在刚刚结束的CoNLL-2018国际评测(universaldependencies.org)中,哈工大社会计算与信息检索研究中心(HIT-SCIR)取得了第一名的好成绩。CoNLL 系列评测每年由 ACL 的计算自然语言学习会议(Conference on Computational Natural Language Learning,CoNLL)主办,是自然语言处理领域影响力最大的国际技术评测,有力推动了自然语言处理各项任务的发展。
与去年的评测任务相同,今年的CoNLL 任务仍为:Multilingual Parsing from Raw Text to Universal Dependencies,即面向生文本的多语言通用依存分析。从生文本出发,需要进行分句、分词、形态学分析、词性标注、依存句法分析等。今年评测任务面向57种语言的82个测试集。最终评价指标为在全部评测集上依存分析任务的平均LAS(依存弧及标签准确率),除此之外还评测了 MLAS(形态学标记正确前提下的LAS)和 BLEX (内容词词形还原正确前提下的LAS)两项指标。
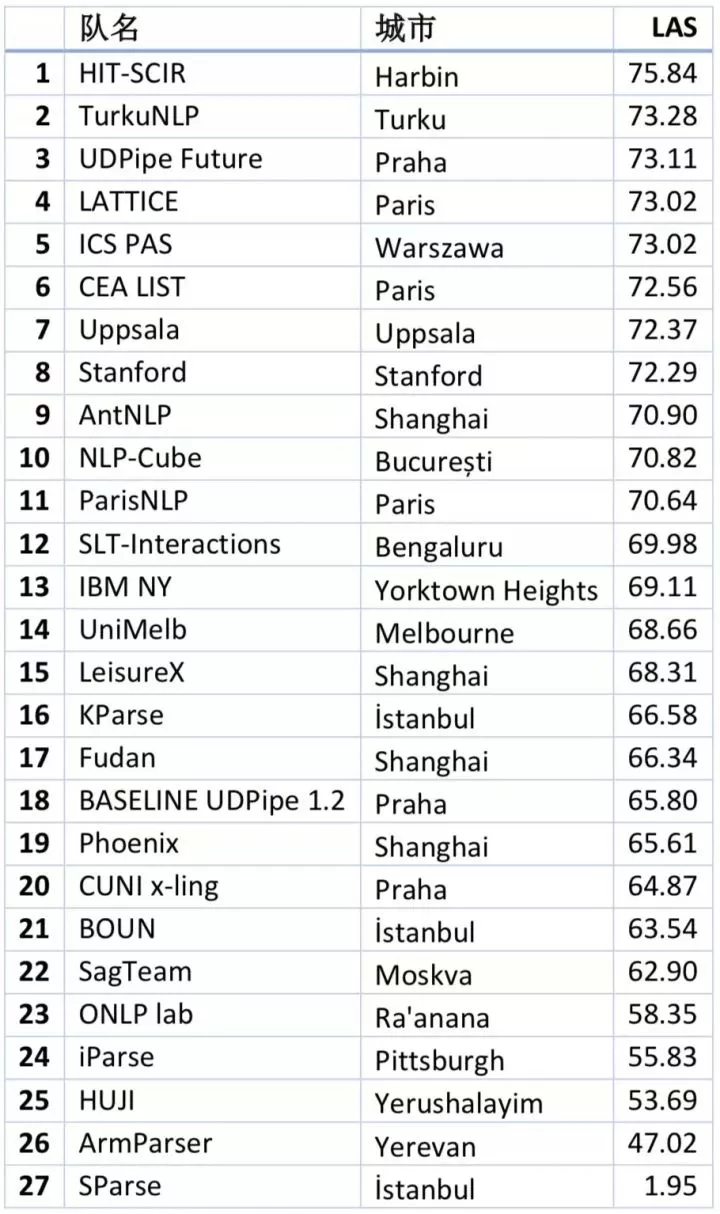
最终有包括斯坦福大学、IBM公司在内的27支队伍成功提交了评测系统,我们的系统在最关键的评测指标,即 LAS 上获得了第1名,高出第二名2.56%。
在去年的评测中,共有45种语言64个数据集,斯坦福大学获得第一名,我们的系统获得了第四名。今年,我们采用了基于图的依存分析算法,并使用大规模未标注数据预训练了上下文相关的词向量模型,大幅提高了系统的准确率。我们的这些技术进步将融入语言技术平台(LTP)中,进一步提高LTP的性能。
项目组成员:车万翔教授,博士生:刘一佳、王宇轩、郑博
http://universaldependencies.org/conll18/results.html):universaldependencies.org
 2一点感受
2一点感受
这个消息真的是令人振奋,大家可能经常看到cv的一些比赛,冠军经常被一些国内的科研单位或者独角兽公司获取,但是在nlp领域的比赛中其实报道并没有那么多,尤其是句法,语义这种基础型的评测比赛。
我在实验室的时候亲眼看到队伍比赛的不易,获得这样的成绩,是对车老师,各位师兄的一个肯定。大家的辛苦没有白忙,真心为实验室感到骄傲!也希望在更多的领域,有更多的中国声音。
希望大家能为我们有这么好的成绩点个赞吧!谢谢大家!