探究一个问题:mysql的innodb引擎下面,索引是个什么数据结构?
- 答:说b树也对,毕竟事实摆在那里。但是b树的结构却又与mysql中索引的特性不相符,这就很奇怪了一方面索引是b树结构,但是又不符合b树的特性。

答:严谨点来说索引数据结构应该是b+树,mysql的索引是在b树的基础上面演变过来的。官网中有原话的哦
- b+树特点(针对普通索引建立的b+树来说)
- 节点是排好序的
- 一个节点可以存多个元素
- 非叶子节点的主键都冗余了一份在叶子节点上面
- 叶子节点间的连接是双向指针
故b+树大概长成这样
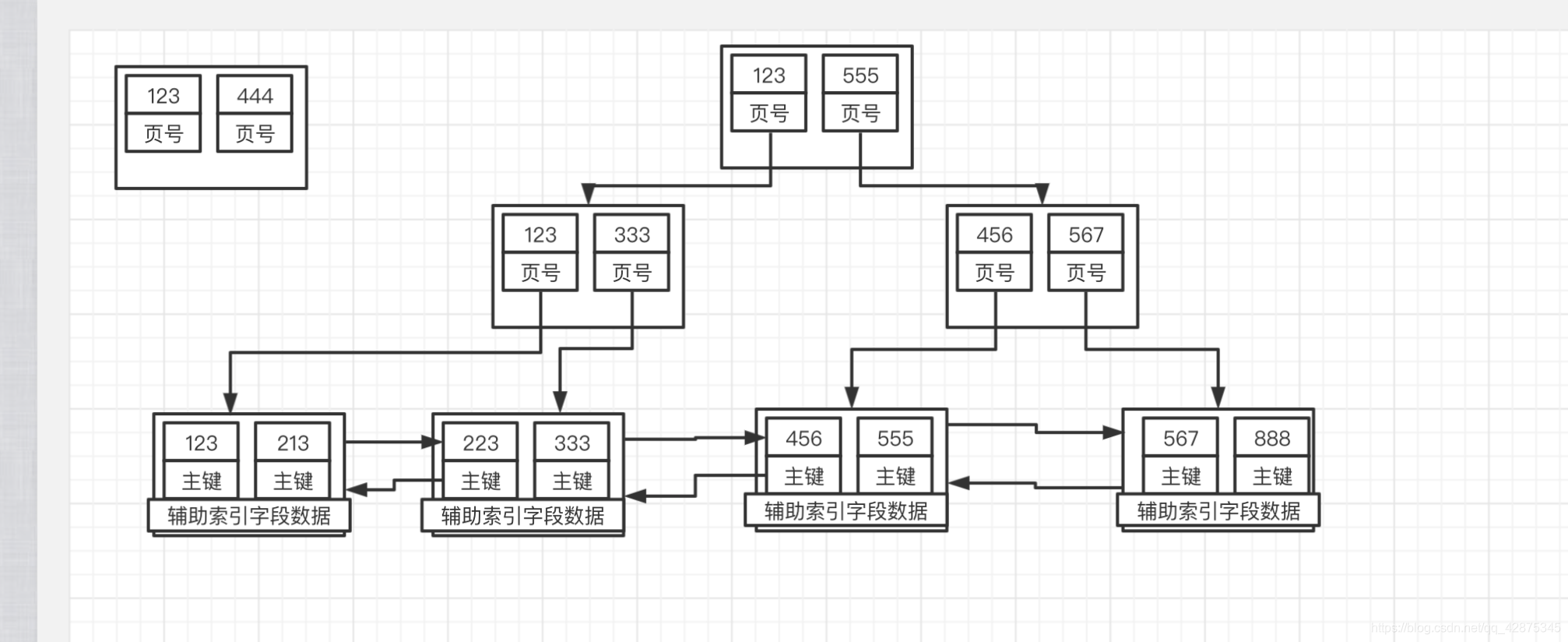
结合b+树图解我们可以来试着解读最左前缀法则、回表、索引下推了
- 最左前缀法则:我们可以理解为&操作,a&b&c当a为false时,后面的b、c不管是true、false直接失效,整个a&b&c生效。同理索引abc也是如此,查询操作第一个条件都不是a,整个索引直接失效
最左前缀法则干嘛的?
- 快速定位到我们需要的数据的主键上面,我们的查询次数仅仅取决于b+树的高度而已,效率快的一批,这也就是使用索引查询数据为什么这么快的原因
什么是回表?(除了主键索引外的索引都是辅助索引)
- 了解回表之前,我们需要明白每创建一个索引,都会依据此索引生成如上一颗b+树的
- 回表:我们所需的字段辅助索引的b+树的叶子节点上面取不到,需要根据辅助索引定位到的主键值,在主键索引的b+树上面进行定位相应的叶子节点获取值的过程称之为回表
回表的情况有哪些?
- select * from user where a = “zzh”; (辅助索引中没有我们需要查询的全部字段)
什么是索引下推?
- 索引下推:从辅助索引中筛选符合条件的主键值然后在回表的过程
- 测试demo:select * from user where a > 100 and a like “%hhh”; (a为索引)
- 索引下推演示:
- 从a索引生成的b+树查找符合条件的主键值
- 从这些主键值中过滤得到符合条件的主键值
- 回表获取完整数据
为什么使用索引下推?
- 好处:减少了回表的次数,由于在辅助索引树中就进行了过滤,因此回表的数据一定是符合我们需要的数据。如果不开启辅助索引,那么我们需要将所有走索引符合条件的主键值进行回表,然后进行过滤操作,回表涉及到对磁盘的io操作,这样开销太大了
现在是不是感觉豁然开朗了呢?别急接着细究。
b+树的叶子节点也可以称之为页,页大小多少?
- mysql中页大小:16kb
- 操作系统的页大小:4kb
这个页是干嘛的?页有什么用?
- 首先普及一个概念:
- 我们每次读取数据都是从磁盘中获取的,然后会把读取到的数据放入内存当中,这个内存有点复杂,其实是有一个专门的缓存池来存放这些数据的,这个缓存池为bufferpool,然后后续需要读取这条数据的线程来时,从内存中获取即可,无需再次从磁盘中获取了
- io:数据流的读入读出
- 页的作用:减少io次数
- 我们io一次把一页放入缓存、我们io多次把等量数据放入缓存,这俩效果相同,但是前者只需io一次,后者io多次。
那为什么mysql是设置页为16kb?
- 答: 为了减少页碎片化问题的出现
- 操作系统页大小为4kb,为了让操作系统取出来的页对应我们mysql中的页,我们可以把mysql页大小设置为操作系统页的整数倍,这样就不会出现操作系统中的页,转换成mysql中的页时会出现碎片化的问题出现了。
知道这些你是否真正了解索引了呢?
索引是什么?
- 粗暴点来说索引就是一颗b+树
你这么了解索引,那么为什么不用uuid作为表的主键呢?
- 索引本质是一颗b+树,b+树的特点之一就是排好序了,用uuid构建b+树的时候进行排序太费劲了(开销太大),想到这还是用自增主键香
索引的结构能具体说清楚点吗?(分主键索引、辅助索引来说)
- 主键索引表:叶子节点 = 行完整数据 + 主键索引值
- 非叶子节点 = 页号 + 主键索引
- 辅助索引表:叶子节点 = 辅助索引+主键索引+索引字段对应的数据
- 非叶子节点 = 辅助索引 + 页号
辅助索引叶子节点为什么不存放完整的数据,只是放主键?
- 如果辅助索引存放完整的数据的话,那么每创建一个索引就需要重新拷贝一份全表的数据,带来的开销是很大的
- 如果辅助索引存放完整的数据的话,那么每插入一条数据都要进行索引的维护,维护起来很麻烦
这么了解索引那你知道有哪些索引吗?
- 物理角度
- 聚簇索引:索引和数据存储于同一个文件下面
- 优点 :查询速度快,根据索引查出主键继而查出数据即可
- 缺点:插入删除慢,插入删除数据需要维护索引关系
- 非聚簇索引:索引与数据分开存储
- 优点:插入删除快,由于索引与数据是分开存储的,插入删除数据无需重新维护索引树
- 缺点:查询速度慢,查出对应的主键值,还需要从数据文件中io获取对应的数据,索引文件与数据文件的分开存储就导致了查询一条数据涉及到对磁盘的多次io,开销大
- 聚簇索引:索引和数据存储于同一个文件下面
- sql语句角度
- 组合索引:对多个字段捆绑建立的索引
- 覆盖索引:组合索引覆盖了单索引,此时的组合索引称为覆盖索引
- 单索引:单个字段建立的索引
- 小结索引:
- innodb使用聚簇索引空间换时间,因此查询速度快,适用于读多写少的业务
- myism使用非聚簇索引,适用于插入删除操作场景多的业务
这么了解索引来实战试试手呗(加深理解 h为单索引 abc为组合索引 user表数据量超级大)
- 查询优化器:辅助索引+回表的代价 > 全表扫描 此时会走全表扫描
- select * from user where h > 30; (根据查询优化器来判断)
- 走索引 先从辅助索引b+树查找h>30对应的主键,回表查出所有数据
- 也可能不走索引 直接全表扫描
- select * from user order by h (根据查询优化器来判断)
- 走索引 h对应的b+树已经对h排好序了
- 不走索引 查询优化器会与全表扫描的代价与之比较,直接从主键b+树把数据加载到内存,基于内存排序
- select h from user; 走索引 辅助索引表叶子节点已经有h字段的值
- select * from user where h= 10 and h like “%0” 索引下推:从辅助索引表中获取主键,过滤筛选主键,回表
关注我一起慢慢变强,来自大三狗的一点学习心得over