“编译器会进行泛型擦除”是一个常识了(好吧,实际擦除的是参数和自变量的类型)。这个过程由“类型擦除”实现。但是并非像许多开发者认为的那样,在 <..> 符号内的东西都被擦除了。看下面这段代码:
import java.lang.reflect.ParameterizedType;
import java.util.ArrayList;
import java.util.List;
public class ClassTest {
class Foo<E extends CharSequence> {
public List<Bar> children = new ArrayList<Bar>();
public List<StringBuilder> foo(List<String> foo) {
return null;
}
public void bar(List<? extends String> param) {
}
}
class Bar extends Foo<String> {
}
public static void main(String[] args) throws Exception {
ParameterizedType type = (ParameterizedType) Bar.class.getGenericSuperclass();
System.out.println(type.getActualTypeArguments()[0]);
ParameterizedType fieldType = (ParameterizedType) Foo.class.getField("children").getGenericType();
System.out.println(fieldType.getActualTypeArguments()[0]);
ParameterizedType paramType = (ParameterizedType) Foo.class.getMethod("foo", List.class).getGenericParameterTypes()[0];
System.out.println(paramType.getActualTypeArguments()[0]);
System.out.println(Foo.class.getTypeParameters()[0].getBounds()[0]);
}
}输出如下:
/**
* class java.lang.String
* class com.test.javabasic.annotation.annotation_eraserse.ClassTest$Bar
* class java.lang.String
* interface java.lang.CharSequence
*/你会发现每一个类型参数都被保留了,而且在运行期可以通过反射机制获取到。那么到底什么是“类型擦除”?至少某些东西被擦除了吧?是的。事实上,除了结构化信息外的所有东西都被擦除了 —— 这里结构化信息是指与类结构相关的信息,而不是与程序执行流程有关的。换言之,与类及其字段和方法的类型参数相关的元数据都会被保留下来,可以通过反射获取到。
而其他的信息都被擦除掉了。例如下面这段代码:
List<String> list = new ArrayList<>();
Iterator<String> it = list.iterator();
while (it.hasNext()) {
String s = it.next();
}实际上会被转换成这个(这两段代码的字节码是一致的)
List list = new ArrayList();
Iterator it = list.iterator();
while (it.hasNext()) {
String s = (String) it.next();
}因此,定义在方法体内的类型参数会被擦除,在必要的时候会有类型转换。另外,如果一个方法被定义为接受 List 参数,这个 T 会被转换成 Object (如果定义了类型的上界的话就转换成对应的类型。这也是你不能 new T() 的原因)。(顺便这里有个关于类型擦除的问题)
目前为止类型擦除定义中的前两点我们都讲完了。第三点是关于bridge方法,我已经在 stackoverflow 上的这个问题(和回答)中已经说明了。
两个结论。第一,java 泛型是非常复杂的。但是不用完全理解这些细节也可以使用它们。
第二,不要假设所有的类型信息都被擦除了 —— 结构化的类型参数还存在,需要的话还是可以用下的(不过不要过分依赖反射机制)。
https://blog.csdn.net/coslay/article/details/41650855
**********************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************************
在运行期只能获取当前class文件中包含泛型信息的泛型类型,而不能在运行时动态获取某个泛型引用的类型。
事实上所谓的泛型的类型擦除是指把某个具体的泛型引用在编译期完成类型检查后,擦除成了Object而丢失了它运行时所赋予的类型信息。举例来说,真正没有擦除的泛型应该是能轻而易举地执行如下操作的:
public class Test<T> {
public T[] getArray(int length) {
Class<T> clazz = T.class;
return (T[])Array.newInstance(clazz, length);
}
}在以上的代码中,假设泛型的信息没有被擦除,您在任何位置new出来的Test实例都会保存自己的“T”类型信息,那么getArray方法就可以获取到实际T的class信息。
而在类型擦除后,上面代码中是没有任何办法在getArray方法内部获取到T的类型信息的,这才是擦除后的实际效果。您所说的可以通过反射获取到的泛型信息一定是某个class作为成员变量、方法返回值等位置的具体泛型类型,举例来说:
public class Test<T> {
private Test<Integer> test;
private T item;
}在上面的代码中,您可以通过反射获取成员test的Integer泛型信息,但是无法获取item的实际类型。这部分我查看了OpenJDK 8的相关源码,从原理上讲,例子中的test成员编译时会将Integer信息编译进class字节码,从而反射系统就可以获取到这个信息,如下图所示:
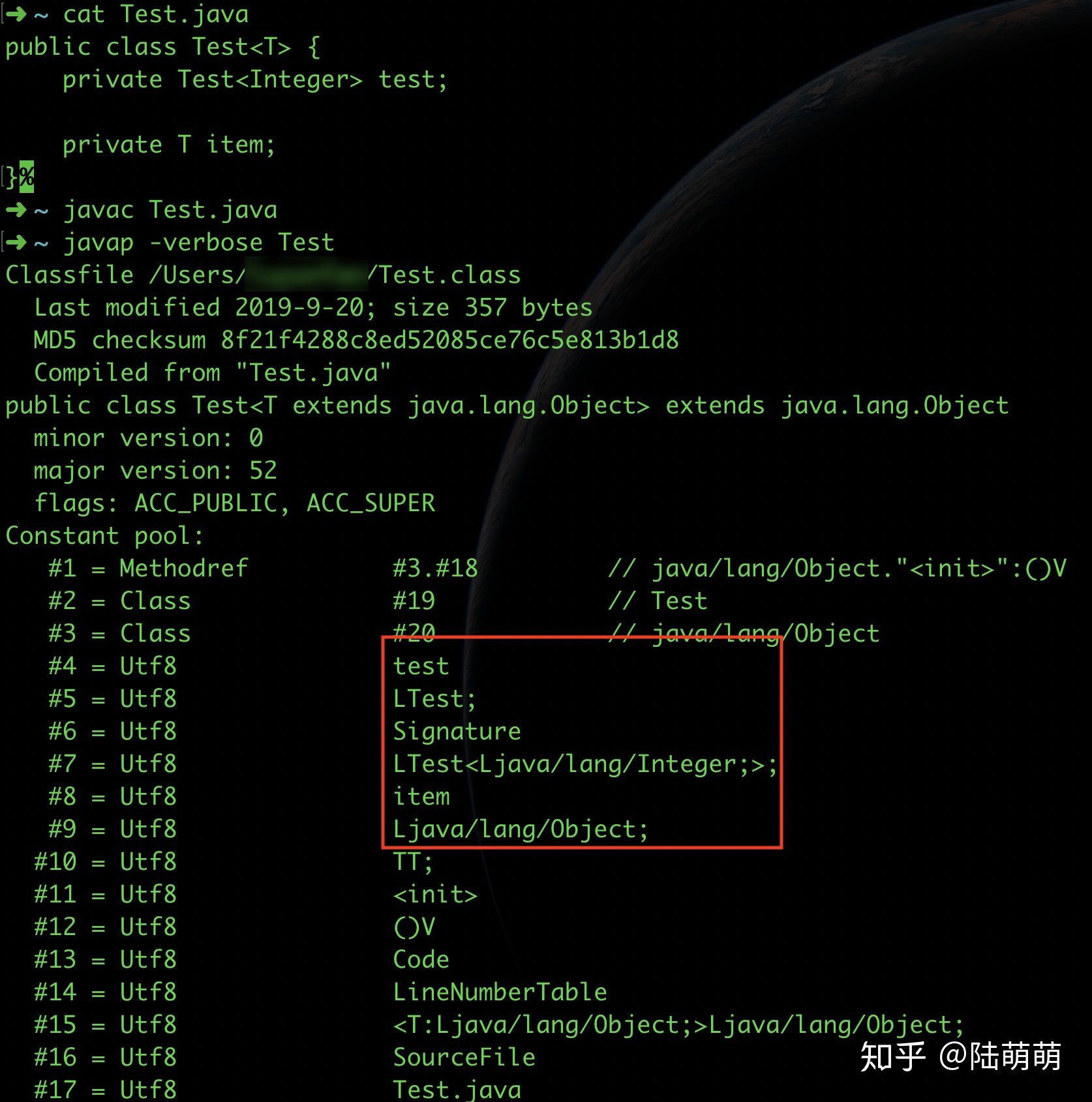
您可以看到,实际上test的泛型信息是直接被编译进字节码了。在OpenJDK 8中,您反射获取泛型的时候,您使用getDeclaredField来获取Field对象时,本质上系统会调用一个native方法:getDeclaredFields0来获取该class的信息。而它的实现在jvm.cpp的JVM_GetClassDeclaredFields方法中:
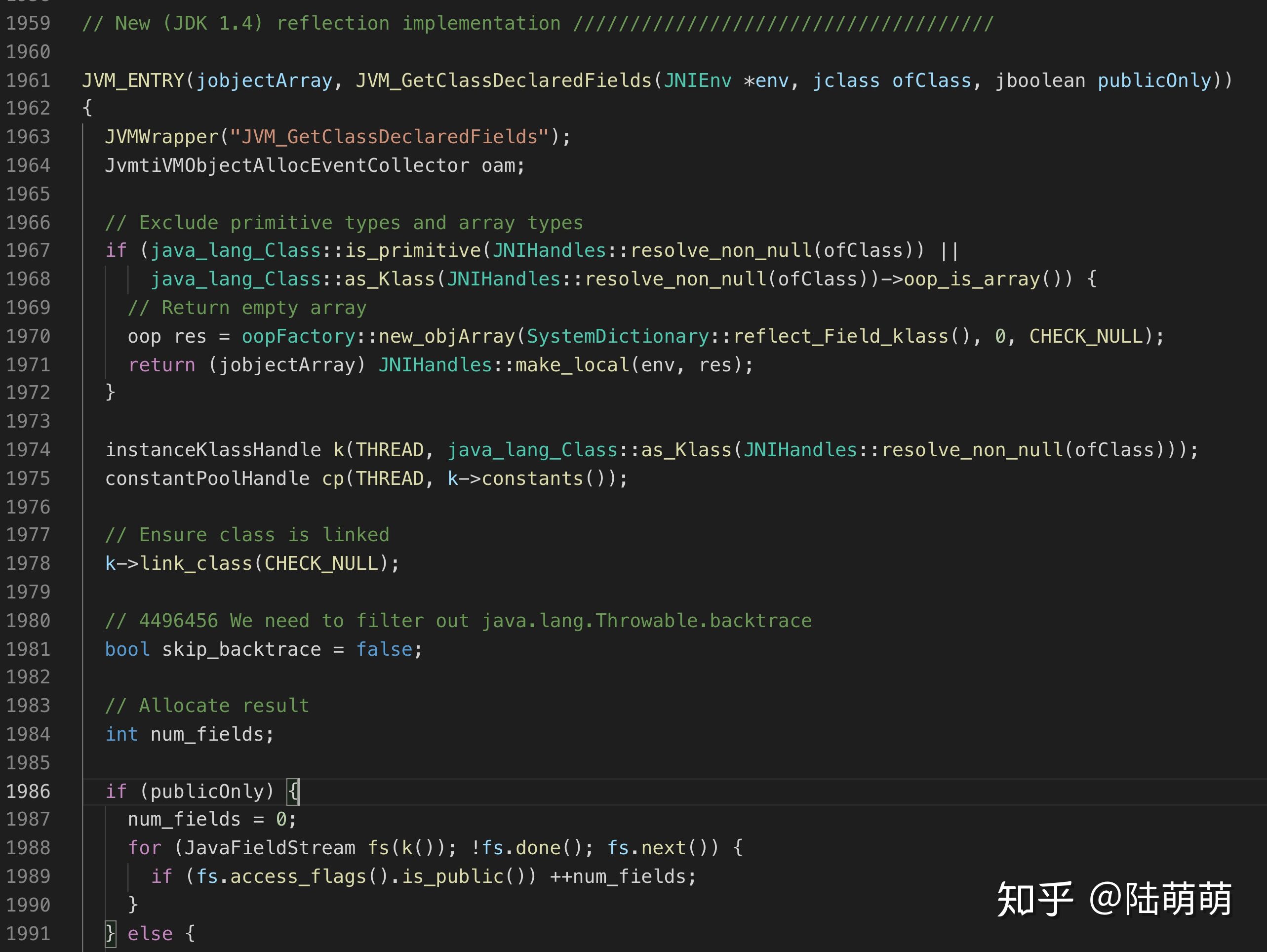
而这个方法本质上的操作是从已经加载好的klass信息中获取fieldDescriptor,从而产生Field对象的oop,把class的field信息注入进去,返回给Java端的调用方。而再追溯klass中产生fieldDescriptor的代码可以发现,事实上这个信息就是在JVM加载字节码的时候,JVM将解析到字节码的泛型信息保存下来的。
也就说在类加载阶段,JVM就将字节码中写死的泛型信息保存了下来。而您反射的时候,反射系统自然就可以获取到该信息,从而您可以通过getGenericType()来获取到Type信息,从而解析出泛型类型。而如同例子中定义的item这类泛型引用来说,它们的泛型信息不来自于自身的class,在编译完成通过类型检查后,类型系统中它们就等同于Object,这种泛型是无法通过反射获取的,也就是说这类类型信息被擦除了。
https://www.zhihu.com/question/346911525/answer/830285753
参考: