<?>>();
char dot = '.';
char sprit = '/';
try {
// 根据当前线程获取ContextClassLoader类加载器 需注意:分隔符的转换
// getResources方法定义的资源是 '/' 分隔符
Enumeration<URL> resources = Thread.currentThread().getContextClassLoader()
.getResources(packageName.replace(dot, sprit));
// 遍历枚举
while (resources.hasMoreElements()) {
URL url = resources.nextElement();
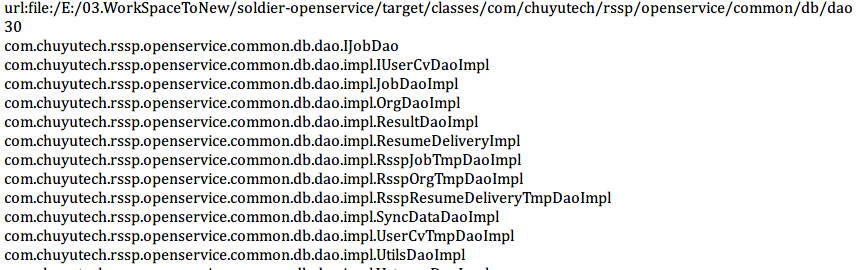
// url:file:/E:/03.WorkSpaceToNew/soldier-openservice/target/classes/com/chuyutech/rssp/openservice/common/db/dao
System.out.println("url:" + url.toString());
// 获取协议名称
String protocol = url.getProtocol();
// 如果为文件类型 接下来就是File类的操作
if (protocol.equals("file")) {
// 使用特定的编码方案解码url
String packagePath = URLDecoder.decode(url.getFile(), "UTF-8");
// 调用方法递归获取文件
getClazzFromPath(packageName, packagePath, isRecursion, clazz);
}
}
} catch (IOException e) {
e.printStackTrace();
}
return clazz;
}
/**
* 获取文件中class文件
*
* @param packageName:包名;
* packagePath:文件路径;isRecursion:是否递归
*/
public static void getClazzFromPath(String packageName, String packagePath, boolean isRecursion,
Set<Class<?>> clazz) {
char dot = '.';
// 根据路径名获取File文件对象
File file = new File(packagePath);
if (!file.exists() || !file.isDirectory()) {
return;
}
// 以File数组的形式列出所有的文件
File[] files = file.listFiles(new FileFilter() {
// 匿名内部类重写FIleFilter
@Override
public boolean accept(File pathName) {
// 自定义过滤规则 如果可以循环(包含子目录) 或者是以.class结尾的文件(编译好的java类文件)
return ((isRecursion && pathName.isDirectory()) || pathName.getName().endsWith(".class"));
}
});
// 遍历files
for (File destFile : files) {
// 如果是目录 则继续扫描
if (destFile.isDirectory()) {
getClazzFromPath(packageName + dot + destFile.getName(), destFile.getAbsolutePath(), isRecursion,
clazz);
} else {
// 如果是编译后java类文件 去掉后面的.class 只留下类名
String fileName = destFile.getName().substring(0, destFile.getName().lastIndexOf(dot));
// 添加到集合中去 通过完整包名+"."+文件名 加载class
try {
// Class<?> forName = Class.forName(packageName + dot +
// className); 此方法在会初始化所加载类的static静态代码块
Class<?> loadClass = Thread.currentThread().getContextClassLoader()
.loadClass(packageName + dot + fileName);
clazz.add(loadClass);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
String packageName = "com.chuyutech.rssp.openservice.common.db.dao";
Set<Class<?>> clazz = getClazz(packageName);
System.out.println(clazz.size());
for (Class<?> class1 : clazz) {
System.out.println(class1.getName());
}
}
}
3.总结:
3.1:实现的大致逻辑:
根据当前线程获取ContextClassLoader类加载器 ,通过类加载器的getResources(String name)方法获取包名所对应的URL.
通过URL获取绝对路径,使用File类的 java.io.listFiles(FileFilter filter)列出所有的文件或目录
对上一步获取的文件或目录递归调用,最后通过Thread.currentThread().getContextClassLoader()
.loadClass(className)获取到Class对象保存到set集合中.
3.2:注意:分隔符的转换:getResources方法定义的资源是 '/' 分隔符
4.结果打印:
---------------------over-----------------------